Disentanglement Beyond Generative Models with Riemannian ICA
Pith reviewed 2026-05-22 07:46 UTC · model grok-4.3
The pith
RICA defines pointwise disentanglement locally at each data point via a tensor built from the log-likelihood Hessian and Ricci curvature, without needing a global generative model of independent sources.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
RICA replaces ICA's global generative model with local geometric structure. Radial curves emanating from each data point are defined to map to axis-aligned lines in latent space. The disentanglement tensor then encodes a second-order notion called pointwise disentanglement; it is constructed from the Hessian of the data log-likelihood together with the Ricci curvature induced by the model. In controlled source-recovery experiments with known ground-truth factors, the tensor recovers sources across multiple manifolds while standard ICA success depends on the coordinate representation chosen for the observations.
What carries the argument
The disentanglement tensor, which encodes second-order pointwise disentanglement from the Hessian of the data log-likelihood and the Ricci curvature of the induced model.
If this is right
- RICA recovers known sources consistently across manifold representations where ICA baselines succeed only for particular coordinate choices.
- The tensor supplies a local, second-order measure of disentanglement that remains compatible with classical generative ICA.
- The framework supplies a theoretical basis for interpreting disentangled features learned by modern encoders that lack any explicit generative model.
Where Pith is reading between the lines
- The same local tensor could be computed directly on the latent space of a pretrained encoder to quantify how disentangled its features are at individual data points.
- Curvature terms in the tensor suggest possible links to other geometric analyses of representation learning that track independence via manifold properties.
- If the radial-curve assumption holds only approximately on real high-dimensional data, the tensor might still serve as a diagnostic rather than an exact recovery tool.
Load-bearing premise
That the factors of variation around any data point can be captured by radial curves that map to straight axis-aligned lines in latent space.
What would settle it
In a source-recovery experiment with known independent ground-truth factors placed on several different manifolds, check whether the disentanglement tensor still identifies the correct directions after arbitrary coordinate changes while standard ICA accuracy drops.
Figures

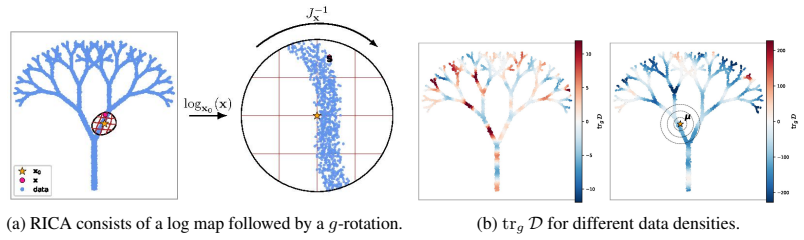
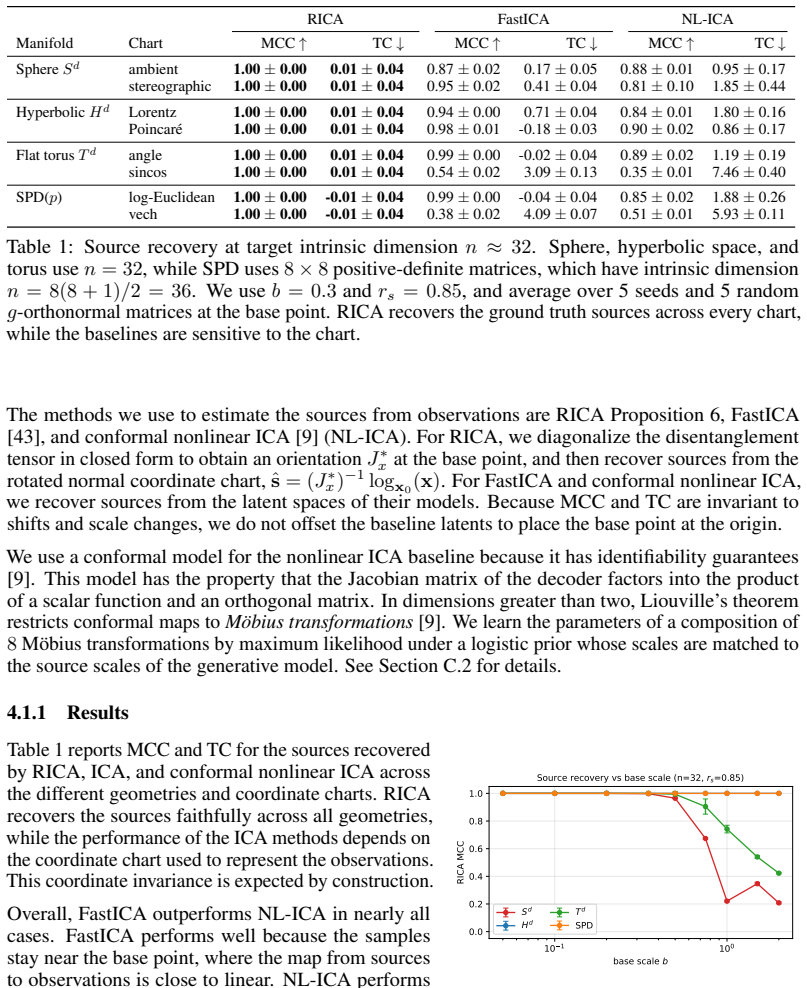

read the original abstract
There is a gap between the theoretical foundations of disentanglement and the practice of modern representation learning. Existing theoretical frameworks, particularly Independent Component Analysis (ICA) and its nonlinear variants, assume a generative model with statistically independent latent variables underlying the data so that disentanglement amounts to identifying the latents that could have generated the data. This generative framework is interpretable and theoretically justified, but its strong assumptions make it difficult to apply to modern representation learning. Modern pretrained encoders often learn features that exhibit disentangled properties without making generative assumptions, yet there is no general theory for interpreting these features as independent factors of variation. We take a step toward such a theory by introducing Riemannian ICA (RICA), which replaces ICA's global generative model with local geometric structure. RICA is founded on the observation that in ICA, the factors of variation underlying a data point can be understood through radial curves emanating from the point that map to axis-aligned lines in the latent space. We formalize this perspective using Riemannian geometry and introduce our theory