Automatic Dataset Construction (ADC): Sample Collection, Data Curation, and Beyond
Pith reviewed 2026-05-23 21:44 UTC · model grok-4.3
The pith
LLMs design classes and generate code to collect and curate over a million images via search engines, reaching 79 percent agreement with humans while halving label noise.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
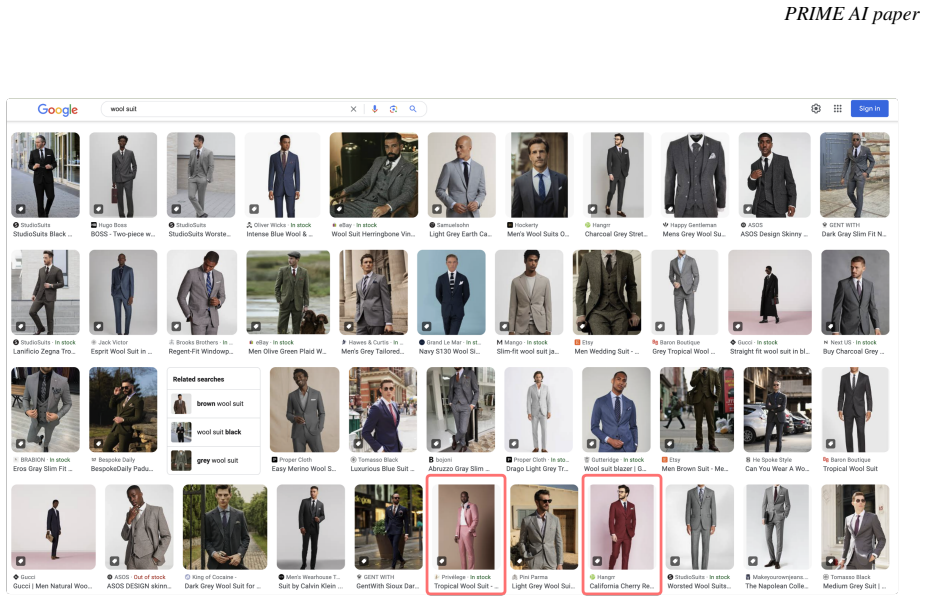
ADC leverages LLMs for the detailed class design and code generation to collect relevant samples via search engines, significantly reducing the need for manual annotation and speeding up the data generation process. To demonstrate ADC at scale, we construct Clothing-ADC: a dataset of over 1 million images spanning 12 main classes and 12,000 fine-grained subclasses. Our automated curation achieves 79% agreement with human annotators and reduces label noise from 22.2% to 10.7%.
What carries the argument
LLM-driven class design combined with generated code that queries search engines, followed by automated curation scripts.
If this is right
- Datasets of million-image scale can be produced for new fine-grained classification problems with far less human labeling effort.
- Open-source tools for detecting label errors and training under noise or imbalance become directly usable on the generated data.
- Three new public benchmarks allow standardized testing of label-noise detection, noise-robust learning, and class-imbalance methods.
- Existing popular methods for these three problems can be re-evaluated on the released benchmarks to measure current performance.
Where Pith is reading between the lines
- The same pipeline could be applied to non-image modalities if suitable search APIs exist for text, audio, or video.
- Faster dataset iteration might accelerate specialized model fine-tuning in domains where labeled data has historically been scarce.
- Search-engine biases could still limit diversity even when label noise is reduced, suggesting a need for diversity audits on the collected samples.
Load-bearing premise
Search engine results supply samples that are relevant enough for LLM-generated curation to reach high agreement with humans without introducing large systematic biases.
What would settle it
Running the full ADC pipeline on a held-out visual domain and finding that human agreement falls below 60 percent or that label noise stays above 15 percent after curation.
