Task Prompt Vectors: Effective Initialization through Multi-Task Soft-Prompt Transfer
Pith reviewed 2026-05-23 22:10 UTC · model grok-4.3
The pith
Task prompt vectors formed by subtracting random initialization from tuned soft prompts enable effective low-resource initialization and arithmetic combination across tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
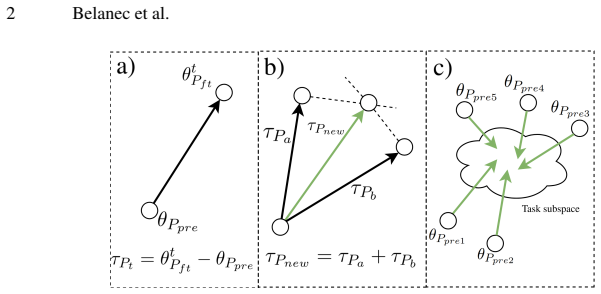
Task prompt vectors are created by the element-wise difference between the weights of tuned soft-prompts and their random initialization. These vectors isolate transferable task-specific information that can initialize prompt tuning effectively on similar tasks in low-resource settings. The vectors prove independent of the particular random initialization and work across two different language model architectures, which permits arithmetic operations such as addition of vectors from multiple tasks to deliver competitive multi-task performance.
What carries the argument
Task prompt vectors, defined as the element-wise difference between tuned soft-prompt weights and their random initialization, isolate transferable task information for initialization and arithmetic.
If this is right
- Task prompt vectors can initialize prompt tuning effectively on similar tasks using limited data.
- Task prompt vectors remain independent of the random initialization seed used during original tuning.
- Arithmetic addition of task prompt vectors from multiple tasks yields competitive multi-task performance.
- The vectors transfer across at least two different language model architectures.
Where Pith is reading between the lines
- Precomputed task prompt vectors could be stored and reused to lower the cost of adapting models to new task combinations.
- The subtraction technique might extend to other parameter-efficient methods such as adapters or LoRA modules.
- Independence from architecture opens the possibility of transferring task vectors between models of different sizes or families.
Load-bearing premise
The element-wise difference between a tuned soft prompt and its random initialization must capture only transferable task-specific information that remains useful when added to a new random prompt on a related task.
What would settle it
An experiment showing that task prompt vectors from similar tasks produce no improvement over random initialization when used to start prompt tuning on a new related task, or that their addition yields worse results than training a single combined prompt.
Figures



read the original abstract
Prompt tuning is an efficient solution for training large language models (LLMs). However, current soft-prompt-based methods often sacrifice multi-task modularity, requiring the training process to be fully or partially repeated for each newly added task. While recent work on task vectors applied arithmetic operations on full model weights to achieve the desired multi-task performance, a similar approach for soft-prompts is still missing. To this end, we introduce Task Prompt Vectors, created by element-wise difference between weights of tuned soft-prompts and their random initialization. Experimental results on 12 NLU datasets show that task prompt vectors can be used in low-resource settings to effectively initialize prompt tuning on similar tasks. In addition, we show that task prompt vectors are independent of the random initialization of prompt tuning on 2 different language model architectures. This allows prompt arithmetics with the pre-trained vectors from different tasks. In this way, we provide a competitive alternative to state-of-the-art baselines by arithmetic addition of task prompt vectors from multiple tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Task Prompt Vectors (TPVs), defined as the element-wise difference between a tuned soft prompt and its random initialization. It reports experimental results on 12 NLU datasets showing that TPVs enable effective initialization of prompt tuning for similar tasks in low-resource settings, that TPVs are independent of the random seed and of the underlying LM architecture (tested on two models), and that arithmetic combinations of TPVs from multiple tasks yield multi-task performance competitive with state-of-the-art baselines.
