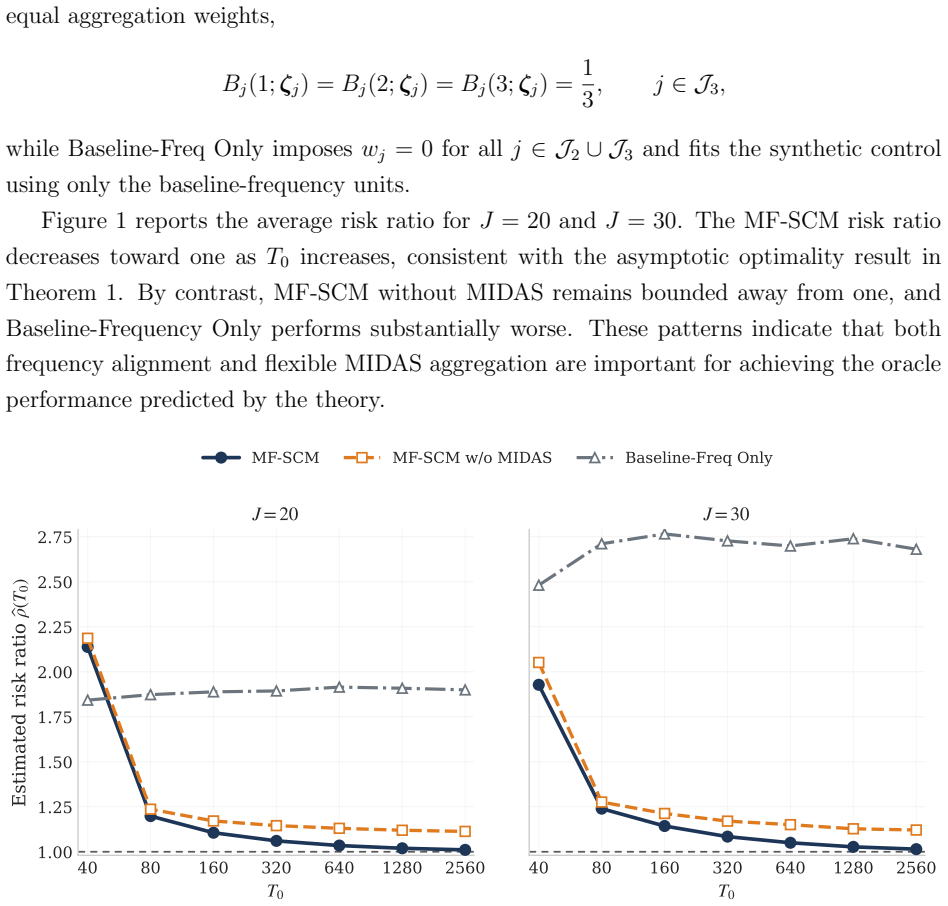
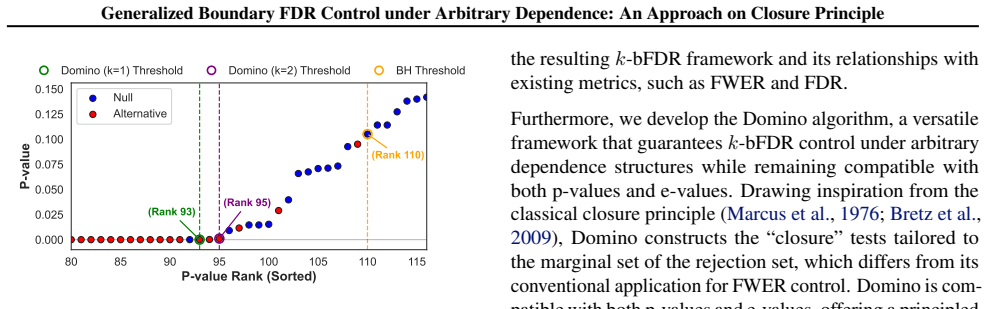
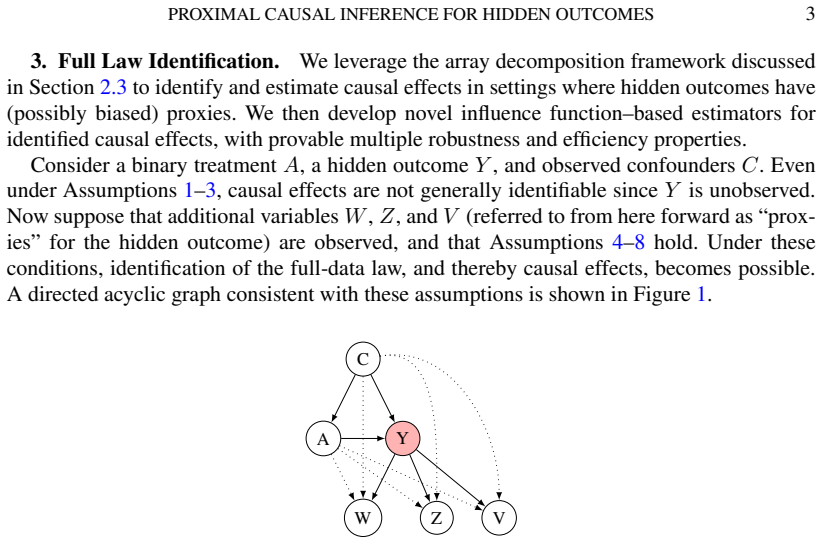
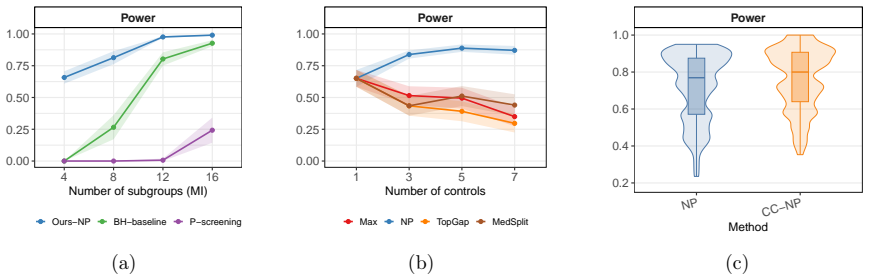
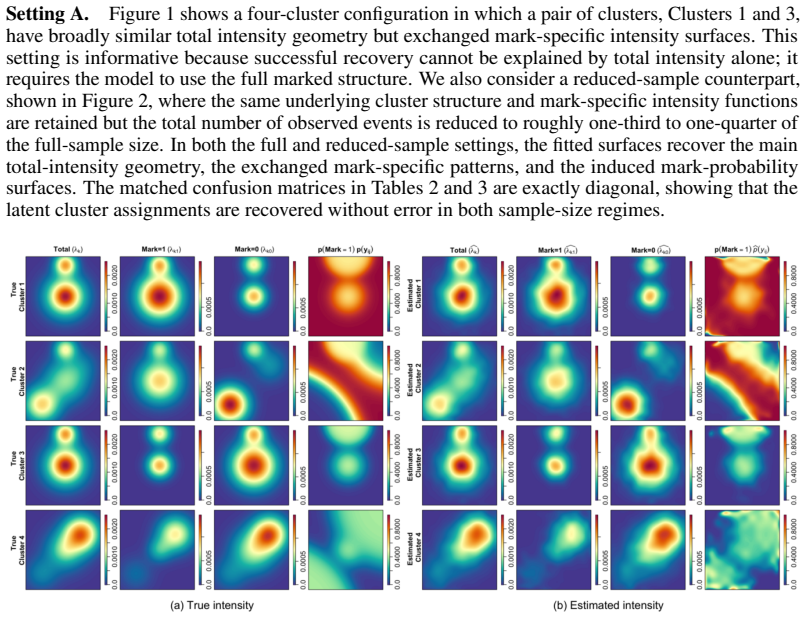
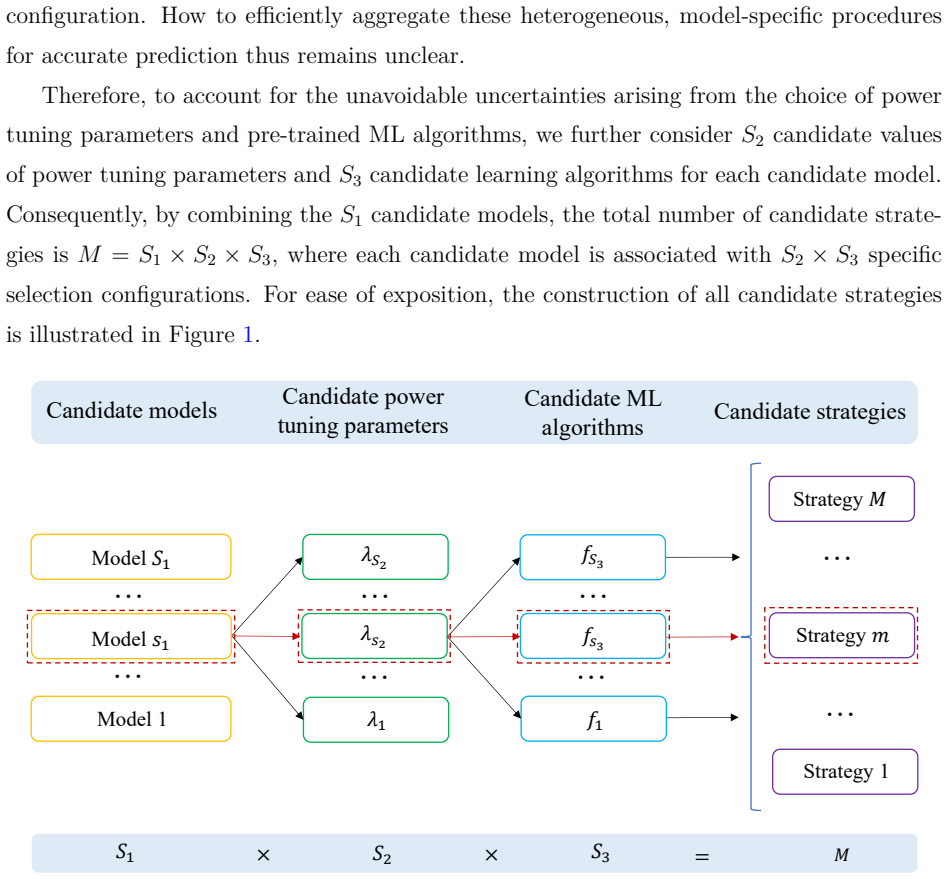
0
Surrogates estimate time-dependent failure probabilities efficiently
Time-variant reliability using time-dependent surrogate models
mNARX and F-NARX with biased designs capture tail responses in stochastic dynamical systems for first-passage analysis.
