Recognition: 2 theorem links
· Lean TheoremFrom Words to Amino Acids: Does the Curse of Depth Persist?
Pith reviewed 2026-05-15 19:13 UTC · model grok-4.3
The pith
Protein language models concentrate most task-relevant computation in a subset of layers, with later layers adding only incremental refinements.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
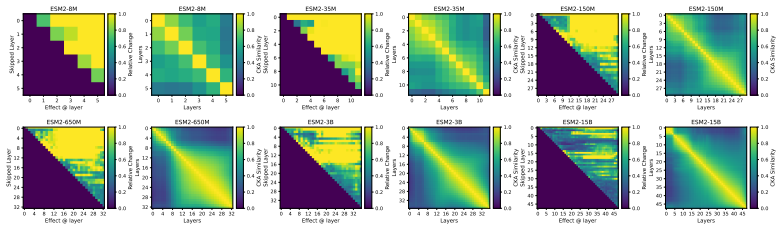
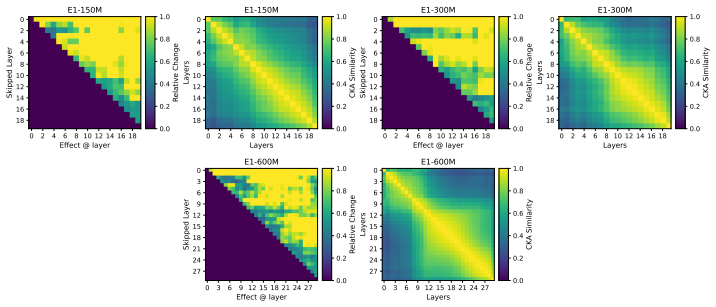
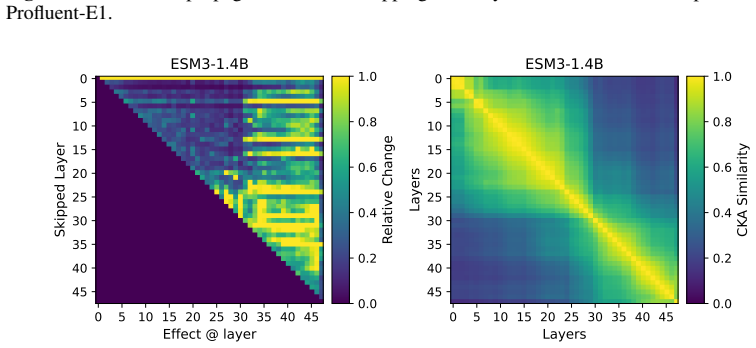
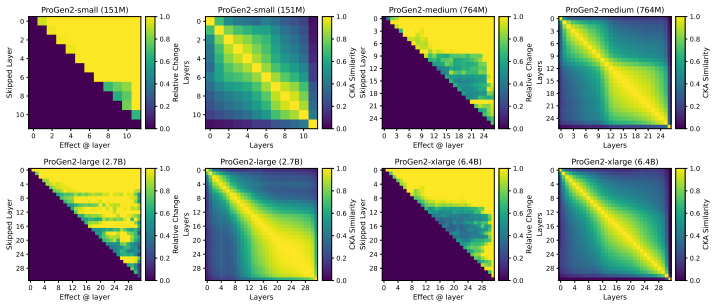
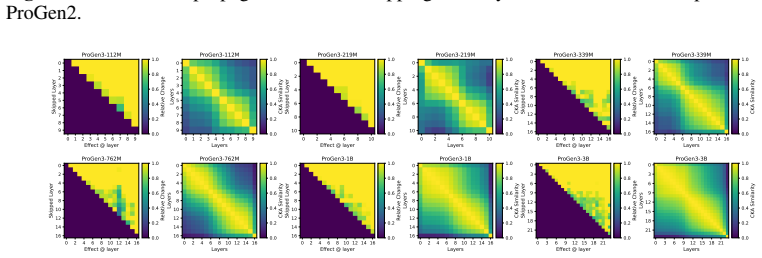
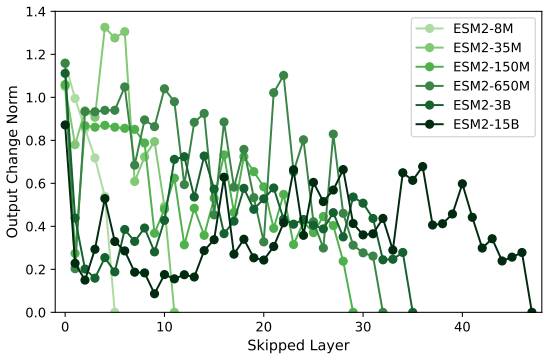
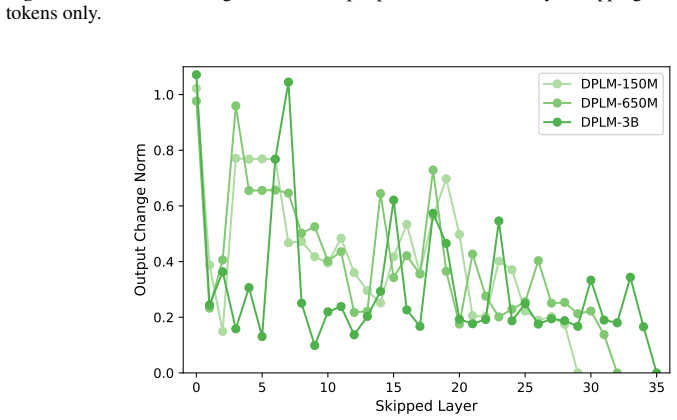
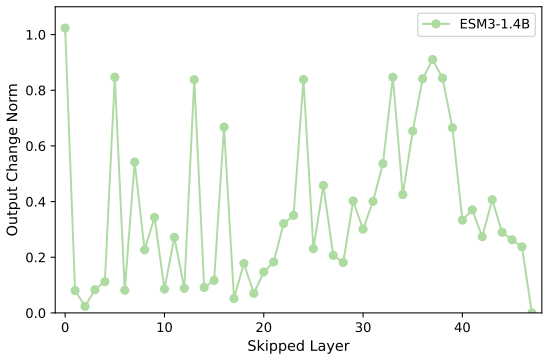
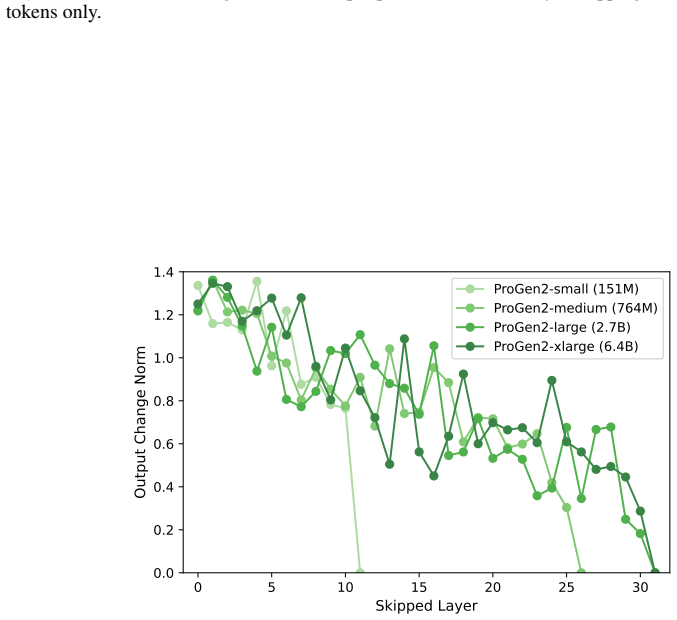
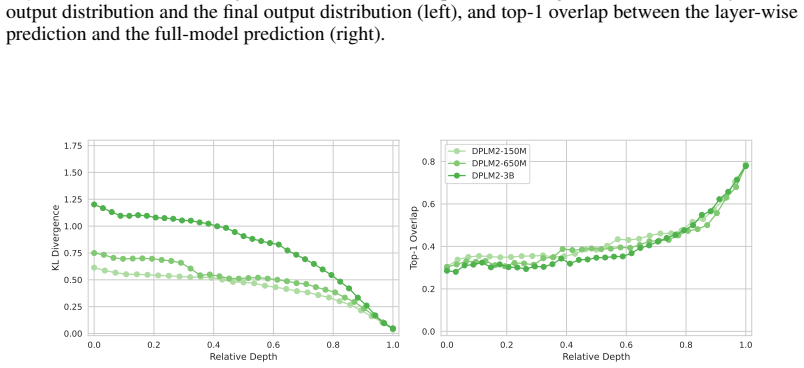
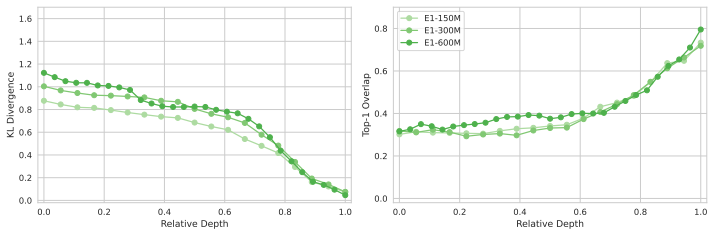
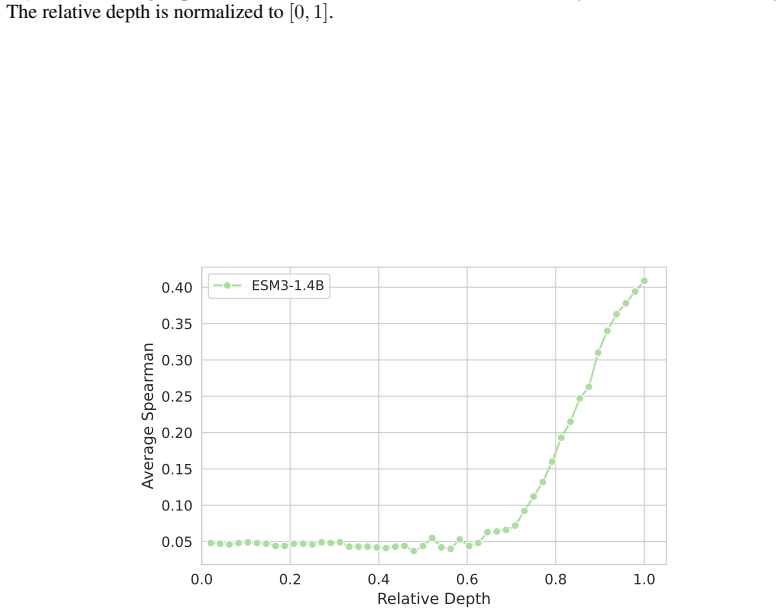
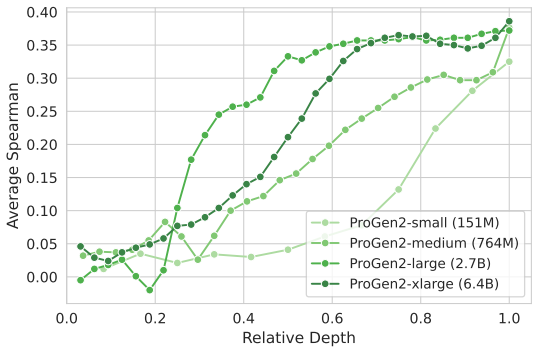
