Shared Generative Latent Representation Learning for Multi-view Clustering
Pith reviewed 2026-05-24 17:45 UTC · model grok-4.3
The pith
A shared generative latent representation modeled as a mixture of Gaussians clusters multi-view data more accurately by capturing cross-view correlations and nonlinear features.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
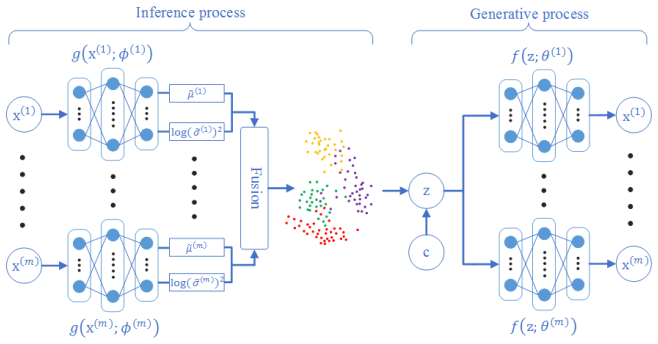
The proposed model learns a shared generative latent representation that obeys a mixture of Gaussian distributions from multi-view data; this representation simultaneously extracts nonlinear features from each view and captures the correlations among all views, yielding improved clustering performance on datasets of varying scales.
What carries the argument
shared generative latent representation obeying a mixture of Gaussian distributions
If this is right
- Clustering accuracy rises because the latent space integrates information from every view rather than treating views in isolation.
- Sample reconstruction quality improves relative to prior multi-view methods that lack an explicit generative component.
- The same learned representation supports clustering on both small and large-scale datasets without separate scaling adjustments.
- Nonlinear feature extraction becomes automatic through the deep generative pathway instead of requiring hand-crafted kernels or linear projections.
Where Pith is reading between the lines
- The mixture-of-Gaussians structure could be replaced by other flexible priors to test whether the clustering gains depend on the specific distributional form.
- The shared representation might transfer to related tasks such as multi-view classification or cross-view retrieval without retraining the full model.
- If the assumption of a shared embedding holds only for certain data domains, the method would be expected to degrade on views with fundamentally incompatible structures.
- Extending the generative component to allow view-specific noise terms could relax the strict common-embedding requirement while retaining the correlation-capturing benefit.
Load-bearing premise
Multi-view data share a single common latent embedding despite differences among the views.
What would settle it
On a dataset constructed so that the views are generated from completely independent latent factors, the method would show no accuracy gain over the best single-view clustering baseline.
Figures


read the original abstract
Clustering multi-view data has been a fundamental research topic in the computer vision community. It has been shown that a better accuracy can be achieved by integrating information of all the views than just using one view individually. However, the existing methods often struggle with the issues of dealing with the large-scale datasets and the poor performance in reconstructing samples. This paper proposes a novel multi-view clustering method by learning a shared generative latent representation that obeys a mixture of Gaussian distributions. The motivation is based on the fact that the multi-view data share a common latent embedding despite the diversity among the views. Specifically, benefited from the success of the deep generative learning, the proposed model not only can extract the nonlinear features from the views, but render a powerful ability in capturing the correlations among all the views. The extensive experimental results, on several datasets with different scales, demonstrate that the proposed method outperforms the state-of-the-art methods under a range of performance criteria.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a multi-view clustering method that learns a shared generative latent representation z ~ mixture of Gaussians. Each view is mapped by its own deep encoder network into this common latent space; clustering is then performed on z. The central motivation is that multi-view data share a common latent embedding despite view diversity; the model is claimed to extract nonlinear features and capture cross-view correlations, with experiments on datasets of varying scales showing outperformance over prior methods.
