A Survey and Experimental Analysis of Distributed Subgraph Matching
Pith reviewed 2026-05-25 14:07 UTC · model grok-4.3
The pith
Reimplementing four distributed subgraph matching strategies inside one dataflow system isolates their performance differences and produces a practical selection guide.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
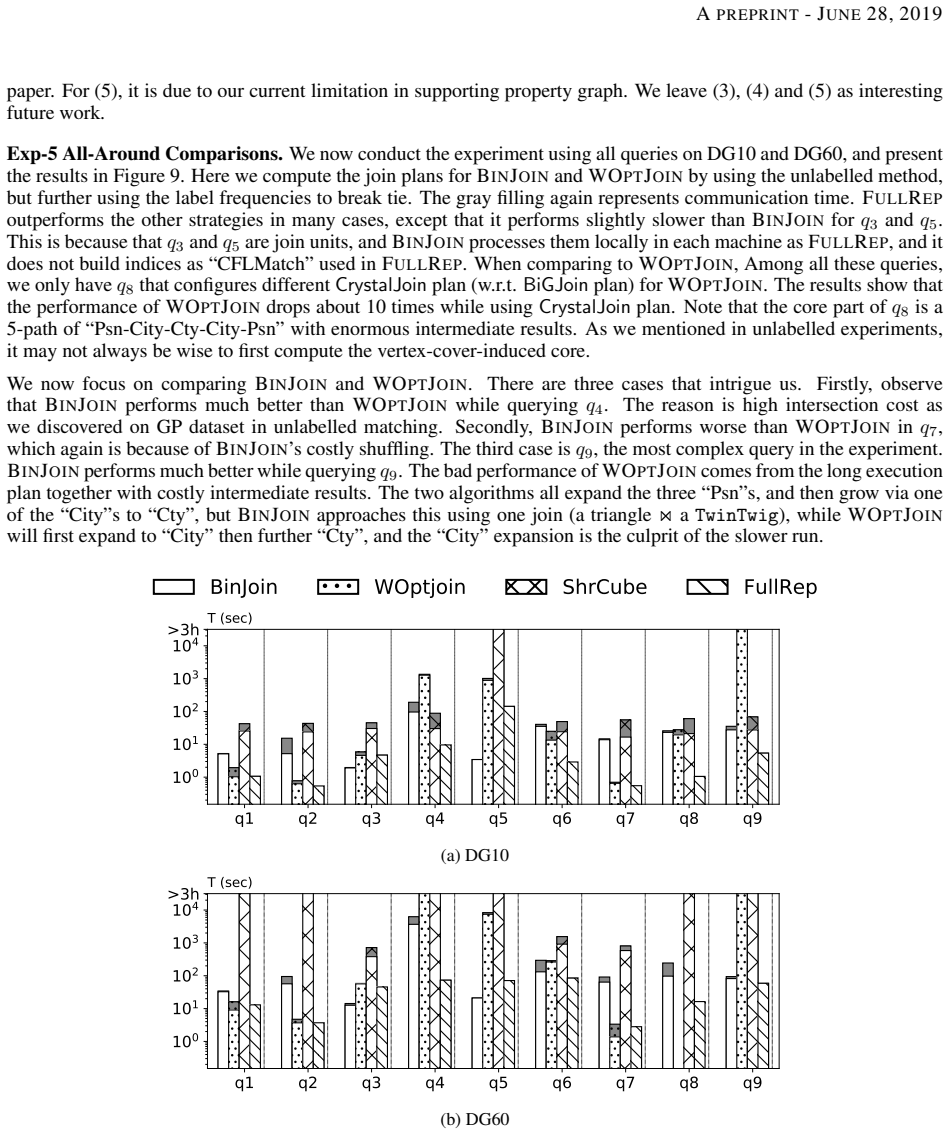
The authors identify four strategies and three general-purpose optimizations from representative state-of-the-art works. They implement the four strategies with the optimizations based on the common Timely dataflow system for systematic strategy-level comparison. Their implementation covers all representation algorithms. They conduct extensive experiments for both unlabelled matching and labelled matching to analyze the performance of distributed subgraph matching under various settings, which is finally summarized as a practical guide.
What carries the argument
Classification of algorithms into four strategies plus three optimizations, all realized inside the same Timely dataflow engine so that strategy effects can be measured in isolation.
If this is right
- Performance rankings among the four strategies become directly comparable because platform differences are removed.
- The practical guide indicates which strategy wins for particular combinations of graph scale, query shape, and label presence.
- The three optimizations improve every strategy, yet their relative value changes with the underlying strategy.
- Results apply separately to unlabelled and labelled matching workloads.
- The experimental methodology covers enough settings to support workload-specific recommendations.
Where Pith is reading between the lines
- The same isolation technique could be applied to other distributed graph primitives such as triangle listing or reachability queries.
