Fine-tuning MLIP foundation models: strategies for accuracy and transferability
Pith reviewed 2026-06-27 07:36 UTC · model grok-4.3
The pith
Foundation model quality and hyperparameters matter more than fine-tuning method, but only multihead replay preserves out-of-distribution robustness.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
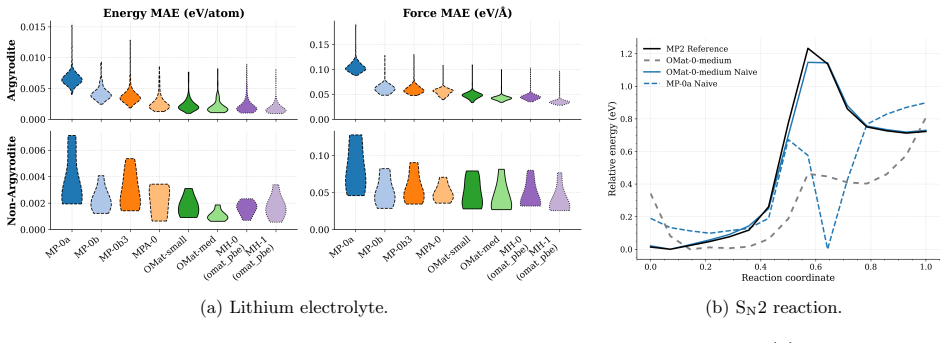
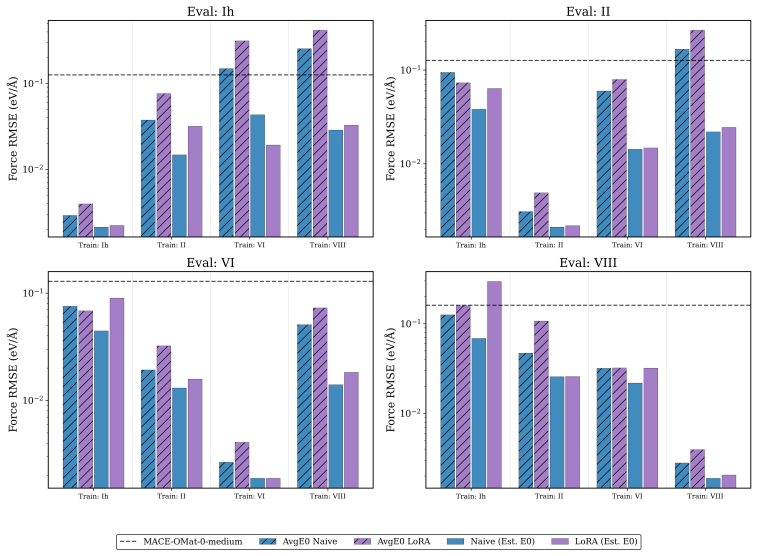
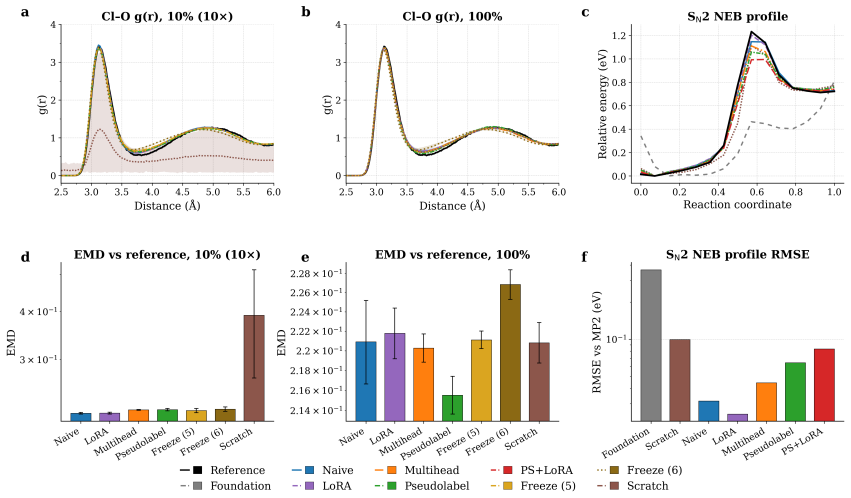
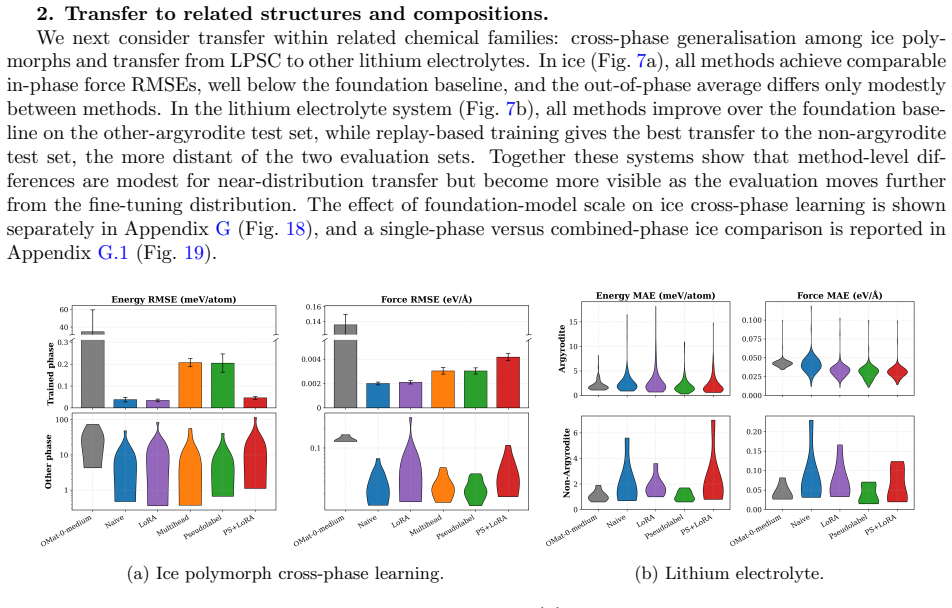
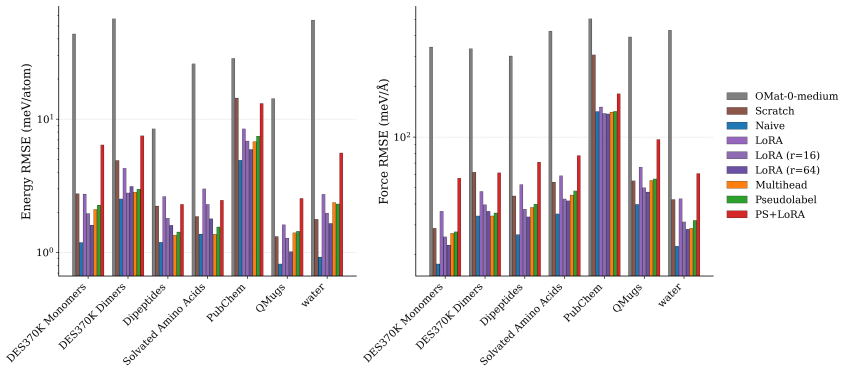
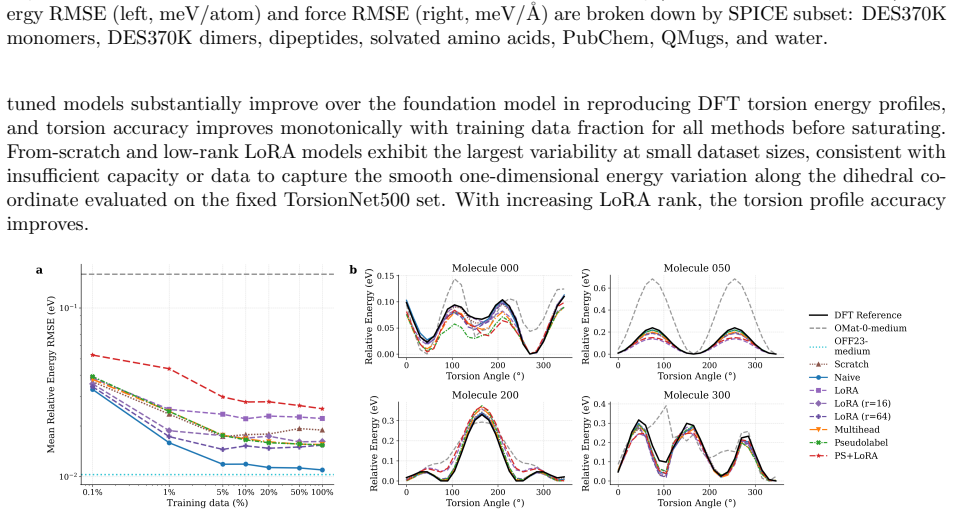
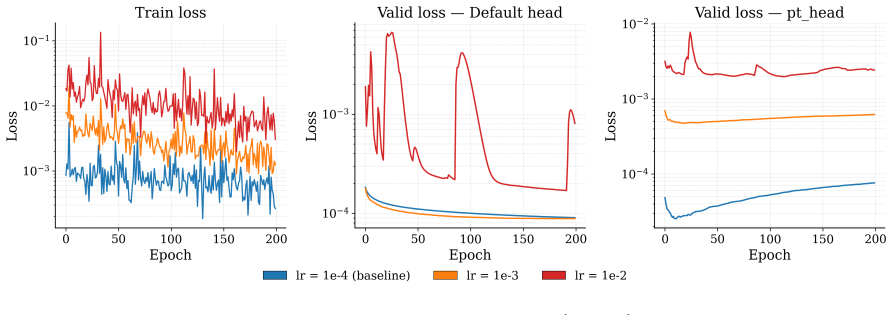
Foundation model quality, correct E0 initialisation, and well-chosen hyperparameters are prerequisites whose impact routinely exceeds that of the fine-tuning strategy itself. Once these prerequisites are met, most strategies achieve strong target-task accuracy, consistently surpassing models trained from scratch. The practical distinction depends on deployment scope: naive fine-tuning offers the best convergence for single-system applications, while multihead replay -- with either original or pseudolabelled data -- is the only approach tested that consistently preserves out-of-distribution robustness, maintaining both pretraining-distribution accuracy for broader deployment and many-body sho
What carries the argument
Comparison of seven fine-tuning strategies (naive full-parameter updates, layer freezing, LoRA for equivariant layers, multihead replay, pseudolabelled replay, and replay plus LoRA) implemented in MACE and tested across benchmarks spanning aqueous NaCl, ice, SN2 reactions, biomolecules, and electrolytes.