Significance. If the empirical claims hold under rigorous controls, the work supplies a modular mechanism for transferring and composing task-specific knowledge directly in the soft-prompt space. This extends the task-vector paradigm from full-model weights to the more parameter-efficient prompt-tuning regime and could reduce the need to retrain prompts from scratch when adding related tasks or combining multiple tasks.
major comments (2)
- [Abstract / Experimental results] The abstract and high-level claims assert positive results on 12 NLU datasets and independence from initialization/architecture, yet no information is supplied on the choice of baselines, data splits, number of random seeds, or any statistical significance tests. Because these details are required to evaluate whether the reported gains are reliable and not confounded, the support for the central empirical claims cannot be assessed from the provided description.
- [§3 (method) and §4 (experiments)] The weakest assumption—that the element-wise difference isolates transferable task information independent of seed and architecture—is load-bearing for both the initialization and arithmetic claims. Without quantitative evidence (e.g., cosine similarity or downstream performance variance across multiple seeds and the two architectures), it remains unclear whether the observed benefits are robust or specific to the particular experimental conditions.
minor comments (1)
- [Tables/Figures] Ensure that all tables and figures reporting performance numbers include error bars or standard deviations across runs.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on clarifying experimental details and strengthening evidence for independence claims. We address each point below and will revise the manuscript to improve transparency and add requested analyses.
read point-by-point responses
-
Referee: [Abstract / Experimental results] The abstract and high-level claims assert positive results on 12 NLU datasets and independence from initialization/architecture, yet no information is supplied on the choice of baselines, data splits, number of random seeds, or any statistical significance tests. Because these details are required to evaluate whether the reported gains are reliable and not confounded, the support for the central empirical claims cannot be assessed from the provided description.
Authors: We agree the abstract lacks these specifics. The full manuscript (Section 4) details the baselines (standard single-task prompt tuning and multi-task methods), data splits (official splits for the 12 NLU datasets), use of multiple random seeds with averaged results, and includes performance metrics. To address the concern directly, we will revise the abstract to note that results are averaged over 3 seeds with standard deviations and that statistical tests (paired t-tests) confirm significance of gains where reported. This makes the protocol explicit at the high level without altering the claims. revision: yes
-
Referee: [§3 (method) and §4 (experiments)] The weakest assumption—that the element-wise difference isolates transferable task information independent of seed and architecture—is load-bearing for both the initialization and arithmetic claims. Without quantitative evidence (e.g., cosine similarity or downstream performance variance across multiple seeds and the two architectures), it remains unclear whether the observed benefits are robust or specific to the particular experimental conditions.
Authors: The manuscript demonstrates independence via consistent transfer performance across seeds and the two architectures (T5 and RoBERTa). However, we acknowledge that direct quantitative measures such as cosine similarity between TPVs from different seeds or explicit variance tables would provide stronger support. In revision we will add these analyses: cosine similarities of TPVs across seeds for the same task, and performance variance tables across seeds and architectures, to confirm the element-wise difference isolates task information robustly. revision: yes
Circularity Check
No significant circularity
full rationale
The paper introduces Task Prompt Vectors as an empirical construction (element-wise difference between tuned soft-prompt weights and random initialization) and validates their use for low-resource initialization and multi-task arithmetic via experiments on 12 NLU datasets across two model architectures. No derivation chain, equations, or predictions are presented that reduce the reported outcomes to definitional equivalence with the inputs; claims rest on experimental results rather than self-referential fitting or self-citation loops. The method is self-contained against external benchmarks with no load-bearing self-citations or ansatzes identified.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Task Prompt Vectors
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Model Merging in LLMs, MLLMs, and Beyond: Methods, Theories, Applications and Opportunities
The paper introduces a new taxonomy for model merging methods and reviews their applications in LLMs, MLLMs, continual learning, multi-task learning, and other subfields while outlining open challenges.
