0
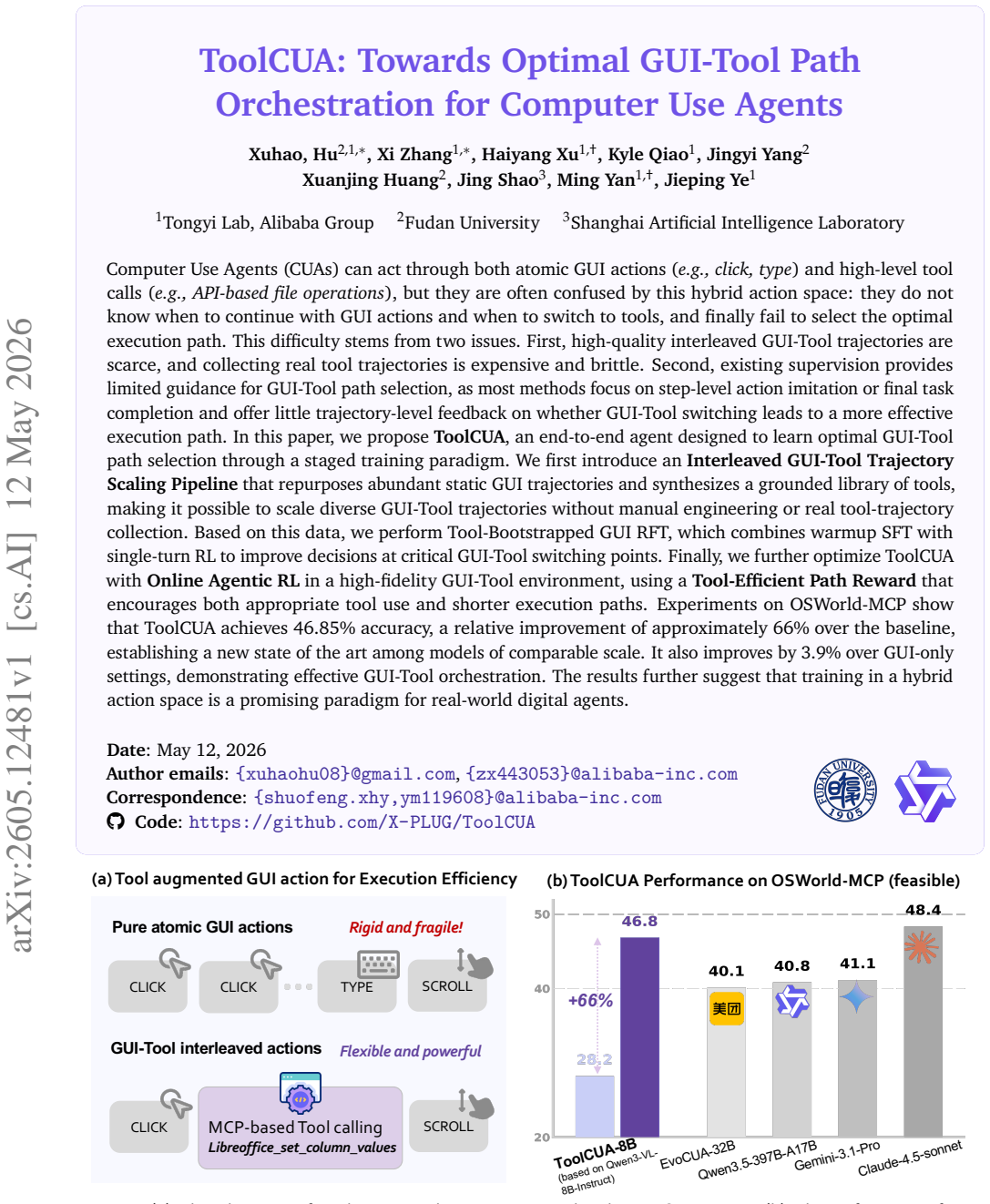
ToolCUA reaches 46.85% accuracy by learning GUI-tool orchestration
ToolCUA: Towards Optimal GUI-Tool Path Orchestration for Computer Use Agents
A scaling pipeline creates synthetic hybrid trajectories and staged RL with efficiency rewards teaches agents when to switch between actions
 full image
full image
abstract click to expand
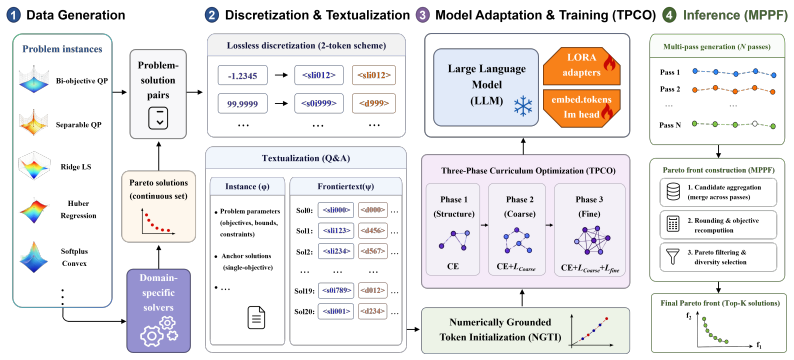
Computer Use Agents (CUAs) can act through both atomic GUI actions, such as click and type, and high-level tool calls, such as API-based file operations, but this hybrid action space often leaves them uncertain about when to continue with GUI actions or switch to tools, leading to suboptimal execution paths. This difficulty stems from the scarcity of high-quality interleaved GUI-Tool trajectories, the cost and brittleness of collecting real tool trajectories, and the lack of trajectory-level supervision for GUI-Tool path selection. In this paper, we propose ToolCUA, an end-to-end agent designed to learn optimal GUI-Tool path selection through a staged training paradigm. We first introduce an Interleaved GUI-Tool Trajectory Scaling Pipeline that repurposes abundant static GUI trajectories and synthesizes a grounded tool library, enabling diverse GUI-Tool trajectories without manual engineering or real tool-trajectory collection. We then perform Tool-Bootstrapped GUI RFT, combining warmup SFT with single-turn RL to improve decisions at critical GUI-Tool switching points. Finally, we optimize ToolCUA with Online Agentic RL in a high-fidelity GUI-Tool environment, guided by a Tool-Efficient Path Reward that encourages appropriate tool use and shorter execution paths. Experiments on OSWorld-MCP show that ToolCUA achieves 46.85% accuracy, a relative improvement of approximately 66% over the baseline, establishing a new state of the art among models of comparable scale. It also improves by 3.9% over GUI-only settings, demonstrating effective GUI-Tool orchestration. The results further suggest that training in a hybrid action space is a promising paradigm for real-world digital agents. Open-sourced here: https://x-plug.github.io/ToolCUA/