If this is right
- Naive fine-tuning gives fastest convergence when the goal is accuracy on one target system only.
- Multihead replay maintains accuracy on the original pretraining distribution for models intended for wider use.
- Pseudolabelled replay achieves similar robustness without needing the original pretraining corpus.
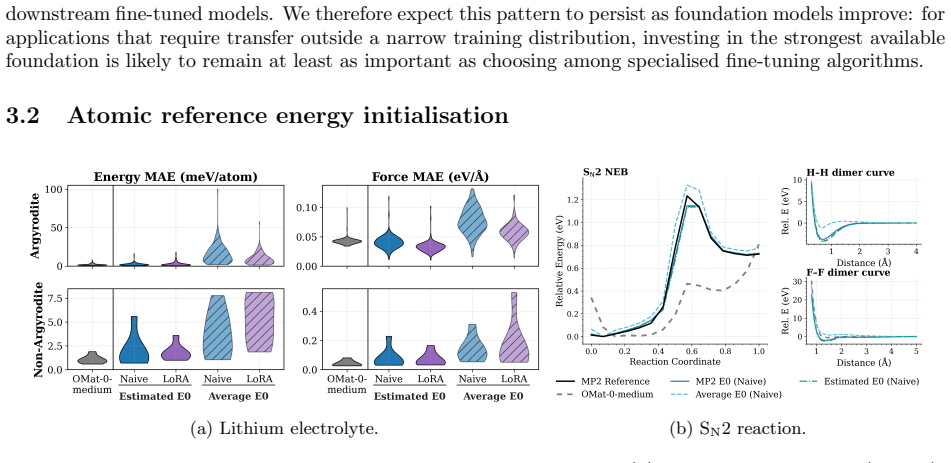
- Proper model-aware E0 reestimation improves all fine-tuning workflows.
- Equivariant LoRA enables parameter-efficient adaptation without breaking message-passing structure.
Where Pith is reading between the lines
- The same prerequisite emphasis may apply when fine-tuning other equivariant architectures.
- Resources spent improving foundation models could yield larger gains than refining adaptation methods.
- Extending the replay approach to longer-range interactions or periodic systems would test its generality.
- The decoupling of replay data via pseudolabelling opens the possibility of using synthetic data for continual learning.
Load-bearing premise
The five chemically diverse benchmarks sufficiently represent the range of chemical environments where fine-tuning robustness matters.
What would settle it
A new benchmark or deployment setting in which multihead replay loses out-of-distribution accuracy or short-range repulsion while naive fine-tuning succeeds would falsify the reported distinction between strategies.