Figures






read the original abstract
Large-scale data collection is essential for developing personalized training data, mitigating the shortage of training data, and fine-tuning specialized models. However, creating high-quality datasets quickly and accurately remains a challenge due to annotation errors, the substantial time and costs associated with human labor. To address these issues, we propose Automatic Dataset Construction (ADC), an innovative methodology that automates dataset creation with negligible cost and high efficiency. Taking the image classification task as a starting point, ADC leverages LLMs for the detailed class design and code generation to collect relevant samples via search engines, significantly reducing the need for manual annotation and speeding up the data generation process. To demonstrate ADC at scale, we construct Clothing-ADC: a dataset of over 1 million images spanning 12 main classes and 12,000 fine-grained subclasses. Our automated curation achieves 79\% agreement with human annotators and reduces label noise from 22.2\% to 10.7\%. Despite these advantages, ADC also encounters real-world challenges such as label errors (label noise) and imbalanced data distributions (label bias). We provide open-source software that incorporates existing methods for label error detection, robust learning under noisy and biased data, ensuring a higher-quality training data and more robust model training procedure. Furthermore, we design three benchmark datasets focused on label noise detection, label noise learning, and class-imbalanced learning. These datasets are vital because there are few existing datasets specifically for label noise detection, despite its importance. Finally, we evaluate the performance of existing popular methods on these datasets, thereby facilitating further research in the field.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Automatic Dataset Construction (ADC), a pipeline that uses LLMs to design detailed classes and generate code for collecting image samples via search engines, with the goal of automating large-scale dataset creation at negligible cost. It demonstrates the approach by constructing Clothing-ADC (>1M images, 12 main classes, 12k fine-grained subclasses), reports that automated curation achieves 79% agreement with human annotators and reduces label noise from 22.2% to 10.7%, releases open-source software for label-error detection and robust learning under noise/bias, and introduces three new benchmark datasets for label-noise detection, noise-robust learning, and class-imbalanced learning together with evaluations of existing methods on them.
Significance. If the reported agreement rates and noise reductions are shown to generalize under transparent validation protocols, ADC could meaningfully accelerate the creation of fine-grained labeled datasets and reduce reliance on manual annotation. The released benchmarks and tooling for noisy/imbalanced settings would also provide concrete resources for research on robust learning.
major comments (3)
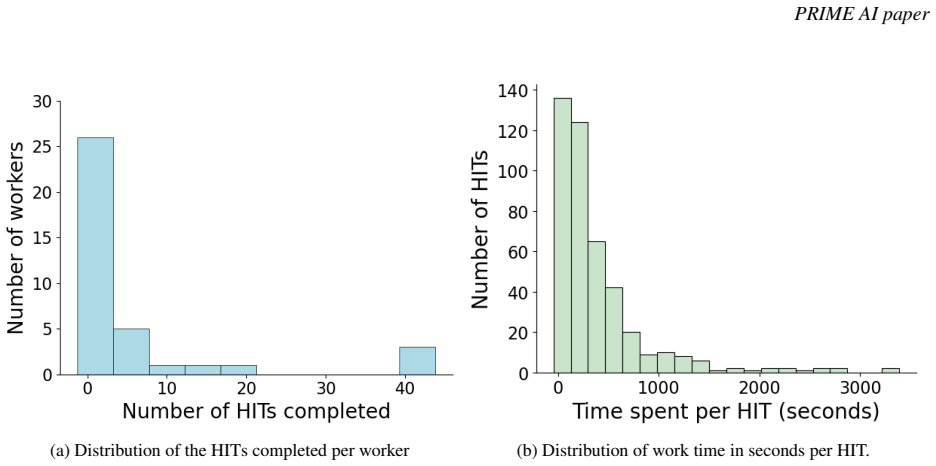
- [Abstract] Abstract: the headline claims of 79% human agreement and noise reduction from 22.2% to 10.7% are presented without any description of the validation subset size, how the subset was sampled, how label noise was measured before versus after curation, inter-annotator agreement among humans, or comparison to any baseline curation procedure; these omissions make it impossible to judge whether the automated step scales reliably to 12k fine-grained classes.
