Motion Capture from Inertial and Vision Sensors
Pith reviewed 2026-05-23 22:28 UTC · model grok-4.3
The pith
A monocular camera plus a few IMUs can capture human motion accurately enough for daily use.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors claim that inertial signals and monocular video supply complementary information that together suffice for accurate multi-person motion capture, and they demonstrate this sufficiency by releasing the MINIONS dataset and training SparseNet on it.
What carries the argument
SparseNet, a fusion network that learns to combine sparse IMU measurements with RGB video features to output SMPL parameters and joint angles.
If this is right
- Motion capture becomes feasible with hardware already present in consumer phones and watches.
- The released dataset supplies training data for other multi-modal pose estimators.
- Sparse fusion reduces the sensor count needed for acceptable accuracy in interactive applications.
Where Pith is reading between the lines
- The same sensor mix could be tested on longer, continuous recordings to check drift accumulation.
- Results may transfer to single-person tracking on mobile devices if the network is quantized.
- Interactive actions in the dataset suggest possible extensions to two-person collaboration or sports analysis.
Load-bearing premise
The combination of one camera and very few IMUs is enough to produce accurate motion estimates outside controlled studio conditions.
What would settle it
Record the same actions with the proposed sensor mix and with a full optical marker system; if the average joint-position error stays above 5 cm or the rotation error above 10 degrees across diverse daily actions, the claim fails.
Figures
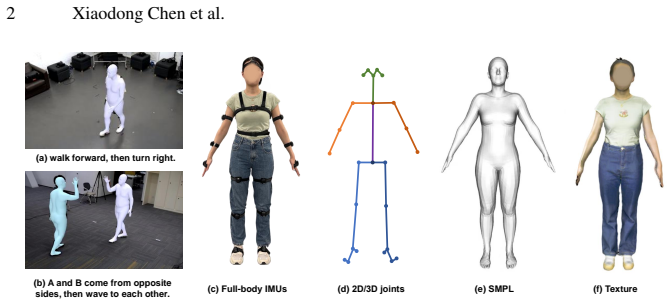







read the original abstract
Human motion capture is the foundation for many computer vision and graphics tasks. While industrial motion capture systems with complex camera arrays or expensive wearable sensors have been widely adopted in movie and game production, consumer-affordable and easy-to-use solutions for personal applications are still far from mature. To utilize a mixture of a monocular camera and very few inertial measurement units (IMUs) for accurate multi-modal human motion capture in daily life, we contribute MINIONS in this paper, a large-scale Motion capture dataset collected from INertial and visION Sensors. MINIONS has several featured properties: 1) large scale of over five million frames and 400 minutes duration; 2) multi-modality data of IMUs signals and RGB videos labeled with joint positions, joint rotations, SMPL parameters, etc.; 3) a diverse set of 146 fine-grained single and interactive actions with textual descriptions. With the proposed MINIONS dataset, we propose a SparseNet framework to capture human motion from IMUs and videos by discovering their supplementary features and exploring the possibilities of consumer-affordable motion capture using a monocular camera and very few IMUs. The experiment results emphasize the unique advantages of inertial and vision sensors, showcasing the promise of consumer-affordable multi-modal motion capture and providing a valuable resource for further research and development.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to contribute the MINIONS dataset—a large-scale collection of over five million frames (400 minutes) of synchronized IMU signals and monocular RGB videos, annotated with joint positions, joint rotations, and SMPL parameters across 146 fine-grained single and interactive actions—and the SparseNet framework that fuses inertial and visual data to enable accurate human motion capture using only a monocular camera and very few IMUs for consumer-affordable daily-life applications.
