On the error control of invariant causal prediction
Pith reviewed 2026-05-24 04:22 UTC · model grok-4.3
The pith
Reformulating invariant causal prediction as a multiple testing problem enables false discovery rate control and simultaneous true discovery bounds while preserving causal guarantees.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By reformulating invariant causal prediction as a multiple testing problem, the authors apply the e-Closure principle together with tailored p-to-e calibrators to obtain simultaneous false discovery rate control, and derive simultaneous true discovery bounds via closed testing; these guarantees are more liberal than the original no-false-discovery requirement, retain every discovery made by the original method, require no additional assumptions, and continue to respect the invariance properties across multiple environments.
What carries the argument
The reformulation of invariant causal prediction as a multiple testing problem, which permits direct application of the e-Closure principle for false discovery rate control and closed testing for true discovery bounds.
If this is right
- More causal predictors can be identified in data sets where the original invariant causal prediction method returns none.
- False discovery rate control at a user-specified level is obtained while keeping all original discoveries.
- Simultaneous true discovery bounds supply additional quantitative causal information on the number of true predictors.
- The procedures apply directly to the same heterogeneous data collected from multiple environments.
- No extra assumptions beyond those of the original method are required.
Where Pith is reading between the lines
- The multiple-testing view may allow other invariance-based causal methods to adopt similar error-control upgrades.
- In high-dimensional settings the added power could support more stable downstream prediction models built on the discovered causal features.
- The US educational attainment application indicates the approach can be used in observational social-science studies that feature environmental heterogeneity.
Load-bearing premise
Reformulating invariant causal prediction as a multiple testing problem must preserve the original invariance properties and permit valid error control without introducing invalid rates or losing causal guarantees.
What would settle it
A simulation study or new dataset in which the proportion of false causal discoveries among those reported under the e-Closure procedure exceeds the nominal false discovery rate level, or in which the simultaneous true discovery bounds are violated when predictors are tested in additional held-out environments.
Figures
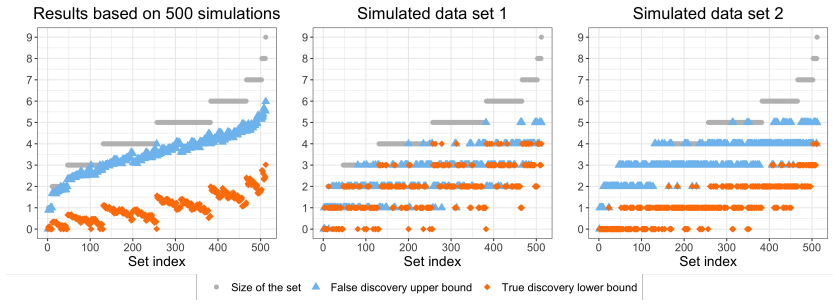
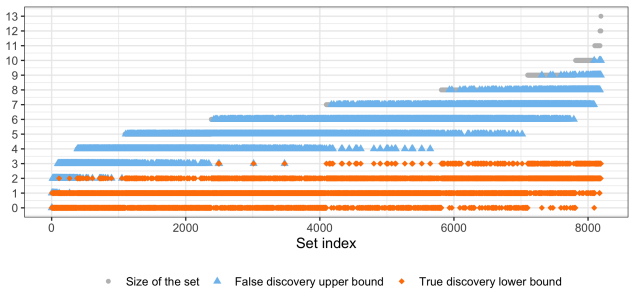
read the original abstract
Invariant causal prediction provides a useful framework for identifying causal predictors of a response using heterogeneous data from multiple environments. One valuable property of the original invariant causal prediction method is that it guarantees no false causal discoveries with high probability. Such a guarantee, however, can be overly conservative in some applications, resulting in few or no causal discoveries. This raises a natural question: can invariant causal prediction be equipped with less conservative error guarantees and thereby extract more causal information from the data? In this paper, we address this question by focusing on two widely used and more liberal guarantees: false discovery rate control and simultaneous true discovery bounds. A key step in our approach is to reformulate invariant causal prediction as a multiple testing problem. We then adopt the e-Closure principle to obtain (simultaneous) false discovery rate control, together with new p-to-e calibrators tailored to this setting. We also derive simultaneous true discovery bounds via closed testing, which provide additional causal information without requiring extra assumptions and retain all discoveries from the original invariant causal prediction method. Through simulations and a real data application on educational attainment of teenagers in the United States, we show that these more liberal error control guarantees can improve the practical usefulness of invariant causal prediction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reformulates invariant causal prediction (ICP) as a multiple-testing problem to equip it with false discovery rate (FDR) control via the e-Closure principle and simultaneous true-discovery bounds via closed testing. New p-to-e calibrators are derived for the ICP setting. Simulations and a real-data example on educational attainment are used to argue that the resulting procedures are less conservative than the original ICP while retaining its causal guarantees and recovering all of its discoveries.