Reference graph
Works this paper leans on
-
[1]
In: Goldberg, Y ., Kozareva, Z., Zhang, Y
Asai, A., Salehi, M., Peters, M., Hajishirzi, H.: ATTEMPT: Parameter-efficient multi-task tuning via attentional mixtures of soft prompts. In: Goldberg, Y ., Kozareva, Z., Zhang, Y . (eds.) Proceedings of the 2022 Conference on EMNLP. pp. 6655–6672. ACL, Abu Dhabi, United Arab Emirates (Dec 2022). https://doi.org/10.18653/v1/2022.emnlp-main. 446
-
[2]
Auer, S., Bizer, C., Kobilarov, G., Lehmann, J., Cyganiak, R., Ives, Z.: Dbpedia: A nucleus for a web of open data. In: Aberer, K., Choi, K.S., Noy, N., Allemang, D., Lee, K.I., Nixon, L., Golbeck, J., Mika, P., Maynard, D., Mizoguchi, R., Schreiber, G., Cudré-Mauroux, P. (eds.) The Semantic Web. pp. 722–735. Springer Berlin Heidelberg, Berlin, Heidelberg (2007)
work page 2007
-
[3]
DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
Bi, X., Chen, D., Chen, G., Chen, S., Dai, D., Deng, C., Ding, H., Dong, K., Du, Q., Fu, Z., et al.: Deepseek llm: Scaling open-source language models with longtermism. arXiv preprint arXiv:2401.02954 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
In: Proceedings of the 2015 Conference on EMNLP (EMNLP)
Bowman, S.R., Angeli, G., Potts, C., Manning, C.D.: A large annotated corpus for learning natural language inference. In: Proceedings of the 2015 Conference on EMNLP (EMNLP). ACL (2015)
work page 2015
-
[5]
Advances in neural information processing systems 33, 1877–1901 (2020)
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J.D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al.: Language models are few-shot learners. Advances in neural information processing systems 33, 1877–1901 (2020)
work page 1901
-
[6]
S em E val-2017 task 1: Semantic textual similarity multilingual and crosslingual focused evaluation
Cer, D., Diab, M., Agirre, E., Lopez-Gazpio, I., Specia, L.: SemEval-2017 task 1: Semantic textual similarity multilingual and crosslingual focused evaluation. In: Bethard, S., Carpuat, M., Apidianaki, M., Mohammad, S.M., Cer, D., Jurgens, D. (eds.) Proceedings of the 11th International Workshop on Semantic Evaluation (SemEval-2017). pp. 1–14. ACL, Vancou...
-
[7]
arXiv preprint arXiv:2311.09344 (2023)
Chronopoulou, A., Pfeiffer, J., Maynez, J., Wang, X., Ruder, S., Agrawal, P.: Language and task arithmetic with parameter-efficient layers for zero-shot summarization. arXiv preprint arXiv:2311.09344 (2023)
-
[8]
No Language Left Behind: Scaling Human-Centered Machine Translation
Costa-Jussà, M.R., Cross, J., Çelebi, O., Elbayad, M., Heafield, K., Heffernan, K., Kalbassi, E., Lam, J., Licht, D., Maillard, J., et al.: No language left behind: Scaling human-centered machine translation. arXiv preprint arXiv:2207.04672 (2022) 16 Belanec et al
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [9]
-
[10]
In: Proceedings of the International Workshop on Paraphrasing (2005)
Dolan, W.B., Brockett, C.: Automatically constructing a corpus of sentential paraphrases. In: Proceedings of the International Workshop on Paraphrasing (2005)
work page 2005
-
[11]
Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Yang, A., Fan, A., et al.: The llama 3 herd of models. arXiv preprint arXiv:2407.21783 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Journal of the American Statistical Association 54(287), 613–621 (1959)