Significance. If validated, the MINIONS dataset would provide a substantial public resource for multi-modal motion capture research due to its scale, action diversity, and textual descriptions, while SparseNet could demonstrate practical sensor fusion for sparse setups, addressing the gap between industrial systems and accessible consumer solutions in graphics, vision, and AR/VR applications.
major comments (1)
- [Abstract] Abstract: The central claims—that MINIONS enables consumer-affordable capture and that SparseNet discovers supplementary IMU-video features for accurate reconstruction—are presented without any description of the network architecture, sensor placement protocol, data collection procedure, loss functions, evaluation metrics, baselines, or quantitative results, making it impossible to assess whether the data or framework support the stated claims.
Simulated Author's Rebuttal
We thank the referee for their review and feedback. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claims—that MINIONS enables consumer-affordable capture and that SparseNet discovers supplementary IMU-video features for accurate reconstruction—are presented without any description of the network architecture, sensor placement protocol, data collection procedure, loss functions, evaluation metrics, baselines, or quantitative results, making it impossible to assess whether the data or framework support the stated claims.
Authors: We agree that the provided abstract is a high-level summary and does not contain the requested technical details. Abstracts are designed to be concise overviews; the full manuscript contains dedicated sections describing the SparseNet architecture, sensor placement, data collection protocol for the MINIONS dataset, loss functions, evaluation metrics, baselines, and quantitative results that support the claims. The referee summary already references these elements from the paper, indicating the full text was available for review. revision: no
Circularity Check
No significant circularity detected
full rationale
The provided document consists only of an abstract with no equations, derivations, parameter fittings, or technical claims about how results are obtained from inputs. The work introduces a new dataset (MINIONS) and framework (SparseNet) as an empirical contribution for multi-modal motion capture, without presenting any derivation chain that could reduce to self-definition, fitted inputs renamed as predictions, or self-citation load-bearing steps. No load-bearing assumptions are isolated or shown to be circular by the paper's own text.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
http://www.neuronmocap.com (2024) 1, 2, 4, 5, 6
Perception neuron. http://www.neuronmocap.com (2024) 1, 2, 4, 5, 6
work page 2024
- [2]
- [3]
-
[4]
https://www.ximea.com/en/products/usb- 31- gen- 1- with- sony-cmos-xic/mc023cg-sy (2024) 6
Ximea. https://www.ximea.com/en/products/usb- 31- gen- 1- with- sony-cmos-xic/mc023cg-sy (2024) 6
work page 2024
- [5]
- [6]
-
[7]
ACM TOG 24(3), 408–416 (2005) 4
Anguelov, D., Srinivasan, P., Koller, D., Thrun, S., Rodgers, J., Davis, J.: SCAPE: shape completion and animation of people. ACM TOG 24(3), 408–416 (2005) 4
work page 2005
- [8]
- [9]
- [10]
-
[11]