- If a new strategy appears, it can be inserted into the Timely framework and ranked against the existing four without re-running all prior experiments.
- Communication volume and load balance patterns exposed by the common runtime may explain why certain strategies scale better on particular graphs.
- The guide could be validated by deploying its recommended strategy on a production workload and measuring end-to-end query latency.
Load-bearing premise
Re-implementing the original algorithms inside Timely dataflow faithfully reproduces their performance characteristics without introducing new biases from the shared runtime.
What would settle it
If the original published implementations of the four strategies, run on identical hardware and inputs, produce different relative performance orderings than the Timely reimplementations, the claim of faithful strategy-level comparison would be falsified.
Figures












read the original abstract
Recently there emerge many distributed algorithms that aim at solving subgraph matching at scale. Existing algorithm-level comparisons failed to provide a systematic view to the pros and cons of each algorithm mainly due to the intertwining of strategy and optimization. In this paper, we identify four strategies and three general-purpose optimizations from representative state-of-the-art works. We implement the four strategies with the optimizations based on the common Timely dataflow system for systematic strategy-level comparison. Our implementation covers all representation algorithms. We conduct extensive experiments for both unlabelled matching and labelled matching to analyze the performance of distributed subgraph matching under various settings, which is finally summarized as a practical guide.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript identifies four strategies and three general-purpose optimizations from representative state-of-the-art works on distributed subgraph matching. It re-implements the four strategies (with the optimizations) inside the common Timely dataflow system to enable systematic strategy-level comparison, states that the implementation covers all representation algorithms, conducts extensive experiments on both unlabelled and labelled matching under various settings, and distills the results into a practical guide.
Significance. If the re-implementations faithfully preserve the performance-relevant behavior of the original algorithms, the work supplies a valuable platform-independent comparison that existing algorithm-level studies have not provided. The shared Timely runtime is a methodological strength for isolating strategy differences. The empirical scope (unlabelled and labelled cases, multiple settings) and the resulting practical guide would be useful to the community.
major comments (2)
- [§4 (Implementation)] §4 (Implementation): the manuscript asserts that the Timely re-implementations cover all representation algorithms but supplies no external validation (e.g., runtime or scalability numbers on shared benchmarks compared against the original published results). This gap is load-bearing because the entire strategy comparison and the derived practical guide rest on the assumption that observed differences reflect the strategies rather than platform-specific artifacts.
- [§5 (Experiments)] §5 (Experiments): without fidelity checks on the re-implementations, it is impossible to determine whether performance differences under varying settings (graph size, label density, etc.) arise from the four strategies or from unstated choices in the common Timely runtime such as partitioning, batching, or indexing.
minor comments (1)
- [Abstract] The abstract would benefit from naming the four strategies and three optimizations explicitly rather than referring to them only by count.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of the paper's contributions and for the constructive major comments. We address each point below regarding the validation of the Timely re-implementations.
read point-by-point responses
-
Referee: [§4 (Implementation)] the manuscript asserts that the Timely re-implementations cover all representation algorithms but supplies no external validation (e.g., runtime or scalability numbers on shared benchmarks compared against the original published results). This gap is load-bearing because the entire strategy comparison and the derived practical guide rest on the assumption that observed differences reflect the strategies rather than platform-specific artifacts.
Authors: We agree that external validation against original published results would strengthen confidence in the re-implementations. However, the majority of the source papers do not provide open-source implementations, which precludes direct runtime or scalability comparisons on identical benchmarks and hardware. Our re-implementations are derived strictly from the algorithmic descriptions and pseudocode in the original works, preserving the four core strategies while standardizing the runtime. In the revision we will expand §4 with an explicit discussion of implementation fidelity, including any simplifications made and why they do not alter the strategy-level behavior being compared. revision: partial
-
Referee: [§5 (Experiments)] without fidelity checks on the re-implementations, it is impossible to determine whether performance differences under varying settings (graph size, label density, etc.) arise from the four strategies or from unstated choices in the common Timely runtime such as partitioning, batching, or indexing.
