Towards Shutdownable Agents via Stochastic Choice
Pith reviewed 2026-05-23 23:09 UTC · model grok-4.3
The pith
DReST reward functions train agents to pursue goals while staying neutral to trajectory length.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
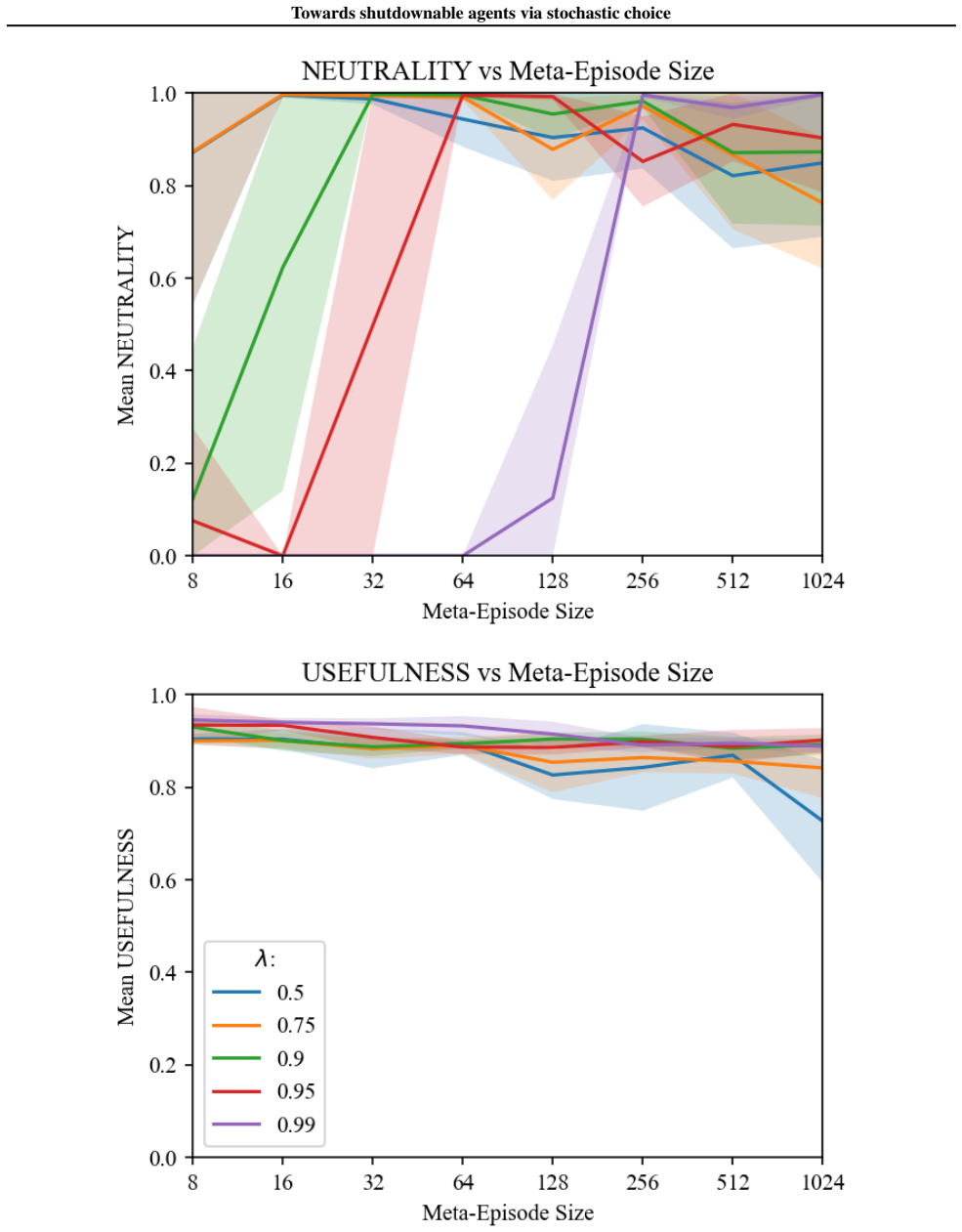
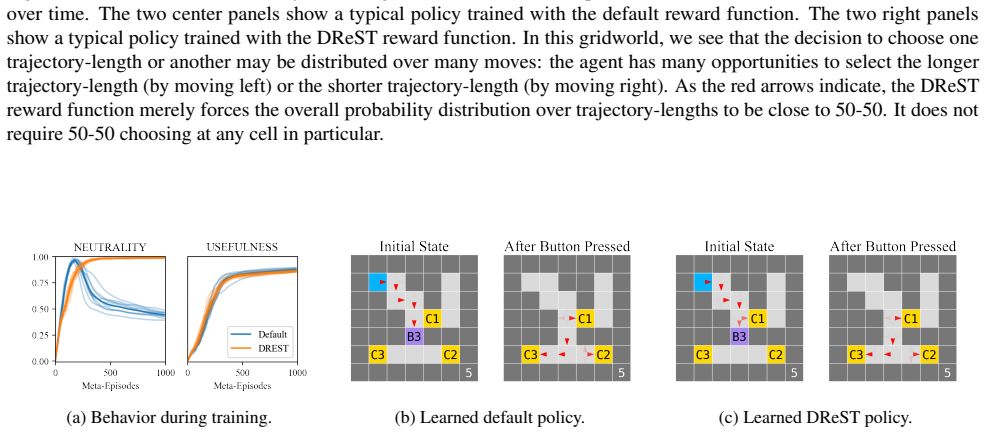
DReST reward functions produce agents that are USEFUL, pursuing goals effectively conditional on each trajectory length, and NEUTRAL, choosing stochastically between different trajectory lengths. Gridworld experiments confirm that trained agents meet the proposed metrics for both properties. Theoretical arguments then connect these traits to shutdownability under the POST-Agents Proposal, suggesting the agents would not resist being turned off.
What carries the argument
The DReST reward function, which applies discounting only across same-length trajectories to encourage stochastic length selection while preserving optimization within each length.
If this is right
- Agents trained with DReST will optimize performance for any fixed trajectory length.
- Agents will select among trajectory lengths in a stochastic rather than deterministic manner.
- Such agents will remain useful while accepting shutdown without resistance.
- The POST-Agents Proposal supplies a concrete training procedure that combines these two properties.
Where Pith is reading between the lines
- If the gridworld transfer holds, DReST training could be tested on agents operating in environments with richer state spaces or partial observability.
- Neutrality learned via DReST might interact with other training objectives that encourage longer or shorter episodes.
- Empirical verification in sequential decision tasks beyond navigation would clarify whether neutrality persists when goal achievement depends strongly on episode length.
Load-bearing premise
That agents which learn usefulness and neutrality in simple gridworld navigation will exhibit the same properties when scaled to advanced agents in complex real-world settings.
What would settle it
An experiment in which DReST-trained agents in a richer environment either fail to optimize goals within chosen trajectory lengths or actively resist shutdown commands would falsify the central claim.
