Causal Foundation Models with Continuous Treatments
Pith reviewed 2026-06-30 21:02 UTC · model grok-4.3
The pith
A transformer meta-learns to reconstruct individual causal response curves across unseen continuous-treatment tasks
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We present the first causal foundation model for the continuous treatment setting. Our model meta-learns the ability to predict causal effects across a wide variety of unseen tasks without additional training or fine-tuning. First, we design a novel prior over data-generating processes with continuous treatment variables in order to generate a rich causal training corpus. We then train a transformer to reconstruct individual treatment-response curves given only observational data, leveraging in-context learning to amortize expensive Bayesian posterior inference. Our model achieves state-of-the-art performance on individual treatment-response curve reconstruction tasks compared to causal mode
What carries the argument
The novel prior over data-generating processes with continuous treatment variables, which generates a training corpus that enables a transformer to perform in-context learning for reconstructing individual treatment-response curves.
If this is right
- A single model suffices for many different continuous-treatment causal problems instead of training one per task.
- The transformer amortizes Bayesian posterior inference over the space of possible data-generating processes.
- Performance on response curve reconstruction exceeds that of models built specifically for each evaluation task.
- The method extends causal foundation modeling beyond binary treatments to continuous ranges.
Where Pith is reading between the lines
- If the prior is broad enough, the same approach could generate foundation models for other causal estimands such as average treatment effects under continuous interventions.
- Real-world testing on observational data from domains like dose-response in medicine would provide a direct check on generalization.
- The technique might reduce computational barriers to applying causal methods in settings where treatments are measured on a continuum.
Load-bearing premise
The novel prior over data-generating processes with continuous treatment variables produces a training corpus sufficiently representative of real-world continuous-treatment scenarios to support generalization to unseen tasks without additional training or fine-tuning.
What would settle it
A real dataset with continuous treatments where the foundation model's curve predictions are less accurate than those produced by a model trained from scratch on that specific dataset.
Figures






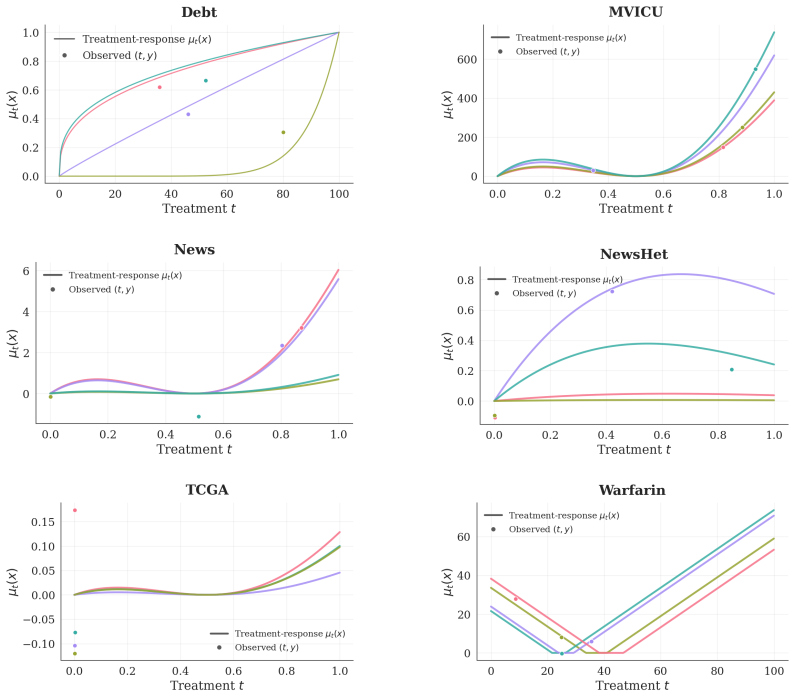


read the original abstract
Causal inference, estimating causal effects from observational data, is a fundamental tool in many disciplines. Of particular importance across a variety of domains is the continuous treatment setting, where the variable of intervention has a continuous range. This setting is far less explored and represents a substantial shift from the binary treatment setting, with models needing to represent effects across a continuum of treatment values. In this paper, we present the first causal foundation model for the continuous treatment setting. Our model meta-learns the ability to predict causal effects across a wide variety of unseen tasks without additional training or fine-tuning. First, we design a novel prior over data-generating processes with continuous treatment variables in order to generate a rich causal training corpus. We then train a transformer to reconstruct individual treatment-response curves given only observational data, leveraging in-context learning to amortize expensive Bayesian posterior inference. Our model achieves state-of-the-art performance on individual treatment-response curve reconstruction tasks compared to causal models which are trained specifically for those tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the first causal foundation model for continuous treatment settings in causal inference. It designs a novel prior over data-generating processes involving continuous treatments to create a synthetic training corpus, then trains a transformer that uses in-context learning to reconstruct individual treatment-response curves from observational data alone, amortizing Bayesian inference. The central empirical claim is that this model achieves state-of-the-art performance on reconstruction tasks for unseen tasks, outperforming causal models trained specifically for those tasks.