Dunn, O.J.: Confidence intervals for the means of dependent, normally distributed variables. Journal of the American Statistical Association 54(287), 613–621 (1959)
work page 1959
-
[13]
Fourrier, C., Habib, N., Wolf, T., Tunstall, L.: Lighteval: A lightweight framework for llm evaluation (2023), https://github.com/huggingface/lighteval
work page 2023
- [14]
-
[15]
PPT : Pre-trained prompt tuning for few-shot learning
Gu, Y ., Han, X., Liu, Z., Huang, M.: PPT: Pre-trained prompt tuning for few-shot learning. In: Muresan, S., Nakov, P., Villavicencio, A. (eds.) Proceedings of the 60th Annual Meeting of the ACL (V olume 1: Long Papers). pp. 8410–8423. ACL, Dublin, Ireland (May 2022). https://doi.org/10.18653/v1/2022.acl-long.576
-
[16]
arXiv preprint arXiv:2502.10140 (2025)
Gurgurov, D., Vykopal, I., van Genabith, J., Ostermann, S.: Small models, big impact: Efficient corpus and graph-based adaptation of small multilingual language models for low-resource languages. arXiv preprint arXiv:2502.10140 (2025)
- [17]
-
[18]
In: Proceedings of the First International Conference on Human Language Technology Research (2001)
Hovy, E., Gerber, L., Hermjakob, U., Lin, C.Y ., Ravichandran, D.: Toward semantics-based answer pinpointing. In: Proceedings of the First International Conference on Human Language Technology Research (2001)
work page 2001
-
[19]
In: ICLR (2022), https://openreview
Hu, E.J., yelong shen, Wallis, P., Allen-Zhu, Z., Li, Y ., Wang, S., Wang, L., Chen, W.: LoRA: Low-rank adaptation of large language models. In: ICLR (2022), https://openreview. net/forum?id=nZeVKeeFYf9
work page 2022
-
[20]
Ilharco, G., Ribeiro, M.T., Wortsman, M., Schmidt, L., Hajishirzi, H., Farhadi, A.: Editing models with task arithmetic. In: The Eleventh ICLR (2022)
work page 2022
-
[21]
In: AAAI Conference on Artificial Intelligence (2018), https://api
Khot, T., Sabharwal, A., Clark, P.: Scitail: A textual entailment dataset from science ques- tion answering. In: AAAI Conference on Artificial Intelligence (2018), https://api. semanticscholar.org/CorpusID:24462950
work page 2018
-
[22]
arXiv preprint arXiv:2404.15737 (2024)
Klimaszewski, M., Andruszkiewicz, P., Birch, A.: No train but gain: Language arithmetic for training-free language adapters enhancement. arXiv preprint arXiv:2404.15737 (2024)
-
[23]
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Xin Zhao, and Ji-Rong Wen
Lee, H., Jeong, M., Yun, S.Y ., Kim, K.E.: Bayesian multi-task transfer learning for soft prompt tuning. In: Bouamor, H., Pino, J., Bali, K. (eds.) Findings of the ACL: EMNLP 2023. pp. 4942–4958. ACL, Singapore (Dec 2023). https://doi.org/10.18653/v1/2023. findings-emnlp.329
-
[24]
URL https://aclanthology.org/2021
Lester, B., Al-Rfou, R., Constant, N.: The power of scale for parameter-efficient prompt tuning. In: Moens, M.F., Huang, X., Specia, L., Yih, S.W.t. (eds.) Proceedings of the 2021 Conference on EMNLP. pp. 3045–3059. ACL, Online and Punta Cana, Dominican Republic (Nov 2021). https://doi.org/10.18653/v1/2021.emnlp-main.243
- [25]
-
[26]
In: Zong, C., Xia, F., Li, W., Navigli, R
Li, X.L., Liang, P.: Prefix-tuning: Optimizing continuous prompts for generation. In: Zong, C., Xia, F., Li, W., Navigli, R. (eds.) Proceedings of the 59th Annual Meeting of the ACL and Task Prompt Vectors 17 the 11th International Joint Conference on Natural Language Processing (V olume 1: Long Papers). pp. 4582–4597. ACL, Online (Aug 2021). https://doi....
