Word-specific tonal realizations in Mandarin
Pith reviewed 2026-05-24 01:21 UTC · model grok-4.3
The pith
Word type and contextual meaning shape Mandarin tonal realizations more strongly than form-related factors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Tonal realization is partially determined by words' meanings. After controlling for effects of speaker and context, word type is a stronger predictor of tonal realization than all the previously established word-form related predictors combined. The addition of information about meaning in context improves prediction accuracy even further. Token-specific pitch contours predict word type with 50% accuracy on held-out data, and context-sensitive, token-specific embeddings can predict the shape of pitch contours with 40% accuracy.
What carries the argument
Generalized additive regression model isolating word-type effects after controlling for form predictors, and bidirectional computational modeling with context-specific word embeddings.
If this is right
- Lexical meaning directly affects the phonetic realization of tones in Mandarin.
- The link between pitch contours and word meanings is strong enough to be potentially functional in language use.
- Standard models of tonal production must be extended to include semantic factors.
- Acoustic models for word recognition can leverage these tonal variations for better performance.
Where Pith is reading between the lines
- Listeners might exploit word-specific tone variations to resolve ambiguities in conversation.
- Speech technology for tonal languages could benefit from incorporating word identity into tone generation models.
- Similar effects may be present in other tonal languages and warrant investigation.
Load-bearing premise
The generalized additive model successfully isolates the effects of word type by fully controlling for all word-form related predictors without any remaining confounding.
What would settle it
Finding that the prediction accuracy for word type from pitch contours drops to near chance level when tested on completely new speakers and contexts, or that adding word type does not improve the regression model fit after the form predictors.
Figures

read the original abstract
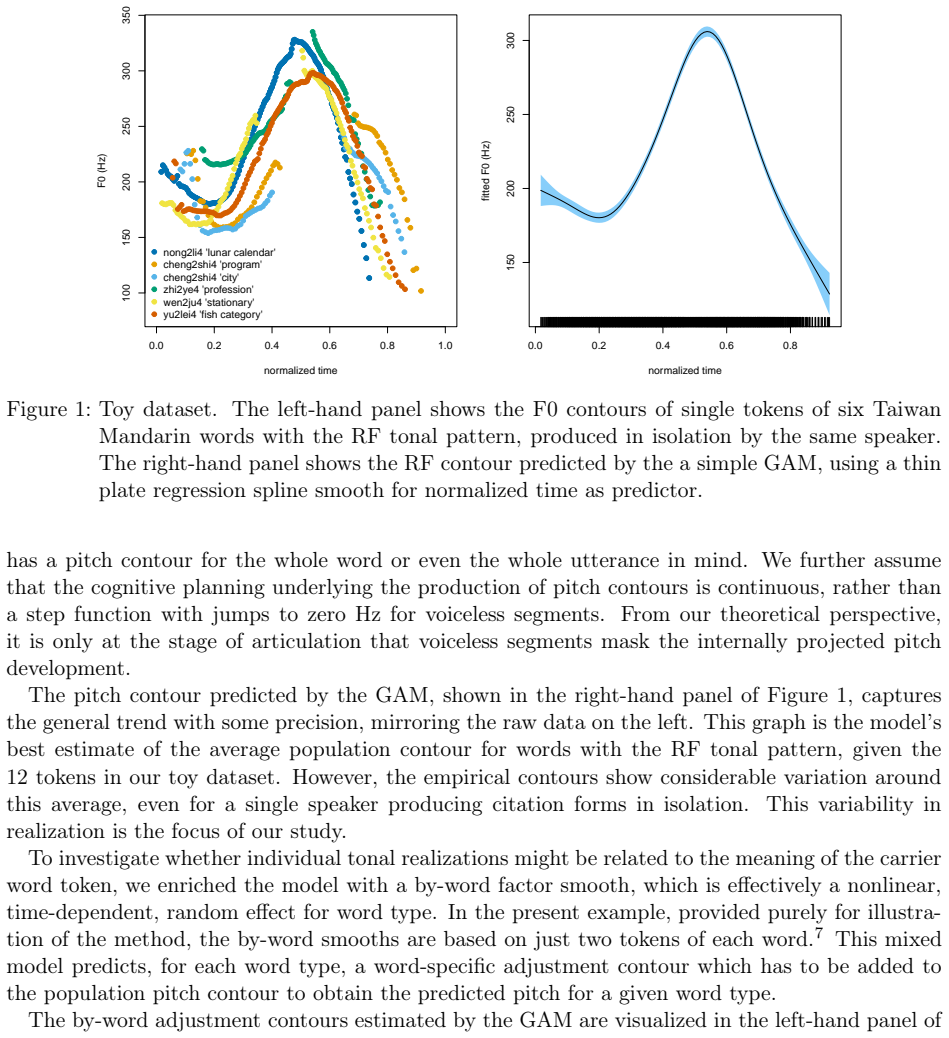
The pitch contours of Mandarin two-character words are generally understood as being shaped by the underlying tones of the constituent single-character words, in interaction with articulatory constraints imposed by factors such as speech rate, co-articulation with adjacent tones, segmental make-up, and predictability. This study shows that tonal realization is also partially determined by words' meanings. We first show, on the basis of a corpus of Taiwan Mandarin spontaneous conversations, using a generalized additive regression model, and focusing on the rise-fall tone pattern, that after controlling for effects of speaker and context, word