 full image
full image
abstract click to expand
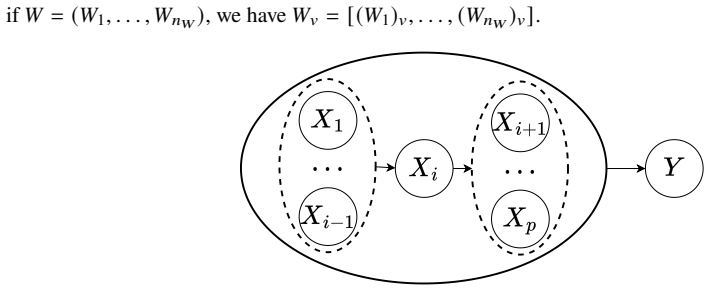
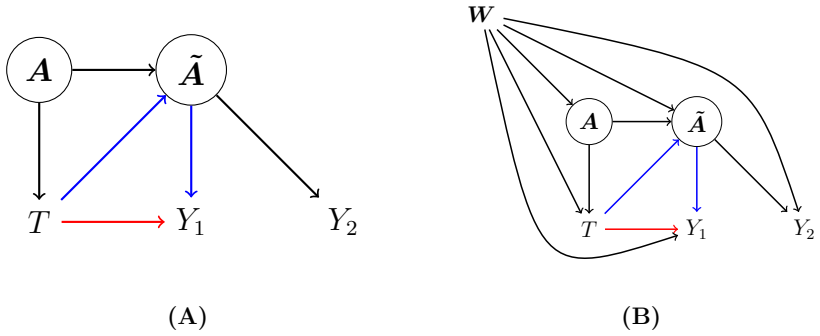
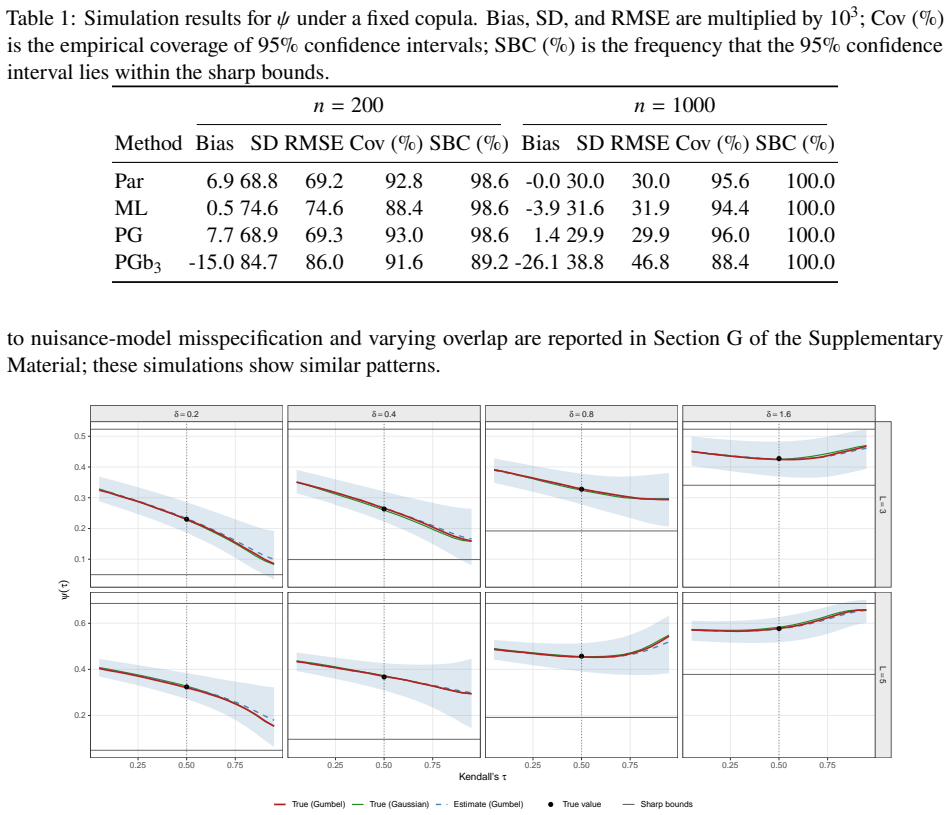
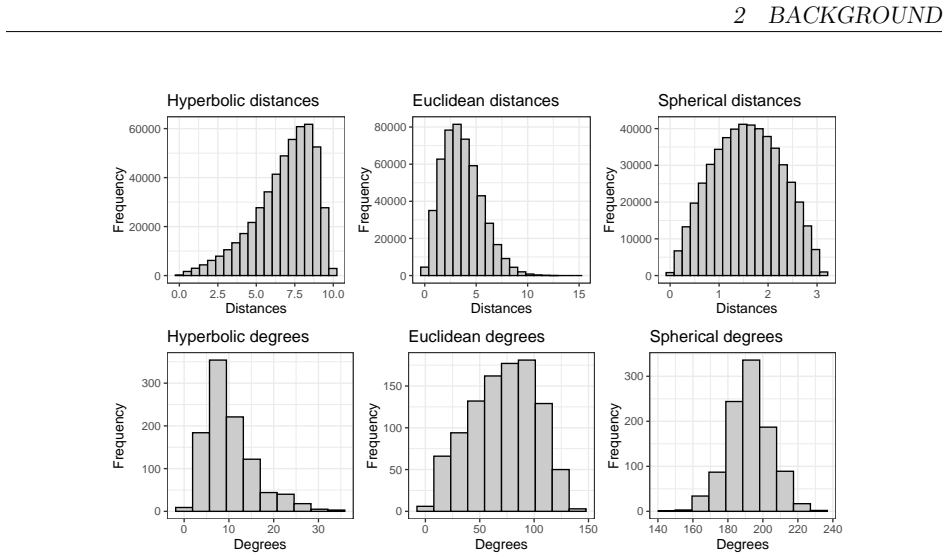
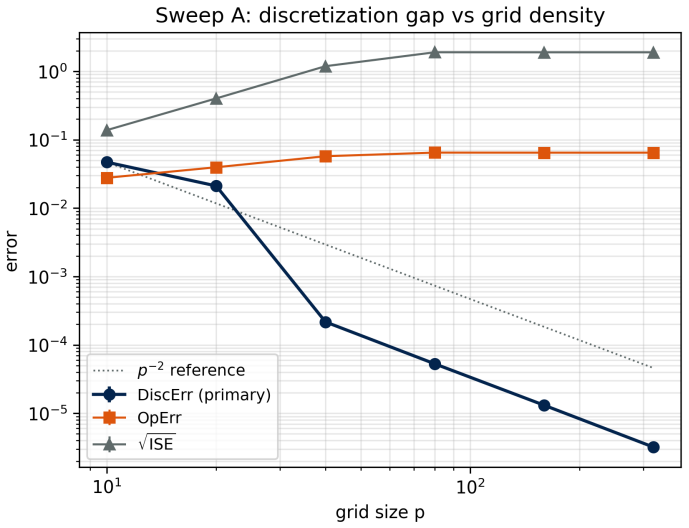
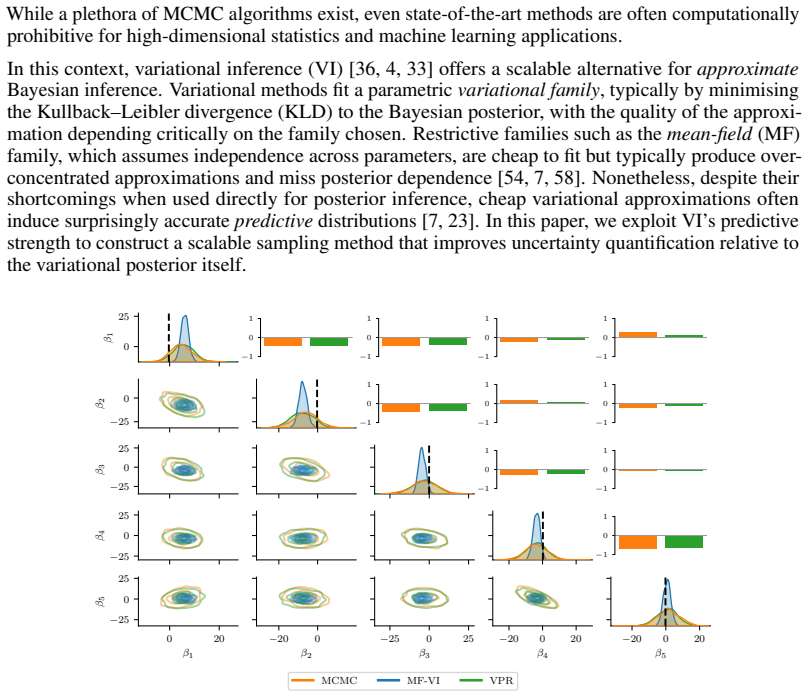
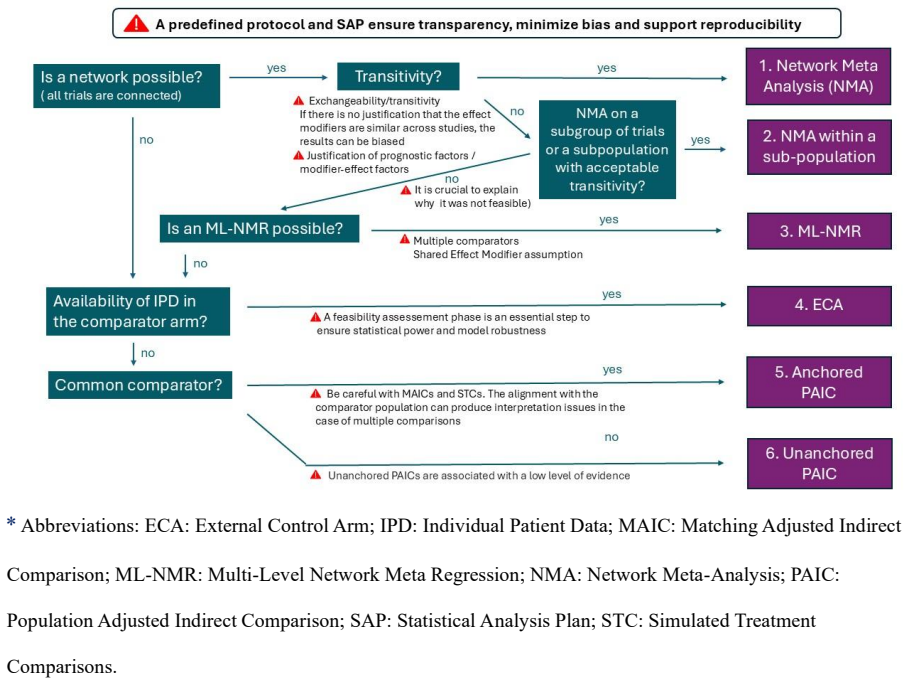
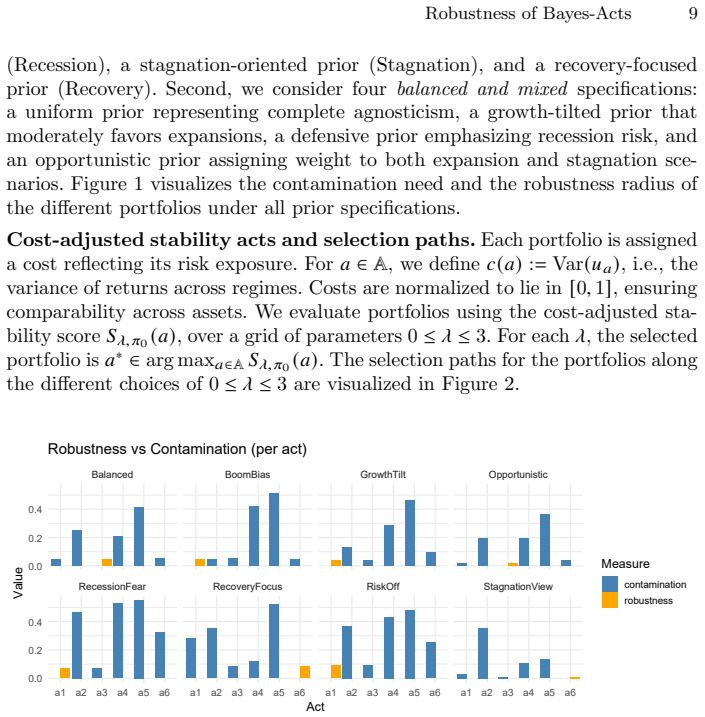
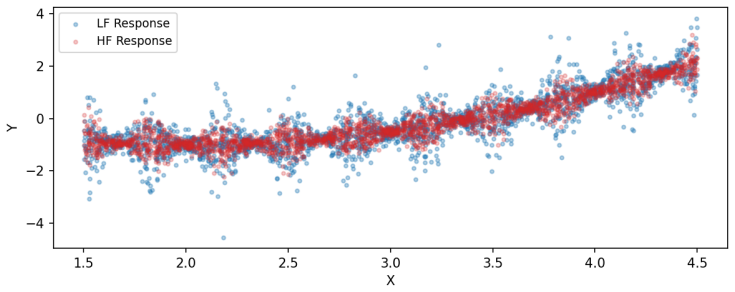
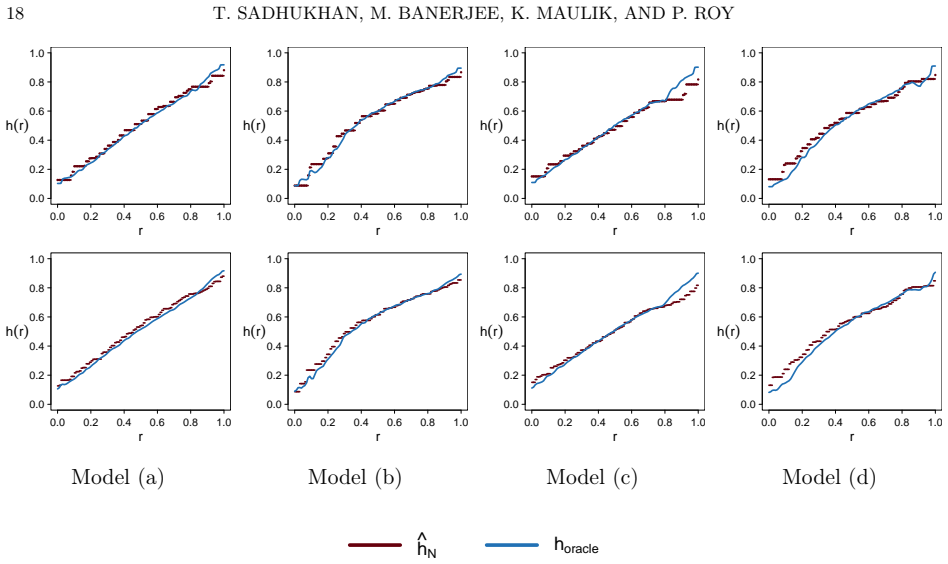