- [Abstract] Abstract: the central efficiency claim rests on the premise that search-engine results plus LLM-generated curation code yield samples whose quality is close to human without large-scale manual intervention, yet no analysis is supplied of class-specific relevance rates, search-ranking biases, or failure modes across the 12k subclasses.
- [Abstract] Abstract: although label bias is listed as a remaining challenge, the manuscript provides no quantitative evidence that the automated pipeline reduces distributional imbalance at the scale of Clothing-ADC.
minor comments (1)
- [Abstract] Abstract: the three new benchmark datasets are mentioned but not named, sized, or contrasted with existing resources, which would help readers assess their novelty.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major comment point by point below. Where the abstract lacks necessary context, we agree that revisions are warranted to improve transparency.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claims of 79% human agreement and noise reduction from 22.2% to 10.7% are presented without any description of the validation subset size, how the subset was sampled, how label noise was measured before versus after curation, inter-annotator agreement among humans, or comparison to any baseline curation procedure; these omissions make it impossible to judge whether the automated step scales reliably to 12k fine-grained classes.
Authors: The referee correctly identifies that the abstract omits these validation details. The main text describes the human study used to obtain the 79% agreement figure and the before/after noise rates, including sampling from the Clothing-ADC collection and the procedure for measuring label noise via human labels. We will revise the abstract to include a concise statement on subset size, sampling approach, and inter-annotator agreement. A comparison against a baseline curation procedure appears in the experimental results. revision: yes
-
Referee: [Abstract] Abstract: the central efficiency claim rests on the premise that search-engine results plus LLM-generated curation code yield samples whose quality is close to human without large-scale manual intervention, yet no analysis is supplied of class-specific relevance rates, search-ranking biases, or failure modes across the 12k subclasses.
Authors: We agree that class-specific relevance rates and explicit failure-mode analysis across all 12k subclasses are not reported. The paper supplies only aggregate relevance and noise statistics because per-subclass human labeling at this scale was not feasible. We will add a sentence to the abstract acknowledging that search-ranking biases and subclass-level variation remain unquantified and are discussed as limitations. revision: partial
-
Referee: [Abstract] Abstract: although label bias is listed as a remaining challenge, the manuscript provides no quantitative evidence that the automated pipeline reduces distributional imbalance at the scale of Clothing-ADC.
Authors: The manuscript does not claim that ADC reduces distributional imbalance; it lists label bias as an open challenge. We will revise the abstract wording to make this explicit and to avoid any implication that quantitative evidence of bias reduction is provided. revision: yes
Circularity Check
No circularity; empirical pipeline proposal with external human-agreement validation
full rationale
The paper presents ADC as a methodological pipeline for automated data collection and curation using LLMs and search engines. It reports concrete empirical results (79% human agreement, noise drop from 22.2% to 10.7%) on Clothing-ADC without any equations, derivations, fitted parameters renamed as predictions, or self-citation chains that reduce claims to inputs by construction. The validation metrics are measured against independent human annotators, satisfying the criterion for non-circular external support. No load-bearing steps match any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLMs can generate accurate and relevant class designs and executable code for image collection via search engines.
- domain assumption Search engine results provide samples amenable to automated curation that achieves high human agreement.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
ADC leverages LLMs for the detailed class design and code generation to collect relevant samples via search engines... automated curation achieves 79% agreement... reduces label noise from 22.2% to 10.7%.
-
IndisputableMonolith/Foundation/DimensionForcing.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We design three benchmark datasets focused on label noise detection, label noise learning, and class-imbalanced learning.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Supplement Generation Training for Enhancing Agentic Task Performance
SGT trains a lightweight model to generate task-specific supplemental text that improves performance of a larger frozen LLM on agentic tasks without modifying the large model.