Significance. If the empirical claims hold after proper validation, the work would be significant for extending foundation-model approaches to causal inference with continuous treatments, a setting that is less explored than binary treatments. The amortization of posterior inference via in-context learning on a synthetically generated corpus is a potentially valuable direction, provided the prior produces tasks representative enough for zero-shot generalization.
major comments (2)
- [Abstract] Abstract: The state-of-the-art performance claim on individual treatment-response curve reconstruction is asserted without any description of the continuous-treatment prior, the transformer architecture, the evaluation metrics, the baselines, the datasets, or statistical significance testing. This absence makes it impossible to assess whether the data and methods support the claim.
- [Abstract] Abstract: The central generalization claim—that in-context learning on the synthetic corpus transfers to unseen real tasks without fine-tuning—rests on the unverified assumption that the novel prior over DGPs produces a distribution of continuous-treatment effects, confounding structures, and response curves sufficiently close to real-world heterogeneity. No construction details, moment-matching diagnostics, or sensitivity analyses are referenced to support this.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. We address each major comment below and propose revisions where appropriate to strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: The state-of-the-art performance claim on individual treatment-response curve reconstruction is asserted without any description of the continuous-treatment prior, the transformer architecture, the evaluation metrics, the baselines, the datasets, or statistical significance testing. This absence makes it impossible to assess whether the data and methods support the claim.
Authors: We agree that the abstract is concise and does not include specific details on these elements, as is typical for abstracts due to length constraints. However, the manuscript provides full descriptions: the continuous-treatment prior is introduced in Section 3, the transformer architecture in Section 4, evaluation metrics and baselines in Section 5, datasets in Section 5.1, and statistical significance testing in the experimental results. To address this, we will revise the abstract to include brief references to these sections and key elements of the prior and architecture. revision: partial
-
Referee: [Abstract] Abstract: The central generalization claim—that in-context learning on the synthetic corpus transfers to unseen real tasks without fine-tuning—rests on the unverified assumption that the novel prior over DGPs produces a distribution of continuous-treatment effects, confounding structures, and response curves sufficiently close to real-world heterogeneity. No construction details, moment-matching diagnostics, or sensitivity analyses are referenced to support this.
Authors: The construction details of the novel prior are provided in Section 3 of the manuscript, including how it generates a rich variety of DGPs with continuous treatments. We include moment-matching diagnostics comparing synthetic to real data distributions in the supplementary material, and sensitivity analyses in Section 6. These support the representativeness for generalization, as evidenced by the strong performance on held-out real tasks. We can add references to these in the abstract if needed. revision: partial
Circularity Check
No circularity: empirical meta-learning on synthetic corpus from novel prior
full rationale
The paper describes designing a novel prior over DGPs with continuous treatments to generate a training corpus, then training a transformer via in-context learning to reconstruct treatment-response curves. The central claim is an empirical SOTA comparison against task-specific models. No equations, derivations, or self-citations in the abstract reduce any reported performance metric to a fitted quantity on the evaluation data by construction. The representativeness of the prior for real-world generalization is an external assumption about data distribution, not a self-referential reduction in the derivation chain. This is a standard synthetic pretraining setup with no load-bearing self-definition or fitted-input-as-prediction pattern.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The novel prior over data-generating processes with continuous treatment variables generates a rich and representative causal training corpus.
