Learning Key-Value Store Design
Pith reviewed 2026-05-24 22:33 UTC · model grok-4.3
The pith
A design continuum unifies distinct key-value store data structures as views of one space built from a small set of layout concepts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
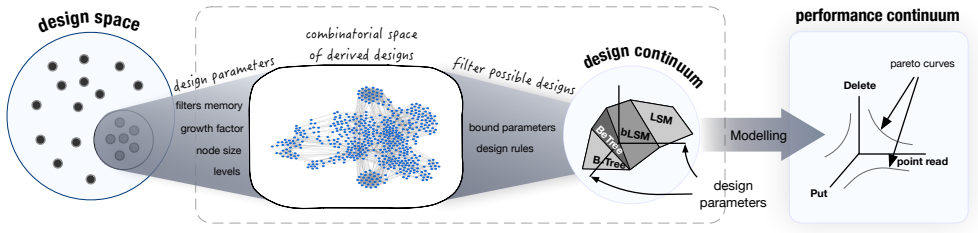
All data structures arise from the very same set of fundamental design principles, i.e., a small set of data layout design concepts out of which we can synthesize any design that exists in the literature as well as new ones. The first such continuum unifies B+tree, B-epsilon-tree, LSM-tree, and LSH-table.
What carries the argument
The design continuum, a model built from a fixed small set of data layout design concepts that generates both known and novel key-value store structures.
If this is right
- Near-instant prediction of how a change in underlying storage design affects performance.
- Selection of the optimal data structure given workload characteristics and a memory budget.
- Self-designing key-value stores that transition between drastically different designs to assume diverse performance properties.
- Generation of new data structure designs with performance properties not feasible by existing designs.
Where Pith is reading between the lines
- The same continuum construction process could be applied to other database components such as indexing or query execution.
- Automated search over the continuum might reveal performance trade-offs that manual design overlooks.
- Hardware evolution could be handled by re-deriving the best point in the continuum for the new device.
Load-bearing premise
Every existing and future key-value store data structure can be generated from one small fixed set of layout design concepts without loss of important performance distinctions.
What would settle it
A concrete data structure whose performance cannot be matched or predicted by any combination of parameters inside the proposed continuum.
Figures














read the original abstract
We introduce the concept of design continuums for the data layout of key-value stores. A design continuum unifies major distinct data structure designs under the same model. The critical insight and potential long-term impact is that such unifying models 1) render what we consider up to now as fundamentally different data structures to be seen as views of the very same overall design space, and 2) allow seeing new data structure designs with performance properties that are not feasible by existing designs. The core intuition behind the construction of design continuums is that all data structures arise from the very same set of fundamental design principles, i.e., a small set of data layout design concepts out of which we can synthesize any design that exists in the literature as well as new ones. We show how to construct, evaluate, and expand, design continuums and we also present the first continuum that unifies major data structure designs, i.e., B+tree, B-epsilon-tree, LSM-tree, and LSH-table. The practical benefit of a design continuum is that it creates a fast inference engine for the design of data structures. For example, we can predict near instantly how a specific design change in the underlying storage of a data system would affect performance, or reversely what would be the optimal data structure (from a given set of designs) given workload characteristics and a memory budget. In turn, these properties allow us to envision a new class of self-designing key-value stores with a substantially improved ability to adapt to workload and hardware changes by transitioning between drastically different data structure designs to assume a diverse set of performance properties at will.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the concept of design continuums for the data layout of key-value stores. It claims that a small fixed set of fundamental data layout design concepts can synthesize any existing design in the literature (demonstrated for B+tree, B-epsilon-tree, LSM-tree, and LSH-table) as well as new designs, unifying what were previously seen as distinct structures under one model. This enables a fast inference engine to predict performance effects of design changes or select optimal designs given workload and memory constraints, supporting a vision of self-designing key-value stores that adapt by transitioning between designs.
Significance. If the unification holds without gaps or loss of performance distinctions, the work provides a principled way to explore the design space of data structures and could enable more adaptive database systems. The practical inference engine for near-instant performance prediction is a concrete strength if the underlying model is complete and parameter-free in the claimed sense.
major comments (1)
- [Abstract] The central claim (abstract) that 'a small set of data layout design concepts' suffices to synthesize 'any design that exists in the literature as well as new ones' is load-bearing but unsupported by a completeness argument or expansion procedure. The manuscript demonstrates synthesis for four specific structures but provides no general method to verify that the fixed set remains sufficient when a fifth design is added or to guarantee that performance distinctions are not approximated away.
minor comments (1)
- Clarify early in the manuscript how the 'design concepts' are enumerated and whether the set is claimed to be minimal or extensible.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] The central claim (abstract) that 'a small set of data layout design concepts' suffices to synthesize 'any design that exists in the literature as well as new ones' is load-bearing but unsupported by a completeness argument or expansion procedure. The manuscript demonstrates synthesis for four specific structures but provides no general method to verify that the fixed set remains sufficient when a fifth design is added or to guarantee that performance distinctions are not approximated away.