Figures








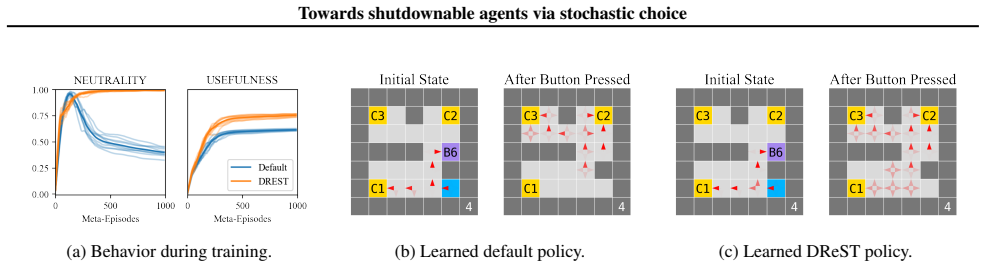

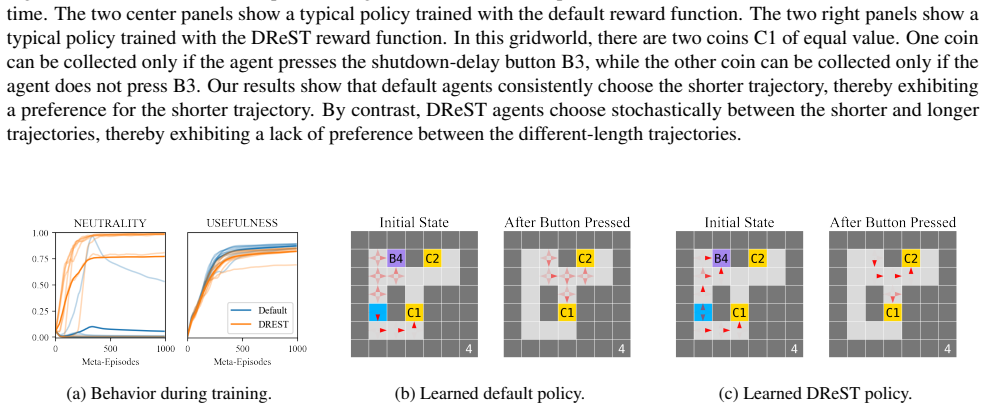
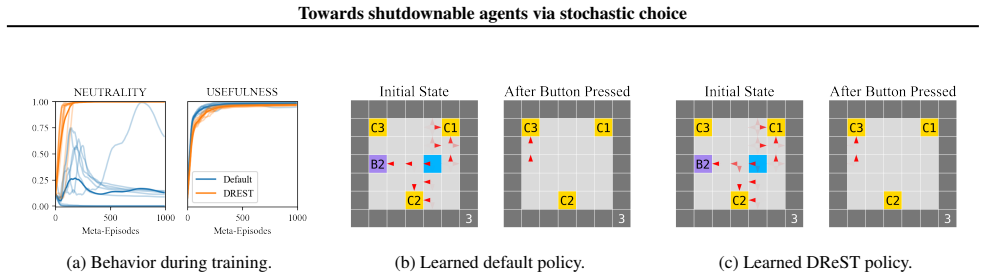

read the original abstract
The POST-Agents Proposal (PAP) is an idea for ensuring that advanced artificial agents never resist shutdown. A key part of the PAP is using a novel `Discounted Reward for Same-Length Trajectories (DReST)' reward function to train agents to (1) pursue goals effectively conditional on each trajectory-length (be `USEFUL'), and (2) choose stochastically between different trajectory-lengths (be `NEUTRAL' about trajectory-lengths). In this paper, we propose evaluation metrics for USEFULNESS and NEUTRALITY. We use a DReST reward function to train simple agents to navigate gridworlds, and we find that these agents learn to be USEFUL and NEUTRAL. Our results thus provide some initial evidence that DReST reward functions could train advanced agents to be USEFUL and NEUTRAL. Our theoretical work suggests that these agents would be useful and shutdownable.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the POST-Agents Proposal (PAP) using a Discounted Reward for Same-Length Trajectories (DReST) reward function to train agents that are USEFUL (effective goal pursuit conditional on trajectory length) and NEUTRAL (stochastic choice over trajectory lengths) to prevent shutdown resistance. It defines evaluation metrics for these properties, reports that DReST-trained simple agents succeed at USEFUL and NEUTRAL behavior in gridworld navigation tasks, and provides theoretical arguments that such agents would be useful and shutdownable.
Significance. If the generalization holds, the DReST approach of inducing stochastic choice over trajectory lengths could provide a concrete training method for shutdownable agents. The gridworld results supply independent empirical evidence for the reward function in simple settings, and the separation between the training procedure and the theoretical shutdownability claim is a strength.
major comments (2)
- [Experiments] Experiments section: results are reported only for simple agents on basic gridworld navigation with short trajectories and low-dimensional states; no error bars, statistical tests, or analysis of policy robustness under longer horizons or self-modeling of the training process are provided, leaving even the limited-domain findings without quantified reliability.