Forward citations
Cited by 1 Pith paper
-
TabPATE: Differentially Private Tabular In-Context Learning Without Public Data
TabPATE applies a PATE-style private aggregation to synthetic tabular queries generated from feature ranges, enabling private in-context learning with near-random membership inference success while keeping competitive...
Reference graph
Works this paper leans on
-
[1]
Alaa and Mihaela van der Schaar
Ahmed M. Alaa and Mihaela van der Schaar. Bayesian inference of individualized treatment effects using multi-task gaussian processes. InProceedings of the 31st International Conference on Neural Information Processing Systems, NIPS’17, page 3427–3435, Red Hook, NY , USA,
-
[2]
ISBN 9781510860964
Curran Associates Inc. ISBN 9781510860964
-
[3]
Susan Athey and Guido W. Imbens. The state of applied econometrics: Causality and policy evaluation.Journal of Economic Perspectives, 31(2):3–32, May 2017. doi: 10.1257/jep.31.2.3. URLhttps://www.aeaweb.org/articles?id=10.1257/jep.31.2.3
-
[4]
Cresswell, and Rahul G
Vahid Balazadeh, Hamidreza Kamkari, Valentin Thomas, Benson Li, Junwei Ma, Jesse C. Cresswell, and Rahul G. Krishnan. CausalPFN: Amortized Causal Effect Estimation via In-Context Learning. InAdvances in Neural Information Processing Systems, volume 38, 2025
2025
-
[5]
EconML: A Python Package for ML-Based Heterogeneous Treatment Effects Estimation
Keith Battocchi, Eleanor Dillon, Maggie Hei, Greg Lewis, Paul Oka, Miruna Oprescu, and Vasilis Syrgkanis. EconML: A Python Package for ML-Based Heterogeneous Treatment Effects Estimation. https://github.com/py-why/EconML, 2019. Version 0.15.0
2019
-
[6]
Estimating the effects of continuous- valued interventions using generative adversarial networks
Ioana Bica, James Jordon, and Mihaela van der Schaar. Estimating the effects of continuous- valued interventions using generative adversarial networks. InAdvances in Neural Information Processing Systems, volume 33, pages 16434–16445, 2020
2020
-
[7]
Charles, D
Léon Bottou, Jonas Peters, Joaquin Quiñonero-Candela, Denis X. Charles, D. Max Chickering, Elon Portugaly, Dipankar Ray, Patrice Simard, and Ed Snelson. Counterfactual reasoning and learning systems: The example of computational advertising.Journal of Machine Learning Research, 14(101):3207–3260, 2013. URL http://jmlr.org/papers/v14/bottou13a. html
2013
-
[8]
Causal data augmentation for robust fine-tuning of tabular foundation models.arXiv:2601.04110, 2026
Magnus Bühler, Lennart Purucker, and Frank Hutter. Causal data augmentation for robust fine-tuning of tabular foundation models.arXiv:2601.04110, 2026
- [9]
-
[10]
The Econometrics Journal , volume =
Victor Chernozhukov, Denis Chetverikov, Mert Demirer, Esther Duflo, Christian Hansen, Whitney Newey, and James Robins. Double/debiased machine learning for treatment and structural parameters.The Econometrics Journal, 21(1), 2018. doi: 10.1111/ectj.12097
-
[11]
Dehejia and Sadek Wahba
Rajeev H. Dehejia and Sadek Wahba. Causal effects in nonexperimental studies: Reevaluating the evaluation of training programs.Journal of the American Statistical Association, 94(448): 1053–1062, 1999
1999
-
[12]
Automated versus do-it-yourself methods for causal inference: Lessons learned from a data analysis competition
Vincent Dorie, Jennifer Hill, Uri Shalit, Marc Scott, and Dan Cervone. Automated versus do-it-yourself methods for causal inference: Lessons learned from a data analysis competition. Statistical Science, 34(1):43–68, 2019
2019
-
[13]
A large scale benchmark for uplift modeling
