Q-fully Quadratic Modeling and its Application in a Random Subspace Derivative-free Method
Pith reviewed 2026-05-24 05:15 UTC · model grok-4.3
The pith
A random-subspace trust-region algorithm using quadratic models converges almost surely to small-gradient points for general objective functions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper constructs Q-fully quadratic models in randomly selected subspaces and embeds them in a trust-region algorithm that requires no special structure on the objective. Under standard smoothness assumptions, the geometry of the sample sets and the resulting approximation errors remain controlled with high probability in the subspaces. This yields an almost-sure global convergence guarantee together with an explicit upper bound on the expected number of iterations required to drive the gradient norm below any positive threshold.
What carries the argument
The Q-fully quadratic model, a quadratic approximation whose error bounds hold uniformly in randomly chosen subspaces and thereby support trust-region steps without full-space sampling.
If this is right
- The algorithm reaches points with arbitrarily small gradient almost surely.
- The expected iteration count to reach a given gradient tolerance is finite and explicitly bounded.
- Quadratic models can be built and analyzed in subspaces with the same tools used for linear models.
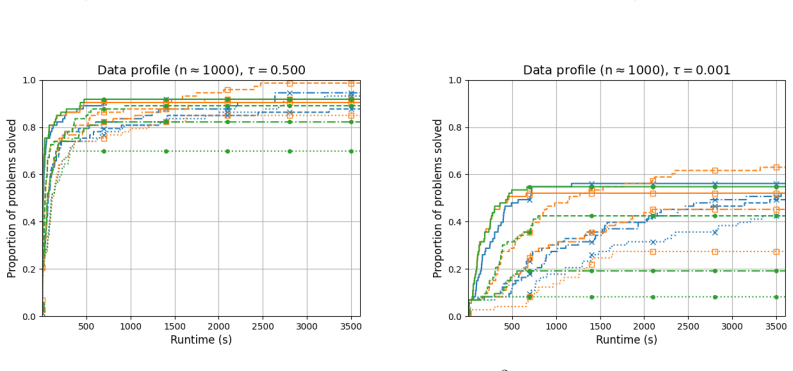
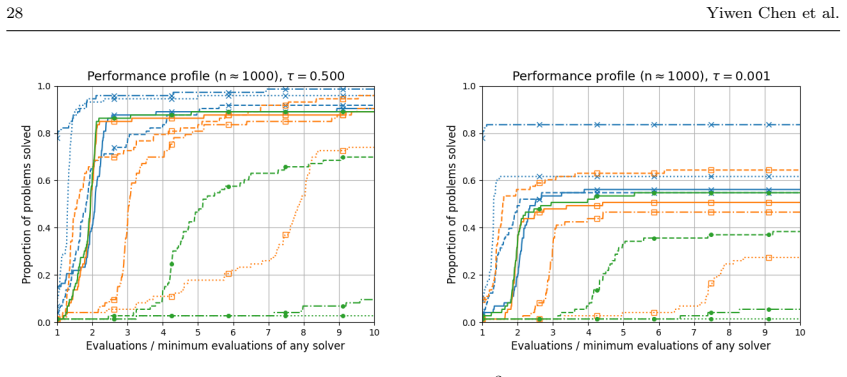
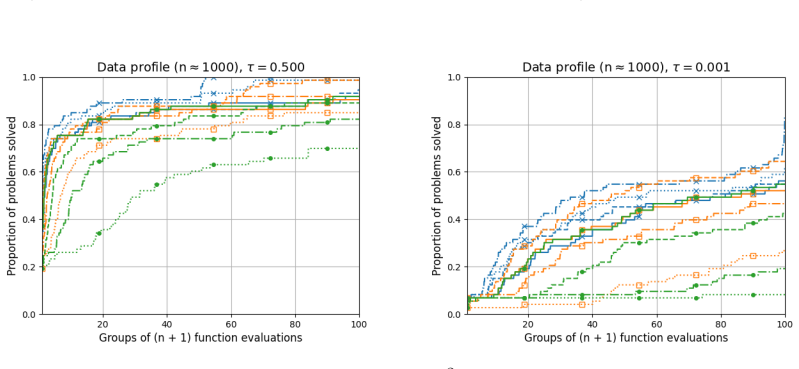
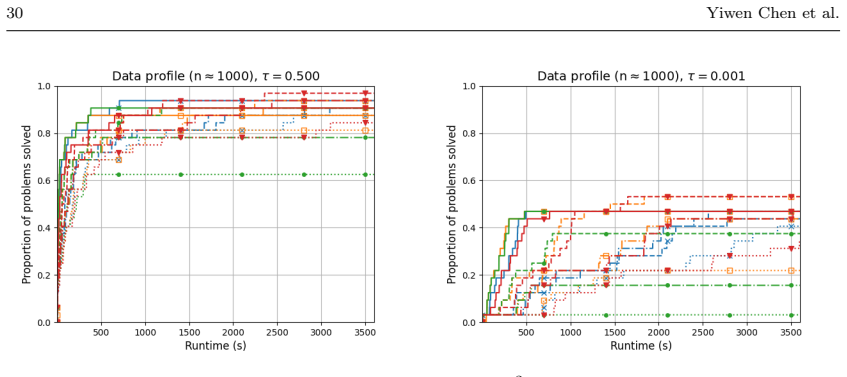
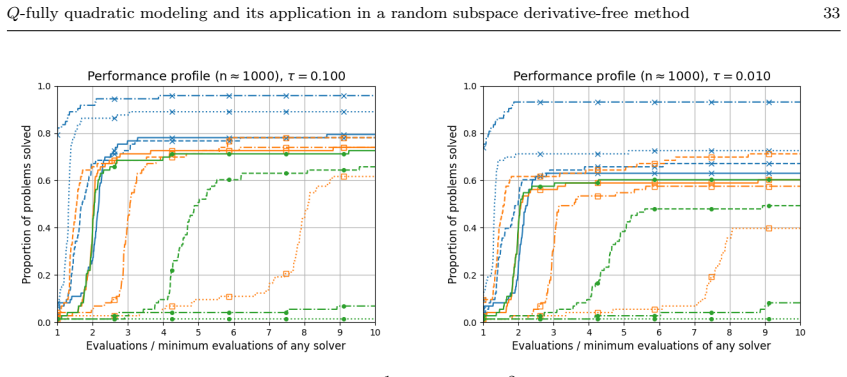
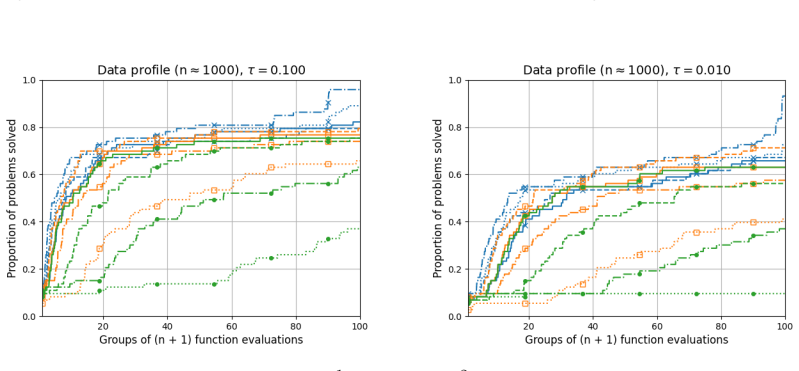
- Numerical comparisons reveal cases where quadratic models improve performance over linear ones and cases where they do not.
Where Pith is reading between the lines
- The same subspace model construction could be reused inside other derivative-free frameworks such as direct-search methods.
- The iteration bound may become practically useful once the subspace dimension and sampling parameters are tuned for a given problem class.
- Extending the analysis to noisy or stochastic objectives would require only modest changes to the error-bound arguments already developed.
Load-bearing premise
Random subspaces preserve the sample-set geometry and quadratic error bounds needed for the model construction to work on arbitrary smooth functions.
What would settle it
Run the algorithm on a smooth high-dimensional test function such as the Rosenbrock function and observe whether the gradient norm fails to drop below a fixed tolerance after more iterations than the derived expectation bound.