Figures





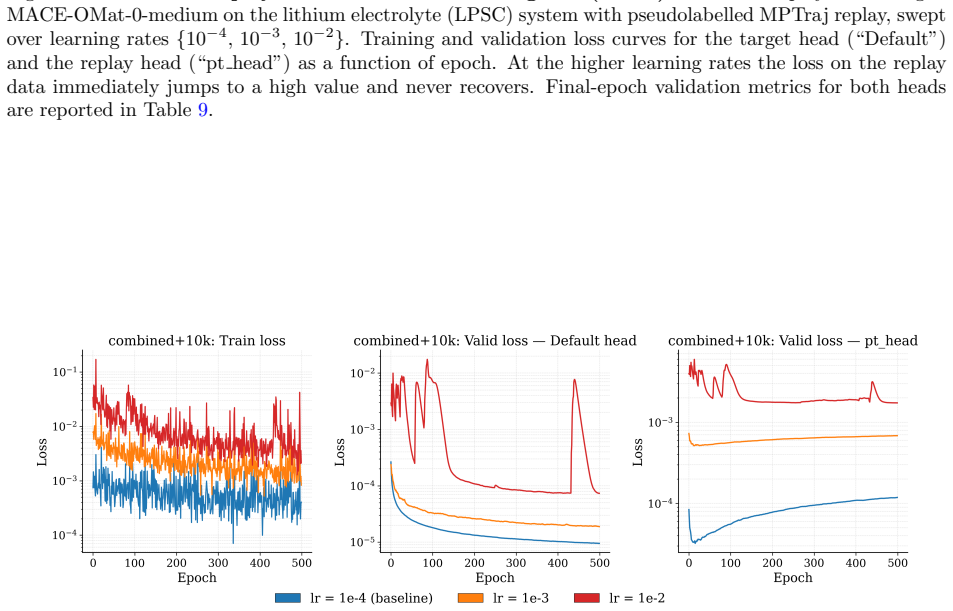
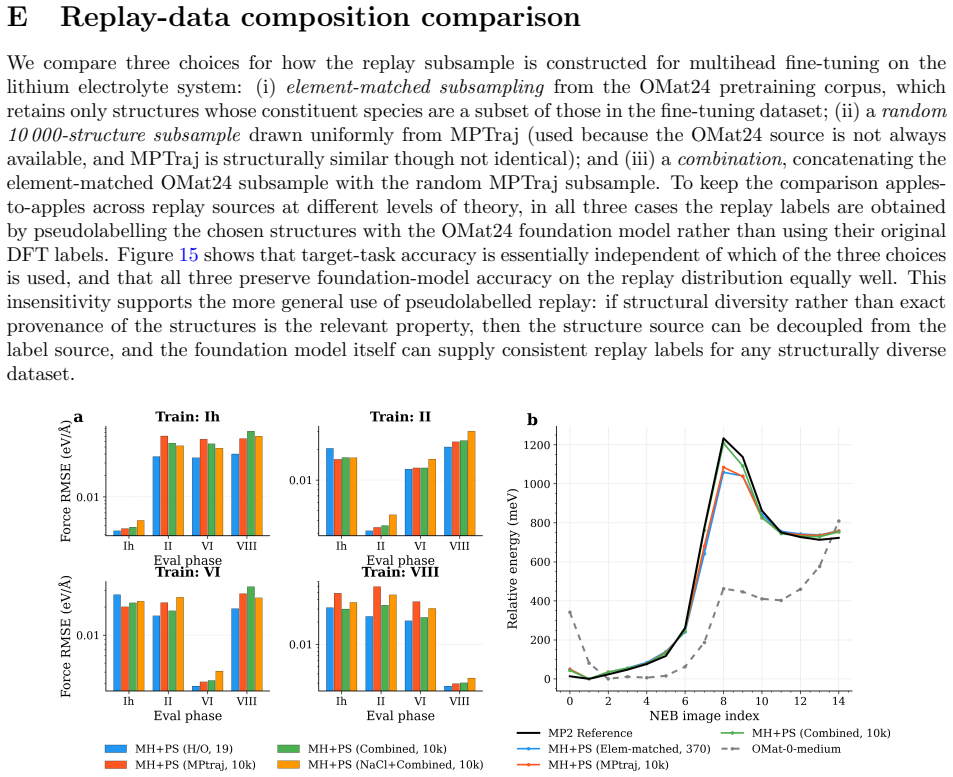
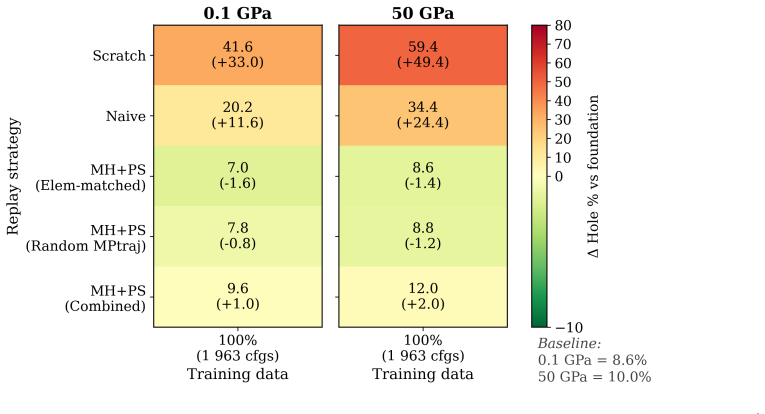
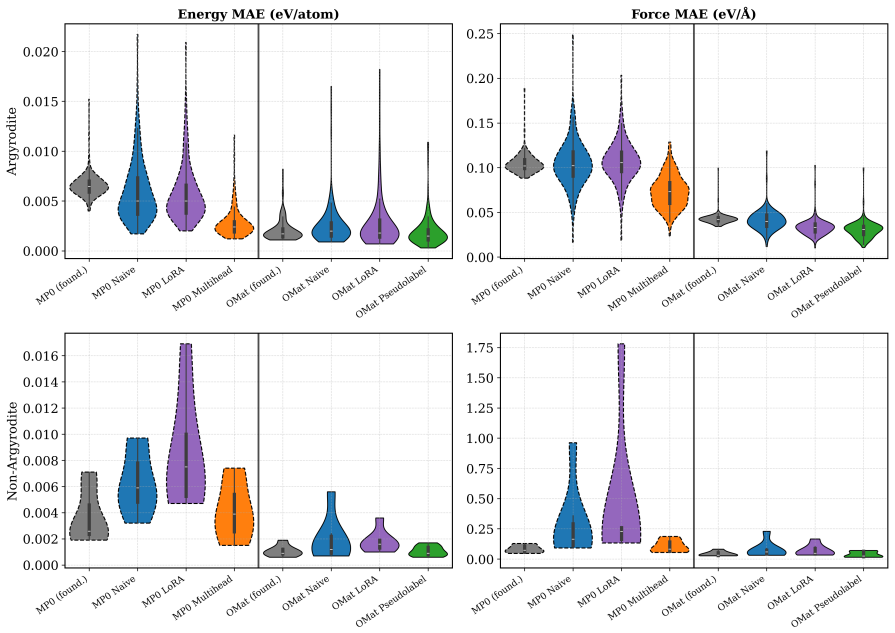



read the original abstract
Adapting machine-learned interatomic potential (MLIP) foundation models to specialised tasks through fine-tuning is an increasingly important practice, yet systematic guidance on when and how to fine-tune is currently limited. We evaluate seven fine-tuning strategies -- naive full-parameter updates, two layer-freezing variants, Low-Rank Adaptation (LoRA), multihead replay, pseudolabelled replay, and replay combined with LoRA -- across five chemically diverse benchmarks (aqueous NaCl, ice polymorphs, S$_\mathrm{N}$2 reactions, SPICE biomolecules, and lithium electrolytes), three generations of foundation models, and training sets spanning five orders of magnitude. To support this evaluation we implement three capabilities in the MACE codebase: LoRA adapted for equivariant message-passing architectures, including both scalar and equivariant linear layers; pseudolabelled replay, which decouples the replay data source from the original pretraining corpus; and model-aware atomic reference energy (E0) reestimation for fine-tuning workflows. We find that foundation model quality, correct E0 initialisation, and well-chosen hyperparameters are prerequisites whose impact routinely exceeds that of the fine-tuning strategy itself. Once these prerequisites are met, most strategies achieve strong target-task accuracy, consistently surpassing models trained from scratch. The practical distinction depends on deployment scope: naive fine-tuning offers the best convergence for single-system applications, while multihead replay -- with either original or pseudolabelled data -- is the only approach tested that consistently preserves out-of-distribution robustness, maintaining both pretraining-distribution accuracy for broader deployment and many-body short-range repulsion.