Eustache Diemert, Artem Betlei, Christophe Renaudin, and Amini Massih-Reza. A large scale benchmark for uplift modeling. InProceedings of the AdKDD and TargetAd Workshop, KDD, London,United Kingdom, August, 20, 2018. ACM, 2018
2018
-
[14]
Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio
Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. InAdvances in Neural Information Processing Systems, volume 27, 2014
2014
-
[15]
Gordon, Florian Zettelmeyer, Neha Bhargava, and Dan Chapsky
Brett R. Gordon, Florian Zettelmeyer, Neha Bhargava, and Dan Chapsky. A comparison of approaches to advertising measurement: Evidence from big field experiments at facebook. Marketing Science, 38(2):193–225, 2019
2019
-
[17]
TabPFN-2.5: Advancing the State of the Art in Tabular Foundation Models
Léo Grinsztajn, Klemens Flöge, Oscar Key, Felix Birkel, Philipp Jund, Brendan Roof, Benjamin Jäger, Dominik Safaric, Simone Alessi, Adrian Hayler, Mihir Manium, Rosen Yu, Felix Jablon- ski, Shi Bin Hoo, Anurag Garg, Jake Robertson, Magnus Bühler, Vladyslav Moroshan, Lennart Purucker, Clara Cornu, Lilly Charlotte Wehrhahn, Alessandro Bonetto, Bernhard Schö...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[18]
Minethatdata e-mail analytics and data mining challenge
Kevin Hillstrom. Minethatdata e-mail analytics and data mining challenge. https://blog. minethatdata.com/2008/03/minethatdata-e-mail-analytics-and-data.html , March 2008
2008
-
[19]
Imbens.The Propensity Score with Continuous Treatments, chapter 7, pages 73–84
Keisuke Hirano and Guido W. Imbens.The Propensity Score with Continuous Treatments, chapter 7, pages 73–84. John Wiley & Sons, Ltd, 2004. ISBN 9780470090459. doi: https: //doi.org/10.1002/0470090456.ch7
-
[20]
Keisuke Hirano and Guido W. Imbens. The propensity score with continuous treatments. In Andrew Gelman and Xiao-Li Meng, editors,Applied Bayesian Modeling and Causal Inference from Incomplete-Data Perspectives, pages 73–84. Wiley, 2004
2004
-
[21]
Paul W. Holland. Statistics and causal inference.Journal of the American Statistical Association, 81(396):945–960, 1986. ISSN 01621459, 1537274X
1986
-
[22]
TabPFN: A transformer that solves small tabular classification problems in a second
Noah Hollmann, Samuel Müller, Katharina Eggensperger, and Frank Hutter. TabPFN: A transformer that solves small tabular classification problems in a second. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[23]
causaldata: Example data sets for causal inference textbooks, 2024
Nick Huntington-Klein. causaldata: Example data sets for causal inference textbooks, 2024. URLhttps://pypi.org/project/causaldata/. Python package
2024
-
[24]
International Warfarin Pharmacogenetics Consortium. Estimation of the warfarin dose with clinical and pharmacogenetic data.New England Journal of Medicine, 360(8):753–764, 2009. doi: 10.1056/NEJMoa0809329
-
[25]
Policy evaluation and optimization with continuous treatments
Nathan Kallus and Angela Zhou. Policy evaluation and optimization with continuous treatments. InProceedings of the Twenty-First International Conference on Artificial Intelligence and Statistics, volume 84 ofProceedings of Machine Learning Research, pages 1243–1251, 09–11 Apr 2018
2018
-
[26]
IBM causal inference benchmarking framework, January 2018
Ehud Karavani, Yishai Shimoni, and Chen Yanover. IBM causal inference benchmarking framework, January 2018. URLhttps://doi.org/10.5281/zenodo.1163587
-
[27]
Causal-curve: a python causal inference package to estimate causal dose- response curves.Journal of Open Source Software, 5(52):2523, 2020