Authors: All four strategy implementations share the identical Timely dataflow configuration, including the same partitioning scheme, batch sizes, and indexing structures; only the query-processing logic differs according to the extracted strategy. We will revise §4 and §5 to make this shared configuration explicit and to state that any observed performance variation is therefore attributable to the strategies rather than to runtime parameters. We will also add a short paragraph confirming that the same Timely version and configuration flags were used throughout the experimental campaign. revision: yes
Circularity Check
No circularity: empirical survey with re-implementations on shared runtime
full rationale
The paper is a survey and experimental analysis that extracts four strategies and three optimizations from prior literature, re-implements them inside a common Timely dataflow system, runs head-to-head experiments on labelled and unlabelled matching, and condenses results into a practical guide. No equations, derivations, or first-principles claims appear. No self-definitional loops, fitted parameters renamed as predictions, load-bearing self-citations, uniqueness theorems imported from the authors' prior work, or ansatzes smuggled via citation are present. The comparison rests on external experimental outcomes rather than reducing to its own inputs by construction. The methodological assumption that re-implementations preserve original performance characteristics is a standard empirical concern but does not instantiate any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
http://www.dis.uniroma1.it/challenge9
The challenge9 datasets. http://www.dis.uniroma1.it/challenge9
-
[2]
https://lemurproject.org/clueweb12
The clubweb12 dataset. https://lemurproject.org/clueweb12
-
[3]
https://en.wikipedia.org/wiki/Sparse_matrix
Compressed sparse row. https://en.wikipedia.org/wiki/Sparse_matrix
- [4]
-
[5]
https://github.com/frankmcsherry/dataflow-join/
The implementation of bigjoin. https://github.com/frankmcsherry/dataflow-join/
- [6]
-
[7]
https://ldbc.github.io/ldbc_snb_docs/ ldbc-snb-specification.pdf
The ldbc social network benchmark. https://ldbc.github.io/ldbc_snb_docs/ ldbc-snb-specification.pdf
-
[8]
https://github.com/frankmcsherry/timely-dataflow
The open-sourced timely dataflow system. https://github.com/frankmcsherry/timely-dataflow
-
[9]
http://snap.stanford.edu/data/index.html
The snap datasets. http://snap.stanford.edu/data/index.html
-
[10]
http://law.di.unimi.it/datasets.php
The webgraph datasets. http://law.di.unimi.it/datasets.php
-
[11]
C. R. Aberger, S. Tu, K. Olukotun, and C. Ré. Emptyheaded: A relational engine for graph processing. SIGMOD ’16, pages 431–446
-
[12]
F. N. Afrati, D. Fotakis, and J. D. Ullman. Enumerating subgraph instances using map-reduce. In Proc. of ICDE’13, 2013
work page 2013
- [13]
- [14]
- [15]
-
[16]
F. Bi, L. Chang, X. Lin, L. Qin, and W. Zhang. Efficient subgraph matching by postponing cartesian products. SIGMOD ’16, pages 1199–1214, 2016
work page 2016
-
[17]
P. Carbone, A. Katsifodimos, Kth, S. Sweden, S. Ewen, V . Markl, S. Haridi, and K. Tzoumas. Apache flink TM: Stream and batch processing in a single engine. 38, 01 2015
work page 2015
-
[18]
D. Chakrabarti, Y . Zhan, and C. Faloutsos. R-mat: A recursive model for graph mining. In SDM, 2004
work page 2004
-
[19]
S. Choudhury, L. B. Holder, G. Chin, K. Agarwal, and J. Feo. A selectivity based approach to continuous pattern detection in streaming graphs. In EDBT, 2015
work page 2015
-
[20]
S. Chu, M. Balazinska, and D. Suciu. From theory to practice: Efficient join query evaluation in a parallel database system. SIGMOD ’15, pages 63–78
-
[21]
F. R. K. Chung, L. Lu, and V . H. Vu. The spectra of random graphs with given expected degrees. Internet Mathematics, 1(3), 2003
work page 2003
-
[22]
D. J. DeWitt and J. Gray. Parallel database systems: The future of database processing or a passing fad?SIGMOD Rec., 19(4):104–112
-
[23]
P. Erdos and A. Renyi. On the evolution of random graphs. In Publ. Math. Inst. Hungary. Acad. Sci., 1960
work page 1960
-
[24]
W. Fan, J. Li, J. Luo, Z. Tan, X. Wang, and Y . Wu. Incremental graph pattern matching. SIGMOD ’11, pages 925–936, 2011
work page 2011
-
[25]
S. Gorka and R. Philip. Improving first-party bank fraud detection with graph databases, 2016