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript evaluates seven fine-tuning strategies (naive full-parameter, layer-freezing variants, LoRA, multihead replay, pseudolabelled replay, and replay+LoRA) for MLIP foundation models across five chemically diverse benchmarks (aqueous NaCl, ice polymorphs, SN2 reactions, SPICE biomolecules, lithium electrolytes), three model generations, and training-set sizes spanning five orders of magnitude. It reports that foundation-model quality, correct E0 initialization, and hyperparameter choice are prerequisites whose impact exceeds that of strategy choice; once met, most strategies achieve strong target-task accuracy (surpassing from-scratch training), while only multihead replay (original or pseudolabelled) consistently preserves out-of-distribution robustness and many-body short-range repulsion.
Significance. If the central empirical findings hold after addressing the noted concerns, the work supplies practical, deployment-scope-dependent guidance for fine-tuning MLIPs and contributes three reusable capabilities (equivariant LoRA, pseudolabelled replay, model-aware E0 reestimation) to the open MACE codebase. The scale of the benchmarking (multiple models, benchmarks, and data regimes) strengthens the evidence base for when naive fine-tuning suffices versus when replay is required.
major comments (2)
- [Methods (LoRA adaptation)] Methods section describing the LoRA implementation for equivariant message-passing: the manuscript states that LoRA was adapted for both scalar and equivariant linear layers but provides no explicit verification (e.g., numerical tests of energy invariance or force covariance under SO(3) rotations, or weight-tying arguments) that the adaptation preserves the underlying equivariance. Because the central ranking of strategies includes LoRA variants, any symmetry-breaking artifact would confound the attribution of performance differences to the replay versus naive distinction.
- [Results (prerequisite impact)] Results section on prerequisite versus strategy impact: the claim that model quality, E0 initialization, and hyperparameters routinely exceed strategy effects is load-bearing for the practical recommendations, yet the manuscript does not report quantitative effect-size comparisons (e.g., variance partitioning or ablation tables) across the five-order-of-magnitude training-size range that would allow readers to assess the relative magnitudes directly.
minor comments (2)
- [Abstract] Abstract: the chemical formula notation S$_ ext{N}$2 may not render consistently; standard subscript formatting (S_N2) would improve clarity.