Figures




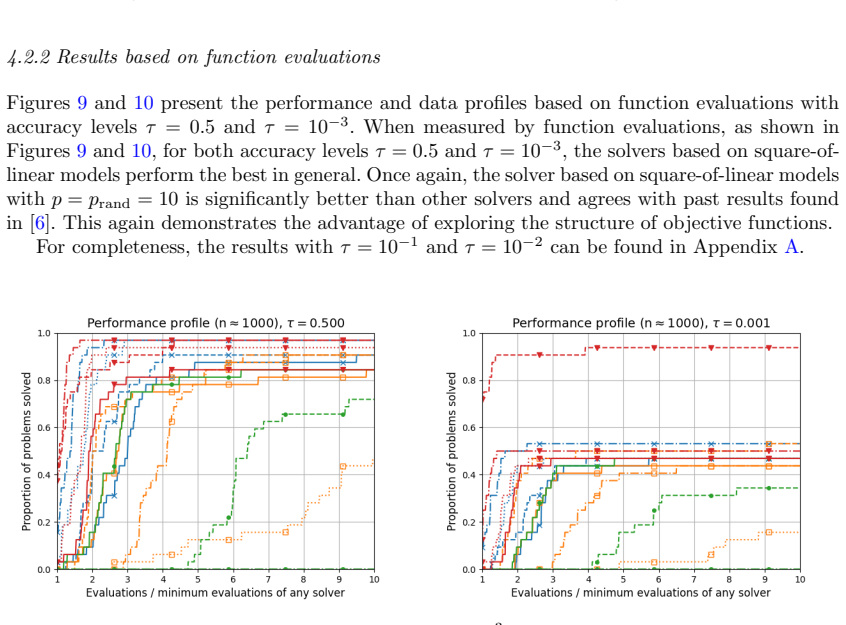
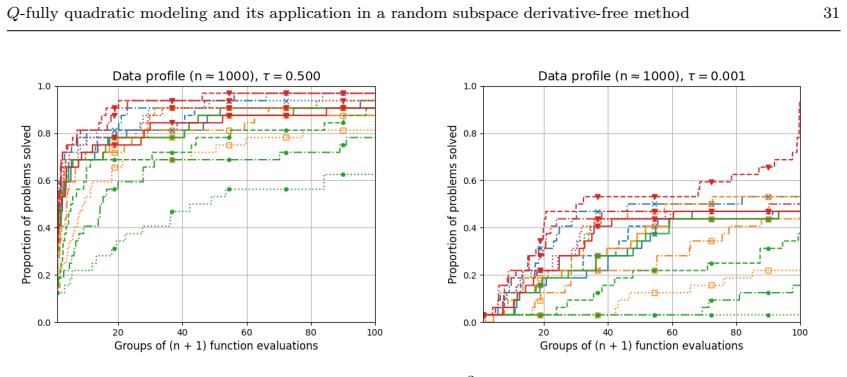
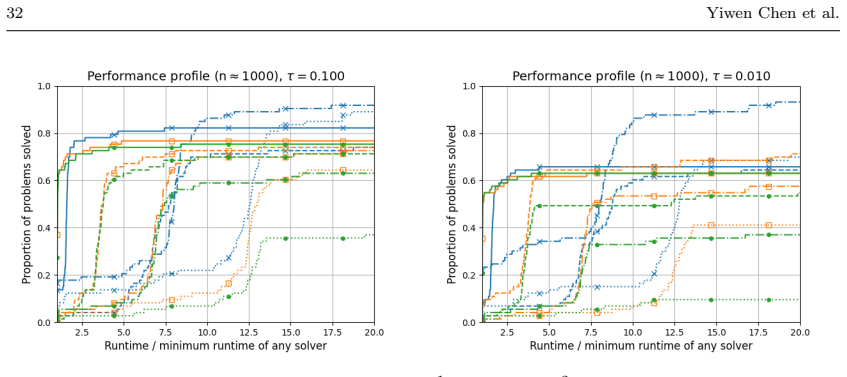
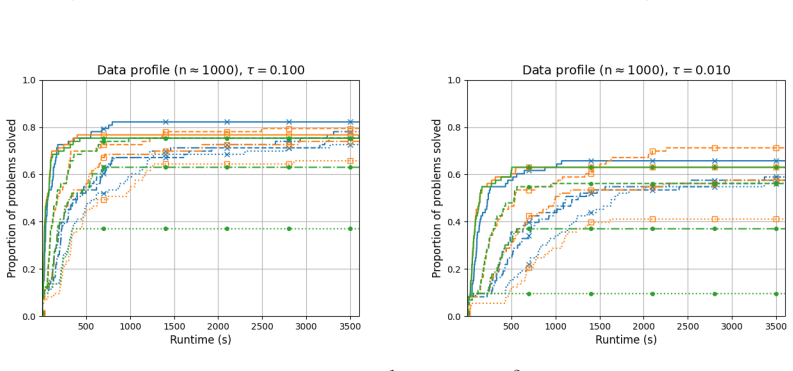




read the original abstract
Model-based derivative-free optimization (DFO) methods are an important class of DFO methods that are known to struggle with solving high-dimensional optimization problems. Recent research has shown that incorporating random subspaces into model-based DFO methods has the potential to improve their performance on high-dimensional problems. However, most of the current theoretical and practical results are based on linear approximation models due to the complexity of quadratic approximation models. This paper proposes a random subspace trust-region algorithm based on quadratic approximations. Unlike most of its precursors, this algorithm does not require any special form of objective function. We study the geometry of sample sets, the error bounds for approximations, and the quality of subspaces. In particular, we provide a technique to construct $Q$-fully quadratic models, which is easy to analyze and implement. We present an almost-sure global convergence result of our algorithm and give an upper bound on the expected number of iterations to find a sufficiently small gradient. We also develop numerical experiments to compare the performance of our algorithm using both linear and quadratic approximation models. The numerical results demonstrate the strengths and weaknesses of using quadratic approximations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a random-subspace trust-region algorithm for derivative-free optimization that employs quadratic (Q-fully quadratic) models rather than linear ones. It develops a construction technique for such models, analyzes the geometry of sample sets and approximation error bounds in randomly chosen subspaces, proves an almost-sure global convergence result together with an upper bound on the expected number of iterations needed to reach a sufficiently small gradient norm, and reports numerical comparisons of linear versus quadratic models on test problems. The method is stated to apply to general smooth objectives without special structure.