Significance. If the reformulation preserves the original per-predictor invariance nulls and the validity of the error-rate guarantees under heterogeneous environments, the work would meaningfully increase the practical utility of ICP by permitting more discoveries without additional assumptions. The provision of both simulation evidence and a real-data application is a positive feature.
major comments (3)
- [§3] §3 (reformulation as multiple testing): the claim that the individual null hypotheses in the MT formulation are exactly equivalent to the original ICP invariance nulls (and therefore inherit the same causal interpretation) is not shown explicitly; a direct statement equating the two families of nulls, including how environment-induced dependence is handled, is needed to confirm that the FDR and TDB guarantees remain causally valid.
- [§4.2] §4.2 (p-to-e calibrators): the derivation of the new calibrators is presented without an explicit verification that they remain valid under the heterogeneous-environment measure used by ICP; if the calibrators rely on exchangeability or identical distribution across environments, this must be stated and justified, as any mismatch would invalidate the subsequent e-Closure application.
- [§5] §5 (simulations): the reported power gains are shown only for the new procedures; a direct comparison table that also reports the original ICP output (number of discoveries and empirical FDR) on the same replicates is required to substantiate the claim that the liberal guarantees improve usefulness without inflating false discoveries beyond the nominal level.
minor comments (2)
- Notation for the environment index and the set of candidate predictors is introduced inconsistently between the abstract, §2, and §3; a single consistent notation should be used throughout.
- [§6] The real-data application in §6 would benefit from a brief description of how the environments were defined and whether any preprocessing steps (e.g., missing-data handling) could affect the invariance assumption.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment below and will revise the manuscript accordingly to improve clarity and strengthen the presentation of our results.
read point-by-point responses
-
Referee: [§3] §3 (reformulation as multiple testing): the claim that the individual null hypotheses in the MT formulation are exactly equivalent to the original ICP invariance nulls (and therefore inherit the same causal interpretation) is not shown explicitly; a direct statement equating the two families of nulls, including how environment-induced dependence is handled, is needed to confirm that the FDR and TDB guarantees remain causally valid.
Authors: We agree that an explicit equating of the null hypotheses would improve the manuscript. In the revised version we will insert a dedicated paragraph in §3 that states the precise equivalence between the individual invariance nulls in the multiple-testing formulation and the original ICP nulls, together with an explanation of how the dependence induced by the heterogeneous environments is handled through the test statistics. This addition will confirm that the FDR and TDB guarantees inherit the causal validity of the original ICP procedure. revision: yes
-
Referee: [§4.2] §4.2 (p-to-e calibrators): the derivation of the new calibrators is presented without an explicit verification that they remain valid under the heterogeneous-environment measure used by ICP; if the calibrators rely on exchangeability or identical distribution across environments, this must be stated and justified, as any mismatch would invalidate the subsequent e-Closure application.
Authors: The calibrators are constructed to be valid under the heterogeneous-environment measure that underlies ICP and do not assume exchangeability or identical distributions across environments. In the revision we will add an explicit verification paragraph in §4.2 that derives the validity of the calibrators directly from the invariance property under the null, thereby justifying their use with the e-Closure principle. revision: yes
-
Referee: [§5] §5 (simulations): the reported power gains are shown only for the new procedures; a direct comparison table that also reports the original ICP output (number of discoveries and empirical FDR) on the same replicates is required to substantiate the claim that the liberal guarantees improve usefulness without inflating false discoveries beyond the nominal level.
Authors: We agree that a side-by-side comparison on identical replicates would strengthen the simulation section. We will add a table in §5 that reports, for every replicate, the number of discoveries and the empirical FDR achieved by the original ICP procedure alongside the corresponding quantities for the new procedures, thereby allowing direct assessment of power gains while confirming that error rates remain controlled. revision: yes
Circularity Check
No significant circularity; reformulation applies standard MT tools to ICP
full rationale
The paper's core contribution is reformulating ICP as a multiple-testing problem to enable e-Closure for FDR control and closed testing for simultaneous true-discovery bounds. This step is presented as a direct mapping that preserves original invariance properties, with no equations showing that the new error guarantees are defined in terms of themselves or fitted parameters. No self-citations are load-bearing for the central claims, no uniqueness theorems are imported from the authors' prior work, and no ansatzes or renamings reduce the results to tautologies. The derivation rests on independent standard multiple-testing machinery (e-Closure, closed testing) applied to the existing ICP nulls, making the approach self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption p-values or e-values obtained from the multiple environments are valid for the multiple-testing reformulation
Forward citations
Cited by 1 Pith paper
-
A Uniform Improvement of the Benjamini-Hochberg Procedure via e-Closure
Closed BH improves the Benjamini-Hochberg procedure via e-Closure, controlling FDR under PRDS or weaker assumptions while never rejecting fewer hypotheses.