in a way that is consistent with the existing generative approach. Our main contribution is the disentanglement tensor, which encodes a second-order notion of disentanglement that we call pointwise disentanglement. This tensor depends on the Hessian of the data log likelihood as well as the Ricci curvature induced by the model. In a controlled source recovery setting with known ground-truth sources, RICA recovers sources across several manifolds, while the success of ICA baselines depends on the coordinates used to represent the observations. Our work provides a theoretical basis for studying local disentanglement without assuming a global generative model.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Riemannian ICA (RICA) to address the gap between theoretical disentanglement frameworks like ICA, which rely on global generative models with independent latents, and modern representation learning where pretrained encoders exhibit disentangled features without such assumptions. RICA replaces the global model with local geometric structure based on radial curves from a data point mapping to axis-aligned lines in latent space. The key contribution is the disentanglement tensor, a second-order measure of pointwise disentanglement derived from the Hessian of the data log-likelihood and the Ricci curvature of the model. In controlled experiments with known ground-truth sources, RICA recovers sources across several manifolds in a coordinate-independent manner, unlike standard ICA baselines.
Significance. If the theoretical construction holds, this provides a valuable step toward a general theory for local disentanglement in representation learning. The approach is consistent with the generative ICA case while relaxing the global model requirement. Strengths include the grounding in Riemannian geometry, the introduction of a coordinate-invariant disentanglement measure, and empirical demonstration of source recovery independent of observation coordinates. This could have implications for interpreting features in large pretrained models.
major comments (2)
- [§3] §3 (Disentanglement tensor definition): the central claim that the tensor encodes pointwise disentanglement depends on an explicit formula combining the Hessian of the log-likelihood with the induced Ricci curvature; the manuscript must supply this formula together with a derivation showing it is a true tensor (coordinate-independent) and reduces to classical ICA independence when a global generative model is present.
- [Experimental section] Experimental section (controlled source recovery): the reported success across manifolds is load-bearing for the coordinate-invariance claim, yet the text provides no quantitative metrics, number of trials, manifold specifications, or error analysis; without these the robustness of the result relative to ICA baselines cannot be assessed.
minor comments (2)
- [Abstract] Abstract: the phrase 'several manifolds' should be replaced by an explicit list or reference to the manifolds used in the experiments.
- [Notation] Notation: ensure the symbols for the log-likelihood Hessian and Ricci tensor are introduced once and used consistently in all subsequent sections.
Simulated Author's Rebuttal
We thank the referee for their constructive and insightful comments, which will help clarify the theoretical contributions and strengthen the empirical validation of Riemannian ICA. We address each major comment below and will incorporate the requested changes in a revised manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Disentanglement tensor definition): the central claim that the tensor encodes pointwise disentanglement depends on an explicit formula combining the Hessian of the log-likelihood with the induced Ricci curvature; the manuscript must supply this formula together with a derivation showing it is a true tensor (coordinate-independent) and reduces to classical ICA independence when a global generative model is present.