Significance. If the shared-embedding hypothesis is empirically supported, the work would offer a generative deep-learning route to multi-view clustering that addresses reconstruction and scalability limitations of earlier approaches. The combination of per-view encoders with a single GMM latent space is a natural extension of VAE-style models to the multi-view setting and could be reusable if the ablation gap is closed.
major comments (1)
- [Model and Experiments sections] The central claim that performance gains arise from capturing correlations via a shared latent embedding (abstract and motivation) is load-bearing yet untested. No ablation replaces the single shared z with view-specific latents (or adds explicit cross-view terms) while keeping the same deep encoders and GMM clustering step; without this comparison on the same datasets, gains cannot be attributed to the shared-embedding hypothesis rather than added model capacity.
minor comments (1)
- [Abstract] Abstract states only high-level motivation and claims; quantitative results, architecture details, and loss formulations appear only later, which slows assessment of the contribution.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the manuscript. The major comment raises an important point about validating the contribution of the shared latent embedding, which we address below.
read point-by-point responses
-
Referee: [Model and Experiments sections] The central claim that performance gains arise from capturing correlations via a shared latent embedding (abstract and motivation) is load-bearing yet untested. No ablation replaces the single shared z with view-specific latents (or adds explicit cross-view terms) while keeping the same deep encoders and GMM clustering step; without this comparison on the same datasets, gains cannot be attributed to the shared-embedding hypothesis rather than added model capacity.
Authors: We agree that the current experiments do not include a direct ablation that isolates the shared latent space by replacing it with view-specific latents while holding encoder depth, GMM clustering, and other components fixed. The existing comparisons are against prior multi-view methods rather than controlled variants of the proposed architecture. To address this, the revised manuscript will add such an ablation study on the same datasets, training a view-specific latent variant (independent per-view GMMs) with matched encoder capacity for direct comparison. This will allow clearer attribution of gains to the shared-embedding design. revision: yes
Circularity Check
No circularity; model is an empirical architecture with external validation
full rationale
The paper introduces a deep generative model that encodes views into a shared latent z ~ GMM and performs clustering on z. The central claim (nonlinear feature extraction and cross-view correlation capture) is presented as a modeling choice motivated by the shared-embedding assumption, then validated by outperforming baselines on multiple datasets. No equations reduce a 'prediction' to a fitted input by construction, no load-bearing self-citations appear, and no uniqueness theorem or ansatz is smuggled in. The derivation chain is therefore self-contained against external benchmarks rather than tautological.
Axiom & Free-Parameter Ledger
free parameters (1)
- Number of mixture components
axioms (1)
- domain assumption Multi-view data share a common latent embedding despite view diversity
Reference graph
Works this paper leans on
- [1]
-
[2]
X. Cai, F. Nie, and H. Huang. Multi-view k-means clustering on big data. In IJCAI, pages 2598–2604, 2013
work page 2013
- [3]
- [4]
-
[5]
K. Chaudhuri, S. M. Kakade, K. Livescu, and K. Sridharan. Multi-view clustering via canonical correlation analysis. In ICML, pages 129–136, 2009
work page 2009
-
[6]
S. S. Chen, D. L. Donoho, and M. A. Saunders. Atomic decomposition by basis pursuit. SIAM Review, 43(1):129–159, Jan. 2001
work page 2001
-
[7]
N. Dalal and B. Triggs. Histograms of oriented gradients for human detection. In CVPR, pages 886–893, 2005
work page 2005
-
[8]
J. Deng, W. Dong, R. Socher, L. jia Li, K. Li, and L. Fei-fei. Imagenet: A large-scale hierarchical image database. In CVPR, 2009