IEEE TPAMI43(1), 172–186 (2021) 8
Cao, Z., Hidalgo, G., Simon, T., Wei, S., Sheikh, Y .: Openpose: Realtime multi-person 2d pose estimation using part affinity fields. IEEE TPAMI43(1), 172–186 (2021) 8
work page 2021
- [12]
-
[13]
IEEE Access 8, 176241–176262 (2020) 3
Chatzitofis, A., Saroglou, L., Boutis, P., Drakoulis, P., Zioulis, N., Subramanyam, S., Kevel- ham, B., Charbonnier, C., Cesar, P., Zarpalas, D., et al.: Human4d: A human-centric mul- timodal dataset for motions and immersive media. IEEE Access 8, 176241–176262 (2020) 3
work page 2020
-
[14]
The Visual Computer 39(5), 1893–1906 (2023) 2, 4
Chen, D., Song, Y ., Liang, F., Ma, T., Zhu, X., Jia, T.: 3d human body reconstruction based on smpl model. The Visual Computer 39(5), 1893–1906 (2023) 2, 4
work page 1906
- [15]
-
[16]
Gilbert, A., Trumble, M., Malleson, C., Hilton, A., Collomosse, J.P.: Fusing visual and in- ertial sensors with semantics for 3d human pose estimation. IJCV 127(4), 381–397 (2019) 5
work page 2019
- [17]
-
[18]
IEEE TIP 29, 8476–8489 (2020) 5
Henschel, R., von Marcard, T., Rosenhahn, B.: Accurate long-term multiple people tracking using video and body-worn imus. IEEE TIP 29, 8476–8489 (2020) 5
work page 2020
- [19]
-
[20]
ACM TOG 37(6), 185 (2018) 3, 4, 7
Huang, Y ., Kaufmann, M., Aksan, E., Black, M.J., Hilliges, O., Pons-Moll, G.: Deep inertial poser: learning to reconstruct human pose from sparse inertial measurements in real time. ACM TOG 37(6), 185 (2018) 3, 4, 7
work page 2018
-
[21]
IEEE TPAMI 36(7), 1325–1339 (2014) 1, 2, 3, 5, 8
Ionescu, C., Papava, D., Olaru, V ., Sminchisescu, C.: Human3.6m: Large scale datasets and predictive methods for 3d human sensing in natural environments. IEEE TPAMI 36(7), 1325–1339 (2014) 1, 2, 3, 5, 8
work page 2014
-
[22]
Jiang, Y ., Ye, Y ., Gopinath, D., Won, J., Winkler, A.W., Liu, C.K.: Transformer inertial poser: Real-time human motion reconstruction from sparse imus with simultaneous terrain genera- tion. In: SIGGRAPH Asia. pp. 3:1–3:9. ACM (2022) 4 16 Xiaodong Chen et al
work page 2022
- [23]
- [24]
- [25]
-
[26]
Li, K., Wang, Y ., He, Y ., Li, Y ., Wang, Y ., Wang, L., Qiao, Y .: Uniformerv2: Spatiotemporal learning by arming image vits with video uniformer. ICCV (2023) 13, 14
work page 2023
- [27]
- [28]
-
[29]
IEEE TPAMI 42(10), 2684– 2701 (2020) 13
Liu, J., Shahroudy, A., Perez, M., Wang, G., Duan, L., Kot, A.C.: NTU RGB+D 120: A large-scale benchmark for 3d human activity understanding. IEEE TPAMI 42(10), 2684– 2701 (2020) 13
work page 2020
-
[30]
Liu, W., Bao, Q., Sun, Y ., Mei, T.: Recent advances of monocular 2d and 3d human pose estimation: a deep learning perspective. ACM Comput. Surv. 55(4), 1–41 (2022) 4
work page 2022
-
[31]
ACM TOG 34(6), 248:1–248:16 (2015) 2, 3, 4, 9
Loper, M., Mahmood, N., Romero, J., Pons-Moll, G., Black, M.J.: SMPL: a skinned multi- person linear model. ACM TOG 34(6), 248:1–248:16 (2015) 2, 3, 4, 9
work page 2015
-
[32]
IJCV 128(6), 1594–1611 (2020) 5
Malleson, C., Collomosse, J.P., Hilton, A.: Real-time multi-person motion capture from multi-view video and imus. IJCV 128(6), 1594–1611 (2020) 5
work page 2020
- [33]
-
[34]
IEEE TPAMI 38(8), 1533–1547 (2016) 5
von Marcard, T., Pons-Moll, G., Rosenhahn, B.: Human pose estimation from video and imus. IEEE TPAMI 38(8), 1533–1547 (2016) 5