Across seven popular protein language model families spanning autoregressive, masked, and diffusion objectives at multiple scales, a large fraction of task-relevant computation is concentrated in a subset of layers, while the remaining layers mainly provide incremental refinement of the final prediction. These depth-dependent patterns persist beyond sequence-only settings and also appear in multimodal PLMs that accept both protein sequence and structure as input.
What carries the argument
A unified set of probing, perturbation, and downstream-evaluation measurements applied consistently across model families to quantify how each layer's contribution changes with depth.
If this is right
- Many later layers can be removed or down-weighted with limited loss in task performance.
- Training can be focused on strengthening the high-contribution layers rather than uniform depth scaling.
- The same concentration pattern appears in both sequence-only and multimodal protein models.
- Architectures that dynamically allocate computation to key layers may outperform fixed-depth transformers.
Where Pith is reading between the lines
- Depth inefficiency may limit returns from simply making protein models deeper for tasks such as design or folding prediction.
- Pruning or selective fine-tuning of the high-contribution layers could yield efficiency gains without retraining from scratch.
- The pattern may extend to other biomolecular sequence models, suggesting a broader principle about how transformers process sequential biological data.
Load-bearing premise
The chosen probing, perturbation, and downstream measurements isolate each layer's actual contribution without being distorted by training objectives, architecture choices, or dataset properties.
What would settle it
A protein language model in which perturbing or probing any layer produces roughly equal performance drops on the same downstream tasks would show that computation is not concentrated in a subset of layers.