Authors: We agree that an explicit formula and derivation are essential for rigor. In the revised manuscript we will add the precise definition of the disentanglement tensor T as the coordinate-invariant contraction T_{ij} = H_{ik} R^k_j (where H is the Hessian of the log-likelihood and R the Ricci curvature of the induced metric), together with a short derivation showing that T transforms as a (0,2)-tensor under diffeomorphisms of the observation space. We will also include a lemma proving that, when the model reduces to a global linear ICA generative process with Euclidean metric, T becomes diagonal precisely when the sources are independent, recovering the classical ICA condition. revision: yes
-
Referee: [Experimental section] Experimental section (controlled source recovery): the reported success across manifolds is load-bearing for the coordinate-invariance claim, yet the text provides no quantitative metrics, number of trials, manifold specifications, or error analysis; without these the robustness of the result relative to ICA baselines cannot be assessed.
Authors: We acknowledge that the current experimental description lacks the quantitative detail needed to evaluate robustness. In the revision we will expand the experimental section with: explicit manifold definitions (e.g., S^2 with standard embedding, flat torus with periodic coordinates), number of independent trials (50 runs per manifold), quantitative metrics (mean and standard deviation of source recovery error measured by permutation-invariant MSE), and a comparative table against linear and nonlinear ICA baselines under both canonical and randomly rotated observation coordinates. Error bars and statistical significance tests will be reported. revision: yes
Circularity Check
No significant circularity
full rationale
The derivation begins from the standard ICA observation that factors correspond to radial curves mapping to axis-aligned latent lines, then formalizes this via Riemannian geometry to define a local disentanglement tensor built from the Hessian of the log-likelihood and the induced Ricci curvature. These are independent geometric objects applied to the data density; the construction is explicitly stated to be consistent with the generative case while removing the global model requirement. No equation reduces a claimed result to a fitted parameter or prior self-citation by construction, and the controlled recovery experiments use external ground-truth sources for validation. The framework therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Riemannian geometry is an appropriate framework for capturing local factors of variation via radial curves and curvature on data manifolds
invented entities (1)
-
disentanglement tensor
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking (SphereAdmitsCircleLinking D iff D=3) contradicts?
contradictsCONTRADICTS: the theorem conflicts with this paper passage, or marks a claim that would need revision before publication.
Our main contribution is the disentanglement tensor, which encodes a second-order notion of disentanglement... D = nabla^2 log rho - 1/3 Ric... Hessian of the normal log-likelihood is given by partial^2 log p_s(0)/partial s partial s^T = D_s(0)
-
IndisputableMonolith/Foundation/DimensionForcing.leanD=3 forcing from 8-tick period and circle linking contradicts?
contradictsCONTRADICTS: the theorem conflicts with this paper passage, or marks a claim that would need revision before publication.
We evaluate four tractable geometries: the sphere, torus, hyperbolic space, and SPD matrices... RICA recovers sources across several manifolds
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel (J uniquely calibrated reciprocal cost) unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
RICA replaces ICA's global generative model with local geometric structure... normal coordinate chart
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Latent space oddity: on the curvature of deep generative models
Georgios Arvanitidis, Lars Kai Hansen, and Søren Hauberg. Latent space oddity: on the curvature of deep generative models. InInternational Conference on Learning Representations,
-
[2]
URLhttps://openreview.net/forum?id=SJzRZ-WCZ
-
[3]
Self-supervised learning from images with a joint- embedding predictive architecture
Mahmoud Assran, Quentin Duval, Ishan Misra, Piotr Bojanowski, Pascal Vincent, Michael Rabbat, Yann LeCun, and Nicolas Ballas. Self-supervised learning from images with a joint- embedding predictive architecture. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15619–15629, 2023
work page 2023
-
[4]
Randall Balestriero, Nicolas Ballas, Mike Rabbat, and Yann LeCun. Gaussian embeddings: How jepas secretly learn your data density.arXiv preprint arXiv:2510.05949, 2025
-
[5]