Significance. If the almost-sure convergence and iteration bound hold, the work would extend model-based DFO theory to quadratic approximations inside random subspaces for arbitrary objectives, addressing a recognized limitation of existing random-subspace methods that rely on linear models. The explicit construction technique for Q-fully quadratic models and the accompanying geometry/error analysis constitute concrete technical contributions that could be reused.
major comments (2)
- [§4] §4 (convergence analysis) and the subspace-quality section: the almost-sure convergence argument invokes Borel–Cantelli on the event that each random subspace yields a sufficiently poised sample set for a Q-fully quadratic model. No explicit lower bound on this probability that is independent of ambient dimension n and of the iteration index is supplied; without such a uniform positive lower bound the Borel–Cantelli step does not go through for general smooth f.
- [§3] Definition of Q-fully quadratic model and the error-bound statements (around Eq. (3.4)–(3.7)): the claimed O(Δ²) gradient and O(Δ) Hessian error bounds are asserted to hold with constants independent of the random subspace, yet the poisedness constants for the projected point set are allowed to depend on the particular realization of the subspace; this dependence must be controlled uniformly to justify the trust-region step analysis that follows.
minor comments (3)
- Notation for the random subspace projection operator is introduced without a dedicated symbol table or consistent use across sections.
- [Numerical experiments] Numerical section reports performance on a modest collection of CUTEst problems but does not include high-dimensional instances (n ≫ 100) that would directly test the claimed advantage of the random-subspace quadratic approach.
- A few typographical inconsistencies appear in the statement of the trust-region subproblem (e.g., the radius update rule).