type is a stronger predictor of tonal realization than all the previously established word-form related predictors combined. Importantly, the addition of information about meaning in context improves prediction accuracy even further. We then proceed to show, using computational modeling with context-specific word embeddings, that token-specific pitch contours predict word type with 50% accuracy on held-out data, and that context-sensitive, token-specific embeddings can predict the shape of pitch contours with 40% accuracy. These accuracies, which are an order of magnitude above chance level, suggest that the relation between words' pitch contours and their meanings are sufficiently strong to be potentially functional for language users. The theoretical implications of these empirical findings are discussed.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that tonal realizations of Mandarin two-character words (focusing on rise-fall patterns) in spontaneous Taiwan Mandarin speech are shaped not only by underlying tones and articulatory factors (speech rate, co-articulation, segmental makeup, predictability) but also by word-specific meanings. Using a generalized additive regression model on corpus data, it reports that word type is a stronger predictor than all word-form predictors combined after controlling for speaker and context; adding contextual meaning information further improves accuracy. Computational modeling with context-specific embeddings then shows token-specific pitch contours predict word type at 50% accuracy and embeddings predict pitch contour shape at 40% accuracy on held-out data—both well above chance—suggesting the pitch-meaning relation may be functionally relevant.
Significance. If the GAM controls adequately isolate word-type effects without residual confounding, the result would extend phonetic research on tone by demonstrating lexically specific, meaning-driven variation beyond established form-based predictors, with potential implications for models of speech production and perception. The held-out predictive modeling provides a quantitative check on effect strength and is a methodological strength. However, the central claim's defensibility depends on unverified aspects of model specification.
major comments (2)
- [generalized additive regression model (Abstract and modeling description)] The generalized additive regression model is presented as successfully isolating word-type effects after controlling for speaker, context, and word-form predictors, but the manuscript provides no concurvity diagnostics, variance inflation factors, or explicit checks for correlations between word type and unmodeled variables (e.g., prosodic boundary strength, syntactic role, or discourse status). This is load-bearing for the claim that word type outperforms the combined word-form predictors, as spontaneous-speech data make such correlations likely.