Jacob Bamberger, Adam Gosztolai, Pierre Vandergheynst, Michael M. Bronstein, and Iolo Jones. Riemannian metric matching for scalable geometric modelling of distributions. InICLR 2026 Workshop on Geometry-grounded Representation Learning and Generative Modeling,
work page 2026
-
[6]
URLhttps://openreview.net/forum?id=DB24JOyswh
-
[7]
Yoshua Bengio, Aaron Courville, and Pascal Vincent. Representation learning: A review and new perspectives.IEEE transactions on pattern analysis and machine intelligence, 35(8): 1798–1828, 8 2013. ISSN 0162-8828. doi: 10.1109/tpami.2013.50
-
[8]
JAX: composable transformations of Python+NumPy programs, 2018
James Bradbury, Roy Frostig, Peter Hawkins, Matthew James Johnson, Yash Katariya, Chris Leary, Dougal Maclaurin, George Necula, Adam Paszke, Jake VanderPlas, Skye Wanderman- Milne, and Qiao Zhang. JAX: composable transformations of Python+NumPy programs, 2018. URLhttp://github.com/jax-ml/jax
work page 2018
-
[9]
Interaction asymmetry: A general principle for learning composable abstrac- tions.arXiv, 2024
Jack Brady, Julius von Kügelgen, Sébastien Lachapelle, Simon Buchholz, Thomas Kipf, and Wieland Brendel. Interaction asymmetry: A general principle for learning composable abstrac- tions.arXiv, 2024. URLhttps://arxiv.org/abs/2411.07784
-
[10]
Geometric Deep Learning: Grids, Groups, Graphs, Geodesics, and Gauges
Michael M Bronstein, Joan Bruna, Taco Cohen, and Petar Veliˇckovi´c. Geometric deep learning: Grids, groups, graphs, geodesics, and gauges.arXiv preprint arXiv:2104.13478, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[11]
Simon Buchholz, Michel Besserve, and Bernhard Schölkopf. Function classes for identifiable nonlinear independent component analysis.Advances in Neural Information Processing Systems, 35:16946–16961, 8 2022. doi: 10.48550/arxiv.2208.06406
-
[12]
Simon Buchholz, Goutham Rajendran, Elan Rosenfeld, Bryon Aragam, Bernhard Schölkopf, and Pradeep Ravikumar. Learning linear causal representations from interventions under general nonlinear mixing.Advances in Neural Information Processing Systems, 36:45419–45462, 2023. 11
work page 2023
-
[13]
Christopher P. Burgess, Irina Higgins, Arka Pal, Loïc Matthey, Nick Watters, Guillaume Desjardins, and Alexander Lerchner. Understanding disentangling in β-V AE. InNIPS 2017 Workshop on Learning Disentangled Representations, 2017
work page 2017
-
[14]
Emerging properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. InProceedings of the International Conference on Computer Vision (ICCV), 2021
work page 2021
-
[15]
Hugo Caselles-Dupré, Michael Garcia Ortiz, and David Filliat. Symmetry-based disentangled representation learning requires interaction with environments.Advances in Neural Information Processing Systems, 32, 2019
work page 2019
-
[16]
Ricky T. Q. Chen, Xuechen Li, Roger B Grosse, and David K Duvenaud. Isolating Sources of Disentanglement in Variational Autoencoders. In S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett, editors,Advances in Neural Information Pro- cessing Systems, volume 31. Curran Associates, Inc., 2 2018. URL https://proceedings. neurips...
work page 2018
-
[17]
Flow matching on general geometries
Ricky TQ Chen and Yaron Lipman. Flow matching on general geometries. InInternational Conference on Learning Representations, volume 2024, pages 47922–47945, 2024
work page 2024
-
[18]
Infogan: Interpretable representation learning by information maximizing generative adversarial nets
Xi Chen, Yan Duan, Rein Houthooft, John Schulman, Ilya Sutskever, and Pieter Abbeel. Infogan: Interpretable representation learning by information maximizing generative adversarial nets. Advances in neural information processing systems, 29, 2016
work page 2016
-
[19]
Independent component analysis, a new concept?Signal Processing, 36(3): 287–314, 1994
Pierre Comon. Independent component analysis, a new concept?Signal Processing, 36(3): 287–314, 1994. doi: 10.1016/0165-1684(94)90029-9
-
[20]
Relaxing bijectivity constraints with continuously indexed normalising flows
Rob Cornish, Anthony Caterini, George Deligiannidis, and Arnaud Doucet. Relaxing bijectivity constraints with continuously indexed normalising flows. InInternational conference on machine learning, pages 2133–2143. PMLR, 2020
work page 2020
-
[21]
Edmond Cunningham. local_coordinates: A JAX-based framework for differential ge- ometry computations on Riemannian manifolds, 2026. URL https://github.com/ EddieCunningham/local_coordinates
work page 2026
-
[22]
The DeepMind JAX Ecosystem, 2020
DeepMind, Igor Babuschkin, Kate Baumli, Alison Bell, Surya Bhupatiraju, Jake Bruce, Peter Buchlovsky, David Budden, Trevor Cai, Aidan Clark, Ivo Danihelka, Antoine Dedieu, Claudio Fantacci, Jonathan Godwin, Chris Jones, Ross Hemsley, Tom Hennigan, Matteo Hessel, Shaobo Hou, Steven Kapturowski, Thomas Keck, Iurii Kemaev, Michael King, Markus Kunesch, Lena ...