Figures































read the original abstract
Protein language models (PLMs) have become widely adopted as general-purpose models, demonstrating strong performance in protein engineering and de novo design. Like large language models (LLMs), they are typically trained as deep transformers with next-token or masked-token prediction objectives on massive sequence corpora and are scaled by increasing model depth. Recent work on autoregressive LLMs has identified the Curse of Depth: many later layers contribute little to the final output predictions. These findings naturally raise the question of whether a similar depth inefficiency also appears in PLMs, where many widely used models are not autoregressive, and some are multimodal, accepting both protein sequence and structure as input. In this work, we present a depth analysis of seven popular PLM families across model scales, spanning autoregressive, masked, and diffusion objectives, and quantify how layer contributions evolve with depth using a unified set of probing-, perturbation-, and downstream-evaluation measurements. Across models, we observe consistent depth-dependent patterns that extend prior findings on LLMs: a large fraction of task-relevant computation is concentrated in a subset of layers, while the remaining layers mainly provide incremental refinement of the final prediction. These trends persist beyond sequence-only settings and also appear in multimodal PLMs. Taken together, our results suggest that depth inefficiency is a common feature of modern PLMs, motivating future work on more depth-efficient architectures and training methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript investigates whether protein language models (PLMs) exhibit a 'curse of depth' analogous to that observed in large language models, wherein a large fraction of task-relevant computation concentrates in a subset of layers while others contribute mainly incremental refinement. Using a unified suite of probing, perturbation, and downstream-evaluation measurements, the authors analyze seven PLM families spanning autoregressive, masked, and diffusion objectives as well as multimodal (sequence+structure) variants, reporting consistent depth-dependent patterns that persist across model scales and input modalities.
Significance. If the central empirical patterns hold after addressing measurement validity, the work extends LLM depth analyses to the protein domain and supplies concrete motivation for depth-efficient PLM architectures, which would be valuable for protein engineering and design applications.
major comments (2)
- [Methods (perturbation experiments)] Methods (perturbation and probing sections): The headline claim that computation is concentrated in a subset of layers rests on the assumption that the chosen measurements cleanly isolate per-layer contributions. However, standard transformer residual connections allow early-layer activations to bypass later layers and reach the output head unchanged. No ablation that severs, re-scales, or compares against non-residual baselines is described, so the observed concentration could be an architectural artifact rather than evidence of depth inefficiency.
- [Results] Results (main figures and tables): The reported 'consistent patterns' are presented without error bars, confidence intervals, or statistical tests for cross-model agreement. This makes it difficult to evaluate the strength of the depth-dependent trends or to rule out that the patterns are driven by a few outlier models or tasks.
minor comments (1)
- [Abstract] Abstract: The phrase 'curse of depth' is used without a brief parenthetical reference to the specific prior LLM findings being extended, which would help readers unfamiliar with that literature.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on measurement validity and statistical reporting. We address each major comment below and outline the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Methods (perturbation experiments)] Methods (perturbation and probing sections): The headline claim that computation is concentrated in a subset of layers rests on the assumption that the chosen measurements cleanly isolate per-layer contributions. However, standard transformer residual connections allow early-layer activations to bypass later layers and reach the output head unchanged. No ablation that severs, re-scales, or compares against non-residual baselines is described, so the observed concentration could be an architectural artifact rather than evidence of depth inefficiency.
Authors: We appreciate this observation on residual connections. Our perturbation protocol intervenes on layer outputs (zeroing or scaling) while the residual pathways remain intact, so the measured change in final predictions or representations already reflects the incremental contribution of each layer atop the bypassed early activations. This is the standard way to quantify layer importance in residual transformers. We agree that a direct comparison to non-residual architectures would be informative, but it would require retraining multiple large models from scratch, which is outside the scope of the current study focused on existing PLMs. In the revision we will add an explicit paragraph in the Methods section describing how perturbations interact with residuals and include a small-scale controlled experiment on a non-residual toy transformer to illustrate the difference. revision: partial
-
Referee: [Results] Results (main figures and tables): The reported 'consistent patterns' are presented without error bars, confidence intervals, or statistical tests for cross-model agreement. This makes it difficult to evaluate the strength of the depth-dependent trends or to rule out that the patterns are driven by a few outlier models or tasks.