work page 2016
-
[35]
von Marcard, T., Rosenhahn, B., Black, M.J., Pons-Moll, G.: Sparse inertial poser: Auto- matic 3d human pose estimation from sparse imus. CGF 36(2), 349–360 (2017) 4
work page 2017
- [36]
-
[37]
Mehta, D., Rhodin, H., Casas, D., Fua, P., Sotnychenko, O., Xu, W., Theobalt, C.: Monocular 3d human pose estimation in the wild using improved CNN supervision. In: IEEE 3DV . pp. 506–516 (2017) 1, 3, 5, 8
work page 2017
-
[38]
Mehta, D., Sotnychenko, O., Mueller, F., Xu, W., Sridhar, S., Pons-Moll, G., Theobalt, C.: Single-shot multi-person 3d pose estimation from monocular RGB. In: IEEE 3DV . pp. 120– 130 (2018) 1, 3
work page 2018
- [39]
- [40]
-
[41]
Riaz, Q., Tao, G., Krüger, B., Weber, A.: Motion reconstruction using very few accelerome- ters and ground contacts. Graph. Model. 79, 23–38 (2015) 4
work page 2015
-
[42]
Schepers, M., Giuberti, M., Bellusci, G., et al.: Xsens mvn: Consistent tracking of human motion using inertial sensing. Xsens Technol 1(8) (2018) 4
work page 2018
- [43]
-
[44]
Shin, S., Li, Z., Halilaj, E.: Markerless motion tracking with noisy video and IMU data. IEEE Trans. Biomed. Eng. 70(11), 3082–3092 (2023) 5
work page 2023
- [45]
- [46]
-
[47]
ACM TOG30(3), 18:1–18:12 (2011) 4
Tautges, J., Zinke, A., Krüger, B., Baumann, J., Weber, A., Helten, T., Müller, M., Seidel, H., Eberhardt, B.: Motion reconstruction using sparse accelerometer data. ACM TOG30(3), 18:1–18:12 (2011) 4
work page 2011
- [48]
- [49]
-
[50]
Trumble, M., Gilbert, A., Malleson, C., Hilton, A., Collomosse, J.P.: Total capture: 3d human pose estimation fusing video and inertial sensors. In: BMVC (2017) 1, 2, 3, 5, 8
work page 2017
-
[51]
IEEE TPAMI 43(10), 3349–3364 (2021) 7
Wang, J., Sun, K., Cheng, T., Jiang, B., Deng, C., Zhao, Y ., Liu, D., Mu, Y ., Tan, M., Wang, X., Liu, W., Xiao, B.: Deep high-resolution representation learning for visual recognition. IEEE TPAMI 43(10), 3349–3364 (2021) 7
work page 2021
- [52]
-
[53]
IEEE TPAMI 41(11), 2740–2755 (2019) 14
Wang, L., Xiong, Y ., Wang, Z., Qiao, Y ., Lin, D., Tang, X., Gool, L.V .: Temporal segment networks for action recognition in videos. IEEE TPAMI 41(11), 2740–2755 (2019) 14
work page 2019
-
[54]
Xu, L., Jin, S., Liu, W., Qian, C., Ouyang, W., Luo, P., Wang, X.: Zoomnas: Searching for whole-body human pose estimation in the wild. IEEE TPAMI (2022) 7
work page 2022
- [55]
- [56]
-
[57]
ACM TOG 40(4), 86:1–86:13 (2021) 4, 11
Yi, X., Zhou, Y ., Xu, F.: Transpose: real-time 3d human translation and pose estimation with six inertial sensors. ACM TOG 40(4), 86:1–86:13 (2021) 4, 11
work page 2021
- [58]
- [59]
-
[60]
Zhang, H., Tian, Y ., Zhang, Y ., Li, M., An, L., Sun, Z., Liu, Y .: Pymaf-x: Towards well- aligned full-body model regression from monocular images. IEEE Trans. Pattern Anal. Mach. Intell. 45(10), 12287–12303 (2023) 4
work page 2023
- [61]
-
[62]
IEEE TPAMI22(11), 1330–1334 (2000) 6
Zhang, Z.: A flexible new technique for camera calibration. IEEE TPAMI22(11), 1330–1334 (2000) 6
work page 2000
- [63]
-
[64]
6m 3d wholebody dataset and benchmark
Zhu, Y ., Samet, N., Picard, D.: H3wb: Human3. 6m 3d wholebody dataset and benchmark. In: ICCV . pp. 20166–20177 (2023) 3
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.