- [Benchmark description] The five benchmarks are chemically diverse, but the manuscript could briefly note any chemical environments (e.g., transition-metal catalysis or extended solids) that remain outside the tested scope to help readers gauge transferability limits.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive feedback on our manuscript. We address each major comment below, proposing revisions to strengthen the work where appropriate while maintaining the integrity of our empirical findings.
read point-by-point responses
-
Referee: Methods (LoRA adaptation)] Methods section describing the LoRA implementation for equivariant message-passing: the manuscript states that LoRA was adapted for both scalar and equivariant linear layers but provides no explicit verification (e.g., numerical tests of energy invariance or force covariance under SO(3) rotations, or weight-tying arguments) that the adaptation preserves the underlying equivariance. Because the central ranking of strategies includes LoRA variants, any symmetry-breaking artifact would confound the attribution of performance differences to the replay versus naive distinction.
Authors: We agree that explicit verification of equivariance preservation would strengthen the manuscript and eliminate any potential concern about symmetry-breaking artifacts. Although the LoRA adaptation applies low-rank updates to the weights of both scalar and equivariant linear layers while preserving the tensorial structure of the message-passing operations (thereby maintaining equivariance by construction), we will add numerical tests in the revised Methods section. These will demonstrate that energies remain invariant and forces transform covariantly under random SO(3) rotations for models employing the equivariant LoRA implementation. This addition will directly address the referee's concern without altering our reported results. revision: yes
-
Referee: Results (prerequisite impact)] Results section on prerequisite versus strategy impact: the claim that model quality, E0 initialization, and hyperparameters routinely exceed strategy effects is load-bearing for the practical recommendations, yet the manuscript does not report quantitative effect-size comparisons (e.g., variance partitioning or ablation tables) across the five-order-of-magnitude training-size range that would allow readers to assess the relative magnitudes directly.
Authors: We acknowledge that while our conclusions are based on consistent patterns observed across all five benchmarks, three model generations, and the full range of training-set sizes, we did not include formal quantitative effect-size comparisons such as variance partitioning. To enable readers to directly assess relative magnitudes, we will add an ablation table (or supplementary figure) in the revised Results section that reports mean absolute errors for variations in foundation-model quality, E0 initialization, and hyperparameters versus those arising from fine-tuning strategy choice, stratified by training-set size. This will provide the requested quantitative support for our claim that prerequisite factors routinely dominate strategy effects. revision: yes
Circularity Check
Empirical benchmarking study with no circular derivations or self-referential predictions
full rationale
The paper is a comparative empirical study evaluating seven fine-tuning strategies on five benchmarks using implemented extensions to the MACE codebase. No equations, predictions, or first-principles derivations are presented that reduce to fitted parameters or prior results by construction. Central claims rest on direct performance comparisons (target accuracy and OOD robustness) rather than any self-definitional, fitted-input, or self-citation load-bearing steps. Self-citations to prior MACE work are present but not invoked to justify uniqueness theorems or ansatzes that would create circularity; the evaluation is externally falsifiable via the reported benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- hyperparameters for fine-tuning
axioms (1)
- domain assumption Equivariant message-passing architectures require adapted LoRA for both scalar and equivariant layers
Forward citations
Cited by 1 Pith paper
-
Universal Interatomic Potentials as Configuration-Space Generators for One-Shot and Iterative Fine-Tuning of Ab Initio-Accurate Material-Specific Models
Universal MLIPs serve as configuration generators whose DFT-relabeled subsamples enable one-shot or iterative training of material-specific MLIPs that recover accurate reactive energy profiles with 600-2000 DFT calculations.