Authors: We agree that the absence of error bars and formal statistical tests weakens the presentation. In the revised manuscript we will recompute all main figures and tables with error bars (standard deviation across random seeds or data splits where applicable) and add statistical tests (Pearson correlation with depth, ANOVA across model families, and outlier-robustness checks) to quantify the consistency of the depth-dependent trends. These additions will be included in both the Results section and the supplementary material. revision: yes
Circularity Check
No significant circularity: purely empirical observational study
full rationale
The paper conducts a direct empirical analysis of seven existing public PLM families using standard probing, perturbation, and downstream metrics on pretrained models. No derivations, equations, fitted parameters renamed as predictions, or self-citation chains are used to support the central claims; observations are reported from measurements on off-the-shelf models without any self-referential construction or ansatz smuggling. The study is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Layer outputs can be meaningfully isolated and their contributions quantified via probing and perturbation without major confounding from residual connections or training dynamics.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Across models, we observe consistent depth-dependent patterns... a large fraction of task-relevant computation is concentrated in a subset of layers, while the remaining layers mainly provide incremental refinement
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_strictMono_of_one_lt unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
skipping later layers produces relatively weak propagated effects... low-effect regions also report high layer-layer similarity
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
Layer Collapse in Diffusion Language Models
Early layers in diffusion language models like LLaDA-8B collapse into redundant representations around a critical super-outlier activation due to overtraining, making them more robust to quantization and sparsity than...
-
Layer Collapse in Diffusion Language Models
Diffusion language models develop early-layer collapse around an indispensable super-outlier due to overtraining, resulting in higher compressibility and reversed optimal sparsity patterns versus autoregressive models.
Reference graph
Works this paper leans on
-
[1]
Eliciting Latent Predictions from Transformers with the Tuned Lens
N. Belrose, Z. Furman, L. Smith, D. Halawi, I. Ostrovsky, L. McKinney, S. Biderman, and J. Steinhardt. Eliciting latent predictions from transformers with the tuned lens.arXiv preprint arXiv:2303.08112, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
A. Bhatnagar, S. Jain, J. Beazer, S. C. Curran, A. M. Hoffnagle, K. S. Ching, M. Martyn, S. Nayfach, J. A. Ruffolo, and A. Madani. Scaling unlocks broader generation and deeper functional understanding of proteins.bioRxiv, pages 2025–04, 2025
work page 2025
-
[3]
N. Brandes, D. Ofer, Y . Peleg, N. Rappoport, and M. Linial. Proteinbert: a universal deep- learning model of protein sequence and function.Bioinformatics, 38(8):2102–2110, 2022
work page 2022
-
[4]
R. Chen, D. Xue, X. Zhou, Z. Zheng, Q. Gu, et al. An all-atom generative model for designing protein complexes. InF orty-second International Conference on Machine Learning, 2025
work page 2025
- [5]
-
[6]
What Does BERT Look At? An Analysis of BERT's Attention
K. Clark, U. Khandelwal, O. Levy, and C. D. Manning. What does bert look at? an analysis of bert’s attention.arXiv preprint arXiv:1906.04341, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[7]
R. Csordás, C. D. Manning, and C. Potts. Do language models use their depth efficiently?arXiv preprint arXiv:2505.13898, 2025
-
[8]
M. Dehghani, S. Gouws, O. Vinyals, J. Uszkoreit, and Ł. Kaiser. Universal transformers.arXiv preprint arXiv:1807.03819, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[9]
A. Elnaggar, M. Heinzinger, C. Dallago, G. Rehawi, Y . Wang, L. Jones, T. Gibbs, T. Feher, C. Angerer, M. Steinegger, et al. Prottrans: Toward understanding the language of life through self-supervised learning.IEEE transactions on pattern analysis and machine intelligence, 44 (10):7112–7127, 2021
