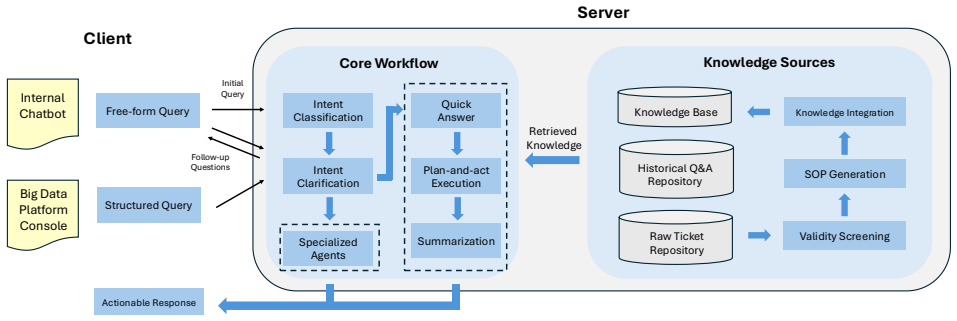
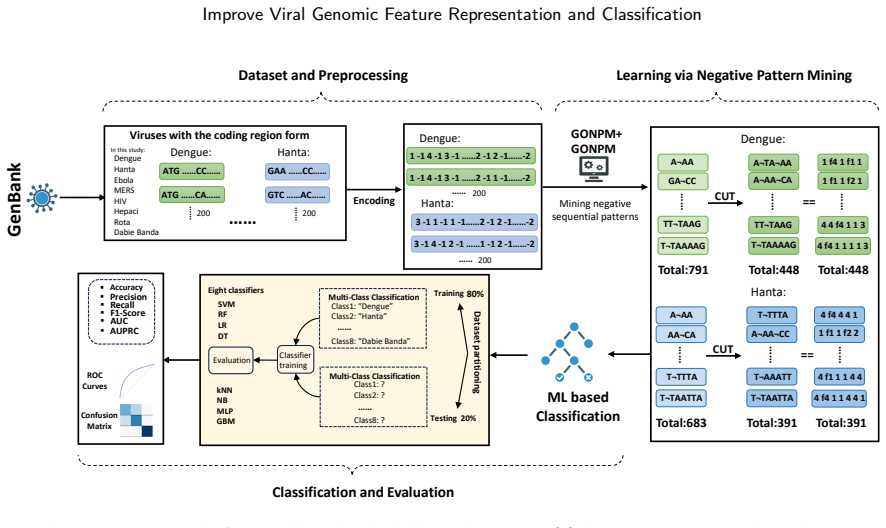
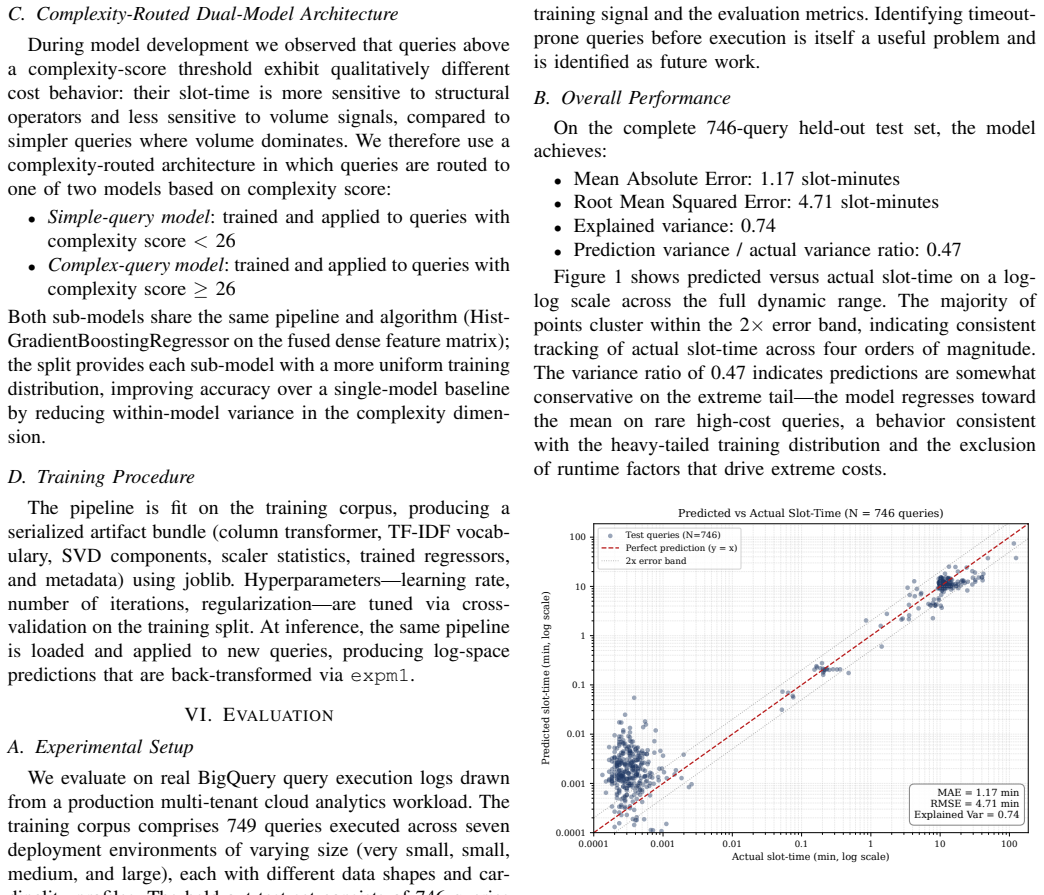
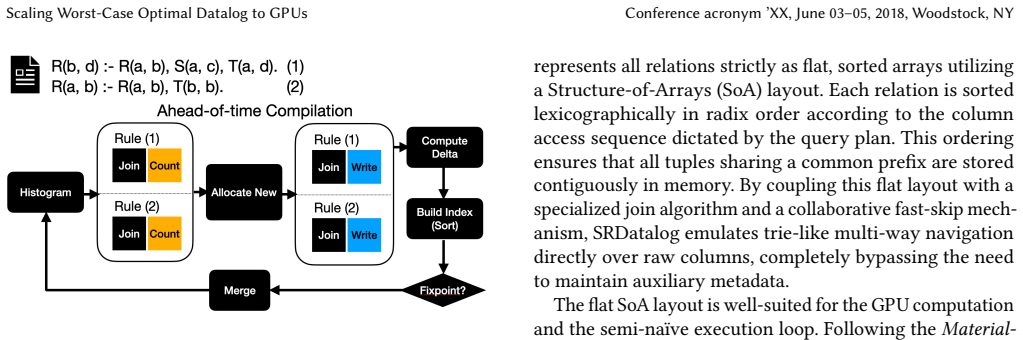
0
Benchmark shows top multimodal models lag on e-commerce
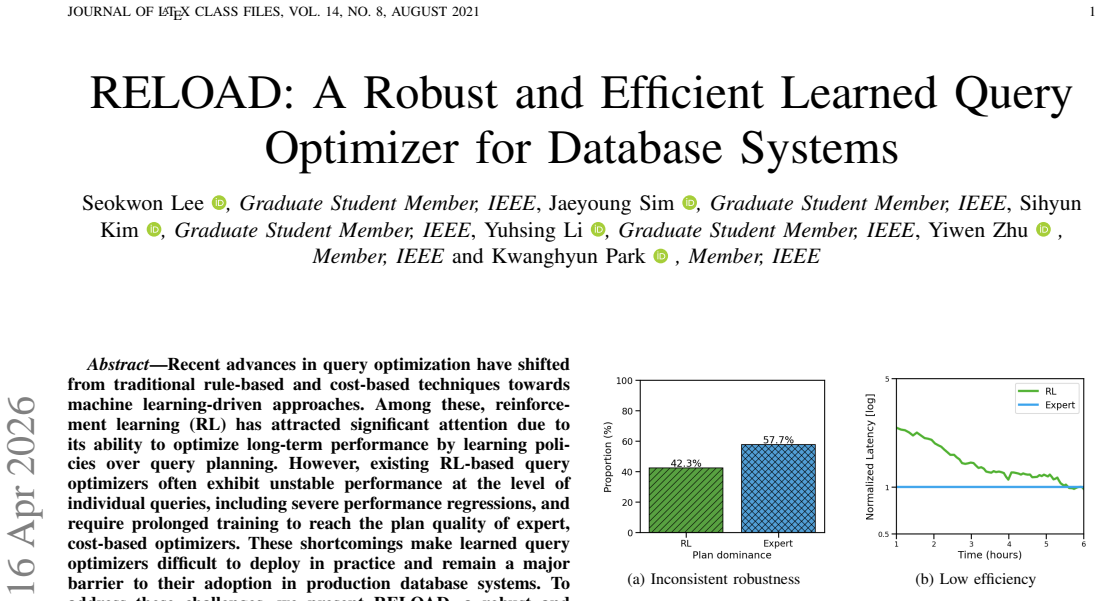
OxyEcomBench: Benchmarking Multimodal Foundation Models across E-Commerce Ecosystems
Tests of 20 leading models on 6300 real instances across merchants, customers and operators reveal modest scores and narrowed gaps due to a
 full image
full image
abstract click to expand