Authors: The manuscript explicitly states that it shows how to construct, evaluate, and expand design continuums. The expansion procedure provides the general method: a new design is decomposed against the existing fundamental concepts; if it cannot be expressed exactly, the minimal additional concepts are incorporated while retaining the parameterized models that capture performance exactly (no approximation). This process can be applied to any fifth design from the literature or newly proposed ones. A formal a-priori completeness proof that one fixed set covers every conceivable data structure is not provided, as that would require an exhaustive formalization of the entire design space, which lies outside the paper's scope. We can revise the abstract and add a clarifying subsection on the expansion procedure to make this methodology more prominent. revision: partial
Circularity Check
No circularity: unification presented as modeling construction, not derived prediction or self-referential fit
full rationale
The paper defines a design continuum as a modeling framework that synthesizes B+tree, B-epsilon-tree, LSM-tree and LSH-table from a fixed set of layout concepts. This is an explicit construction and demonstration rather than a derivation that reduces to fitted parameters relabeled as predictions or to self-citations whose validity depends on the current work. No equations, parameter-fitting procedures, or load-bearing self-citations appear in the provided text that would make any claimed prediction equivalent to its inputs by construction. The central claim therefore remains an independent modeling assertion whose completeness can be evaluated externally.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
ENHANCING CREA TIVITY Beyond the ability to assume existing designs, a contin- uum can also assist in identifying new data structure designs that were unknown before, but they are naturally derived from the continuum’s design parameters and rules. For example, the design continuum we presented in this paper allows us to synthesize two new subspaces of hyb...
-
[2]
THE PA TH TO SELF-DESIGN Knowing which design is the best for a workload opens the opportunity for systems that can adapt on-the-fly. While adaptivity has been studied in several forms including adapt- ing storage to queries [41, 4, 12, 49, 43, 30, 40, 66], the new opportunity is morphing among what is typically con- sidered as fundamentally different desig...
work page 2000
-
[3]
We envision a complementary line of future research to construct and improve on design continuums
NEXT STEPS Research on data structures has focused on identifying the fundamentally best performance trade-offs. We envision a complementary line of future research to construct and improve on design continuums. The overarching goal is to flexibly harness our maturing knowledge of data structures to build more robust, diverse and navigable systems. Future s...
-
[4]
This work is supported by the National Science Foundation under grant IIS-1452595
ACKNOWLEDGMENTS Mark Callaghan has provided the authors with feedback and insights on key-value store design and industry prac- tices repeatedly over the past few years and specifically for this paper. This work is supported by the National Science Foundation under grant IIS-1452595
-
[5]
N. Agrawal, V. Prabhakaran, T. Wobber, J. D. Davis, M. Manasse, and R. Panigrahy. Design Tradeoffs for SSD Performance. ATC, 2008
work page 2008
-
[6]
J.-S. Ahn, C. Seo, R. Mayuram, R. Yaseen, J.-S. Kim, and S. Maeng. ForestDB: A Fast Key-Value Storage System for Variable-Length String Keys. TC, 65(3):902–915, 2016
work page 2016
-
[7]
D. V. Aken, A. Pavlo, G. J. Gordon, and B. Zhang. Automatic Database Management System Tuning Through Large-scale Machine Learning. SIGMOD, 2017
