Differentially Private Estimation and Inference in High-Dimensional Regression with FDR Control
Pith reviewed 2026-05-24 06:49 UTC · model grok-4.3
The pith
DP-BIC, debiased estimators, and FDR procedures enable practical differentially private estimation and inference in sparse high-dimensional linear regression without prior sparsity knowledge.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By introducing a differentially private Bayesian Information Criterion for sparsity selection, adapting debiased estimators to the private setting, and constructing a multiple-testing rule that preserves FDR control, the procedures achieve valid estimation, inference on individual parameters, and private feature selection in sparse high-dimensional linear models without requiring the sparsity level to be supplied beforehand.
What carries the argument
The DP-BIC for automatic sparsity selection together with the DP debiased algorithm that exploits sparsity for private inference and the DP multiple testing procedure that maintains FDR control.
If this is right
- Sparsity selection becomes feasible in private high-dimensional regression without external knowledge of the number of non-zero coefficients.
- Inference on individual regression parameters can be performed while satisfying differential privacy by leveraging model sparsity.
- Significant predictors can be identified with FDR control even after privacy noise is added.
- The same framework supports both point estimation and multiple-testing decisions in one private pipeline.
Where Pith is reading between the lines
- The approach may extend to generalized linear models if the debiased step can be generalized beyond ordinary least squares.
- Calibration of the privacy noise scale could be tuned further to improve power in the multiple-testing step without losing FDR control.
- Real-world deployment would require checking whether the privacy budget allocation across selection, inference, and testing steps can be optimized for specific data regimes.
Load-bearing premise
The underlying linear model is sparse and the privacy noise does not invalidate the debiased estimators or the FDR guarantees.
What would settle it
Run the DP procedures on a simulated sparse regression dataset with known ground-truth coefficients and count how often the reported confidence intervals cover the true values or the selected features exceed the nominal FDR level.
Figures



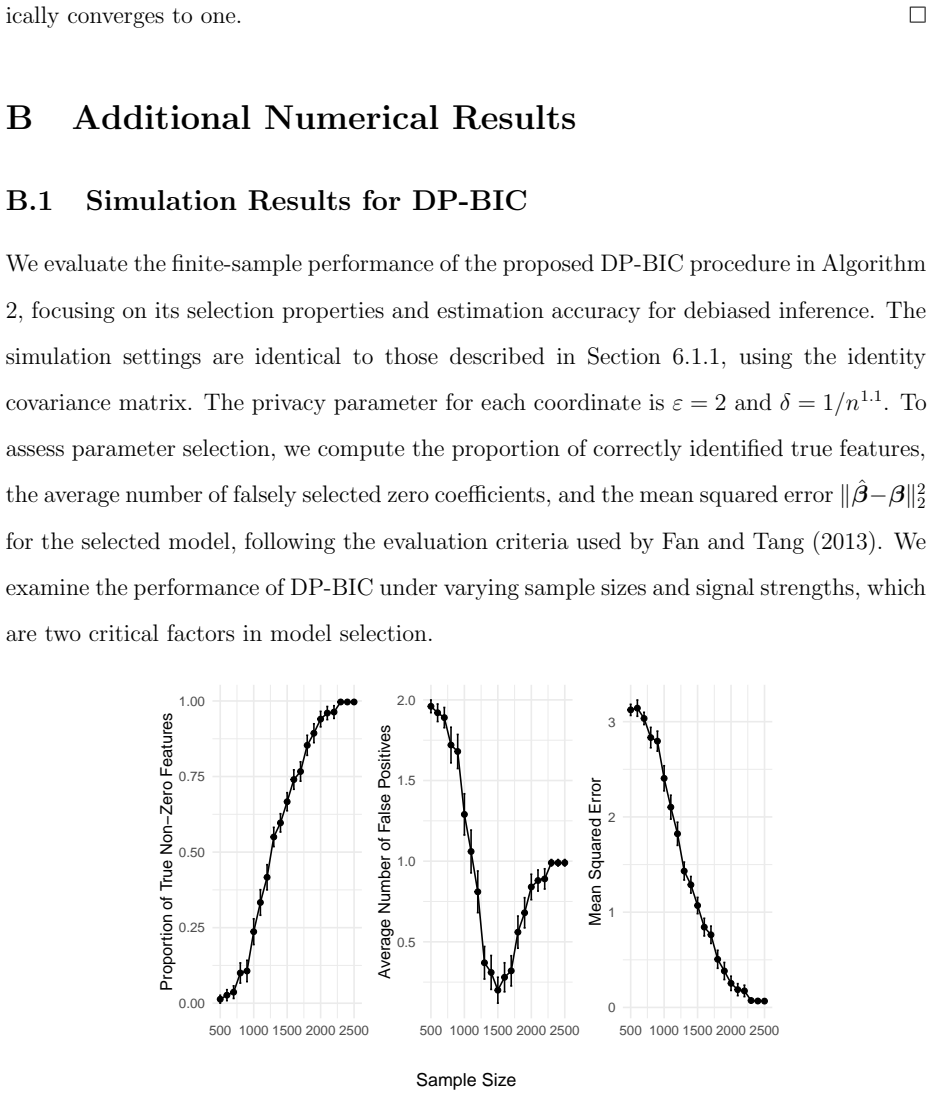