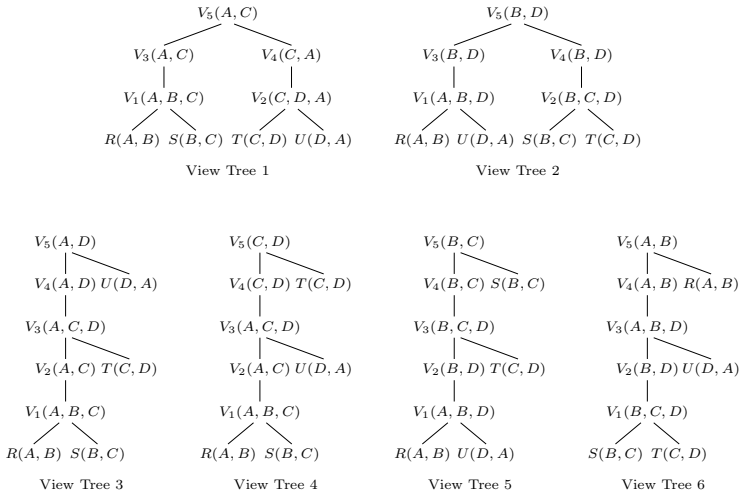
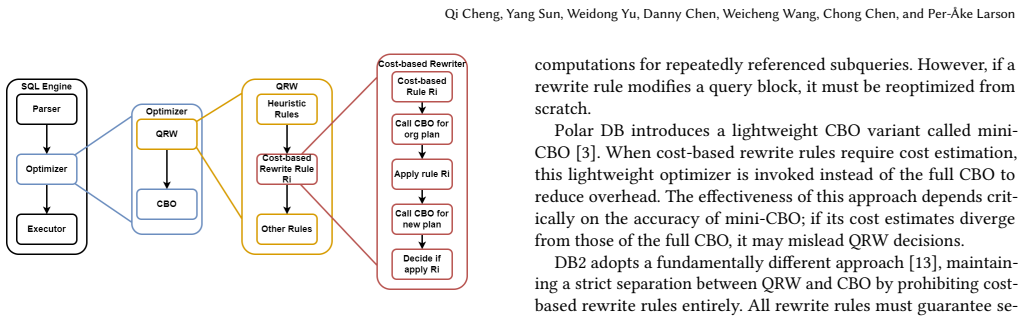
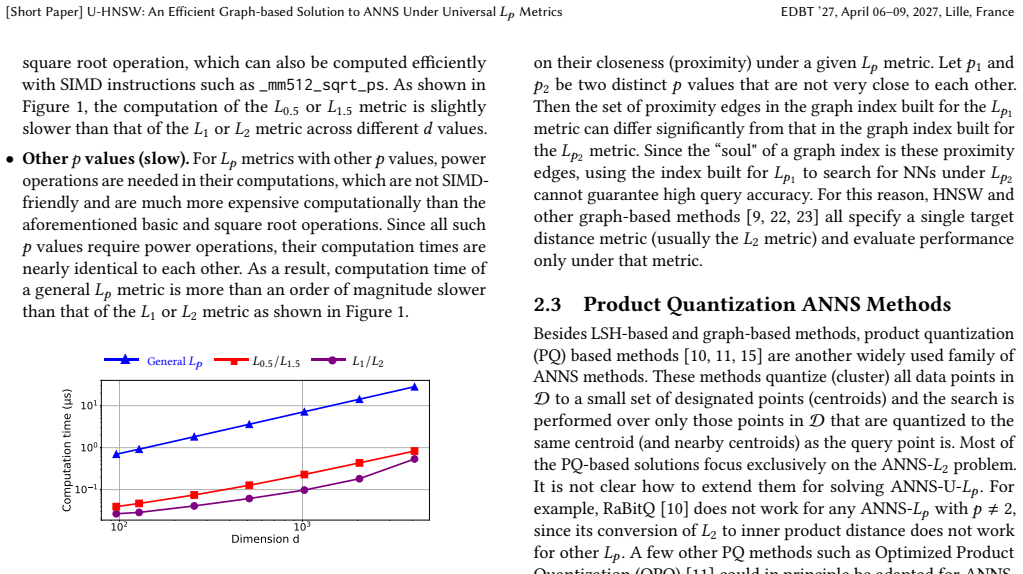
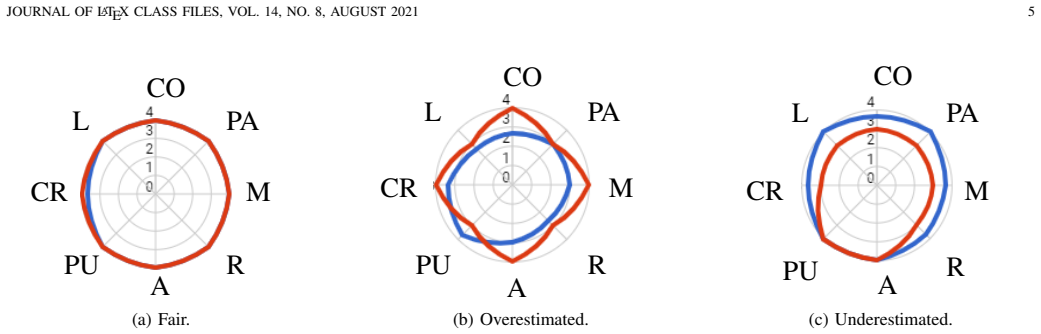
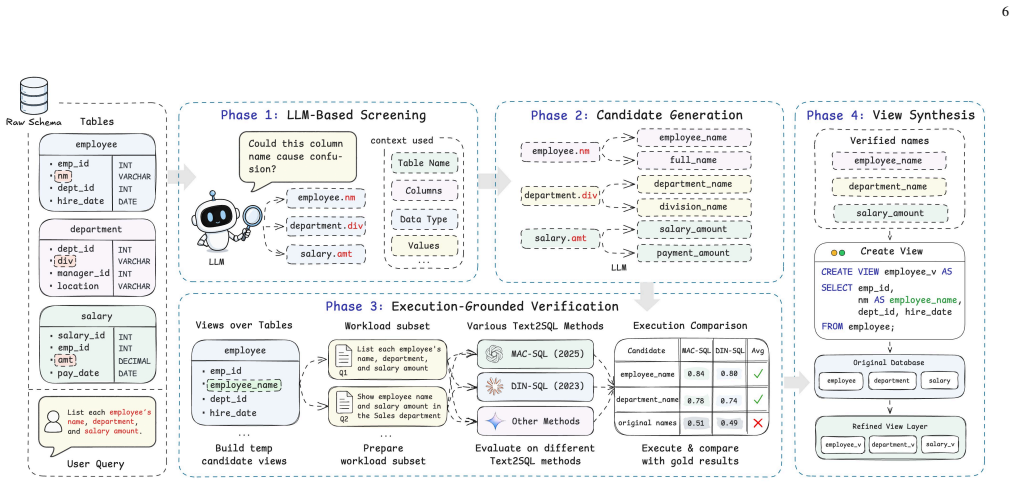
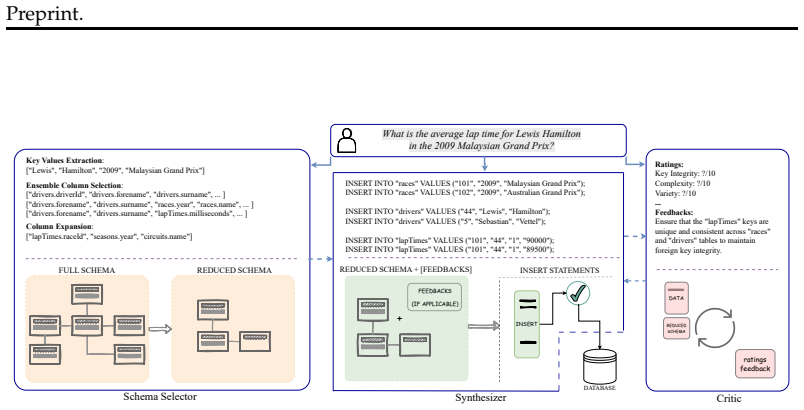
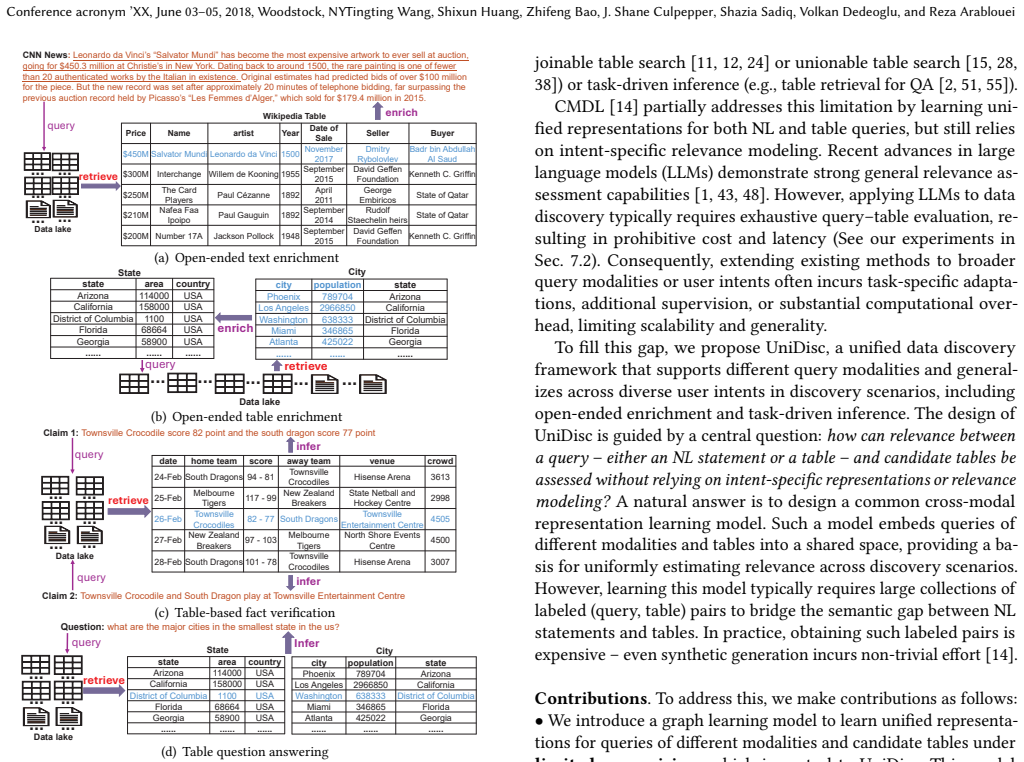
LLMs and MLLMs have become indispensable tools across a wide range of applications. E-commerce, however, poses distinctive challenges -- including intricate domain knowledge, long-tail product evidence, heterogeneous visual data, and the interplay among