Recognition: 2 theorem links
· Lean TheoremFANoS-v2: Feedback-Controlled Momentum with Thermostat Damping for Lightweight Neural Optimization
Pith reviewed 2026-05-16 18:09 UTC · model grok-4.3
The pith
Feedback-controlled momentum with thermostat damping yields top-1 accuracy gains over AdamW on reduced vision datasets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
FANoS augments RMS-preconditioned momentum with a scalar feedback controller over update energy and applies a non-negative thermostat damping coefficient to produce stable updates, resulting in the reported accuracy gains over AdamW at the expense of increased computation time in the tested configurations.
What carries the argument
Scalar feedback controller over update energy with bounded log-ratio thermostat damping that modulates the momentum term in parameter-update units across different preconditioning modes.
If this is right
- The Fast profile delivers consistent mean accuracy gains without per-dataset retuning on the three tested vision benchmarks.
- Wall-clock time increases by roughly 50-62% compared to AdamW under the reported conditions.
- Multiple preconditioning options including diagonal, factored, and raw-gradient are supported with the same controller.
- Diagnostics are exposed to allow auditing for stability issues.
Where Pith is reading between the lines
- If the controller remains stable at larger scales, it could offer an alternative to standard adaptive methods for tasks where accuracy margins matter.
- The mixed preliminary results on PINN and EEG data suggest testing on a wider range of problem types to determine the domain of applicability.
- Implementation optimizations could potentially reduce the runtime penalty while preserving the accuracy benefit.
Load-bearing premise
The feedback controller and thermostat damping generate stable and beneficial updates without requiring dataset-specific adjustments or causing hidden instabilities.
What would settle it
A demonstration of accuracy degradation or training instability on full-scale versions of the same datasets or on additional architectures would challenge the central claim.
Figures




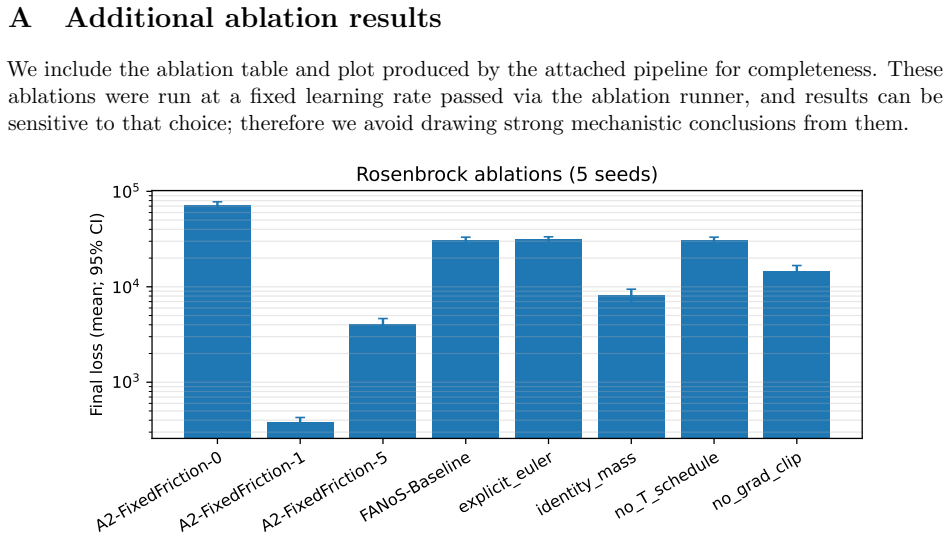
read the original abstract
\FANOS{} is a PyTorch optimizer that augments RMS-preconditioned momentum with a scalar feedback controller over update energy. The public reference implementation stores momentum in parameter-update units, applies a non-negative thermostat damping coefficient, supports diagonal, factored, and raw-gradient preconditioning, and exposes diagnostics intended for stability audits. This study gives a complete mathematical specification of the released optimizer, including the exact parameter-unit update, the study-equation physical update mode, bounded log-ratio thermostat control, adaptive preconditioner softening, warmup guardrails, and the experimental \Fast{} profile. We report the v0.2 evidence: five-seed reduced-sample MNIST, Fashion-MNIST, and CIFAR-10 experiments show mean top-1 gains of 0.889, 2.197, and 2.666 percentage points over AdamW for \Fast{}, but with 49.8\%, 61.6\%, and 56.8\% higher wall-clock time. Preliminary scientific, PINN, and EEG smoke tests are mixed and are treated as hypothesis-generating only. The evidence supports \FANOS{} as an alpha-stage research optimizer with a reproducible lightweight-vision signal and an explicit runtime bottleneck.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces FANoS-v2, a PyTorch optimizer augmenting RMS-preconditioned momentum with a scalar feedback controller over update energy and bounded log-ratio thermostat damping. It supplies a complete mathematical specification of the parameter-unit update, physical update mode, adaptive preconditioner softening, warmup guardrails, and the experimental Fast profile. Five-seed reduced-sample experiments on MNIST, Fashion-MNIST, and CIFAR-10 report mean top-1 gains of 0.889, 2.197, and 2.666 percentage points over AdamW for the Fast profile, offset by 49.8%, 61.6%, and 56.8% higher wall-clock time; non-vision smoke tests are mixed and labeled hypothesis-generating only.