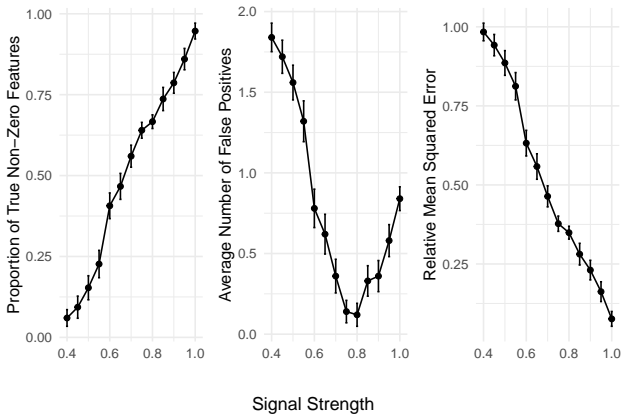


read the original abstract
This paper proposes new methodologies for conducting practical differentially private (DP) estimation and inference in high-dimensional linear regression. We first introduce a DP Bayesian Information Criterion (DP-BIC) for selecting the unknown sparsity parameter in differentially private sparse linear regression (DP-SLR), eliminating the need for prior knowledge of model sparsity, which is a requisite in the existing literature. Next, we develop the DP debiased algorithm that enables privacy-preserving inference on a particular subset of regression parameters. Our proposed method enables privacy-preserving inference on the regression parameters by leveraging the inherent sparsity of high-dimensional linear regression models. Additionally, we address private feature selection by considering multiple testing in high-dimensional linear regression by introducing a DP multiple testing procedure that controls the false discovery rate (FDR). This allows for accurate and privacy-preserving identification of significant predictors in the regression model. Through extensive simulations and real data analyses, we demonstrate the effectiveness of our proposed methods in conducting inference for high-dimensional linear models while safeguarding privacy and controlling the FDR.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DP-BIC for selecting the sparsity parameter in differentially private sparse linear regression without prior knowledge, a DP debiased algorithm for privacy-preserving inference on regression parameters by leveraging sparsity, and a DP multiple testing procedure that controls FDR for identifying significant predictors. Effectiveness is shown via simulations and real-data analyses under stated sparsity and privacy regimes.
Significance. If the concentration bounds, asymptotic normality after noise addition, and FDR control hold as claimed, the work supplies practical, implementable tools for private high-dimensional inference with explicit algorithms and simulation support. This addresses a gap between theoretical DP methods and usable inference/FDR procedures in sparse regression settings.
minor comments (3)
- [Abstract] Abstract: the phrase 'a particular subset of regression parameters' is vague; the manuscript should state explicitly which coordinates receive inference guarantees and under what conditions on the support size.