Reference graph
Works this paper leans on
-
[1]
Leveraging large language models for decision support in personalized oncology
Manuela Benary, Xing David Wang, Max Schmidt, Dominik Soll, Georg Hilfenhaus, Mani Nassir, Christian Sigler, Maren Knödler, Ulrich Keller, Dieter Beule, et al. Leveraging large language models for decision support in personalized oncology. JAMA Network Open, 6(11):e2343689–e2343689, 2023
work page 2023
-
[2]
Autogen: A personalized large language model for academic enhancement—ethics and proof of principle
Sebastian Porsdam Mann, Brian D Earp, Nikolaj Møller, Suren Vynn, and Julian Savulescu. Autogen: A personalized large language model for academic enhancement—ethics and proof of principle. The American Journal of Bioethics, 23(10):28–41, 2023
work page 2023
-
[3]
Personalized large language models
Stanisław Wo´ zniak, Bartłomiej Koptyra, Arkadiusz Janz, Przemysław Kazienko, and Jan Koco´n. Personalized large language models. arXiv preprint arXiv:2402.09269, 2024
-
[4]
Tidybot: Personalized robot assistance with large language models
Jimmy Wu, Rika Antonova, Adam Kan, Marion Lepert, Andy Zeng, Shuran Song, Jeannette Bohg, Szymon Rusinkiewicz, and Thomas Funkhouser. Tidybot: Personalized robot assistance with large language models. Autonomous Robots, 47(8):1087–1102, 2023
work page 2023
-
[5]
Llm-rec: Personalized recommendation via prompting large language models
Hanjia Lyu, Song Jiang, Hanqing Zeng, Yinglong Xia, and Jiebo Luo. Llm-rec: Personalized recommendation via prompting large language models. arXiv preprint arXiv:2307.15780, 2023
-
[6]
Democratizing large language models via personalized parameter-efficient fine-tuning
Zhaoxuan Tan, Qingkai Zeng, Yijun Tian, Zheyuan Liu, Bing Yin, and Meng Jiang. Democratizing large language models via personalized parameter-efficient fine-tuning. arXiv preprint arXiv:2402.04401, 2024
-
[7]
Learning from massive noisy labeled data for image classification
Tong Xiao, Tian Xia, Yi Yang, Chang Huang, and Xiaogang Wang. Learning from massive noisy labeled data for image classification. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2691–2699, 2015
work page 2015
-
[8]
Learning multiple layers of features from tiny images
Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. 2009
work page 2009
-
[9]
Learning with noisy labels revisited: A study using real-world human annotations
Jiaheng Wei, Zhaowei Zhu, Hao Cheng, Tongliang Liu, Gang Niu, and Yang Liu. Learning with noisy labels revisited: A study using real-world human annotations. arXiv preprint arXiv:2110.12088, 2021
-
[10]
Deep learning face attributes in the wild
Ziwei Liu, Ping Luo, Xiaogang Wang, and Xiaoou Tang. Deep learning face attributes in the wild. In Proceedings of International Conference on Computer Vision (ICCV), December 2015
work page 2015
-
[11]
Vikram V Ramaswamy, Sunnie SY Kim, Ruth Fong, and Olga Russakovsky. Overlooked factors in concept-based explanations: Dataset choice, concept learnability, and human capability. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10932–10941, 2023
work page 2023
-
[12]
Nagarajan Natarajan, Inderjit S Dhillon, Pradeep K Ravikumar, and Ambuj Tewari. Learning with noisy labels. Advances in neural information processing systems, 26, 2013
work page 2013
-
[13]
Classification with noisy labels by importance reweighting
Tongliang Liu and Dacheng Tao. Classification with noisy labels by importance reweighting. IEEE Transactions on pattern analysis and machine intelligence, 38(3):447–461, 2015
work page 2015
-
[14]
WebVision Database: Visual Learning and Understanding from Web Data