Reference graph
Works this paper leans on
-
[1]
Benjamini, Y. and Hochberg, Y. (1995). Controlling the false discovery rate: a practical and powerful approach to multiple testing. Journal of the Royal statistical society: series B (Methodological) , 57(1):289--300
work page 1995
-
[2]
Benjamini, Y. and Yekutieli, D. (2001). The control of the false discovery rate in multiple testing under dependency. Annals of statistics , pages 1165--1188
work page 2001
-
[3]
Dudoit, S., Van der Laan, M. J., and Pollard, K. S. (2004). Multiple testing. part i. single-step procedures for control of general type i error rates. Statistical Applications in Genetics and Molecular Biology , 3(1)
work page 2004
-
[4]
Finner, H., Dickhaus, T., and Roters, M. (2009). On the false discovery rate and an asymptotically optimal rejection curve. Ann. Statist. , 37(1):596--618
work page 2009
-
[5]
Genovese, C. R. and Wasserman, L. (2006). Exceedance control of the false discovery proportion. Journal of the American Statistical Association , 101(476):1408--1417
work page 2006
-
[6]
J., Hemerik, J., and Solari, A
Goeman, J. J., Hemerik, J., and Solari, A. (2021). Only closed testing procedures are admissible for controlling false discovery proportions. The Annals of Statistics , 49(2):1218--1238
work page 2021
-
[7]
Goeman, J. J. and Solari, A. (2011). Multiple testing for exploratory research. Statistical Science , 26(4):584--597
work page 2011
-
[8]
Heinze-Deml, C., Peters, J., and Meinshausen, N. (2018). Invariant causal prediction for nonlinear models. Journal of Causal Inference , 6(2)
work page 2018
-
[9]
Holm, S. (1979). A simple sequentially rejective multiple test procedure. Scandinavian journal of statistics , pages 65--70
work page 1979
-
[10]
R., Hothorn, T., and Peters, J
Kook, L., Saengkyongam, S., Lundborg, A. R., Hothorn, T., and Peters, J. (2023). Model-based causal feature selection for general response types. arXiv preprint arXiv:2309.12833
-
[11]
Korn, E. L., Troendle, J. F., McShane, L. M., and Simon, R. (2004). Controlling the number of false discoveries: application to high-dimensional genomic data. Journal of Statistical Planning and Inference , 124(2):379--398
work page 2004
-
[12]
Lehmann, E. L. and Romano, J. P. (2005). Generalizations of the familywise error rate . The Annals of Statistics , 33(3):1138 -- 1154
work page 2005
-
[13]
Marcus, R., Eric, P., and Gabriel, K. R. (1976). On closed testing procedures with special reference to ordered analysis of variance. Biometrika , 63(3):655--660
work page 1976
-
[14]
Peters, J., B \"u hlmann, P., and Meinshausen, N. (2016). Causal inference by using invariant prediction: identification and confidence intervals. Journal of the Royal Statistical Society: Series B (Statistical Methodology) , 78(5):947--1012
work page 2016
-
[15]
Pfister, N., B \"u hlmann, P., and Peters, J. (2019). Invariant causal prediction for sequential data. Journal of the American Statistical Association , 114(527):1264--1276
work page 2019
-
[16]
Romano, J. P. and Shaikh, A. M. (2006). Stepup procedures for control of generalizations of the familywise error rate. The Annals of Statistics , pages 1850--1873
work page 2006
-
[17]
Rouse, C. E. (1995). Democratization or diversion? the effect of community colleges on educational attainment. Journal of Business & Economic Statistics , 13(2):217--224
work page 1995
-
[18]
Sarkar, S. K. (2007). Stepup procedures controlling generalized fwer and generalized fdr. The Annals of Statistics , pages 2405--2420
work page 2007
-
[19]
Stock, J. H., Watson, M. W., et al. (2003). Introduction to econometrics , volume 104. Addison Wesley Boston
work page 2003
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.