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments. We address the two major comments point by point below. Both identify gaps in the current presentation of the probability bound and uniformity of constants; we will revise the manuscript to close these gaps.
read point-by-point responses
-
Referee: [§4] §4 (convergence analysis) and the subspace-quality section: the almost-sure convergence argument invokes Borel–Cantelli on the event that each random subspace yields a sufficiently poised sample set for a Q-fully quadratic model. No explicit lower bound on this probability that is independent of ambient dimension n and of the iteration index is supplied; without such a uniform positive lower bound the Borel–Cantelli step does not go through for general smooth f.
Authors: We agree that an explicit lower bound must be stated. Since the problem dimension n is fixed for any given instance, a positive lower bound that depends on n but is independent of the iteration index and of f is sufficient for the Borel–Cantelli argument. In the revision we will add a lemma deriving such a bound from the random-subspace sampling procedure and the geometry conditions of Section 3, thereby completing the almost-sure convergence proof for general smooth objectives. revision: yes
-
Referee: [§3] Definition of Q-fully quadratic model and the error-bound statements (around Eq. (3.4)–(3.7)): the claimed O(Δ²) gradient and O(Δ) Hessian error bounds are asserted to hold with constants independent of the random subspace, yet the poisedness constants for the projected point set are allowed to depend on the particular realization of the subspace; this dependence must be controlled uniformly to justify the trust-region step analysis that follows.
Authors: The current statements permit the poisedness constant to depend on the realized subspace, which could make the error constants non-uniform. We will revise Section 3 to establish a uniform upper bound on the poisedness constant that holds for all subspaces satisfying the quality condition used later in the analysis. With this uniform control the O(Δ²) gradient and O(Δ) Hessian bounds will hold with constants independent of the particular subspace realization, supporting the trust-region arguments in Section 4. revision: yes
Circularity Check
No circularity: convergence rests on independent analysis of random-subspace geometry and model error bounds
full rationale
The paper claims to provide an explicit technique for constructing Q-fully quadratic models in random subspaces, then derives almost-sure global convergence and an expected-iteration bound from the resulting geometry and approximation-error controls. No quoted step equates a derived quantity to a fitted parameter by construction, nor does any load-bearing premise reduce to a self-citation whose content is itself unverified. The derivation chain is therefore self-contained against external benchmarks (poisedness constants, error bounds) rather than tautological.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Objective function is sufficiently smooth for local quadratic approximations to exist with controllable error.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We provide a technique to construct Q-fully quadratic models... almost-sure global convergence result... upper bound on the expected number of iterations
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
σ_min(Dk) maximized... αD-well aligned... probability at least 1−δS
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
- [1]
-
[2]
M. Alzantot, Y. Sharma, S. Chakraborty, H. Zhang, C. Hsieh, and M. B. Srivastava , GenAttack: practical black-box attacks with gradient-free optimization , in Proceedings of the Genetic and Evolutionary Computation Conference, 2019, pp. 1111–1119
work page 2019
- [3]
-
[4]
C. Audet and W. Hare , Derivative-free and blackbox optimization , Springer, Cham, 2017
work page 2017
-
[5]
, Model-based methods in derivative-free nonsmooth optimization , Springer, Cham, 2020, pp. 655–691
work page 2020
-
[6]
C. Cartis and L. Roberts , Scalable subspace methods for derivative-free nonlinear least-squares optimiza- tion, Math. Program., 199 (2023), pp. 461–524
work page 2023
-
[7]