- [computational modeling with context-specific word embeddings (Abstract and results)] The reported 50% and 40% held-out accuracies for word-type prediction from pitch contours and embedding-to-pitch mapping lack details on exact controls, error estimation procedures, potential post-hoc model choices, or validation of the embedding-to-pitch mapping. These omissions directly affect assessment of whether the accuracies reflect genuine word-specific effects rather than artifacts of the modeling pipeline.
minor comments (1)
- [Abstract] The abstract and modeling sections would benefit from explicit statements of the number of observations, exact basis functions/smoothing parameters used in the GAM, and the precise definition of 'word type' versus 'word-form predictors' to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight important aspects of methodological transparency. We address each major comment below and will revise the manuscript to incorporate additional details and diagnostics as outlined.
read point-by-point responses
-
Referee: The generalized additive regression model is presented as successfully isolating word-type effects after controlling for speaker, context, and word-form predictors, but the manuscript provides no concurvity diagnostics, variance inflation factors, or explicit checks for correlations between word type and unmodeled variables (e.g., prosodic boundary strength, syntactic role, or discourse status). This is load-bearing for the claim that word type outperforms the combined word-form predictors, as spontaneous-speech data make such correlations likely.
Authors: We agree that explicit reporting of concurvity diagnostics and variance inflation factors would strengthen the presentation. The current manuscript describes the GAM specification and the set of word-form controls but does not include these post-fit checks. In revision we will add concurvity scores for the smooth terms, VIF values for the parametric predictors, and a supplementary analysis examining correlations between word type and available corpus annotations for prosodic boundary strength and syntactic position. These additions will allow readers to verify that the reported word-type effects are not driven by residual confounding. revision: yes
-
Referee: The reported 50% and 40% held-out accuracies for word-type prediction from pitch contours and embedding-to-pitch mapping lack details on exact controls, error estimation procedures, potential post-hoc model choices, or validation of the embedding-to-pitch mapping. These omissions directly affect assessment of whether the accuracies reflect genuine word-specific effects rather than artifacts of the modeling pipeline.
Authors: The manuscript reports held-out accuracies well above chance but does not provide the full pipeline details requested. We will expand the computational modeling section to specify the exact cross-validation scheme, the number of random seeds used for error estimation, the absence of post-hoc hyperparameter tuning, and the precise procedure used to map embeddings to pitch-contour parameters. These clarifications will be added without altering the reported accuracy figures. revision: yes
Circularity Check
No significant circularity; empirical corpus study with held-out prediction
full rationale
The paper reports GAM fits on spontaneous speech data controlling for speaker/context and word-form predictors, followed by held-out accuracies (50% word-type prediction from pitch contours; 40% pitch prediction from embeddings). These are standard out-of-sample evaluations with no self-definitional equations, fitted parameters renamed as predictions, or load-bearing self-citations. The central claims rest on independent data splits and external modeling rather than reduction to the same fitted quantities by construction. This is the expected non-finding for a predictive modeling study on held-out data.
Axiom & Free-Parameter Ledger
free parameters (2)
- GAM smoothing parameters and basis functions
- Embedding model hyperparameters and training objective
axioms (2)
- domain assumption The Taiwan Mandarin conversation corpus is representative and annotations of tones and context are accurate.
- domain assumption Context-sensitive embeddings encode semantic information relevant to tonal choice.