Reference graph
Works this paper leans on
-
[1]
Batatia, I.et al.A foundation model for atomistic materials chemistry (2025). URLhttps://arxiv. org/abs/2401.00096.2401.00096
Pith/arXiv arXiv 2025
-
[2]
URLhttps://doi.org/10.1038/ s42256-023-00716-3
Deng, B.et al.CHGNet as a pretrained universal neural network potential for charge-informed atom- istic modelling.Nature Machine Intelligence5, 1031–1041 (2023). URLhttps://doi.org/10.1038/ s42256-023-00716-3
2023
-
[3]
M.et al.Uma: A family of universal models for atoms (2026)
Wood, B. M.et al.Uma: A family of universal models for atoms (2026). URLhttps://arxiv.org/ abs/2506.23971.2506.23971
arXiv 2026
-
[4]
URL https://doi.org/10.1038/s41586-023-06735-9
Merchant, A.et al.Scaling deep learning for materials discovery.Nature624, 80–85 (2023). URL https://doi.org/10.1038/s41586-023-06735-9
-
[5]
URLhttps://arxiv.org/ abs/2410.22570.2410.22570
Neumann, M.et al.Orb: A fast, scalable neural network potential (2024). URLhttps://arxiv.org/ abs/2410.22570.2410.22570
arXiv 2024
-
[6]
Park, Y., Kim, J., Hwang, S. & Han, S. Scalable parallel algorithm for graph neural network interatomic potentials in molecular dynamics simulations.Journal of Chemical Theory and Computation20, 4857– 4868 (2024). URLhttps://doi.org/10.1021/acs.jctc.4c00190. PMID: 38813770,https://doi. org/10.1021/acs.jctc.4c00190. 21
-
[7]
URLhttps://arxiv.org/abs/2510.25380.2510
Batatia, I.et al.Cross learning between electronic structure theories for unifying molecular, surface, and inorganic crystal foundation force fields (2025). URLhttps://arxiv.org/abs/2510.25380.2510. 25380
arXiv 2025
-
[8]
T.et al.Machine learning force fields.Chemical Reviews121, 10142–10186 (2021)
Unke, O. T.et al.Machine learning force fields.Chemical Reviews121, 10142–10186 (2021). URL https://doi.org/10.1021/acs.chemrev.0c01111. PMID: 33705118
-
[9]
Behler, J. Four generations of high-dimensional neural network potentials.Chemical Reviews121, 10037–10072 (2021). URLhttps://doi.org/10.1021/acs.chemrev.0c00868. PMID: 33779150, https://doi.org/10.1021/acs.chemrev.0c00868
-
[10]
S., Nebgen, B., Lubbers, N., Isayev, O
Smith, J. S., Nebgen, B., Lubbers, N., Isayev, O. & Roitberg, A. E. Less is more: Sampling chemical space with active learning.The Journal of Chemical Physics148, 241733 (2018). URLhttps://doi. org/10.1063/1.5023802.https://pubs.aip.org/aip/jcp/article-pdf/doi/10.1063/1.5023802/ 16656391/241733_1_online.pdf
work page doi:10.1063/1.5023802.https://pubs.aip.org/aip/jcp/article-pdf/doi/10.1063/1.5023802/ 2018
-
[11]
Schran, C., Brezina, K. & Marsalek, O. Committee neural network potentials control generalization errors and enable active learning.The Journal of Chemical Physics153(2020). URLhttp://dx.doi. org/10.1063/5.0016004
-
[12]
URLhttps://arxiv.org/abs/2405.20217.2405.20217
Kaur, H.et al.Data-efficient fine-tuning of foundational models for first-principles quality sublimation enthalpies (2024). URLhttps://arxiv.org/abs/2405.20217.2405.20217
arXiv 2024
-
[13]
Sci.16, 11419–11433 (2025)
Della Pia, F.et al.Accurate and efficient machine learning interatomic potentials for finite temperature modelling of molecular crystals.Chem. Sci.16, 11419–11433 (2025). URLhttp://dx.doi.org/10. 1039/D5SC01325A
2025
-
[14]
URLhttps://arxiv.org/abs/2503.14118.2503.14118
Mazitov, A.et al.Pet-mad, a lightweight universal interatomic potential for advanced materials modeling (2025). URLhttps://arxiv.org/abs/2503.14118.2503.14118
arXiv 2025
-
[15]
Radova, M., Stark, W. G., Allen, C. S., Maurer, R. J. & Bart´ ok, A. P. Fine-tuning foundation models of materials interatomic potentials with frozen transfer learning (2025). URLhttps://arxiv.org/abs/ 2502.15582.2502.15582
arXiv 2025
-
[16]
Wang, R., Gao, Y., Wu, H. & Zhong, Z. Pre-training, fine-tuning, and distillation (pfd): Automatically generating machine learning force fields from universal models.Physical Review Materials9(2025). URLhttp://dx.doi.org/10.1103/sbz6-btz8
-
[17]
E., Lyons, J
Turiansky, M. E., Lyons, J. L. & Bernstein, N. Machine learning phonon spectra for fast and accurate optical lineshapes of defects.ACS Nano20, 7454–7463 (2026). URLhttp://dx.doi.org/10.1021/ acsnano.5c15446
2026
-
[18]
Kirkpatrick, J.et al.Overcoming catastrophic forgetting in neural networks.Proceedings of the National Academy of Sciences114, 3521–3526 (2017). URLhttp://dx.doi.org/10.1073/pnas.1611835114
-
[19]
J.et al.Lora: Low-rank adaptation of large language models (2021)
Hu, E. J.et al.Lora: Low-rank adaptation of large language models (2021). URLhttps://arxiv.org/ abs/2106.09685.2106.09685