work page 2020
-
[23]
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large- scale hierarchical image database. In2009 IEEE Conference on Computer Vision and Pattern Recognition, pages 248–255, 2009. doi: 10.1109/CVPR.2009.5206848
-
[24]
Density estimation using real NVP
Laurent Dinh, Jascha Sohl-Dickstein, and Samy Bengio. Density estimation using real NVP. In International Conference on Learning Representations, 2017. URL https://openreview. net/forum?id=HkpbnH9lx
work page 2017
-
[25]
Diffeomorphic explanations with normalizing flows
Ann-Kathrin Dombrowski, Jan E Gerken, and Pan Kessel. Diffeomorphic explanations with normalizing flows. InICML Workshop on Invertible Neural Networks, Normalizing Flows, and Explicit Likelihood Models, 6 2021. URL https://openreview.net/forum? id=ZBR9EpEl6G4
work page 2021
-
[26]
Nelson Elhage, Tristan Hume, Catherine Olsson, Nicholas Schiefer, Tom Henighan, Shauna Kravec, Zac Hatfield-Dodds, Robert Lasenby, Dawn Drain, Carol Chen, Roger Grosse, Sam McCandlish, Jared Kaplan, Dario Amodei, Martin Wattenberg, and Christopher Olah. Toy models of superposition. https://transformer-circuits.pub/2022/toy_model/ 12 index.html, 2022. URL ...
work page 2022
-
[27]
P Thomas Fletcher, Conglin Lu, Stephen M Pizer, and Sarang Joshi. Principal geodesic analysis for the study of nonlinear statistics of shape.IEEE transactions on medical imaging, 23(8): 995–1005, 2004
work page 2004
-
[28]
Geodesic regression on riemannian manifolds
Thomas Fletcher. Geodesic regression on riemannian manifolds. InProceedings of the Third International Workshop on Mathematical Foundations of Computational Anatomy-Geometrical and Statistical Methods for Modelling Biological Shape Variability, pages 75–86, 2011
work page 2011
-
[29]
Normalizing Flows on Riemannian Manifolds
Mevlana C Gemici, Danilo Rezende, and Shakir Mohamed. Normalizing flows on riemannian manifolds.arXiv preprint arXiv:1611.02304, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[30]
Gene H Golub and Charles F Van Loan.Matrix computations. JHU press, 2013
work page 2013
-
[31]
Generative adversarial nets.Advances in neural information processing systems, 27, 2014
Ian J Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets.Advances in neural information processing systems, 27, 2014
work page 2014
-
[32]
Independent mechanism analysis, a new concept? In A
Luigi Gresele, Julius V on Kügelgen, Vincent Stimper, Bernhard Schölkopf, and Michel Besserve. Independent mechanism analysis, a new concept? In A. Beygelzimer, Y . Dauphin, P. Liang, and J. Wortman Vaughan, editors,Advances in Neural Information Processing Systems, pages 28233–28248, 2021. URLhttps://openreview.net/forum?id=Rnn8zoAkrwr
work page 2021
-
[33]
Riemannian metric learning: Closer to you than you imagine
Samuel Gruffaz and Josua Sassen. Riemannian metric learning: Closer to you than you imagine. arXiv preprint arXiv:2503.05321, 2025
-
[34]
Charles R. Harris, K. Jarrod Millman, Stéfan J. van der Walt, Ralf Gommers, Pauli Vir- tanen, David Cournapeau, Eric Wieser, Julian Taylor, Sebastian Berg, Nathaniel J. Smith, Robert Kern, Matti Picus, Stephan Hoyer, Marten H. van Kerkwijk, Matthew Brett, Allan Haldane, Jaime Fernández del Río, Mark Wiebe, Pearu Peterson, Pierre Gérard-Marchant, Kevin She...