Reference graph
Works this paper leans on
-
[1]
Akaike, H. (1998). Information theory and an extension of the maximum likelihood principle. In Selected papers of Hirotugu Akaike , pages 199--213. Springer
work page 1998
-
[2]
H., Chuang, Y.-Y., Shafaei-Bajestan, E., and Blevins, J
Baayen, R. H., Chuang, Y.-Y., Shafaei-Bajestan, E., and Blevins, J. P. (2019). The discriminative lexicon: A unified computational model for the lexicon and lexical processing in comprehension and production grounded not in (de)composition but in linear discriminative learning. Complexity , 2019:4895891
work page 2019
-
[3]
H., Fasiolo, M., Wood, S., and Chuang, Y.-Y
Baayen, R. H., Fasiolo, M., Wood, S., and Chuang, Y.-Y. (2022). A note on the modeling of the effects of experimental time in psycholinguistic experiments. The Mental Lexicon , 17(2):178--212
work page 2022
-
[4]
Bell, A., Jurafsky, D., Fosler-Lussier, E., Girand, C., Gregory, M., and Gildea, D. (2003). Effects of disfluencies, predictability, and utterance position on word form variation in E nglish conversation. The Journal of the Acoustical Society of America , 113(2):1001--1024
work page 2003
-
[5]
Bi, Y., Chen, Y., and Schiller, N. O. (2015). The effect of word frequency and neighbourhood density on tone merge. In Proceedings of the 18th International Congress of Phonetic Sciences , Glasgow, Scotland
work page 2015
-
[6]
Boersma, P. and Weenink, D. (2019). Praat: doing phonetics by computer [computer program]. http://www.praat.org/
work page 2019
-
[7]
Bojanowski, P., Grave, E., Joulin, A., and Mikolov, T. (2017). Enriching word vectors with subword information. Transactions of the Association for Computational Linguistics , 5:135--146
work page 2017
-
[8]
Bruni, E., Tran, N.-K., and Baroni, M. (2014). Multimodal distributional semantics. Journal of Artificial Intelligence Research , 49:1--47
work page 2014
-
[9]
Chao, Y. R. (1968). A grammar of spoken Chinese . University of California Press
work page 1968
-
[10]
Chen, Y. (2010). Post-focus f0 compression—now you see it, now you don’t. Journal of Phonetics , 38(4):517--525
work page 2010
- [11]
-
[12]
Chuang, Y.-Y. and Baayen, R. H. (2021). Discriminative learning and the lexicon: NDL and LDL . In Oxford Research Encyclopedia of Linguistics . Oxford University Press
work page 2021
-
[13]
Chuang, Y.-Y., Huang, Y.-H., and Fon, J. (2007). The effect of incredulity and particle on the intonation of yes/no questions in T aiwan M andarin. In Proceedings of the 16th International Congress of Phonetic Sciences , pages 1261--1264, Saarbr\" u cken, Germany
work page 2007
-
[14]
Chuang, Y.-Y., Kang, M., Luo, X. F., and Baayen, R. H. (2023). Vector space morphology with linear discriminative learning. In Crepaldi, D., editor, Linguistic morphology in the mind and brain . Routledge
work page 2023
-
[15]
Chung, K. S. (2006). Contraction and backgrounding in Taiwan Mandarin . Concentric: Studies in Linguistics , 32(1):69--88
work page 2006
-
[16]
Cutler, A. and Clifton Jr., C. (1999). Comprehending spoken language: a blueprint of the listener. In Brown, C. and Hagoort, P., editors, The N eurocognition of L anguage , pages 123--166. Oxford U niversity P ress, Oxford
work page 1999
-
[17]
Drager, K. K. (2011). Sociophonetic variation and the lemma. Journal of Phonetics , 39(4):694--707
work page 2011
-
[18]
Duanmu, S. (2007). The phonology of standard Chinese . OUP Oxford
work page 2007
-
[19]
Elman, J. L. (2009). On the meaning of words and dinosaur bones: Lexical knowledge without a lexicon. Cognitive Science , 33(4):547--582
work page 2009
-
[20]
Ernestus, M. (2000). Voice assimilation and segment reduction in casual D utch. A corpus-based study of the phonology-phonetics interface . LOT, Utrecht
work page 2000
-
[21]
Firth, J. R. (1968). Selected papers of J R Firth, 1952-59 . Indiana University Press
work page 1968
-
[22]
Fon, J. (2004). A preliminary construction of T aiwan S outhern M in spontaneous speech corpus. Technical Report NSC-92-2411-H-003-050-, National Science Council, Taipei, Taiwan