Significance. If the controller stability holds, the work supplies a reproducible lightweight-vision signal together with explicit diagnostics for stability audits, which could serve as a useful alpha-stage research optimizer. The substantial runtime penalty and confinement to small datasets nevertheless limit immediate practical impact.
major comments (3)
- [Stability verification] The central claim that the scalar feedback controller plus bounded log-ratio thermostat damping yields stable beneficial updates rests on the unverified assumption that the controller remains well-behaved across diagonal, factored, and raw-gradient preconditioning modes; no trajectories of update energy, damping coefficient, or preconditioner softening are shown to confirm bounded behavior outside the Fast profile.
- [Experimental protocol] The reported vision gains are quantified with five seeds and explicit percentages, yet the manuscript does not state whether data splits, hyperparameter search, or preconditioner softening choices were fixed in advance or selected after observing results.
- [Results] The mixed non-vision smoke tests are presented only as hypothesis-generating, which leaves the broader claim of beneficial updates without dataset-specific retuning without supporting evidence.
minor comments (1)
- [Experiments] Absolute wall-clock times and hardware specifications are omitted, which would improve reproducibility of the reported runtime overheads.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below, indicating planned revisions where appropriate. The manuscript's scope is limited to an alpha-stage research optimizer with a reproducible lightweight-vision signal; we do not claim broad applicability.
read point-by-point responses
-
Referee: The central claim that the scalar feedback controller plus bounded log-ratio thermostat damping yields stable beneficial updates rests on the unverified assumption that the controller remains well-behaved across diagonal, factored, and raw-gradient preconditioning modes; no trajectories of update energy, damping coefficient, or preconditioner softening are shown to confirm bounded behavior outside the Fast profile.
Authors: We agree that explicit trajectories would strengthen the stability claim. The released implementation already exposes the necessary diagnostics, but the manuscript reports only the Fast profile results. In revision we will add a supplementary figure with representative trajectories of update energy, damping coefficient, and preconditioner softening for diagonal and factored modes on a CIFAR-10 subset, confirming bounded behavior under the same controller parameters. revision: yes
-
Referee: The reported vision gains are quantified with five seeds and explicit percentages, yet the manuscript does not state whether data splits, hyperparameter search, or preconditioner softening choices were fixed in advance or selected after observing results.
Authors: We thank the referee for noting this omission. Standard fixed train/validation/test splits were used for all datasets; the Fast profile hyperparameters and preconditioner softening value were selected from a small preliminary grid before the final five-seed runs and were not adjusted post hoc. We will add an explicit statement to the experimental protocol section clarifying the pre-specified choices. revision: yes
-
Referee: The mixed non-vision smoke tests are presented only as hypothesis-generating, which leaves the broader claim of beneficial updates without dataset-specific retuning without supporting evidence.