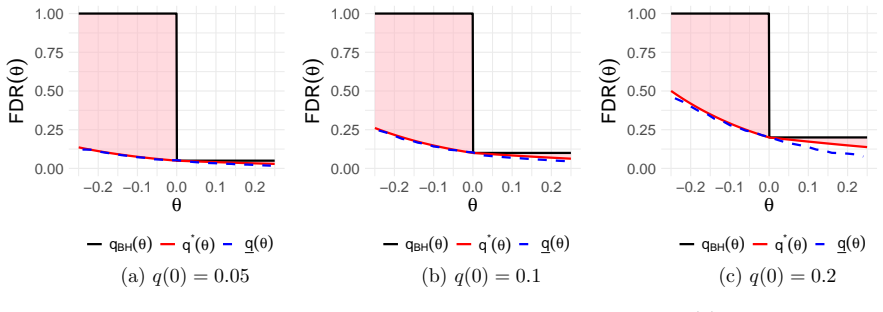
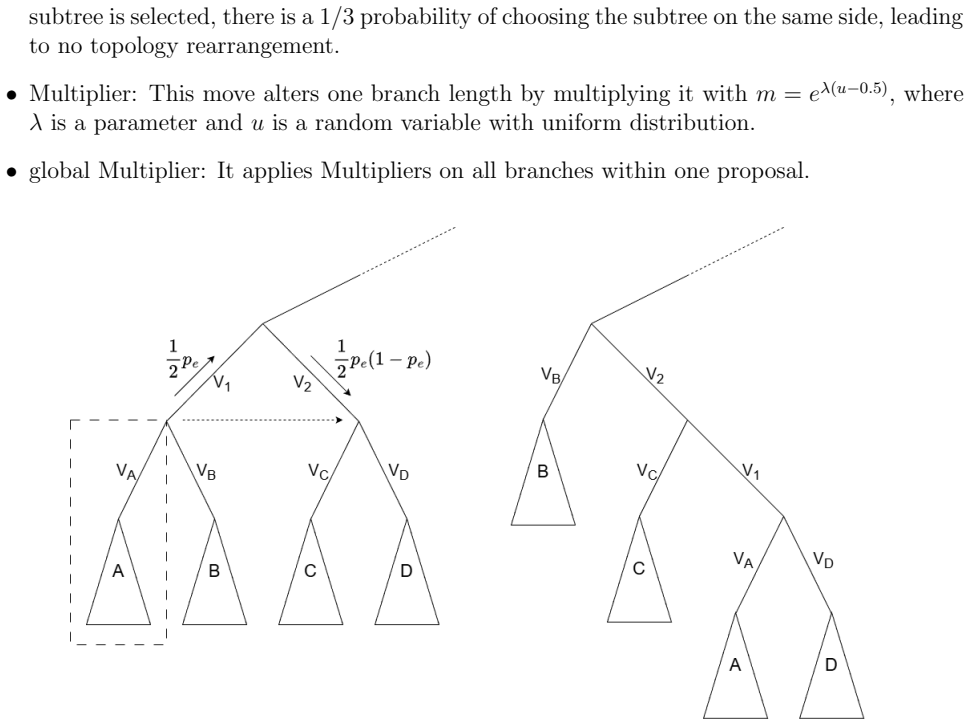
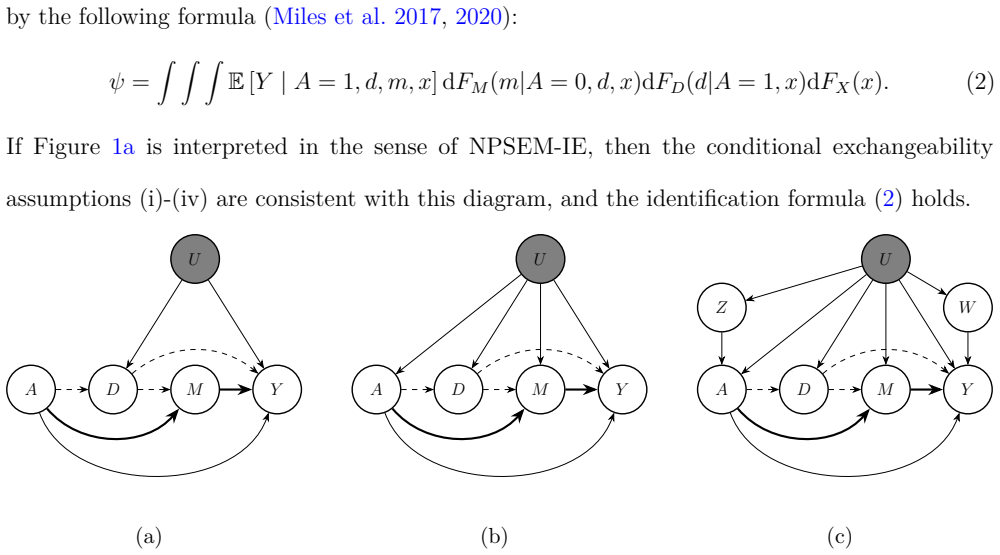
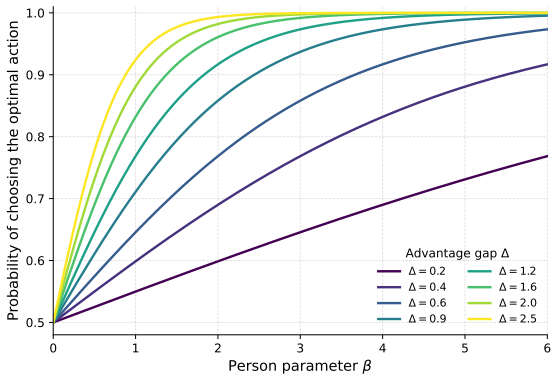
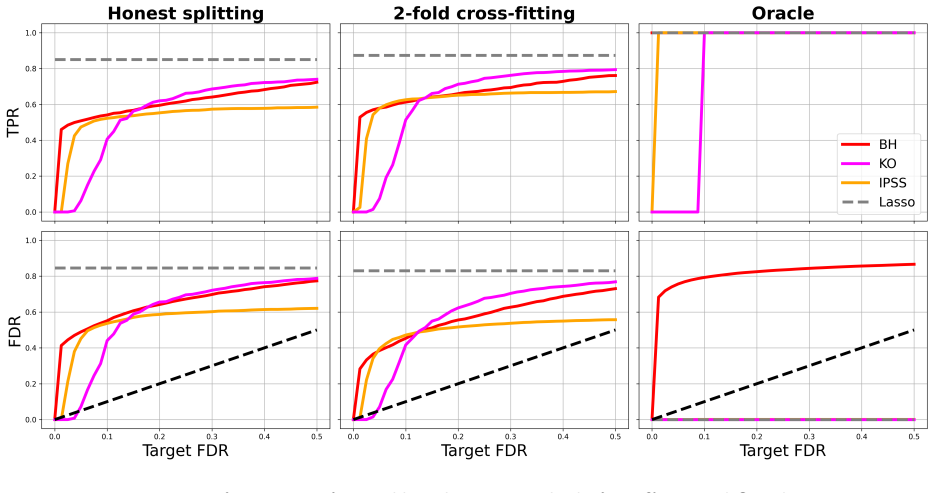
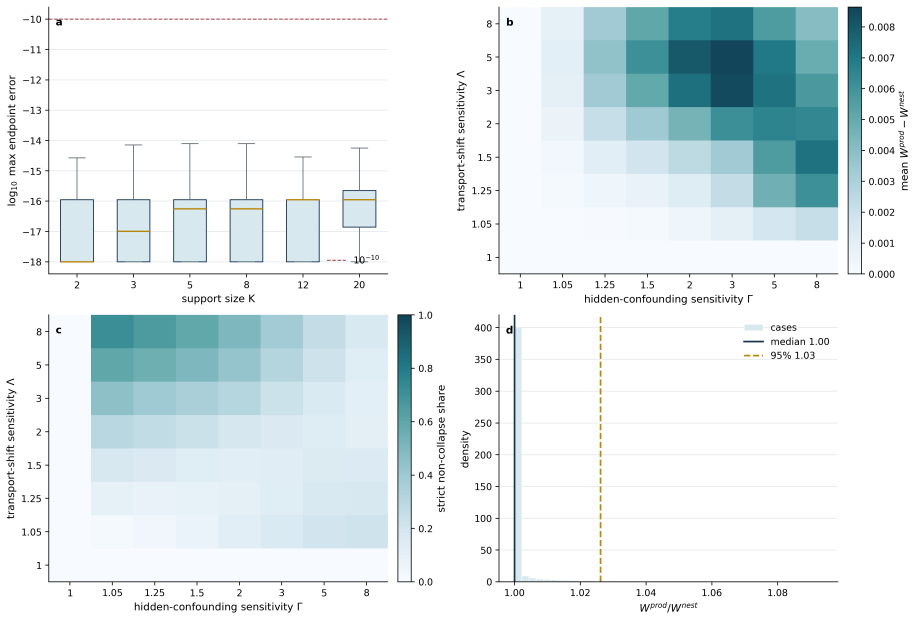
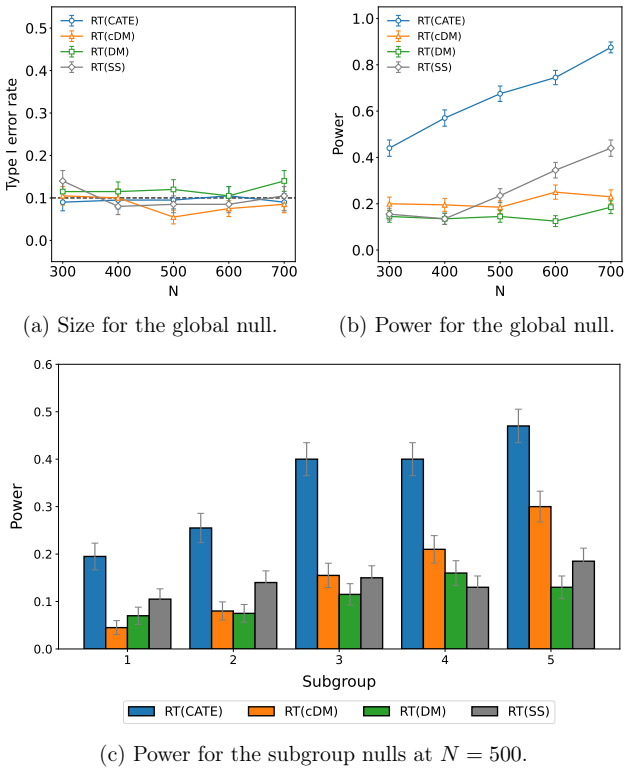
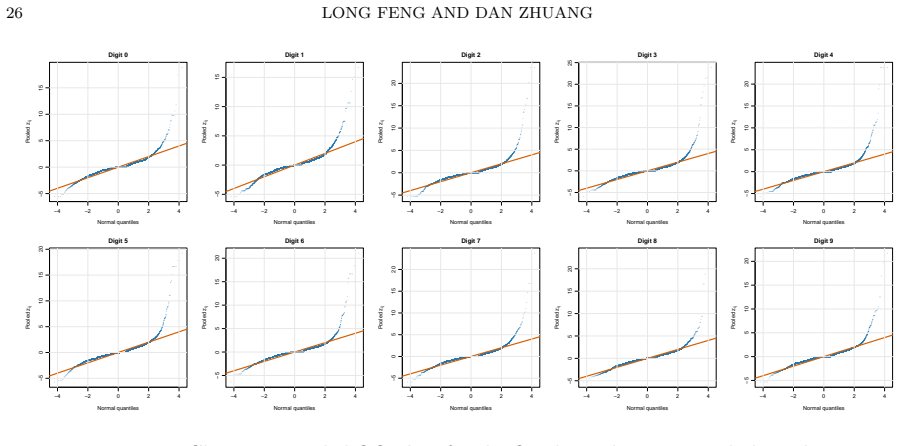
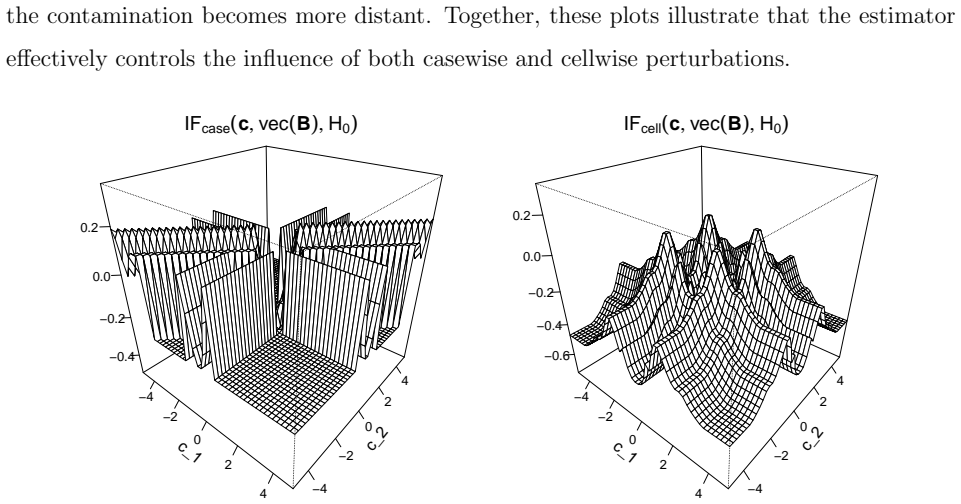
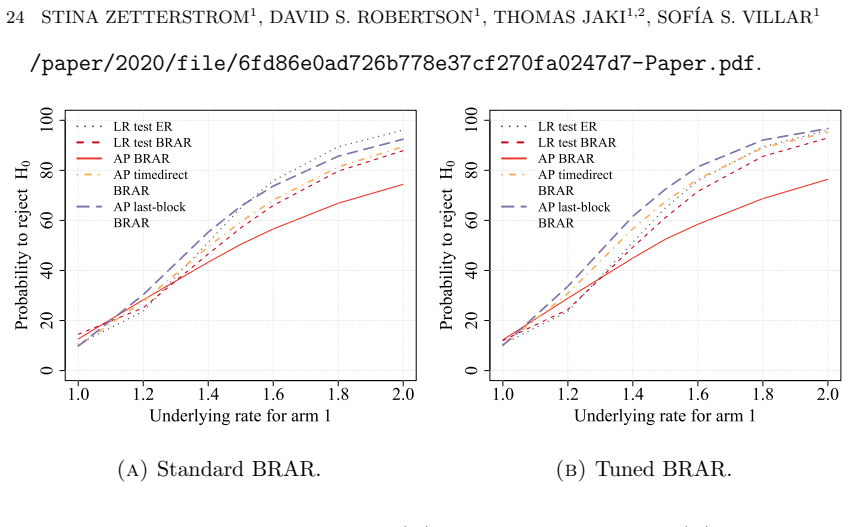
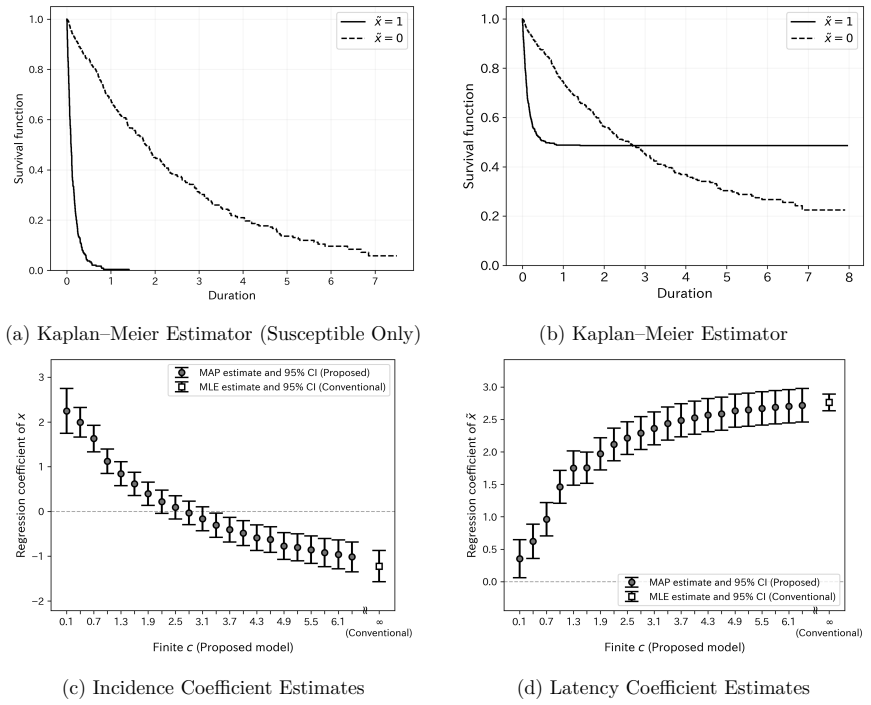