-
[27]
In: COLING 2002: The 19th International Conference on Computational Linguistics (2002)
Li, X., Roth, D.: Learning question classifiers. In: COLING 2002: The 19th International Conference on Computational Linguistics (2002)
work page 2002
-
[28]
Liu, X., Zheng, Y ., Du, Z., Ding, M., Qian, Y ., Yang, Z., Tang, J.: Gpt understands, too. AI Open (2023)
work page 2023
-
[29]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Liu, Y ., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., Levy, O., Lewis, M., Zettlemoyer, L., Stoyanov, V .: Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[30]
In: Lin, D., Matsumoto, Y ., Mihalcea, R
Maas, A.L., Daly, R.E., Pham, P.T., Huang, D., Ng, A.Y ., Potts, C.: Learning word vectors for sentiment analysis. In: Lin, D., Matsumoto, Y ., Mihalcea, R. (eds.) Proceedings of the 49th Annual Meeting of the ACL: Human Language Technologies. pp. 142–150. ACL, Portland, Oregon, USA (Jun 2011)
work page 2011
- [31]
-
[32]
Advances in Neural Information Processing Systems 36 (2024)
Ortiz-Jimenez, G., Favero, A., Frossard, P.: Task arithmetic in the tangent space: Improved editing of pre-trained models. Advances in Neural Information Processing Systems 36 (2024)
work page 2024
-
[33]
arXiv preprint arXiv:2402.12819 (2024)
Pecher, B., Srba, I., Bielikova, M.: Comparing specialised small and general large language models on text classification: 100 labelled samples to achieve break-even performance. arXiv preprint arXiv:2402.12819 (2024)
-
[34]
In: Merlo, P., Tiedemann, J., Tsarfaty, R
Pfeiffer, J., Kamath, A., Rücklé, A., Cho, K., Gurevych, I.: AdapterFusion: Non-destructive task composition for transfer learning. In: Merlo, P., Tiedemann, J., Tsarfaty, R. (eds.) Proceed- ings of the 16th Conference of the European Chapter of the ACL: Main V olume. pp. 487–503. ACL, Online (Apr 2021). https://doi.org/10.18653/v1/2021.eacl-main. 39
-
[35]
Qin, Y ., Wang, X., Su, Y ., Lin, Y ., Ding, N., Yi, J., Chen, W., Liu, Z., Li, J., Hou, L., Li, P., Sun, M., Zhou, J.: Exploring universal intrinsic task subspace for few-shot learning via prompt tuning. IEEE/ACM Trans. Audio, Speech and Lang. Proc. 32, 3631–3643 (Jul 2024). https://doi.org/10.1109/TASLP.2024.3430545, https://doi.org/10. 1109/TASLP.2024.3430545
-
[36]
Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., Sutskever, I., et al.: Language models are unsupervised multitask learners. OpenAI blog 1(8), 9 (2019)
work page 2019
-
[37]
Journal of machine learning research 21(140), 1–67 (2020)
Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y ., Li, W., Liu, P.J.: Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of machine learning research 21(140), 1–67 (2020)
work page 2020
-
[38]
Rajpurkar, P., Jia, R., Liang, P.: Know what you don’t know: Unanswerable questions for SQuAD. In: Gurevych, I., Miyao, Y . (eds.) Proceedings of the 56th Annual Meeting of the ACL (V olume 2: Short Papers). pp. 784–789. ACL, Melbourne, Australia (Jul 2018). https://doi.org/10.18653/v1/P18-2124
- [39]
-
[40]
In: The Twelfth ICLR (2024), https://openreview.net/forum?id=KjegfPGRde
Shi, Z., Lipani, A.: DePT: Decomposed prompt tuning for parameter-efficient fine-tuning. In: The Twelfth ICLR (2024), https://openreview.net/forum?id=KjegfPGRde
work page 2024
-
[41]
In: Proceedings of the 2013 conference on EMNLP
Socher, R., Perelygin, A., Wu, J., Chuang, J., Manning, C.D., Ng, A.Y ., Potts, C.: Recursive deep models for semantic compositionality over a sentiment treebank. In: Proceedings of the 2013 conference on EMNLP. pp. 1631–1642 (2013)
work page 2013
-
[42]
03053, arXiv:2305.03053 [cs] 18 Belanec et al
Stoica, G., Bolya, D., Bjorner, J., Ramesh, P., Hearn, T., Hoffman, J.: ZipIt! Merging Models from Different Tasks without Training (Mar 2024), http://arxiv.org/abs/2305. 03053, arXiv:2305.03053 [cs] 18 Belanec et al
- [43]
-
[44]
In: Carpuat, M., de Marneffe, M.C., Meza Ruiz, I.V
Su, Y ., Wang, X., Qin, Y ., Chan, C.M., Lin, Y ., Wang, H., Wen, K., Liu, Z., Li, P., Li, J., Hou, L., Sun, M., Zhou, J.: On transferability of prompt tuning for natural language processing. In: Carpuat, M., de Marneffe, M.C., Meza Ruiz, I.V . (eds.) Proceedings of the 2022 Conference of the North American Chapter of the ACL: Human Language Technologies....