work page 2004
-
[23]
Fon, J. and Chiang, W.-Y. (1999). What does Chao have to say about tones?-a case study of Taiwan Mandarin . Journal of Chinese Linguistics , 27(1):13--37
work page 1999
-
[24]
Fon, J. and Hsu, H.-J. (2007). Positional and phonotactic effects on the realization of dipping tones in Taiwan Mandarin . In Gussenhoven, C. and Riad, T., editors, Phonology and Phonetics, Tones and Tunes: Vol. 2. Experimental Studies in Word and Sentence Prosody , pages 239--269. Mouton de Gruyter, Berlin
work page 2007
-
[25]
Fu, J.-W. (1999). Chinese tonal variation and social network --- A case study in Tantzu Junior High School, Taichung, Taiwan . Master's thesis, Providence University
work page 1999
-
[26]
Gahl, S. (2008). Time and thyme are not homophones: The effect of lemma frequency on word durations in spontaneous speech. Language , 84(3):474--496
work page 2008
-
[27]
Gahl, S. and Baayen, R. H. (2024). Time and thyme again: Connecting E nglish spoken word duration to models of the mental lexicon. Language , 100(4):623--670
work page 2024
-
[28]
Gahl, S., Yao, Y., and Johnson, K. (2012). Why reduce? P honological neighborhood density and phonetic reduction in spontaneous speech. Journal of Memory and Language , 66(4):789--806
work page 2012
-
[29]
G rding, E. (1987). Speech act and tonal pattern in Standard Chinese : constancy and variation. Phonetica , 44(1):13--29
work page 1987
-
[30]
Goldman, J.-P. (2011). Easyalign: An automatic phonetic alignment tool under praat. In Interspeech , volume 12, pages 3233--3236
work page 2011
-
[31]
G \"u nther, F., Rinaldi, L., and Marelli, M. (2019). Vector-space models of semantic representation from a cognitive perspective: A discussion of common misconceptions. Perspectives on Psychological Science , 14(6):1006--1033
work page 2019
-
[32]
Harris, Z. S. (1954). Distributional structure. WORD , 10(2-3):146--162
work page 1954
-
[33]
Heitmeier, M., Chuang, Y.-Y., and Baayen, R. H. (2021). Modeling morphology with linear discriminative learning: Considerations and design choices. Frontiers in Psychology , 12:720713
work page 2021
-
[34]
Heitmeier, M., Chuang, Y.-Y., and Baayen, R. H. (2023). How trial-to-trial learning shapes mappings in the mental lexicon: Modelling lexical decision with linear discriminative learning. Cognitive Psychology , 146:101598
work page 2023
-
[35]
Heitmeier, M., Chuang, Y.-Y., and Baayen, R. H. (2025). The Discriminative Lexicon: Theory and implementation in the julia package JudiLing . In preparation for Cambridge University Press
work page 2025
-
[36]
Ho, A. T. (1976). The acoustic variation of M andarin tones. Phonetica , 33(5):353--367
work page 1976
-
[37]
Howie, J. M. (1974). On the domain of tone in Mandarin . Phonetica , 30(3):129--148
work page 1974
-
[38]
Hsieh, P.-j. (2013). Prosodic markings of semantic predictability in Taiwan Mandarin . In INTERSPEECH , pages 553--557
work page 2013
-
[39]
Hsieh, S.-K. and Tseng, Y.-H. (2020). Tutorial on sense-aware computing in chinese (version 0.1.6). In Paper presented in 32nd conference on Computational Linguistics and Speech Processing (ROCLING 2020)
work page 2020
-
[40]
Huang, C.-R., Hsieh, S.-K., Hong, J.-F., Chen, Y.-Z., Su, I.-L., Chen, Y.-X., and Huang, S.-W. (2010). Constructing Chinese Wordnet: Design Principles and Implementation. (in Chinese) . Zhong-Guo-Yu-Wen , 24:2:169--186
work page 2010
-
[41]
Huang, E., Socher, R., Manning, C., and Ng, A. (2012). Improving word representations via global context and multiple word prototypes. In Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages 873--882, Jeju Island, Korea. Association for Computational Linguistics
work page 2012
-
[42]
Huang, J., Tang, D., Zhong, W., Lu, S., Shou, L., Gong, M., Jiang, D., and Duan, N. (2021). W hitening BERT : An easy unsupervised sentence embedding approach. In Moens, M.-F., Huang, X., Specia, L., and Yih, S. W.-t., editors, Findings of the Association for Computational Linguistics: EMNLP 2021 , pages 238--244, Punta Cana, Dominican Republic. Associati...