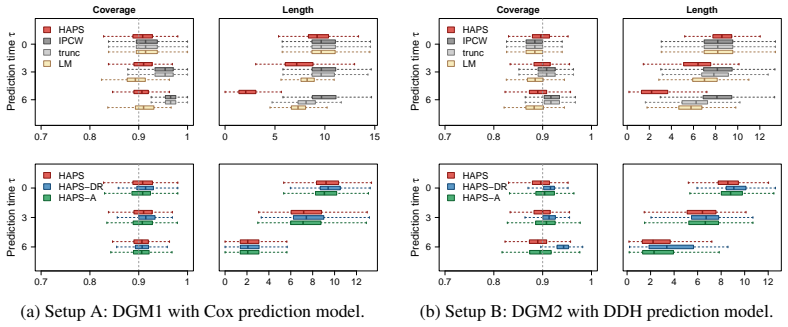
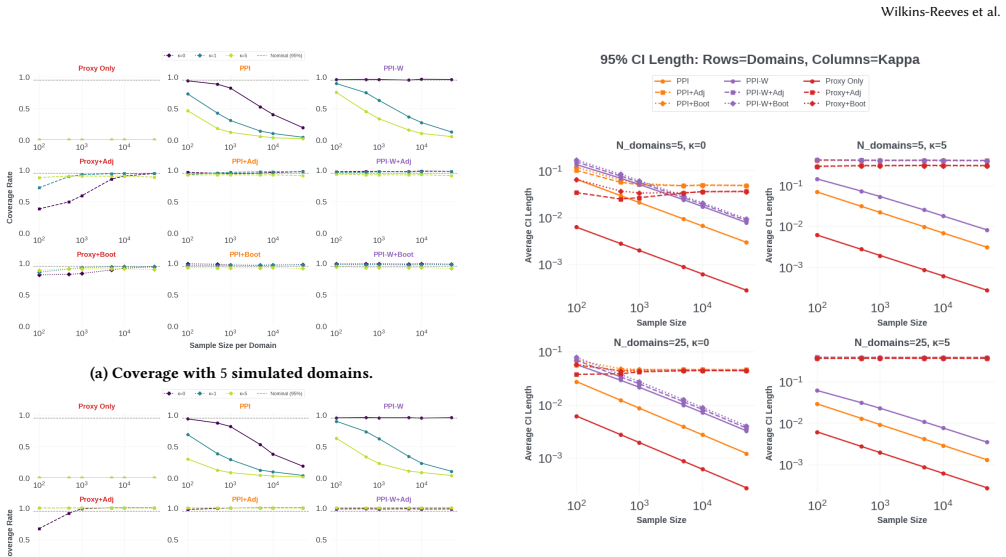
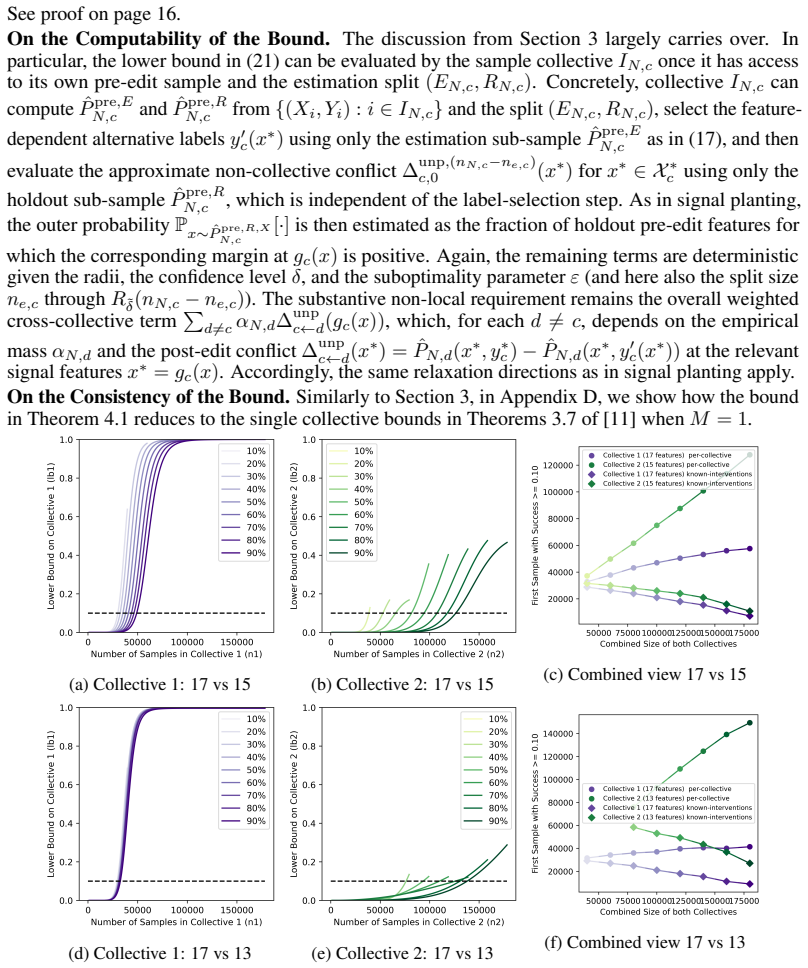
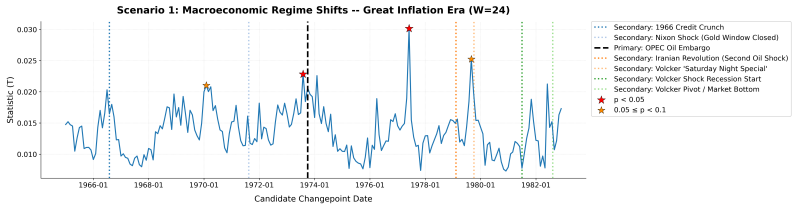
Time-variant reliability analysis is a critical task for ensuring the safety of engineering dynamical systems subjected to stochastic excitations. However, assessing failure probability for realistic systems with Monte-Carlo simulation-based methods is often computationally intractable due to the high cost of the underlying models and the large number of simulations required. While surrogate models such as polynomial chaos expansions or Kriging are well-established for time-invariant reliability problems, their direct application to time-dependent systems remains challenging. This chapter introduces two advanced surrogate modeling frameworks designed specifically for dynamical systems: manifold-NARX (mNARX) and functional NARX (F-NARX). The mNARX approach constructs the surrogate on a reduced-order manifold of auxiliary state variables, enabling the efficient handling of high-dimensional inputs by embedding physical insight into a regression formulation. Conversely, the F-NARX framework exploits the functional nature of system trajectories, extracting principal component features from continuous time windows to mitigate issues associated with discrete lag selection and long-memory effects. We demonstrate the efficacy of these methods on two benchmark reliability problems: a stochastic quarter-car model and a hysteretic Bouc-Wen oscillator. The results highlight that, when combined with suitably biased experimental designs, both frameworks accurately capture the tail behavior of the system response, enabling precise and efficient estimation of first-passage probabilities.