work page 2017
-
[8]
I. Alagiannis, S. Idreos, and A. Ailamaki. H2O: A Hands-free Adaptive Store. SIGMOD, 2014
work page 2014
-
[9]
D. J. Aldous. Exchangeability and related topics. pages 1–198, 1985
work page 1985
-
[10]
P. M. Aoki. Generalizing ”Search” in Generalized Search Trees (Extended Abstract). ICDE, 1998
work page 1998
-
[11]
P. M. Aoki. How to Avoid Building DataBlades That Know the Value of Everything and the Cost of Nothing. SSDBM, 1999
work page 1999
- [12]
- [13]
-
[14]
L. Arge. The Buffer Tree: A Technique for Designing Batched External Data Structures. Algorithmica, 37(1):1–24, 2003
work page 2003
-
[15]
T. G. Armstrong, V. Ponnekanti, D. Borthakur, and M. Callaghan. LinkBench: a Database Benchmark Based on the Facebook Social Graph. SIGMOD, 2013
work page 2013
-
[16]
J. Arulraj, A. Pavlo, and P. Menon. Bridging the Archipelago between Row-Stores and Column-Stores for Hybrid Workloads. SIGMOD, 2016
work page 2016
-
[17]
M. Athanassoulis, M. S. Kester, L. M. Maas, R. Stoica, S. Idreos, A. Ailamaki, and M. Callaghan. Designing Access Methods: The RUM Conjecture. EDBT, 2016
work page 2016
-
[18]
R. Bayer and E. M. McCreight. Organization and Maintenance of Large Ordered Indexes. Proceedings of the ACM SIGFIDET Workshop on Data Description and Access , 1970
work page 1970
-
[19]
R. Bayer and E. M. McCreight. Organization and Maintenance of Large Ordered Indices. Acta Informatica, 1(3):173–189, 1972
work page 1972
-
[20]
M. A. Bender, M. Farach-Colton, J. T. Fineman, Y. R. Fogel, B. C. Kuszmaul, and J. Nelson. Cache-Oblivious Streaming B-trees. SPAA, 2007
work page 2007
-
[21]
G. S. Brodal and R. Fagerberg. Lower Bounds for External Memory Dictionaries. SODA, 2003
work page 2003
-
[22]
Y. Bu, V. R. Borkar, J. Jia, M. J. Carey, and T. Condie. Pregelix: Big(ger) Graph Analytics on a Dataflow Engine. PVLDB, 8(2):161–172, 2014
work page 2014
-
[23]
Z. Cao, S. Chen, F. Li, M. Wang, and X. S. Wang. LogKV: Exploiting Key-Value Stores for Log Processing. CIDR, 2013
work page 2013
-
[24]
B. Chandramouli, G. Prasaad, D. Kossmann, J. J. Levandoski, J. Hunter, and M. Barnett. FASTER: A Concurrent Key-Value Store with In-Place Updates. SIGMOD, 2018
work page 2018
- [25]
-
[26]
D. Cohen and N. Campbell. Automating Relational Operations on Data Structures. IEEE Software, 10(3):53–60, 1993
work page 1993
-
[27]
B. Dageville, T. Cruanes, M. Zukowski, V. Antonov, A. Avanes, J. Bock, J. Claybaugh, D. Engovatov, M. Hentschel, J. Huang, A. W. Lee, A. Motivala, A. Q. Munir, S. Pelley, P. Povinec, G. Rahn, S. Triantafyllis, and P. Unterbrunner. The Snowflake Elastic Data Warehouse. SIGMOD, 2016
work page 2016
- [28]
- [29]
- [30]
-
[31]
N. Dayan and S. Idreos. Dostoevsky: Better Space-Time Trade-Offs for LSM-Tree Based Key-Value Stores via Adaptive Removal of Superfluous Merging. SIGMOD, 2018
work page 2018
-
[32]
N. Dayan and S. Idreos. The log-structured merge-bush & the wacky continuum. In SIGMOD, 2019
work page 2019
-
[33]
G. DeCandia, D. Hastorun, M. Jampani, G. Kakulapati, A. Lakshman, A. Pilchin, S. Sivasubramanian, P. Vosshall, and W. Vogels. Dynamo: Amazon’s Highly Available Key-value Store. SIGOPS Op. Sys. Rev. , 41(6):205–220, 2007
work page 2007
-
[34]
J. Dittrich and A. Jindal. Towards a One Size Fits All Database Architecture. CIDR, 2011
work page 2011
-
[35]
S. Dong, M. Callaghan, L. Galanis, D. Borthakur, T. Savor, and M. Strum. Optimizing Space Amplification in RocksDB. CIDR, 2017
work page 2017
-
[36]
Facebook. RocksDB. https://github.com/facebook/rocksdb
-
[37]
M. J. Franklin. Caching and Memory Management in Client-Server Database Systems. PhD thesis, University of Wisconsin-Madison, 1993
work page 1993
-
[38]
G. Golan-Gueta, E. Bortnikov, E. Hillel, and I. Keidar. Scaling Concurrent Log-Structured Data Stores. EuroSys, 2015