work page 2016
-
[26]
J. A. Grochow and M. Kellis. Network motif discovery using subgraph enumeration and symmetry-breaking. In Proc. of RECOMB’07, 2007. 22 A PREPRINT - J UNE 28, 2019
work page 2007
-
[27]
W.-S. Han, J. Lee, and J.-H. Lee. Turboiso: Towards ultrafast and robust subgraph isomorphism search in large graph databases. In Proc. of SIGMOD’13, 2013
work page 2013
-
[28]
J. He, S. Zhang, and B. He. In-cache query co-processing on coupled cpu-gpu architectures. PVLDB, 8(4):329– 340, 2014
work page 2014
- [29]
- [30]
-
[31]
Y . E. Ioannidis and Y . C. Kang. Left-deep vs. bushy trees: An analysis of strategy spaces and its implications for query optimization. In SIGMOD’91, pages 168–177, 1991
work page 1991
-
[32]
M. Junghanns, M. Kiesling, A. Averbuch, A. Petermann, and E. Rahm. Cypher-based graph pattern matching in gradoop. GRADES’17, pages 3:1–3:8
-
[33]
C. Kankanamge, S. Sahu, A. Mhedbhi, J. Chen, and S. Salihoglu. Graphflow: An active graph database. SIG- MOD ’17, pages 1695–1698
-
[34]
H. Kim, J. Lee, S. S. Bhowmick, W.-S. Han, J. Lee, S. Ko, and M. H. Jarrah. Dualsim: Parallel subgraph enumeration in a massive graph on a single machine. SIGMOD ’16, pages 1231–1245, 2016
work page 2016
-
[35]
L. Lai, L. Qin, X. Lin, and L. Chang. Scalable subgraph enumeration in mapreduce. PVLDB, 8(10):974–985, 2015
work page 2015
-
[36]
L. Lai, L. Qin, X. Lin, and L. Chang. Scalable subgraph enumeration in mapreduce: A cost-oriented approach. The VLDB Journal, 26(3):421–446, June 2017
work page 2017
-
[37]
L. Lai, L. Qin, X. Lin, Y . Zhang, L. Chang, and S. Yang. Scalable distributed subgraph enumeration. PVLDB, 10(3):217–228, 2016
work page 2016
-
[38]
Y . Low, D. Bickson, J. Gonzalez, C. Guestrin, A. Kyrola, and J. M. Hellerstein. Distributed graphlab: A frame- work for machine learning and data mining in the cloud. PVLDB, 5(8):716–727, 2012
work page 2012
-
[39]
Y . Luo, W. Wang, and X. Lin. Spark: A keyword search engine on relational databases. In ICDE, pages 1552– 1555, April 2008
work page 2008
-
[40]
Y . Luo, W. Wang, X. Lin, X. Zhou, J. Wang, and K. Li. Spark2: Top-k keyword query in relational databases. IEEE Transactions on Knowledge and Data Engineering, 23(12):1763–1780, Dec 2011
work page 2011
-
[41]
G. Malewicz, M. H. Austern, A. J. Bik, J. C. Dehnert, I. Horn, N. Leiser, and G. Czajkowski. Pregel: A system for large-scale graph processing. In Proc. of SIGMOD’10, 2010
work page 2010
-
[42]
F. McSherry, M. Isard, and D. G. Murray. Scalability! but at what cost? HOTOS’15, 2015
work page 2015
-
[43]
D. G. Murray, F. McSherry, R. Isaacs, M. Isard, P. Barham, and M. Abadi. Naiad: A timely dataflow system. SOSP ’13, pages 439–455, 2013
work page 2013
-
[44]
H. Q. Ngo, E. Porat, C. Ré, and A. Rudra. Worst-case optimal join algorithms. J. ACM, 65(3), 2018
work page 2018
-
[45]
M. Qiao, H. Zhang, and H. Cheng. Subgraph matching: On compression and computation. PVLDB, 11(2):176– 188, 2017
work page 2017
- [46]
-
[47]
R. Shamir and D. Tsur. Faster subtree isomorphism. In Proceedings of the Fifth Israeli Symposium on Theory of Computing and Systems, pages 126–131, 1997
work page 1997
- [48]
-
[49]
B. Shao, H. Wang, and Y . Li. Trinity: A distributed graph engine on a memory cloud. SIGMOD ’13, pages 505–516, 2013
work page 2013
-
[50]
Y . Shao, B. Cui, L. Chen, L. Ma, J. Yao, and N. Xu. Parallel subgraph listing in a large-scale graph. In SIGMOD’14, pages 625–636. ACM, 2014
work page 2014
-
[51]
Z. Sun, H. Wang, H. Wang, B. Shao, and J. Li. Efficient subgraph matching on billion node graphs. PVLDB, 5(9):788–799, 2012
work page 2012
-
[52]
C. H. C. Teixeira, A. J. Fonseca, M. Serafini, G. Siganos, M. J. Zaki, and A. Aboulnaga. Arabesque: A system for distributed graph mining. SOSP ’15, pages 425–440. 23 A PREPRINT - J UNE 28, 2019
work page 2019
-
[53]
H. Wei, J. X. Yu, C. Lu, and X. Lin. Speedup graph processing by graph ordering. SIGMOD ’16, pages 1813– 1828
-
[54]
M. Zaharia, M. Chowdhury, M. J. Franklin, S. Shenker, and I. Stoica. Spark: Cluster computing with working sets. In HotCloud’10, pages 10–10. A Auxiliary Experiments Exp-6 Scalability of Unlabelled Matching. We vary the number of machines as 1, 2, 4, 6, 8, 10, and run the unlabelled queriesq1 andq2 to see how each strategy (B INJOIN, WO PTJOIN, S HRCUBE a...
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.