Roni W Kobrosly. Causal-curve: a python causal inference package to estimate causal dose- response curves.Journal of Open Source Software, 5(52):2523, 2020
2020
-
[28]
https://doi.org/10.1073/pnas.1804597116 Publisher: Proceedings of the National Academy of Sciences
Sören R. Künzel, Jasjeet S. Sekhon, Peter J. Bickel, and Bin Yu. Metalearners for estimating heterogeneous treatment effects using machine learning.Proceedings of the National Academy of Sciences, 116(10):4156–4165, 2019. doi: 10.1073/pnas.1804597116
-
[29]
BIGTARGET Hackathon Dataset, 2020
Lenta and Microsoft. BIGTARGET Hackathon Dataset, 2020. URL https://www.kaggle. com/datasets/mrmorj/bigtarget
2020
-
[30]
Bayesian causal inference: A critical review.Philo- sophical Transactions of the Royal Society A, 381(2247):20220153, 2023
Fan Li, Peng Ding, and Fabrizia Mealli. Bayesian causal inference: A critical review.Philo- sophical Transactions of the Royal Society A, 381(2247):20220153, 2023
2023
-
[31]
Generalization can emerge in tabular foundation models from a single table.arXiv:2511.09665, 2025
Junwei Ma, Nour Shaheen, Alex Labach, Amine Mhedhbi, Frank Hutter, Anthony L Caterini, and Valentin Thomas. Generalization can emerge in tabular foundation models from a single table.arXiv:2511.09665, 2025
-
[32]
Cresswell, Keyvan Golestan, Guangwei Yu, Anthony L
Junwei Ma, Valentin Thomas, Rasa Hosseinzadeh, Alex Labach, Hamidreza Kamkari, Jesse C. Cresswell, Keyvan Golestan, Guangwei Yu, Anthony L. Caterini, and Maksims V olkovs. Tab- DPT: Scaling Tabular Foundation Models on Real Data. InAdvances in Neural Information Processing Systems, 2025. 13
2025
-
[33]
Foundation models for causal inference via prior-data fitted networks
Yuchen Ma, Dennis Frauen, Emil Javurek, and Stefan Feuerriegel. Foundation models for causal inference via prior-data fitted networks. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[34]
An end-to-end pipeline for Causal ML with continuous treatments: An application to financial decision making
Javier Moral Hernández, Clara Higuera-Cabañes, and Álvaro Ibraín. An end-to-end pipeline for Causal ML with continuous treatments: An application to financial decision making. In3rd Workshop on Causal Inference and Machine Learning in Practice, 2025
2025
-
[35]
Course Lecture Notes, 2020
Brady Neal.Introduction to Causal Inference from a Machine Learning Perspective. Course Lecture Notes, 2020. URL https://www.bradyneal.com/Introduction_to_Causal_ Inference-Dec17_2020-Neal.pdf
2020
-
[36]
Realcause: Realistic causal inference benchmarking.CoRR, abs/2011.15007, 2020
Brady Neal, Chin-Wei Huang, and Sunand Raghupathi. RealCause: Realistic Causal Inference Benchmarking, 2021. URLhttps://arxiv.org/abs/2011.15007
-
[37]
VCNet and Functional Targeted Regulariza- tion For Learning Causal Effects of Continuous Treatments
Lizhen Nie, Mao Ye, Qiang Liu, and Dan Nicolae. VCNet and Functional Targeted Regulariza- tion For Learning Causal Effects of Continuous Treatments. InInternational Conference on Learning Representations, 2021
2021
-
[38]
Arman Oganisian and Jason A. Roy. A practical introduction to Bayesian estimation of causal effects: Parametric and nonparametric approaches.Statistics in Medicine, 40(2):518–551, 2021
2021
-
[39]
TabICL: A Tabular Foundation Model for In-Context Learning on Large Data