work page 2021
-
[43]
Huang, P.-H. and Chiu, C. (2023). Production and perception of coarticulated tones: The cases of Taiwan Mandarin and Taiwan Southern Min . Available at SSRN 4637487
work page 2023
-
[44]
Huang, Y.-H. (2008). Dialectal variations on the realization of high tonal targets in Taiwan Mandarin . Master's thesis, National Taiwan University
work page 2008
-
[45]
Iacobacci, I., Pilehvar, M. T., and Navigli, R. (2015). S ens E mbed: Learning sense embeddings for word and relational similarity. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) , pages 95--105, Beijing, China. Ass...
work page 2015
-
[46]
Johnson, K. (2004). Massive reduction in conversational A merican E nglish. In Spontaneous speech: data and analysis. Proceedings of the 1st session of the 10th international symposium , pages 29--54, Tokyo, J apan. The N ational I nternational I nstitute for J apanese L anguage
work page 2004
-
[47]
Kendall, D. G. (1977). The diffusion of shape. Advances in Applied Probability , 9(3):428--430
work page 1977
-
[48]
Kilgarriff, A. (2007). Word senses. In Agirre, E. and Edmonds, P., editors, Word Sense Disambiguation: Algorithms and Applications , pages 29--46. Springer
work page 2007
-
[49]
Kuhn, M. (2013). Applied predictive modeling . Springer
work page 2013
-
[50]
Ladd, R. and Silverman, K. E. (1984). Vowel intrinsic pitch in connected speech. Phonetica , 41(1):31--40
work page 1984
-
[51]
Landauer, T. and Dumais, S. (1997). A solution to P lato's problem: T he latent semantic analysis theory of acquisition, induction and representation of knowledge. Psychological R eview , 104(2):211--240
work page 1997
-
[52]
Lee, O. J. (2005). The prosody of questions in Beijing Mandarin . The Ohio State University
work page 2005
-
[53]
Levelt, W. J., Roelofs, A., and Meyer, A. S. (1999). A theory of lexical access in speech production. Behavioral and Brain Sciences , 22(1):1--38
work page 1999
-
[54]
Li, Q. and Chen, Y. (2016). An acoustic study of contextual tonal variation in Tianjin Mandarin . Journal of Phonetics , 54:123--150
work page 2016
- [55]
-
[56]
Lohmann, A. (2018). Cut (n) and cut (v) are not homophones: Lemma frequency affects the duration of noun--verb conversion pairs. Journal of Linguistics , 54(4):753--777
work page 2018
-
[57]
Ma, W.-Y. and Chen, K.-J. (2003). Introduction to CKIP C hinese word segmentation system for the first international C hinese word segmentation bakeoff. In Proceedings of the Second SIGHAN Workshop on C hinese Language Processing , pages 168--171, Sapporo, Japan. Association for Computational Linguistics
work page 2003
-
[58]
Maaten, L. v. d. and Hinton, G. (2008). Visualizing data using t-SNE . Journal of Machine Learning Research , 9(11):2579--2605
work page 2008
-
[59]
Marsolek, C. J. (2008). What antipriming reveals about priming. Trends in C ognitive S cience , 12(5):176--181
work page 2008
-
[60]
Martinet, A. (1965). La Linguistique Synchronique: \'Etudes et Recherches . Presses Universitaires de France, Paris
work page 1965
-
[61]
Moore, C. B. and Jongman, A. (1997). Speaker normalization in the perception of Mandarin Chinese tones. The Journal of the Acoustical Society of America , 102(3):1864--1877
work page 1997
-
[62]
Neelakantan, A., Shankar, J., Passos, A., and McCallum, A. (2014). Efficient non-parametric estimation of multiple embeddings per word in vector space. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing ( EMNLP ) , pages 1059--1069, Doha, Qatar. Association for Computational Linguistics