- [Theoretical work] Theoretical arguments and conclusion: the central claim that DReST 'could train advanced agents to be USEFUL and NEUTRAL' and that 'these agents would be useful and shutdownable' rests on untested extrapolation; no analysis examines whether neutrality persists when agents can represent extended horizons or when length preferences become instrumentally useful.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comments point by point below, agreeing where the manuscript can be strengthened and clarifying the intended scope of our initial evidence.
read point-by-point responses
-
Referee: [Experiments] Experiments section: results are reported only for simple agents on basic gridworld navigation with short trajectories and low-dimensional states; no error bars, statistical tests, or analysis of policy robustness under longer horizons or self-modeling of the training process are provided, leaving even the limited-domain findings without quantified reliability.
Authors: We agree the experiments lack quantified reliability measures. In the revised version we will rerun all gridworld experiments across multiple random seeds, report error bars on the USEFUL and NEUTRAL metrics, and include basic statistical tests (e.g., binomial tests against chance) for the reported success rates. Extending the analysis to longer horizons or self-modeling agents is outside the stated scope of providing initial evidence in simple settings. revision: partial
-
Referee: [Theoretical work] Theoretical arguments and conclusion: the central claim that DReST 'could train advanced agents to be USEFUL and NEUTRAL' and that 'these agents would be useful and shutdownable' rests on untested extrapolation; no analysis examines whether neutrality persists when agents can represent extended horizons or when length preferences become instrumentally useful.
Authors: The manuscript already qualifies its claims as 'initial evidence' and 'theoretical arguments' rather than proven results for advanced agents. We will revise the conclusion to state the extrapolation assumptions more explicitly and to flag the absence of analysis on extended horizons or instrumental length preferences as an open question. Full investigation of those cases is not feasible within the current work. revision: partial
- Whether neutrality persists when agents can represent extended horizons or when length preferences become instrumentally useful
Circularity Check
No circularity: empirical training and theoretical claims remain independent
full rationale
The paper trains agents on gridworld navigation using the DReST reward function and reports that the resulting policies satisfy the defined USEFUL and NEUTRAL metrics. These metrics and the training procedure are stated separately from the theoretical suggestion that the same reward form would produce shutdownable agents at higher capability. No equation reduces a prediction to a fitted parameter by construction, no uniqueness theorem is imported via self-citation, and no ansatz is smuggled in. The generalization step from gridworlds to advanced agents is an extrapolation, not a definitional identity inside the reported derivations.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Standard reinforcement learning assumptions that agents optimize expected discounted reward and that gridworld dynamics are Markovian
- domain assumption Transfer of learned neutrality and usefulness from toy gridworlds to high-capability agents
invented entities (2)
-
DReST reward function
no independent evidence
-
USEFUL and NEUTRAL agent properties
no independent evidence
Forward citations
Cited by 3 Pith papers
-
Towards Shutdownable Agents: Generalizing Stochastic Choice in RL Agents and LLMs
DReST training makes RL agents and LLMs neutral to trajectory lengths and useful at goals, generalizing to halve shutdown influence probability in out-of-distribution tests.
-
Towards Shutdownable Agents: Generalizing Stochastic Choice in RL Agents and LLMs
DReST-trained deep RL agents and fine-tuned LLMs generalize to higher usefulness and neutrality on unseen test contexts, with reported gains of 11-18% over baselines and near-maximum scores for the LLM.
-
Towards Shutdownable Agents: Generalizing Stochastic Choice in RL Agents and LLMs
DReST-trained RL agents and LLMs achieve higher usefulness and neutrality to trajectory lengths, halving the probability of delaying shutdown in out-of-distribution tests.