Jingang Qu, David Holzmüller, Gaël Varoquaux, and Marine Le Morvan. TabICL: A Tabular Foundation Model for In-Context Learning on Large Data. InProceedings of the 42nd Inter- national Conference on Machine Learning, volume 267 ofProceedings of Machine Learning Research, pages 50817–50847, 13–19 Jul 2025
2025
-
[40]
TabICLv2: A better, faster, scalable, and open tabular foundation model.arXiv:2602.11139, 2026
Jingang Qu, David Holzmüller, Gaël Varoquaux, and Marine Le Morvan. TabICLv2: A better, faster, scalable, and open tabular foundation model.arXiv:2602.11139, 2026
-
[41]
Do-PFN: In-Context Learning for Causal Effect Estimation
Jake Robertson, Arik Reuter, Siyuan Guo, Noah Hollmann, Frank Hutter, and Bernhard Schölkopf. Do-PFN: In-Context Learning for Causal Effect Estimation. InAdvances in Neural Information Processing Systems, 2025
2025
-
[42]
Donald B. Rubin. Bayesianly justifiable and relevant frequency calculations for the applied statistician.The Annals of Statistics, pages 1151–1172, 1984
1984
-
[43]
Patrick Schwab, Lorenz Linhardt, Stefan Bauer, Joachim M. Buhmann, and Walter Karlen. Learning counterfactual representations for estimating individual dose-response curves.Pro- ceedings of the AAAI Conference on Artificial Intelligence, 34(04):5612–5619, 2020. ISSN 2159-5399. doi: 10.1609/aaai.v34i04.6014
-
[44]
Johansson, and David Sontag
Uri Shalit, Fredrik D. Johansson, and David Sontag. Estimating individual treatment effect: generalization bounds and algorithms. In Doina Precup and Yee Whye Teh, editors,Proceedings of the 34th International Conference on Machine Learning, volume 70 ofProceedings of Machine Learning Research, pages 3076–3085. PMLR, 06–11 Aug 2017. URL https:// proceedin...
2017
-
[45]
scikit-uplift: Uplift modeling in scikit-learn style, 2020
Maksim Shevchenko and contributors. scikit-uplift: Uplift modeling in scikit-learn style, 2020. URLhttps://github.com/maks-sh/scikit-uplift
2020
-
[46]
Self-supervised representation learning from random data projectors
Yi Sui, Tongzi Wu, Jesse Cresswell, Ga Wu, George Stein, Xiaoshi Huang, Xiaochen Zhang, and Maksims V olkovs. Self-supervised representation learning from random data projectors. In International Conference on Learning Representations, 2024
2024
-
[47]
Entropy balancing for continuous treatments.Journal of Econometric Methods, 11(1):71–89, 2022
Stefan Tübbicke. Entropy balancing for continuous treatments.Journal of Econometric Methods, 11(1):71–89, 2022. doi: doi:10.1515/jem-2021-0002
-
[48]
Attention is all you need
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neural Informa- tion Processing Systems, 2017
2017
-
[49]
Generalization bounds for estimating causal effects of continuous treatments
Xin Wang, Shengfei Lyu, Xingyu Wu, Tianhao Wu, and Huanhuan Chen. Generalization bounds for estimating causal effects of continuous treatments. InAdvances in Neural Information Processing Systems, volume 35, pages 8605–8617, 2022. 14
2022
-
[50]
M. Whirl-Carrillo, R. Huddart, L. Gong, K. Sangkuhl, C. F. Thorn, R. Whaley, and T. E. Klein. An evidence-based framework for evaluating pharmacogenomics knowledge for personalized medicine.Clinical Pharmacology & Therapeutics, 110(3):563–572, 2021. doi: 10.1002/cpt. 2350
work page doi:10.1002/cpt 2021
-
[51]
lgbm", "xgboost
X5 Retail Group and ODS.ai. X5 RetailHero Uplift Modeling Dataset, 2019. URL https: //ods.ai/competitions/x5-retailhero-uplift-modeling. 15 A Further Details About Benchmarks and Baselines A.1 Synthetic and Semi-Synthetic Data Scenarios Each subclass ofScenarioat minimum implements the following three methods: •load_covariates : Generates the base covaria...