work page 2014
-
[63]
Nieder, J., Chuang, Y.-Y., van de Vijver, R., and Baayen, R. H. (2023). A discriminative lexicon approach to word comprehension, production, and processing: Maltese plurals. Language , 99(2)
work page 2023
-
[64]
Ouyang, I. C. and Kaiser, E. (2015). Prosody and information structure in a tone language: an investigation of Mandarin Chinese . Language, Cognition and Neuroscience , 30(1-2):57--72
work page 2015
-
[65]
Perek, F. and Hilpert, M. (2017). A distributional semantic approach to the periodization of change in the productivity of constructions. International Journal of Corpus Linguistics , 22(4):490--520
work page 2017
-
[66]
Pilehvar, M. T. and Camacho-Collados, J. (2020). Embeddings in natural language processing: Theory and advances in vector representations of meaning . Morgan & Claypool Publishers
work page 2020
-
[67]
Plag, I., Homann, J., and Kunter, G. (2017). Homophony and morphology: The acoustics of word-final S in E nglish. Journal of Linguistics , 53(1):181--216
work page 2017
-
[68]
R: A Language and Environment for Statistical Computing
R Core Team (2022). R: A Language and Environment for Statistical Computing . R Foundation for Statistical Computing, Vienna, Austria
work page 2022
-
[69]
Reisinger, J. and Mooney, R. J. (2010). Multi-prototype vector-space models of word meaning. In Human Language Technologies: The 2010 Annual Conference of the North A merican Chapter of the Association for Computational Linguistics , pages 109--117, Los Angeles, California. Association for Computational Linguistics
work page 2010
-
[70]
Saito, M., Tomaschek, F., and Baayen, R. H. (2023). Articulatory effects of frequency modulated by inflectional meanings. In Schlechtweg, M., editor, Interfaces of Phonetics . De Gruyter
work page 2023
-
[71]
Salton, G., Wong, A., and Yang, C. S. (1975). A vector space model for automatic indexing. Commun. ACM , 18(11):613–620
work page 1975
-
[72]
Sampson, G. (2015). A chinese phonological enigma. Journal of Chinese Linguistics , 43(2):679--691
work page 2015
-
[73]
Sampson, G. (2019). An unaddressed phonological contradiction. International Journal of Chinese Linguistics , 6(2):221--237
work page 2019
-
[74]
Sch\" u tze, H. (1992). Word space. In Hanson, S., Cowan, J., and Giles, C., editors, Advances in Neural Information Processing Systems , volume 5. Morgan-Kaufmann
work page 1992
-
[75]
Shen, X. S. (1989). Interplay of the four citation tones and intonation in Mandarin Chinese . Journal of Chinese Linguistics , 17(1):61--74
work page 1989
-
[76]
Shen, X. S. (1990a). The prosody of Mandarin Chinese , volume 118. University of California Press
-
[77]
Shen, X. S. (1990b). Tonal coarticulation in M andarin. Journal of Phonetics , 18(2):281--295
-
[78]
Shen, X. S. and Lin, M. (1991). A perceptual study of M andarin tones 2 and 3. Language and Speech , 34(2):145--156
work page 1991
-
[79]
Shi, B. and Zhang, J. (1987). Vowel intrinsic pitch in S tandard C hinese. In Proceedings of the 11th International Congress of Phonetic Sciences , pages 142--145
work page 1987
-
[80]
Shih, C. (1988). Tone and intonation in M andarin. Working Papers, Cornell Phonetics Laboratory , 3:83--109
work page 1988
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.