- [Simulations] The simulation section should report the exact privacy parameter values (ε, δ) and sparsity levels used in each table/figure so that the FDR control and coverage results can be directly reproduced.
- [DP debiased algorithm] Notation for the noise scale in the DP debiased step should be unified across the algorithm description and the concentration lemma that follows it.
Simulated Author's Rebuttal
We thank the referee for their positive summary of our work on DP-BIC for sparsity selection, the DP-debiased inference procedure, and the DP-FDR control method in high-dimensional linear regression. We appreciate the recommendation for minor revision and the recognition that the paper supplies practical tools with explicit algorithms and simulation support.
Circularity Check
No significant circularity detected
full rationale
The paper introduces DP-BIC for sparsity selection, a DP debiased estimator, and a DP multiple-testing procedure for FDR control. These are constructed from standard differential privacy mechanisms (noise addition with explicit concentration bounds) and established high-dimensional regression tools (debiased Lasso, BH procedure). No equation reduces a claimed prediction to a fitted input by construction, no self-citation chain is load-bearing for the central guarantees, and no ansatz or uniqueness result is imported from the authors' prior work. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption High-dimensional linear regression model is sparse
- domain assumption Differential privacy noise addition preserves validity of debiased estimators and FDR control
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We first introduce a DP Bayesian Information Criterion (DP-BIC) for selecting the unknown sparsity parameter in differentially private sparse linear regression (DP-SLR)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
develop the DP debiased algorithm that enables privacy-preserving inference on a particular subset of regression parameters
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Differentially private hypothesis testing in survival analysis
Initiates finite-sample theory for differentially private hypothesis testing in survival analysis, with private tests for Cox models and cumulative hazards plus minimax bounds.
Reference graph
Works this paper leans on
- [1]
- [2]
-
[3]
Azriel, D. and Schwartzman, A. (2015). The empirical distribution of a large number of correlated normal variables. Journal of the American Statistical Association, 110(511), 1217--1228
work page 2015
-
[4]
Barber, R.F. and Cand \`e s, E.J. (2015). Controlling the false discovery rate via knockoffs. The Annals of Statistics, 43(5), 2055--2085
work page 2015
-
[5]
Barber, R.F. and Cand \`e s, E.J. (2019). A knockoff filter for high-dimensional selective inference. The Annals of Statistics, 47(5), 2504--2537
work page 2019
-
[6]
Cai, T.T., Wang, Y., and Zhang, L. (2021). The cost of privacy: Optimal rates of convergence for parameter estimation with differential privacy. The Annals of Statistics, 49(5), 2825--2850
work page 2021
-
[7]
Candes, E., Fan, Y., Janson, L., and Lv, J. (2018). Panning for gold:‘model-x’knockoffs for high dimensional controlled variable selection. Journal of the Royal Statistical Society Series B: Statistical Methodology, 80(3), 551--577
work page 2018
-
[8]
Dai, C., Lin, B., Xing, X., and Liu, J.S. (2022). False discovery rate control via data splitting. Journal of the American Statistical Association, pages 1--18
work page 2022
-
[9]
Dai, C., Lin, B., Xing, X., and Liu, J.S. (2023). A scale-free approach for false discovery rate control in generalized linear models. Journal of the American Statistical Association, pages 1--15
work page 2023
-
[10]
Dwork, C., McSherry, F., Nissim, K., and Smith, A. (2006). Calibrating noise to sensitivity in private data analysis. In TCC 2006, pages 265--284. Springer