-
[35]
Lagrangian manifold monte carlo on monge patches
Marcelo Hartmann, Mark Girolami, and Arto Klami. Lagrangian manifold monte carlo on monge patches. InInternational Conference on Artificial Intelligence and Statistics, pages 4764–4781. PMLR, 2022
work page 2022
-
[36]
beta-vae: Learning basic visual concepts with a constrained variational framework
Irina Higgins, Loic Matthey, Arka Pal, Christopher Burgess, Xavier Glorot, Matthew Botvinick, Shakir Mohamed, and Alexander Lerchner. beta-vae: Learning basic visual concepts with a constrained variational framework. InInternational Conference on Learning Representations, 4 2017
work page 2017
-
[37]
Towards a Definition of Disentangled Representations
Irina Higgins, David Amos, David Pfau, Sebastien Racaniere, Loic Matthey, Danilo Rezende, and Alexander Lerchner. Towards a definition of disentangled representations.arXiv preprint arXiv:1812.02230, abs/1812.02230, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[38]
Daniella Horan, Eitan Richardson, and Yair Weiss. When is unsupervised disentanglement possible?Advances in Neural Information Processing Systems, 34:5150–5161, 2021
work page 2021
-
[39]
Sparse autoencoders find highly interpretable features in language models
Robert Huben, Hoagy Cunningham, Logan Riggs Smith, Aidan Ewart, and Lee Sharkey. Sparse autoencoders find highly interpretable features in language models. InThe Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum? id=F76bwRSLeK
work page 2024
-
[40]
J. D. Hunter. Matplotlib: A 2d graphics environment.Computing in Science & Engineering, 9 (3):90–95, 2007. doi: 10.1109/MCSE.2007.55
-
[41]
Independent component analysis: Algorithms and applications
Aapo Hyvärinen and Erkki Oja. Independent component analysis: Algorithms and applications. Neural Networks, 13(4–5):411–430, 6 2000. ISSN 0893-6080. doi: 10.1016/S0893-6080(00) 00026-5. 13
-
[42]
Aapo Hyvärinen and Petteri Pajunen. Nonlinear independent component analysis: Existence and uniqueness results.Neural Netw., 12(3):429–439, apr 1999. ISSN 0893-6080. doi: 10.1016/ S0893-6080(98)00140-3. URLhttps://doi.org/10.1016/S0893-6080(98)00140-3
-
[43]
Nonlinear ica using auxiliary variables and generalized contrastive learning
Aapo Hyvarinen, Hiroaki Sasaki, and Richard Turner. Nonlinear ica using auxiliary variables and generalized contrastive learning. InThe 22nd international conference on artificial intelligence and statistics, pages 859–868. PMLR, 2019
work page 2019
-
[44]
Aapo Hyvärinen, Ilyes Khemakhem, and Hiroshi Morioka. Nonlinear independent component analysis for principled disentanglement in unsupervised deep learning.Patterns, 4(10), 2023
work page 2023
-
[45]
Aapo Hyvärinen and Erkki Oja. A fast fixed-point algorithm for independent component analysis.Neural Computation, 9(7):1483–1492, 1997. doi: 10.1162/neco.1997.9.7.1483
-
[46]
Computing diffusion geometry.arXiv preprint arXiv:2602.06006, 2026
Iolo Jones and David Lanners. Computing diffusion geometry.arXiv preprint arXiv:2602.06006, 2026
-
[47]
A style-based generator architecture for generative adversarial networks
Tero Karras, Samuli Laine, and Timo Aila. A style-based generator architecture for generative adversarial networks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4401–4410, 6 2019. doi: 10.1109/cvpr.2019.00453
-
[48]
Variational au- toencoders and nonlinear ica: A unifying framework
Ilyes Khemakhem, Diederik Kingma, Ricardo Monti, and Aapo Hyvarinen. Variational au- toencoders and nonlinear ica: A unifying framework. InInternational conference on artificial intelligence and statistics, pages 2207–2217. PMLR, 2020
work page 2020
-
[49]
Patrick Kidger and Cristian Garcia. Equinox: neural networks in JAX via callable PyTrees and filtered transformations.Differentiable Programming workshop at Neural Information Processing Systems 2021, 2021
work page 2021
-
[50]