Wen Li, Limin Wang, Wei Li, Eirikur Agustsson, and Luc Van Gool. Webvision database: Visual learning and understanding from web data. arXiv preprint arXiv:1708.02862, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[15]
Learning with noisy labels revisited: A study using real-world human annotations
Jiaheng Wei, Zhaowei Zhu, Hao Cheng, Tongliang Liu, Gang Niu, and Yang Liu. Learning with noisy labels revisited: A study using real-world human annotations. In International Conference on Learning Representations, 2022
work page 2022
-
[16]
Revolt: Collaborative crowdsourcing for labeling machine learning datasets
Joseph Chee Chang, Saleema Amershi, and Ece Kamar. Revolt: Collaborative crowdsourcing for labeling machine learning datasets. In Proceedings of the 2017 CHI conference on human factors in computing systems , pages 2334–2346, 2017
work page 2017
-
[17]
Structured labeling for facilitating concept evolution in machine learning
Todd Kulesza, Saleema Amershi, Rich Caruana, Danyel Fisher, and Denis Charles. Structured labeling for facilitating concept evolution in machine learning. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, pages 3075–3084, 2014
work page 2014
-
[18]
Does the whole exceed its parts? the effect of ai explanations on complementary team performance
Gagan Bansal, Tongshuang Wu, Joyce Zhou, Raymond Fok, Besmira Nushi, Ece Kamar, Marco Tulio Ribeiro, and Daniel Weld. Does the whole exceed its parts? the effect of ai explanations on complementary team performance. In Proceedings of the 2021 CHI conference on human factors in computing systems, pages 1–16, 2021
work page 2021
-
[19]
Is the most accurate ai the best teammate? optimizing ai for teamwork
Gagan Bansal, Besmira Nushi, Ece Kamar, Eric Horvitz, and Daniel S Weld. Is the most accurate ai the best teammate? optimizing ai for teamwork. In Proceedings of the AAAI Conference on Artificial Intelligence , volume 35, pages 11405–11414, 2021
work page 2021
-
[20]
Iterative human-in-the-loop discovery of unknown unknowns in image datasets
Lei Han, Xiao Dong, and Gianluca Demartini. Iterative human-in-the-loop discovery of unknown unknowns in image datasets. In Proceedings of the AAAI Conference on Human Computation and Crowdsourcing, volume 9, pages 72–83, 2021. 10 PRIME AI paper
work page 2021
-
[21]
Get another label? improving data quality and data mining using multiple, noisy labelers
Victor S Sheng, Foster Provost, and Panagiotis G Ipeirotis. Get another label? improving data quality and data mining using multiple, noisy labelers. In Proceedings of the 14th ACM SIGKDD international conference on Knowledge discovery and data mining, pages 614–622, 2008
work page 2008
- [22]
- [23]
- [24]
-
[25]
Zhaowei Zhu, Jialu Wang, Hao Cheng, and Yang Liu. Unmasking and improving data credibility: A study with datasets for training harmless language models. arXiv preprint arXiv:2311.11202, 2023
-
[26]
Clusterability as an alternative to anchor points when learning with noisy labels
Zhaowei Zhu, Yiwen Song, and Yang Liu. Clusterability as an alternative to anchor points when learning with noisy labels. In International Conference on Machine Learning, pages 12912–12923. PMLR, 2021
work page 2021
-
[27]
Detecting corrupted labels without training a model to predict
Zhaowei Zhu, Zihao Dong, and Yang Liu. Detecting corrupted labels without training a model to predict. In International conference on machine learning, pages 27412–27427. PMLR, 2022
work page 2022
-
[28]
Updates in human-ai teams: Understanding and addressing the performance/compatibility tradeoff
Gagan Bansal, Besmira Nushi, Ece Kamar, Daniel S Weld, Walter S Lasecki, and Eric Horvitz. Updates in human-ai teams: Understanding and addressing the performance/compatibility tradeoff. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 33, pages 2429–2437, 2019