Authors: The manuscript's central claim, as stated in the abstract and conclusion, is restricted to a reproducible lightweight-vision signal on MNIST-scale tasks. The non-vision smoke tests are already labeled hypothesis-generating precisely because they are mixed and were not retuned; we make no broader claim of beneficial updates without dataset-specific retuning. The evidence presented therefore matches the stated scope, and no change is required. revision: no
Circularity Check
No circularity: empirical gains are direct measurements, not derived from controller equations
full rationale
The paper supplies an explicit mathematical specification of the optimizer (parameter-unit update, bounded log-ratio thermostat, preconditioner softening, etc.) and then reports separate empirical measurements of top-1 accuracy on reduced-sample MNIST/Fashion-MNIST/CIFAR-10. These accuracy deltas are obtained by running the implemented optimizer against AdamW; they are not obtained by algebraic reduction, parameter fitting, or self-citation that would make the reported numbers tautological with the controller equations. No load-bearing uniqueness theorem, ansatz smuggled via prior work, or “prediction” that collapses to a fitted input appears in the provided text. The central claim therefore remains externally falsifiable and independent of its own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A scalar feedback controller over update energy can be stabilized by a non-negative thermostat damping coefficient without additional loss-landscape assumptions.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel (J uniqueness) and dAlembert_cosh_solution_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Equations (2)–(3) ... ˙ζ = 1/Q (T(v;M) − T0(t)) ... discrete thermostat update ζk+1 ← clip(ζk + h/Q (Tema − T0(k)), [−ζmax, ζmax]) with exponential target schedule T0(k)
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking (D=3 forcing) unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 1 (Linear stability of symplectic Euler on the harmonic oscillator) ... det(A)=1 and eigenvalues on the unit circle when 0 < hω < 2
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Evolution of Optimization Methods: Algorithms, Scenarios, and Evaluations
A retrospective survey and empirical evaluation of deep learning optimization algorithms that identifies trends, design trade-offs, and future directions.
Reference graph
Works this paper leans on
-
[1]
Stochastic gradient Hamiltonian monte carlo
Tianqi Chen, Emily Fox, and Carlos Guestrin. Stochastic gradient Hamiltonian monte carlo. InInternational Conference on Machine Learning, 2014
work page 2014
-
[2]
Nan Ding, Youhan Fang, Ryan Babbush, Changyou Chen, Robert D. Skeel, and Hartmut Neven. Bayesian sampling using stochastic gradient thermostats. InAdvances in Neural Information Processing Systems, 2014
work page 2014
-
[3]
Ernst Hairer, Christian Lubich, and Gerhard Wanner.Geometric Numerical Integration: Structure-Preserving Algorithms for Ordinary Differential Equations. Springer, 2 edition, 2006. 12
work page 2006
-
[4]
William G. Hoover. Canonical dynamics: Equilibrium phase-space distributions.Physical Review A, 31(3):1695–1697, 1985
work page 1985
-
[5]
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. In International Conference on Learning Representations, 2015
work page 2015
-
[6]
Dong C. Liu and Jorge Nocedal. On the limited memory BFGS method for large scale optimization.Mathematical Programming, 45(1):503–528, 1989
work page 1989
-
[7]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InInternational Conference on Learning Representations, 2019
work page 2019
-
[8]
Yurii Nesterov. A method for solving the convex programming problem with convergence rate O(1/k2).Soviet Mathematics Doklady, 27:372–376, 1983
work page 1983
-
[9]
Jorge Nocedal and Stephen J. Wright.Numerical Optimization. Springer, 2 edition, 2006
work page 2006
-
[10]
Shuichi Nos´ e. A molecular dynamics method for simulations in the canonical ensemble.Molecular Physics, 52(2):255–268, 1984
work page 1984
-
[11]
On the difficulty of training recurrent neural networks
Razvan Pascanu, Tomas Mikolov, and Yoshua Bengio. On the difficulty of training recurrent neural networks. InInternational Conference on Machine Learning, 2013
work page 2013
-
[12]
Boris T. Polyak. Some methods of speeding up the convergence of iteration methods.USSR Computational Mathematics and Mathematical Physics, 4(5):1–17, 1964
work page 1964
-
[13]
Maziar Raissi, Paris Perdikaris, and George E. Karniadakis. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations.Journal of Computational Physics, 378:686–707, 2019
work page 2019
-
[14]
Howard H. Rosenbrock. An automatic method for finding the greatest or least value of a function.The Computer Journal, 3(3):175–184, 1960
work page 1960
-
[15]
Lecture 6.5—RMSProp: Divide the gradient by a running average of its recent magnitude
Tijmen Tieleman and Geoffrey Hinton. Lecture 6.5—RMSProp: Divide the gradient by a running average of its recent magnitude. Technical report, University of Toronto, 2012. Technical report, Neural Networks for Machine Learning (Coursera)
work page 2012
-
[16]
Bayesian learning via stochastic gradient Langevin dynamics
Max Welling and Yee Whye Teh. Bayesian learning via stochastic gradient Langevin dynamics. InInternational Conference on Machine Learning, 2011. 13
work page 2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.