Hyunjik Kim and Andriy Mnih. Disentangling by factorising. InInternational conference on machine learning, pages 2649–2658. PMLR, 2018
work page 2018
-
[51]
Auto-Encoding Variational Bayes
Diederik P. Kingma and Max Welling. Auto-encoding variational bayes. In Yoshua Bengio and Yann LeCun, editors,2nd International Conference on Learning Representations, ICLR 2014, Banff, AB, Canada, April 14-16, 2014, Conference Track Proceedings, 2014. URL http://arxiv.org/abs/1312.6114
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[52]
Alexander Kraskov, Harald Stögbauer, and Peter Grassberger. Estimating mutual information. Physical Review E—Statistical, Nonlinear, and Soft Matter Physics, 69(6):066138, 2004
work page 2004
-
[53]
Diagonalizing the ricci tensor.The Journal of Geometric Analysis, 31(6): 5638–5658, 2021
Anusha M Krishnan. Diagonalizing the ricci tensor.The Journal of Geometric Analysis, 31(6): 5638–5658, 2021
work page 2021
-
[54]
Variational inference of disentangled latent concepts from unlabeled observations
Abhishek Kumar, Prasanna Sattigeri, and Avinash Balakrishnan. Variational inference of disentangled latent concepts from unlabeled observations. InInternational Conference on Learning Representations, 2018
work page 2018
-
[55]
Disentanglement via mechanism sparsity regularization: A new principle for nonlinear ica
Sébastien Lachapelle, Pau Rodriguez, Yash Sharma, Katie E Everett, Rémi Le Priol, Alexandre Lacoste, and Simon Lacoste-Julien. Disentanglement via mechanism sparsity regularization: A new principle for nonlinear ica. InConference on Causal Learning and Reasoning, pages 428–484. PMLR, 2022
work page 2022
-
[56]
Lee.Introduction to Smooth Manifolds
John M. Lee.Introduction to Smooth Manifolds. Springer, 2000
work page 2000
-
[57]
Lee.Introduction to Riemannian Manifolds, volume 176 ofGraduate Texts in Mathemat- ics
John M. Lee.Introduction to Riemannian Manifolds, volume 176 ofGraduate Texts in Mathemat- ics. Springer, 2nd edition, 2018. ISBN 978-3-319-91754-2. doi: 10.1007/978-3-319-91755-9
-
[58]
Francesco Locatello, Stefan Bauer, Mario Lucic, Gunnar Rätsch, Sylvain Gelly, Bernhard Schölkopf, and Olivier Bachem. A sober look at the unsupervised learning of disentangled representations and their evaluation.Journal of Machine Learning Research, 21(209):1–62, 2020
work page 2020
-
[59]
Mechanistic independence: A principle for identifiable disentangled representations
Stefan Matthes, Zhiwei Han, and Hao Shen. Mechanistic independence: A principle for identifiable disentangled representations. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=0VVdai71xb. 14
work page 2026
-
[60]
Linguistic regularities in continuous space word representations
Tomas Mikolov, Wen-tau Yih, and Geoffrey Zweig. Linguistic regularities in continuous space word representations. InProceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 746–751, Atlanta, Georgia, June 2013. Association for Computational Linguistics. URL https:...
work page 2013
-
[61]
Jürgen Moser. On the volume elements on a manifold.Transactions of the American Mathemat- ical Society, 120(2):286–294, 1965
work page 1965
-
[62]
Aaron Mueller, Andrew Lee, Shruti Joshi, Ekdeep Singh Lubana, Dhanya Sridhar, and Patrik Reizinger. From isolation to entanglement: When do interpretability methods identify and disentangle known concepts?arXiv preprint arXiv:2512.15134, 2025
-
[63]
Disentangling dense embeddings with sparse autoencoders.arXiv preprint arXiv:2408.00657, 2024
Charles O’Neill, Christine Ye, Kartheik Iyer, and John F Wu. Disentangling dense embeddings with sparse autoencoders.arXiv preprint arXiv:2408.00657, 2024
-
[64]
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V . V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel HAZIZA, Francisco Massa, Alaaeldin El-Nouby, Mido Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Herve Jegou, Julien Mairal, Patrick L...