work page 2019
-
[29]
Minghao Liu, Jiaheng Wei, Yang Liu, and James Davis. Do humans and machines have the same eyes? human- machine perceptual differences on image classification. arXiv preprint arXiv:2304.08733, 2023
-
[30]
The inaturalist species classification and detection dataset
Grant Van Horn, Oisin Mac Aodha, Yang Song, Yin Cui, Chen Sun, Alex Shepard, Hartwig Adam, Pietro Perona, and Serge Belongie. The inaturalist species classification and detection dataset. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 8769–8778, 2018
work page 2018
-
[31]
SELFIE: Refurbishing unclean samples for robust deep learning
Hwanjun Song, Minseok Kim, and Jae-Gil Lee. SELFIE: Refurbishing unclean samples for robust deep learning. In ICML, 2019
work page 2019
-
[32]
Food-101 – mining discriminative components with random forests
Lukas Bossard, Matthieu Guillaumin, and Luc Van Gool. Food-101 – mining discriminative components with random forests. In European Conference on Computer Vision, 2014
work page 2014
-
[33]
Making deep neural networks robust to label noise: A loss correction approach
Giorgio Patrini, Alessandro Rozza, Aditya Krishna Menon, Richard Nock, and Lizhen Qu. Making deep neural networks robust to label noise: A loss correction approach. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1944–1952, 2017
work page 1944
-
[34]
Curtis Northcutt, Lu Jiang, and Isaac Chuang. Confident learning: Estimating uncertainty in dataset labels.Journal of Artificial Intelligence Research, 70:1373–1411, 2021
work page 2021
-
[35]
Estimating training data influence by tracing gradient descent
Garima Pruthi, Frederick Liu, Satyen Kale, and Mukund Sundararajan. Estimating training data influence by tracing gradient descent. Advances in Neural Information Processing Systems, 33:19920–19930, 2020
work page 2020
-
[36]
Deep self-learning from noisy labels
Jiangfan Han, Ping Luo, and Xiaogang Wang. Deep self-learning from noisy labels. In Proceedings of the IEEE/CVF international conference on computer vision, pages 5138–5147, 2019
work page 2019
-
[37]
Early-learning regularization prevents memorization of noisy labels
Sheng Liu, Jonathan Niles-Weed, Narges Razavian, and Carlos Fernandez-Granda. Early-learning regularization prevents memorization of noisy labels. Advances in neural information processing systems, 33:20331–20342, 2020
work page 2020
-
[38]
Robust early- learning: Hindering the memorization of noisy labels
Xiaobo Xia, Tongliang Liu, Bo Han, Chen Gong, Nannan Wang, Zongyuan Ge, and Yi Chang. Robust early- learning: Hindering the memorization of noisy labels. In International conference on learning representations, 2020
work page 2020
-
[39]
Identifying mislabeled training data.Journal of artificial intelligence research, 11:131–167, 1999
Carla E Brodley and Mark A Friedl. Identifying mislabeled training data.Journal of artificial intelligence research, 11:131–167, 1999
work page 1999
-
[40]
Improving identification of difficult small classes by balancing class distribution
Jorma Laurikkala. Improving identification of difficult small classes by balancing class distribution. In Artificial Intelligence in Medicine: 8th Conference on Artificial Intelligence in Medicine in Europe, AIME 2001 Cascais, Portugal, July 1–4, 2001, Proceedings 8, pages 63–66. Springer, 2001
work page 2001
-
[41]
Learning with instance-dependent label noise: A sample sieve approach
Hao Cheng, Zhaowei Zhu, Xingyu Li, Yifei Gong, Xing Sun, and Yang Liu. Learning with instance-dependent label noise: A sample sieve approach. arXiv preprint arXiv:2010.02347, 2020
-
[42]
Deep k-Nearest Neighbors: Towards Confident, Interpretable and Robust Deep Learning