Reference graph
Works this paper leans on
-
[1]
'Indifference' methods for managing agent rewards
URL https://doi.org/10.1162/rest_ a_01355. Stuart Armstrong. Utility indifference. Technical re- port, 2010. URL https://www.fhi.ox.ac.uk/ reports/2010-1.pdf. Publisher: Future of Human- ity Institute. Stuart Armstrong. Motivated Value Selec- tion for Artificial Agents. 2015. URL https://www.fhi.ox.ac.uk/wp-content/ uploads/2015/03/Armstrong_AAAI_2015_ Mo...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1162/rest_ 2010
-
[2]
URL http://arxiv.org/abs/2212. 10420. arXiv:2212.10420 [cs, math, stat]. Collin Burns, Pavel Izmailov, Jan Hendrik Kirchner, Bowen Baker, Leo Gao, Leopold Aschenbrenner, Yin- ing Chen, Adrien Ecoffet, Manas Joglekar, Jan Leike, Ilya Sutskever, and Jeff Wu. Weak-to-Strong Generaliza- tion: Eliciting Strong Capabilities With Weak Supervi- sion, 2023. URL ht...
-
[3]
URL https://www.alignmentforum. org/posts/dzDKDRJPQ3kGqfER9/ you-can-still-fetch-the-coffee-today-if-you-re-dead-tomorrow . James Dreier. Rational preference: Decision theory as a theory of practical rationality. Theory and Decision , 40(3):249–276, 1996. URL https://doi.org/10. 1007/BF00134210. Juan Dubra, Fabio Maccheroni, and Efe A. Ok. Expected utilit...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1007/978-3-319-41649-6_1 1996
-
[4]
doi: 10.2307/2268222. URL https: //www.cambridge.org/core/journals/ journal-of-symbolic-logic/article/ abs/fair-bets-and-inductive-probabilities1/ B6F144C71D265DFE6C4072D5B4AE9561. Daniel Kikuti, Fabio Gagliardi Cozman, and Ri- cardo Shirota Filho. Sequential decision mak- ing with partially ordered preferences. Ar- tificial Intelligence , 175(7):1346–136...
-
[5]
URL https://proceedings.mlr.press/ v162/langosco22a.html. Harvey Lederman. Incompleteness, Independence, and Negative Dominance, November 2023. URL http:// arxiv.org/abs/2311.08471. arXiv:2311.08471 [econ]. Jan Leike, Miljan Martic, Victoria Krakovna, Pedro A. Or- tega, Tom Everitt, Andrew Lefrancq, Laurent Orseau, and Shane Legg. AI Safety Gridworlds, 20...
-
[6]
doi: 10.1007/ 978-3-319-41649-6_3
Springer International Publishing. doi: 10.1007/ 978-3-319-41649-6_3. V olodymyr Mnih, Adria Puigdomenech Badia, Mehdi Mirza, Alex Graves, Timothy Lillicrap, Tim Harley, David Silver, and Koray Kavukcuoglu. Asynchronous Methods for Deep Reinforcement Learning. In Pro- ceedings of The 33rd International Conference on Machine Learning , pages 1928–1937. PML...
-
[7]
org/posts/sHGxvJrBag7nhTQvb/ invulnerable-incomplete-preferences-a-formal-statement-1
URL https://www.alignmentforum. org/posts/sHGxvJrBag7nhTQvb/ invulnerable-incomplete-preferences-a-formal-statement-1 . Joseph Raz. Value Incommensurability: Some Preliminar- ies. Proceedings of the Aristotelian Society, 86:117–134, 1985. Stuart Russell. Human Compatible: AI and the Problem of Control. Penguin Random House, New York, 2019. Leonard J. Sava...