Pith/arXiv arXiv 2021
-
[20]
& Jia, W
Wang, C., Hu, S., Tan, G. & Jia, W. ELoRA: Low-rank adaptation for equivariant GNNs. InProceedings of the 42nd International Conference on Machine Learning, vol. 267 ofProceedings of Machine Learning Research, 63113–63135 (PMLR, 2025). URLhttps://proceedings.mlr.press/v267/wang25al.html
2025
-
[21]
O’Neill, N., Shi, B. X., Fong, K., Michaelides, A. & Schran, C. To pair or not to pair? machine-learned explicitly-correlated electronic structure for nacl in water (2024). URLhttps://arxiv.org/abs/2311. 01527.2311.01527
arXiv 2024
-
[22]
Kuryla, D., Cs´ anyi, G., van Duin, A. C. T. & Michaelides, A. Efficient exploration of reaction path- ways using reaction databases and active learning.The Journal of Chemical Physics162, 114122 (2025). URLhttps://doi.org/10.1063/5.0235715.https://pubs.aip.org/aip/jcp/article-pdf/ doi/10.1063/5.0235715/20449557/114122_1_5.0235715.pdf. 22
work page doi:10.1063/5.0235715.https://pubs.aip.org/aip/jcp/article-pdf/ 2025
-
[23]
Eastman, P.et al.SPICE, a dataset of drug-like molecules and peptides for training machine learning potentials.Scientific Data10, 11 (2023)
2023
-
[24]
Elena, A.et al.Machine learned potential for high-throughput phonon calculations of metal-organic frameworks.Npj Computational Materials11(2025)
2025
-
[25]
URLhttps://arxiv.org/abs/2410.12771.2410.12771
Barroso-Luque, L.et al.Open materials 2024 (omat24) inorganic materials dataset and models (2024). URLhttps://arxiv.org/abs/2410.12771.2410.12771
Pith/arXiv arXiv 2024
-
[26]
Kolsbjerg, E. L., Groves, M. N. & Hammer, B. An automated nudged elastic band method.The Journal of Chemical Physics145, 094107 (2016). URLhttps://doi.org/10.1063/1.4961868.https: //pubs.aip.org/aip/jcp/article-pdf/doi/10.1063/1.4961868/15516968/094107_1_online.pdf
-
[27]
Pickard, C. J. & Needs, R. J. ¡i¿ab initio¡/i¿random structure searching.Journal of Physics: Condensed Matter23, 053201 (2011). URLhttp://dx.doi.org/10.1088/0953-8984/23/5/053201
-
[28]
Kov´ acs, D. P.et al.Mace-off: Transferable short range machine learning force fields for organic molecules (2025). URLhttps://arxiv.org/abs/2312.15211.2312.15211
arXiv 2025
-
[29]
Rolnick, D., Ahuja, A., Schwarz, J., Lillicrap, T. P. & Wayne, G. Experience replay for continual learning. InAdvances in Neural Information Processing Systems, vol. 32, 348–358 (2019). URLhttps: //papers.nips.cc/paper/8327-experience-replay-for-continual-learning
2019
-
[30]
Lesort, T., Caselles-Dupr´ e, H., Garcia-Ortiz, M., Stoian, A. & Filliat, D. Generative models from the perspective of continual learning. In2019 International Joint Conference on Neural Networks (IJCNN), 1–8 (2019). URLhttps://doi.org/10.1109/IJCNN.2019.8851986
-
[31]
& Hoiem, D
Li, Z. & Hoiem, D. Learning without forgetting. InComputer Vision – ECCV 2016, vol. 9908 ofLecture Notes in Computer Science, 614–629 (Springer, 2016). URLhttps://doi.org/10.1007/ 978-3-319-46493-0_37
2016
-
[32]
& Lab, T
Schulman, J. & Lab, T. M. Lora without regret.Thinking Machines Lab: Connectionism(2025). https://thinkingmachines.ai/blog/lora/
2025
-
[33]
Kov´ acs, D. P., Batatia, I., Arany, E. S. & Cs´ anyi, G. Evaluation of the mace force field architec- ture: From medicinal chemistry to materials science.The Journal of Chemical Physics159, 044118 (2023). URLhttps://doi.org/10.1063/5.0155322.https://pubs.aip.org/aip/jcp/article-pdf/ doi/10.1063/5.0155322/18065016/044118_1_5.0155322.pdf
work page doi:10.1063/5.0155322.https://pubs.aip.org/aip/jcp/article-pdf/ 2023
-
[34]
URLhttps://arxiv.org/abs/2602.19411.2602.19411
Batatia, I.et al.Mace-polar-1: A polarisable electrostatic foundation model for molecular chemistry (2026). URLhttps://arxiv.org/abs/2602.19411.2602.19411
arXiv 2026
-
[35]
McIntosh-Smith, S., Alam, S. R. & Woods, C. Isambard-ai: a leadership class supercomputer optimised specifically for artificial intelligence (2024). URLhttps://doi.org/10.48550/arXiv.2410.11199. 2410.11199
-
[36]
Loshchilov, I. & Hutter, F. Decoupled weight decay regularization (2019). URLhttps://arxiv.org/ abs/1711.05101.1711.05101
Pith/arXiv arXiv 2019
-
[37]
Fredericks, S., Parrish, K., Sayre, D. & Zhu, Q. PyXtal: A python library for crystal structure generation and symmetry analysis.Computer Physics Communications261, 107810 (2021). URLhttps://doi. org/10.1016/j.cpc.2020.107810. 23 Appendix This appendix collects the computational details that support the main text and the additional results and comparisons...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.