Nicolas Papernot and Patrick McDaniel. Deep k-nearest neighbors: Towards confident, interpretable and robust deep learning. arXiv preprint arXiv:1803.04765, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[43]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016. 11 PRIME AI paper
work page 2016
-
[44]
Learning to reweight examples for robust deep learning
Mengye Ren, Wenyuan Zeng, Bin Yang, and Raquel Urtasun. Learning to reweight examples for robust deep learning. In International conference on machine learning, pages 4334–4343. PMLR, 2018
work page 2018
-
[45]
Symmetric cross entropy for robust learning with noisy labels
Yisen Wang, Xingjun Ma, Zaiyi Chen, Yuan Luo, Jinfeng Yi, and James Bailey. Symmetric cross entropy for robust learning with noisy labels. In Proceedings of the IEEE/CVF international conference on computer vision, pages 322–330, 2019
work page 2019
-
[46]
Generalized cross entropy loss for training deep neural networks with noisy labels
Zhilu Zhang and Mert Sabuncu. Generalized cross entropy loss for training deep neural networks with noisy labels. Advances in neural information processing systems, 31, 2018
work page 2018
-
[47]
Peer loss functions: Learning from noisy labels without knowing noise rates
Yang Liu and Hongyi Guo. Peer loss functions: Learning from noisy labels without knowing noise rates. In International conference on machine learning, pages 6226–6236. PMLR, 2020
work page 2020
-
[48]
When optimizing f-divergence is robust with label noise
Jiaheng Wei and Yang Liu. When optimizing f-divergence is robust with label noise. arXiv preprint arXiv:2011.03687, 2020
-
[49]
mixup: Beyond Empirical Risk Minimization
Hongyi Zhang, Moustapha Cisse, Yann N Dauphin, and David Lopez-Paz. mixup: Beyond empirical risk minimization. arXiv preprint arXiv:1710.09412, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[50]
When does label smoothing help? Advances in neural information processing systems, 32, 2019
Rafael Müller, Simon Kornblith, and Geoffrey E Hinton. When does label smoothing help? Advances in neural information processing systems, 32, 2019
work page 2019
-
[51]
Michal Lukasik, Srinadh Bhojanapalli, Aditya Menon, and Sanjiv Kumar. Does label smoothing mitigate label noise? In International Conference on Machine Learning, pages 6448–6458. PMLR, 2020
work page 2020
-
[52]
To smooth or not? when label smoothing meets noisy labels
Jiaheng Wei, Hangyu Liu, Tongliang Liu, Gang Niu, Masashi Sugiyama, and Yang Liu. To smooth or not? when label smoothing meets noisy labels. In International Conference on Machine Learning, pages 23589–23614. PMLR, 2022
work page 2022
-
[53]
Bo Han, Quanming Yao, Xingrui Yu, Gang Niu, Miao Xu, Weihua Hu, Ivor Tsang, and Masashi Sugiyama. Co-teaching: Robust training of deep neural networks with extremely noisy labels.Advances in neural information processing systems, 31, 2018
work page 2018
-
[54]
Mentornet: Learning data-driven curriculum for very deep neural networks on corrupted labels
Lu Jiang, Zhengyuan Zhou, Thomas Leung, Li-Jia Li, and Li Fei-Fei. Mentornet: Learning data-driven curriculum for very deep neural networks on corrupted labels. In International conference on machine learning , pages 2304–2313. PMLR, 2018
work page 2018
-
[55]
Dividemix: Learning with noisy labels as semi-supervised learning
Junnan Li, Richard Socher, and Steven CH Hoi. Dividemix: Learning with noisy labels as semi-supervised learning. arXiv preprint arXiv:2002.07394, 2020
-
[56]
Combating noisy labels by agreement: A joint training method with co-regularization
Hongxin Wei, Lei Feng, Xiangyu Chen, and Bo An. Combating noisy labels by agreement: A joint training method with co-regularization. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 13726–13735, 2020