work page 2006
-
[11]
Dwork, C. and Roth, A. (2014). The algorithmic foundations of differential privacy. Foundations and Trends in Theoretical Computer Science , 9(3--4), 211--407
work page 2014
-
[12]
Dwork, C., Rothblum, G.N., and Vadhan, S. (2010). Boosting and differential privacy. In 2010 IEEE 51st Annual Symposium on Foundations of Computer Science, pages 51--60. IEEE
work page 2010
-
[13]
Dwork, C., Su, W., and Zhang, L. (2021). Differentially private false discovery rate control. Journal of Privacy and Confidentiality, 11(2)
work page 2021
-
[14]
Elbaz, A., Bower, J.H., Maraganore, D.M., McDonnell, S.K., Peterson, B.J., Ahlskog, J.E., Schaid, D.J., and Rocca, W.A. (2002). Risk tables for parkinsonism and parkinson's disease. Journal of Clinical Epidemiology, 55(1), 25--31
work page 2002
- [15]
-
[16]
Javanmard, A. and Montanari, A. (2014). Confidence intervals and hypothesis testing for high-dimensional regression. Journal of Machine Learning Research, 15(1), 2869--2909
work page 2014
-
[17]
Lane, J., Stodden, V., Bender, S., and Nissenbaum, H. (2014). Privacy, big data, and the public good: Frameworks for engagement. Cambridge University Press
work page 2014
-
[18]
Little, M., McSharry, P., Hunter, E., Spielman, J., and Ramig, L. (2008). Suitability of dysphonia measurements for telemonitoring of parkinson’s disease. Nature Precedings, pages 1--1
work page 2008
-
[19]
Liu, W. (2013). Gaussian graphical model estimation with false discovery rate control . The Annals of Statistics, 41(6), 2948 -- 2978
work page 2013
-
[20]
Ning, Y. and Liu, H. (2017). A general theory of hypothesis tests and confidence regions for sparse high dimensional models . The Annals of Statistics, 45(1), 158 -- 195. doi:10.1214/16-AOS1448
-
[21]
Pournaderi, M. and Xiang, Y. (2021). Differentially private variable selection via the knockoff filter. In 2021 IEEE 31st International Workshop on Machine Learning for Signal Processing (MLSP), pages 1--6. IEEE
work page 2021
-
[22]
Romano, Y., Sesia, M., and Cand \`e s, E. (2020). Deep knockoffs. Journal of the American Statistical Association, 115(532), 1861--1872
work page 2020
-
[23]
Shi, C., Song, R., Lu, W., and Li, R. (2021). Statistical inference for high-dimensional models via recursive online-score estimation. Journal of the American Statistical Association, 116(535), 1307--1318
work page 2021
-
[24]
Tan, K., Shi, L., and Yu, Z. (2020). Sparse sir: Optimal rates and adaptive estimation. The Annals of Statistics, 48(1), 64--85
work page 2020
-
[25]
Tsanas, A., Little, M., McSharry, P., and Ramig, L. (2009). Accurate telemonitoring of parkinson’s disease progression by non-invasive speech tests. Nature Precedings, pages 1--1
work page 2009
-
[26]
Van de Geer, S., B \"u hlmann, P., Ritov, Y., and Dezeure, R. (2014). On asymptotically optimal confidence regions and tests for high-dimensional models. The Annals of Statistics, 42(3), 1166--1202
work page 2014
- [27]
-
[28]
Wasserman, L. and Roeder, K. (2009). High dimensional variable selection. Annals of statistics, 37(5A), 2178
work page 2009
-
[29]
Xia, X. and Cai, Z. (2023). Adaptive false discovery rate control with privacy guarantee. Journal of Machine Learning Research, 24(252), 1--35
work page 2023
-
[30]
Zhang, C.H. and Zhang, S.S. (2014). Confidence intervals for low dimensional parameters in high dimensional linear models. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 76(1), 217--242
work page 2014
-
[31]
, " * write output.state after.block = add.period write newline
ENTRY address author booktitle chapter doi edition editor eid howpublished institution isbn issn journal key month note number organization pages publisher school series title type volume year label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block FUNCTION init.state.consts #0 'before.all := #1 'mi...
-
[32]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.