multiple stakeholder roles -- that diverge substantially from the general world knowledge these models are primarily trained on, often causing a notable gap between their open-domain and e-commerce performance. To systematically quantify this gap, we introduce OxyEcomBench, a unified multimodal benchmark comprising approximately 6,300 high-quality instances for real-world bilingual Chinese--English e-commerce. Although several e-commerce benchmarks have been proposed, they typically adopt a single stakeholder perspective, target a narrow set of tasks, or address isolated challenges, making it difficult to holistically assess models' understanding of the full e-commerce pipeline. OxyEcomBench addresses these limitations by jointly covering platform operators, merchants, and customers across 6 capability aspects and 29 tasks, supporting text-only and mixed-modality inputs with single-image, multi-image, single-turn, and multi-turn configurations. All data is sourced from authentic e-commerce platforms and verified by domain experts. The benchmark further adopts a difficulty-aware design with a four-level P0--P3 rubric applied to all 29 tasks whose difficulty admits stable expert consensus, and rigorously prioritizes visually salient multimodal cases in which key evidence resides in images rather than text alone. Evaluations on 20 mainstream LLMs and MLLMs show that even the leading models attain modest performance and that performance gaps narrow on OxyEcomBench, suggesting that insufficient e-commerce-specific knowledge infusion mutes the advantages of advanced general-purpose models in this domain.