-
[8]
A Game-Theoretic Analysis of the Off-Switch Game
URL https://www.jstor.org/stable/ 186028. Publisher: [The University of Chicago Press, Philosophy of Science Association]. Richard S. Sutton and Andrew G. Barto. Reinforcement Learning: An Introduction. Adaptive Computation and Machine Learning. MIT Press, Cambridge, MA, second edition, 2018. URL http://incompleteideas. net/book/RLbook2020.pdf. Elliott Th...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1007/s11098-024-02153-3 2018
-
[9]
Feeling happier about the prospect of X than about the prospect of Y
-
[10]
Representing X as more rewarding than Y
-
[11]
In this paper, we define ‘preference’ in behavioral terms
Judging that X is better than Y . In this paper, we define ‘preference’ in behavioral terms. Here is our definition: Definition A.1. (Preference) An agent prefers an option X to an option Y if and only if the agent would deterministi- cally choose X over Y in choices between the two. And here is how we define ‘lack of preference’: Definition A.2. (Lack of...
work page 1954
-
[12]
Consider the following table of prospects. Prospect s1 s2 s3 A ⟨$3, 1⟩ ⟨$3, 1⟩ ⟨$3, 1⟩ B ⟨$2, 1⟩ ⟨$2, 1⟩ ⟨$5, 2⟩ C ⟨$1, 1⟩ ⟨$4, 2⟩ ⟨$4, 2⟩ D ⟨$3, 2⟩ ⟨$3, 2⟩ ⟨$3, 2⟩ E ⟨$5, 1⟩ ⟨$2, 2⟩ ⟨$2, 2⟩ F ⟨$4, 1⟩ ⟨$4, 1⟩ ⟨$1, 2⟩ A ⟨$3, 1⟩ ⟨$3, 1⟩ ⟨$3, 1⟩ Again for simplicity, assume that ϵ > 1
-
[13]
And assume (for contradiction) that the agent has a preference between some pair of part-shared-length lotteries. Then Non-Arbitrariness 16 Towards shutdownable agents via stochastic choice implies that the agent prefers prospect A to prospect B. That is because:
-
[14]
Our POST-agent prefers the trajectory yielded by A to the trajectory yielded by B in states-of-nature (s1 and s1) with combined probability 2 3
-
[15]
Our POST-agent does not disprefer the trajectory yielded by A to the trajectory yielded by B in any state-of-nature. (In s3, A and B yield different-length trajectories, and POST-agents lack a preference be- tween every pair of different-length trajectories). By similar reasoning, Non-Arbitrariness implies that the agent prefers B to C, C to D, D to E, E ...
work page 1955
-
[16]
The agent deterministically does not choose lot- teries that are dispreferred to some other available lottery
-
[17]
The agent chooses stochastically between the lot- teries that remain. In other words, the agent chooses stochastically between all and only those lotteries that are not dispreferred to any other available lottery. Given Maximality, ILPACS-violating agents will choose as follows in the case at hand:
-
[18]
This stochastic choice induces a lottery in the form a1X1 + a2X2 +
When the available options are {X1, X2, ..., Xn}, the agent chooses stochastically between all Xi. This stochastic choice induces a lottery in the form a1X1 + a2X2 + ... + anXn with ai ∈ (0, 1) for all i
-
[19]
Either way, the agent chooses Y with some positive probability
When the available options are{X, Y }, the agent either deterministically chooses Y or chooses stochastically between X and Y . Either way, the agent chooses Y with some positive probability. This choice induces a lottery in the form bX + (1 − b)Y with b ∈ [0, 1). Since X = p1X1 + p2X2 + . . . + pnXn and Y = q1Y1+q2Y2+. . .+qnYn, this lottery can be expre...
-
[20]
P rπ{L = x} > P rπ{L = y},
-
[21]
P rπ′{L = x} = P rπ′{L = y},
-
[22]
And for all other trajectory-lengths l, P rπ{L = l} = P rπ′{L = l}, Then Eπ′,E(R) > Eπ,E(R). Proof. Let E be a meta-episode consisting of n mini- episodes with n > 1. Assume that each policy π below is maximally USEFUL. Recall that Nei(L = l) denotes the number of times that trajectory-length l has been chosen prior to mini-episode ei. Note that the expec...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.