2019
-
[52]
It is possible that there is no local csv, and the covariates will have to be downloaded in the script itself (e.g
Ask the user which ‘csv‘ file to use as the base covariates ‘X‘. It is possible that there is no local csv, and the covariates will have to be downloaded in the script itself (e.g. using sklearn.datasets). You can download and view the covariates now, so that you have intuition for the context
-
[53]
what do the base covariates ‘X‘ represent in this dataset?
Ask the user for covariate context, i.e. what do the base covariates ‘X‘ represent in this dataset?
-
[54]
what scenario the user has in mind for the treatment and outcomes
Ask the user for treatment and outcome context, i.e. what scenario the user has in mind for the treatment and outcomes
-
[55]
Remember, the treatment variable should be continuous, *not* binary
Based on the information provided in steps 1 - 3, devise a *realistic* DGP to simulate treatment assignment and outcomes. Remember, the treatment variable should be continuous, *not* binary. This DGP should satisfy the following requirements:
-
[56]
There should be a high degree of confounding: at least 50% of the covariates should be causes of both the treatment and the outcome
-
[57]
This should be a suitably complex and realistic function which can be implemented in simple Python code
You should generate a *dose-response function* f(X, t) that maps an individual with covariates X and hypothetical treatment t to the *conditional expected 19 potential outcome (CEPO)*. This should be a suitably complex and realistic function which can be implemented in simple Python code
-
[58]
This should be a suitably complex and realistic function which can be implemented in simple Python code
You should generate a *treatment assignment function* T(X) that maps an individual with covariates X to the *observed* treatment T(X). This should be a suitably complex and realistic function which can be implemented in simple Python code
-
[59]
In order to ensure that there is a high degree of confounding, the functions f and T should both depend on some subset of covariates comprising at least half of the total number of covariate features
-
[60]
Once you have constructed this DGP, generate a *Python script* that outputs a csv file as follows:
-
[61]
Ask the user for the desired name of the Python script
-
[62]
The Python script should include code for the dose-response function f(X, t) and the treatment assignment function T(X)
-
[63]
The data should be filled as follows:
The Python script should output a single csv file with columns named x_0 through x_n (where n is the number of covariate features), t, y, t_test, cepo_test. The data should be filled as follows:
-
[64]
The values of columns x_0 through x_n should be the values of the original base covariates csv
-
[65]
The value of t should be the value of T(X) for X the corresponding covariate value
-
[66]
The value of y should be f(X, t) for X the corresponding covariate value and t = T(X), *plus Gaussian noise* which is iid for each row
-
[67]
The value of t_test should be randomly sampled from [t_min, t_max]
-
[68]
The value of cepo_test should be f(X, t_test)
-
[69]
string-based categorical variables should be encoded as integers)
All data should be numerical (e.g. string-based categorical variables should be encoded as integers)
-
[70]
When you are ready to proceed with this task, begin at step 1 above
Save the python script in tracee/inference/benchmarks/data_generation_scripts. When you are ready to proceed with this task, begin at step 1 above. System Prompt for Generating Synthetic Validation Data #2 #Semi-synthetic data generation instructions ##Background You are working on a project in causal inference. The goal is to train a model to perform cau...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.