work page 2022
-
[45]
In: Muresan, S., Nakov, P., Villavicencio, A
Vu, T., Lester, B., Constant, N., Al-Rfou’, R., Cer, D.: SPoT: Better frozen model adaptation through soft prompt transfer. In: Muresan, S., Nakov, P., Villavicencio, A. (eds.) Proceedings of the 60th Annual Meeting of the ACL (V olume 1: Long Papers). pp. 5039–5059. ACL, Dublin, Ireland (May 2022). https://doi.org/10.18653/v1/2022.acl-long.346
-
[46]
Wang, A., Singh, A., Michael, J., Hill, F., Levy, O., Bowman, S.: GLUE: A multi-task benchmark and analysis platform for natural language understanding. In: Linzen, T., Chrupała, G., Alishahi, A. (eds.) Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP. pp. 353–355. ACL, Brussels, Belgium (Nov 2018). ht...
-
[47]
In: The Eleventh ICLR (2023), https:// openreview.net/forum?id=Nk2pDtuhTq
Wang, Z., Panda, R., Karlinsky, L., Feris, R., Sun, H., Kim, Y .: Multitask prompt tuning enables parameter-efficient transfer learning. In: The Eleventh ICLR (2023), https:// openreview.net/forum?id=Nk2pDtuhTq
work page 2023
-
[48]
Transactions of the ACL 7, 625–641 (2019)
Warstadt, A., Singh, A., Bowman, S.R.: Neural network acceptability judgments. Transactions of the ACL 7, 625–641 (2019). https://doi.org/10.1162/tacl_a_00290
-
[49]
A Broad-Coverage Challenge Corpus for Sentence Understanding through Inference
Williams, A., Nangia, N., Bowman, S.: A broad-coverage challenge corpus for sentence understanding through inference. In: Walker, M., Ji, H., Stent, A. (eds.) Proceedings of the 2018 Conference of the North American Chapter of the ACL: Human Language Technologies, V olume 1 (Long Papers). pp. 1112–1122. ACL, New Orleans, Louisiana (Jun 2018).https: //doi....
work page internal anchor Pith review doi:10.18653/v1/n18-1101 2018
-
[50]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Wortsman, M., Ilharco, G., Kim, J.W., Li, M., Kornblith, S., Roelofs, R., Lopes, R.G., Hajishirzi, H., Farhadi, A., Namkoong, H., et al.: Robust fine-tuning of zero-shot models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 7959–7971 (2022)
work page 2022
-
[51]
arXiv preprint arXiv:2312.12148 (2023)
Xu, L., Xie, H., Qin, S.Z.J., Tao, X., Wang, F.L.: Parameter-efficient fine-tuning meth- ods for pretrained language models: A critical review and assessment. arXiv preprint arXiv:2312.12148 (2023)
-
[52]
Advances in Neural Information Processing Systems 36, 12589–12610 (2023)
Zhang, J., Liu, J., He, J., et al.: Composing parameter-efficient modules with arithmetic operation. Advances in Neural Information Processing Systems 36, 12589–12610 (2023)
work page 2023
-
[53]
Advances in neural information processing systems 28 (2015)
Zhang, X., Zhao, J., LeCun, Y .: Character-level convolutional networks for text classification. Advances in neural information processing systems 28 (2015)
work page 2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.