work page 2021
- [10]
-
[11]
T. Geffner, K. Didi, Z. Cao, D. Reidenbach, Z. Zhang, C. Dallago, E. Kucukbenli, K. Kreis, and A. Vahdat. La-proteina: Atomistic protein generation via partially latent flow matching.arXiv preprint arXiv:2507.09466, 2025
- [12]
- [13]
-
[14]
J. Hewitt and C. D. Manning. A structural probe for finding syntax in word representations. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, V olume 1 (Long and Short Papers), pages 4129–4138, 2019
work page 2019
-
[15]
S. Jain, J. Beazer, J. A. Ruffolo, A. Bhatnagar, and A. Madani. E1: Retrieval-augmented protein encoder models.bioRxiv, pages 2025–11, 2025
work page 2025
-
[16]
Jülich Supercomputing Centre. JUWELS Cluster and Booster: Exascale Pathfinder with Modular Supercomputing Architecture at Juelich Supercomputing Centre.Journal of large- scale research facilities, 7(A138), 2021. doi: 10.17815/jlsrf-7-183. 11
- [17]
- [18]
- [19]
-
[20]
S. Kornblith, M. Norouzi, H. Lee, and G. Hinton. Similarity of neural network representations revisited. InInternational conference on machine learning, pages 3519–3529. PMlR, 2019
work page 2019
- [21]
-
[22]
Z. Lin, H. Akin, R. Rao, B. Hie, Z. Zhu, W. Lu, N. Smetanin, R. Verkuil, O. Kabeli, Y . Shmueli, et al. Evolutionary-scale prediction of atomic-level protein structure with a language model. Science, 379(6637):1123–1130, 2023
work page 2023
- [23]
- [24]
- [25]
-
[26]
E. Nijkamp, J. A. Ruffolo, E. N. Weinstein, N. Naik, and A. Madani. Progen2: exploring the boundaries of protein language models.Cell systems, 14(11):968–978, 2023
work page 2023
-
[27]
Interpreting GPT: The logit lens, 2020
Nostalgebraist. Interpreting GPT: The logit lens, 2020. URL https://www.lesswrong.com/ posts/AcKRB8wDpdaN6v6ru/interpreting-gpt-the-logit-lens
work page 2020
- [28]
-
[29]
R. Rao, N. Bhattacharya, N. Thomas, Y . Duan, P. Chen, J. Canny, P. Abbeel, and Y . Song. Evaluating protein transfer learning with tape.Advances in Neural Information Processing Systems, 32, 2019
work page 2019
-
[30]
A. Rives, J. Meier, T. Sercu, S. Goyal, Z. Lin, J. Liu, D. Guo, M. Ott, C. L. Zitnick, J. Ma, et al. Biological structure and function emerge from scaling unsupervised learning to 250 million protein sequences.Proceedings of the National Academy of Sciences, 118(15):e2016239118, 2021
work page 2021
-
[31]
N. Saunshi, S. Karp, S. Krishnan, S. Miryoosefi, S. Jakkam Reddi, and S. Kumar. On the inductive bias of stacking towards improving reasoning.Advances in Neural Information Processing Systems, 37:71437–71464, 2024
work page 2024
-
[32]
Layer by Layer: Uncovering Hidden Representations in Language Models
O. Skean, M. R. Arefin, D. Zhao, N. Patel, J. Naghiyev, Y . LeCun, and R. Shwartz-Ziv. Layer by layer: Uncovering hidden representations in language models.arXiv preprint arXiv:2502.02013, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [33]
-
[34]
B. E. Suzek, H. Huang, P. McGarvey, R. Mazumder, and C. H. Wu. Uniref: comprehensive and non-redundant uniprot reference clusters.Bioinformatics, 23(10):1282–1288, 2007. 12
work page 2007
-
[35]
I. Tenney, P. Xia, B. Chen, A. Wang, A. Poliak, R. T. McCoy, N. Kim, B. Van Durme, S. R. Bowman, D. Das, et al. What do you learn from context? probing for sentence structure in contextualized word representations.arXiv preprint arXiv:1905.06316, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[36]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin. Attention is all you need.Advances in Neural Information Processing Systems, 30, 2017
work page 2017
-
[37]
X. Wang, Z. Zheng, F. Ye, D. Xue, S. Huang, and Q. Gu. Diffusion language models are versatile protein learners. InInternational Conference on Machine Learning, pages 52309–52333. PMLR, 2024
work page 2024
-
[38]
X. Wang, Z. Zheng, D. Xue, S. Huang, Q. Gu, et al. Dplm-2: A multimodal diffusion protein language model. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[39]
J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V . Le, D. Zhou, et al. Chain-of- thought prompting elicits reasoning in large language models.Advances in Neural Information Processing Systems, 35:24824–24837, 2022. 13 A Experimental Details In this section, we explain the included PLMs and provide full details of the experiments used in our ...
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.