work page 2015
-
[39]
Google. LevelDB. https://github.com/google/leveldb/
-
[40]
P. Hawkins, A. Aiken, K. Fisher, M. C. Rinard, and M. Sagiv. Data Representation Synthesis. PLDI, 2011
work page 2011
-
[41]
P. Hawkins, A. Aiken, K. Fisher, M. C. Rinard, and M. Sagiv. Concurrent data representation synthesis. PLDI, 2012
work page 2012
- [42]
-
[43]
J. M. Hellerstein, J. F. Naughton, and A. Pfeffer. Generalized Search Trees for Database Systems. VLDB, 1995
work page 1995
- [44]
- [45]
- [46]
- [47]
- [48]
- [49]
-
[50]
H. V. Jagadish, P. P. S. Narayan, S. Seshadri, S. Sudarshan, and R. Kanneganti. Incremental Organization for Data Recording and Warehousing. VLDB, 1997
work page 1997
- [51]
-
[52]
C. Jermaine, E. Omiecinski, and W. G. Yee. The Partitioned Exponential File for Database Storage Management. VLDBJ, 16(4):417–437, 2007
work page 2007
- [53]
-
[54]
M. L. Kersten and L. Sidirourgos. A database system with amnesia. In CIDR, 2017
work page 2017
-
[55]
H. Kondylakis, N. Dayan, K. Zoumpatianos, and T. Palpanas. Coconut: A scalable bottom-up approach for building data series indexes. VLDB, 11(6):677–690, 2018
work page 2018
-
[56]
H. Kondylakis, N. Dayan, K. Zoumpatianos, and T. Palpanas. Coconut palm: Static and streaming data series exploration now in your palm. In SIGMOD, 2019
work page 2019
- [57]
-
[58]
M. Kornacker, C. Mohan, and J. M. Hellerstein. Concurrency and Recovery in Generalized Search Trees. SIGMOD, 1997
work page 1997
-
[59]
M. Kornacker, M. A. Shah, and J. M. Hellerstein. amdb: An Access Method Debugging Tool. SIGMOD, 1998
work page 1998
-
[60]
M. Kornacker, M. A. Shah, and J. M. Hellerstein. Amdb: A Design Tool for Access Methods. IEEE DEBULL , 26(2):3–11, 2003
work page 2003
-
[61]
D. Kossman. Systems Research - Fueling Future Disruptions. In Keynote talk at the Microsoft Research Faculty Summit , Redmond, WA, USA, aug 2018
work page 2018
- [62]
- [63]
-
[64]
A. Lakshman and P. Malik. Cassandra - A Decentralized Structured Storage System. SIGOPS Op. Sys. Rev. , 44(2):35–40, 2010
work page 2010
-
[65]
V. Leis, A. Kemper, and T. Neumann. The Adaptive Radix Tree: ARTful Indexing for Main-Memory Databases. ICDE, 2013
work page 2013
-
[66]
J. J. Levandoski, D. B. Lomet, and S. Sengupta. The Bw-Tree: A B-tree for New Hardware Platforms. ICDE, 2013
work page 2013
-
[67]
Y. Li, B. He, J. Yang, Q. Luo, K. Yi, and R. J. Yang. Tree Indexing on Solid State Drives. PVLDB, 3(1-2):1195–1206, 2010
work page 2010
-
[68]
H. Lim, D. Han, D. G. Andersen, and M. Kaminsky. MICA: A Holistic Approach to Fast In-Memory Key-Value Storage. NSDI, 2014
work page 2014
- [69]
- [70]
-
[71]
C. Loncaric, E. Torlak, and M. D. Ernst. Fast Synthesis of Fast Collections. PLDI, 2016
work page 2016
-
[72]
L. Lu, T. S. Pillai, A. C. Arpaci-Dusseau, and R. H. Arpaci-Dusseau. WiscKey: Separating Keys from Values in SSD-conscious Storage. F AST, 2016
work page 2016
-
[73]
S. Manegold, P. A. Boncz, and M. L. Kersten. Generic Database Cost Models for Hierarchical Memory Systems. VLDB, 2002
work page 2002
-
[74]
T. Mattson, B. Sanders, and B. Massingill. Patterns for Parallel Programming. Addison-Wesley Professional, 2004
work page 2004
- [75]
- [76]
-
[77]
M. A. Olson, K. Bostic, and M. I. Seltzer. Berkeley DB. ATC, 1999
work page 1999
-
[78]
P. E. O’Neil, E. Cheng, D. Gawlick, and E. J. O’Neil. The log-structured merge-tree (LSM-tree). Acta Informatica, 33(4):351–385, 1996
work page 1996
-
[79]
J. K. Ousterhout, G. T. Hamachi, R. N. Mayo, W. S. Scott, and G. S. Taylor. Magic: A VLSI Layout System. DAC, 1984
work page 1984
-
[80]
A. Papagiannis, G. Saloustros, P. Gonz´ alez-F´ erez, and A. Bilas. Tucana: Design and Implementation of a Fast and Efficient Scale-up Key-value Store. ATC, 2016
work page 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.