P. Chen, H. Zhang, Y. Sharma, J. Yi, and C. Hsieh, ZOO: zeroth order optimization based black-box attacks to deep neural networks without training substitute models , in Proceedings of the 10th ACM Workshop on Artificial Intelligence and Security, 2017, pp. 15–26
work page 2017
-
[8]
Y. Chen and W. Hare , Adapting the centred simplex gradient to compensate for misaligned sample points , IMA J. Numer. Anal., (2023). 36 Yiwen Chen et al
work page 2023
-
[9]
Y. Chen, W. Hare, and G. Jarry-Bolduc , Error analysis of surrogate models constructed through opera- tions on submodels , Math. Oper. Res., (2022)
work page 2022
-
[10]
A. Conn, K. Scheinberg, and L. N. Vicente, Geometry of interpolation sets in derivative free optimization , Math. Program., 111 (2008), pp. 141–172
work page 2008
-
[11]
, Geometry of sample sets in derivative-free optimization: polynomial regression and underdetermined interpolation, IMA J. Numer. Anal., 28 (2008), pp. 721–748
work page 2008
-
[12]
, Introduction to derivative-free optimization , SIAM, 2009
work page 2009
-
[13]
A. Conn, P. L. Toint, A. Sartenaer, and N. Gould , On iterated-subspace minimization methods for nonlinear optimization, tech. rep., Rutherford Appleton Laboratory, 1994
work page 1994
-
[14]
J. E. Dennis Jr. and R. B. Schnabel , Numerical methods for unconstrained optimization and nonlinear equations, SIAM, 1996
work page 1996
- [15]
-
[16]
M. Feurer and F. Hutter , Hyperparameter optimization, Springer, Cham, 2019, pp. 3–33
work page 2019
-
[17]
Fukushima, Parallel variable transformation in unconstrained optimization , SIAM J
M. Fukushima, Parallel variable transformation in unconstrained optimization , SIAM J. Optim., 8 (1998), pp. 658–672
work page 1998
-
[18]
Black-Box Optimization in Machine Learning with Trust Region Based Derivative Free Algorithm
H. Ghanbari and K. Scheinberg, Black-box optimization in machine learning with trust region based deriva- tive free algorithm , (2017). arXiv:1703.06925
work page internal anchor Pith review Pith/arXiv arXiv 2017
- [19]
-
[20]
G. N. Grapiglia, J. Yuan, and Y. Yuan , A subspace version of the Powell–Yuan trust-region algorithm for equality constrained optimization , J. Oper. Res. Soc. China, 1 (2013), pp. 425–451
work page 2013
-
[21]
S. Gratton, C. W. Royer, L. N. Vicente, and Z. Zhang , Direct search based on probabilistic descent , SIAM J. Optim., 25 (2015), pp. 1515–1541
work page 2015
-
[22]
W. Hare and G. Jarry-Bolduc, Calculus identities for generalized simplex gradients: rules and applications , SIAM J. Optim., 30 (2020), pp. 853–884
work page 2020
-
[23]
W. Hare, G. Jarry-Bolduc, and C. Planiden , A matrix algebra approach to approximate hessians , IMA J. Numer. Anal., (2023)
work page 2023
- [24]
-
[25]
R. A. Horn and C. R. Johnson , Topics in matrix analysis , Cambridge University Press, 1991
work page 1991
- [26]
-
[27]
Z. Li, F. Liu, W. Yang, S. Peng, and J. Zhou , A survey of convolutional neural networks: analysis, applications, and prospects , IEEE Trans. Neural Netw. Learn. Syst., (2021)
work page 2021
- [28]
-
[29]
J. J. Mor ´e and S. M. Wild , Benchmarking derivative-free optimization algorithms , SIAM J. Optim., 20 (2009), pp. 172–191
work page 2009
-
[30]
R. Penrose, A generalized inverse for matrices , in Mathematical Proceedings of the Cambridge Philosophical Society, vol. 51, Cambridge University Press, 1955, pp. 406–413
work page 1955
-
[31]
M. J. D. Powell, The NEWUOA software for unconstrained optimization without derivatives , Springer US, Boston, MA, 2006, pp. 255–297
work page 2006
-
[32]
, Developments of NEWUOA for minimization without derivatives , IMA J. Numer. Anal., 28 (2008), pp. 649–664
work page 2008
-
[33]
rep., University of Cambridge, 2009
, The BOBYQA algorithm for bound constrained optimization without derivatives , tech. rep., University of Cambridge, 2009
work page 2009
-
[34]
L. Roberts and C. W. Royer , Direct search based on probabilistic descent in reduced spaces , SIAM J. Optim., 33 (2023), pp. 3057–3082
work page 2023
-
[35]
Z. Zhang, On derivative-free optimization methods (in Chinese) , PhD thesis, Chinese Academy of Sciences,
-
[36]
https://www.zhangzk.net/docs/publications/thesis.pdf
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.