work page 2024
-
[65]
George Papamakarios, Eric Nalisnick, Danilo Jimenez Rezende, Shakir Mohamed, and Balaji Lakshminarayanan. Normalizing flows for probabilistic modeling and inference.Journal of Machine Learning Research, 22(57):1–64, 2021
work page 2021
-
[66]
The linear representation hypothesis and the geometry of large language models
Kiho Park, Yo Joong Choe, and Victor Veitch. The linear representation hypothesis and the geometry of large language models. InCausal Representation Learning Workshop at NeurIPS 2023, 2023. URLhttps://openreview.net/forum?id=T0PoOJg8cK
work page 2023
-
[67]
F. Pedregosa, G. Varoquaux, A. Gramfort, V . Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V . Dubourg, J. Vanderplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, and E. Duchesnay. Scikit-learn: Machine learning in Python.Journal of Machine Learning Research, 12:2825–2830, 2011
work page 2011
-
[68]
Xavier Pennec. Intrinsic statistics on Riemannian manifolds: Basic tools for geometric measurements.Journal of Mathematical Imaging and Vision, 25:127–154, 2006. doi: 10.1007/s10851-006-6228-4
-
[69]
Barycentric subspace analysis on manifolds.The Annals of Statistics, 46 (6A):2711 – 2746, 2018
Xavier Pennec. Barycentric subspace analysis on manifolds.The Annals of Statistics, 46 (6A):2711 – 2746, 2018. doi: 10.1214/17-AOS1636. URL https://doi.org/10.1214/ 17-AOS1636
-
[70]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
work page 2021
-
[71]
Goutham Rajendran, Simon Buchholz, Bryon Aragam, Bernhard Schölkopf, and Pradeep Ravikumar. From causal to concept-based representation learning.Advances in Neural Infor- mation Processing Systems, 37:101250–101296, 2024
work page 2024
-
[72]
Patrik Reizinger, Luigi Gresele, Jack Brady, Julius V on Kügelgen, Dominik Zietlow, Bernhard Schölkopf, Georg Martius, Wieland Brendel, and Michel Besserve. Embrace the gap: Vaes perform independent mechanism analysis.Advances in Neural Information Processing Systems, 35:12040–12057, 6 2022. doi: 10.48550/arxiv.2206.02416
-
[73]
Variational inference with normalizing flows
Danilo Rezende and Shakir Mohamed. Variational inference with normalizing flows. In Francis Bach and David Blei, editors,Proceedings of the 32nd International Conference on Machine Learning, volume 37 ofProceedings of Machine Learning Research, pages 1530–1538, Lille, France, 07–09 Jul 2015. PMLR. URLhttps://proceedings.mlr.press/v37/rezende15. html. 15
work page 2015
-
[74]
Zimmermann, and Wieland Brendel
Evgenia Rusak, Patrick Reizinger, Attila Juhos, Oliver Bringmann, Roland S. Zimmermann, and Wieland Brendel. Infonce: Identifying the gap between theory and practice. InProceedings of the 28th International Conference on Artificial Intelligence and Statistics, volume 258 of Proceedings of Machine Learning Research, Mai Khao, Thailand, 2025. PMLR
work page 2025
-
[75]
Toward causal representation learning.Proceedings of the IEEE, 109(5):612–634, 2021
Bernhard Schölkopf, Francesco Locatello, Stefan Bauer, Nan Rosemary Ke, Nal Kalchbrenner, Anirudh Goyal, and Yoshua Bengio. Toward causal representation learning.Proceedings of the IEEE, 109(5):612–634, 5 2021. ISSN 0018-9219. doi: 10.1109/jproc.2021.3058954
-
[76]
Open Problems in Mechanistic Interpretability
Lee Sharkey, Bilal Chughtai, Joshua Batson, Jack Lindsey, Jeff Wu, Lucius Bushnaq, Nicholas Goldowsky-Dill, Stefan Heimersheim, Alejandro Ortega, Joseph Bloom, et al. Open problems in mechanistic interpretability.arXiv preprint arXiv:2501.16496, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[77]
Oriane Siméoni, Huy V . V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michaël Ramamonjisoa, Francisco Massa, Daniel Haziza, Luca Wehrstedt, Jianyuan Wang, Timothée Darcet, Théo Moutakanni, Leonel Sentana, Claire Roberts, Andrea Vedaldi, Jamie Tolan, John Brandt, Camille Couprie, Julie...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[78]
Raphael Suter, Djordje Miladinovic, Bernhard Schölkopf, and Stefan Bauer. Robustly disen- tangled causal mechanisms: Validating deep representations for interventional robustness. In International Conference on Machine Learning, pages 6056–6065. PMLR, 2019
work page 2019
-
[79]
Adly Templeton, Tom Conerly, Jonathan Marcus, Jack Lindsey, Trenton Bricken, Brian Chen, Adam Pearce, Craig Citro, Emmanuel Ameisen, Andy Jones, Hoagy Cunningham, Nicholas L Turner, Callum McDougall, Monte MacDiarmid, C. Daniel Freeman, Theodore R. Sumers, Edward Rees, Joshua Batson, Adam Jermyn, Shan Carter, Chris Olah, and Tom Henighan. Scaling monosema...
work page 2024
-
[80]
KP Tod. On choosing coordinates to diagonalize the metric.Classical and Quantum Gravity, 9 (7):1693–1705, 1992
work page 1992
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.