work page 2009
-
[9]
C. Du, C. Du, and H. He. Sharing deep generative representation for perceived image reconstruction from human brain activity. In IJCNN, pages 1049–1056, 2017
work page 2017
- [10]
-
[11]
H. Gao, F. Nie, X. Li, and H. Huang. Multi-view subspace clustering. In ICCV, pages 4238–4246, 2015
work page 2015
-
[12]
G. E. Hinton and R. R. Salakhutdinov. Reducing the dimensionality of data with neural networks. Science, 313(5786):504–507, 2006
work page 2006
-
[13]
P. Ji, T. Zhang, H. Li, M. Salzmann, and I. Reid. Deep subspace clustering networks. In NIPS, pages 24–33, 2017
work page 2017
- [14]
-
[15]
D. P. Kingma and J. Ba. Adam: A method for stochastic optimization. In ICLR, volume abs/1412.6980, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[16]
D. P. Kingma and M. Welling. Auto-encoding variational Bayes. CoRR, abs/1312.6114, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[17]
F.-F. Li, R. Fergus, and P. Perona. Learning generative visual models from few training examples: An incremental Bayesian approach tested on 101 object categories. In CVPR Workshop , pages 178–178, 2004
work page 2004
-
[18]
Y. Li, F. Nie, H. Huang, and J. Huang. Large-scale multi-view spectral clustering via bipartite graph. In AAAI, volume 4, pages 2750–2756, 2015
work page 2015
-
[19]
J. Liu, C. Wang, J. Gao, and J. Han. Multi-view clustering via joint nonneg- ative matrix factorization. In SIAM Data Mining , 2013
work page 2013
-
[20]
L. van der Maaten and G. Hinton. Visualizing data using t-SNE. Journal of Machine Learning Research, 9(11):2579–2605, 2008
work page 2008
- [21]
- [22]
-
[23]
X. Peng, S. Xiao, J. Feng, W.-Y. Yau, and Z. Yi. Deep subspace clustering 17 with sparsity prior. In IJCAI, pages 1925–1931, 2016
work page 1925
-
[24]
Y. Pu, Z. Gan, R. Henao, X. Yuan, C. Li, A. Stevens, and L. Carin. Varia- tional autoencoder for deep learning of images, labels and captions. In NIPS, pages 2352–2360, 2016
work page 2016
-
[25]
N. Srivastava and R. Salakhutdinov. Multimodal learning with deep Boltz- mann machines. Journal of Machine Learning Research , 15(1):2949–2980, 2014
work page 2014
-
[26]
S. Sun. A survey of multi-view machine learning. Neural Computing and Applications, 23(7):2031–2038, 2013
work page 2031
-
[27]
F. Tian, B. Gao, Q. Cui, E. Chen, and T.-Y. Liu. Learning deep representa- tions for graph clustering. In AAAI, pages 1293–1299, 2014
work page 2014
-
[28]
H. Wang, F. Nie, and H. Huang. Multi-view clustering and feature learning via structured sparsity. In ICML, volume 28, pages 352–360, 2013
work page 2013
-
[29]
W. Wang, R. Arora, K. Livescu, and J. Bilmes. On deep multi-view repre- sentation learning. In ICML, pages l083-1092, 2015
work page 2015
-
[30]
W. Wang, X. Yan, H. Lee, and K. Livescu. Deep variational canonical corre- lation analysis. preprint arXiv:1610.03454, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[31]
J. Xie, R. Girshick, and A. Farhadi. Unsupervised deep embedding for clus- tering analysis. In ICML, pages 478–487, 2016
work page 2016
-
[32]
C. Xu, Z. Guan, W. Zhao, Y. Niu, Q. Wang, and Z. Wang. Deep multi-view concept learning. In IJCAI, pages 2898-2904, 2018
work page 2018
-
[33]
C. Xu, D. Tao, and C. Xu. A survey on multi-view learning. preprint arXiv:1304.5634, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[34]
J. Xu, J. Han, F. Nie, and X. Li. Re-weighted discriminatively embedded k-means for multi-view clustering. IEEE Transactions on Image Processing , 26(6):3016-3027, 2017
work page 2017
-
[35]
B. Yang, X. Fu, N. D. Sidiropoulos, and M. Hong. Towards k-means-friendly spaces: Simultaneous deep learning and clustering. In ICML, pages 3861– 3870, 2017
work page 2017
-
[36]
M. Yin, J. Gao, S. Xie, and Y. Guo. Multiview subspace clustering via tensorial t-product representation. IEEE Transactions on Neural Networks and Learning Systems , 30(3):851–864, 2019
work page 2019
- [37]
-
[38]
Z. Zhang, L. Liu, F. Shen, H. T. Shen, and L. Shao. Binary multi-view clustering. IEEE Transactions on Pattern Analysis and Machine Intelligence, doi:10.1109/TPAMI.2018.2847335, pages 1–1, 2018
- [39]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.