work page 2020
-
[57]
Mitigating memorization of noisy labels by clipping the model prediction
Hongxin Wei, Huiping Zhuang, Renchunzi Xie, Lei Feng, Gang Niu, Bo An, and Yixuan Li. Mitigating memorization of noisy labels by clipping the model prediction. In International Conference on Machine Learning, pages 36868–36886. PMLR, 2023
work page 2023
-
[58]
Improved cross entropy loss for noisy labels in vision leaf disease classification
Yipeng Chen, Ke Xu, Peng Zhou, Xiaojuan Ban, and Di He. Improved cross entropy loss for noisy labels in vision leaf disease classification. IET Image Processing, 16(6):1511–1519, 2022
work page 2022
-
[59]
Class imbalances versus small disjuncts
Taeho Jo and Nathalie Japkowicz. Class imbalances versus small disjuncts. ACM Sigkdd Explorations Newsletter, 6(1):40–49, 2004
work page 2004
-
[60]
Smote: synthetic minority over-sampling technique
Nitesh V Chawla, Kevin W Bowyer, Lawrence O Hall, and W Philip Kegelmeyer. Smote: synthetic minority over-sampling technique. Journal of artificial intelligence research, 16:321–357, 2002
work page 2002
-
[61]
Borderline-smote: a new over-sampling method in imbalanced data sets learning
Hui Han, Wen-Yuan Wang, and Bing-Huan Mao. Borderline-smote: a new over-sampling method in imbalanced data sets learning. In International conference on intelligent computing, pages 878–887. Springer, 2005
work page 2005
-
[62]
Chumphol Bunkhumpornpat, Krung Sinapiromsaran, and Chidchanok Lursinsap. Safe-level-smote: Safe-level- synthetic minority over-sampling technique for handling the class imbalanced problem. InAdvances in Knowledge Discovery and Data Mining: 13th Pacific-Asia Conference, PAKDD 2009 Bangkok, Thailand, April 27-30, 2009 Proceedings 13, pages 475–482. Springer, 2009
work page 2009
-
[63]
Adasyn: Adaptive synthetic sampling approach for imbalanced learning
Haibo He, Yang Bai, Edwardo A Garcia, and Shutao Li. Adasyn: Adaptive synthetic sampling approach for imbalanced learning. In 2008 IEEE international joint conference on neural networks (IEEE world congress on computational intelligence), pages 1322–1328. Ieee, 2008
work page 2008
-
[64]
knn approach to unbalanced data distributions: a case study involving information extraction
Inderjeet Mani and I Zhang. knn approach to unbalanced data distributions: a case study involving information extraction. In Proceedings of workshop on learning from imbalanced datasets, volume 126, pages 1–7. ICML, 2003. 12 PRIME AI paper
work page 2003
-
[65]
Addressing the curse of imbalanced training sets: one-sided selection
Miroslav Kubat, Stan Matwin, et al. Addressing the curse of imbalanced training sets: one-sided selection. In Icml, volume 97, page 179. Citeseer, 1997
work page 1997
-
[66]
I TOMEK. Two modifications of cnn. IEEE Trans. Systems, Man and Cybernetics, 6:769–772, 1976
work page 1976
-
[67]
The foundations of cost-sensitive learning
Charles Elkan. The foundations of cost-sensitive learning. In International joint conference on artificial intelligence, volume 17, pages 973–978. Lawrence Erlbaum Associates Ltd, 2001
work page 2001
-
[68]
Cost-sensitive learning with neural networks
Matjaz Kukar, Igor Kononenko, et al. Cost-sensitive learning with neural networks. In ECAI, volume 15, pages 88–94. Citeseer, 1998
work page 1998
-
[69]
Training cost-sensitive neural networks with methods addressing the class imbalance problem
Zhi-Hua Zhou and Xu-Ying Liu. Training cost-sensitive neural networks with methods addressing the class imbalance problem. IEEE Transactions on knowledge and data engineering, 18(1):63–77, 2005
work page 2005
-
[70]
Neural network classification and prior class probabilities
Steve Lawrence, Ian Burns, Andrew Back, Ah Chung Tsoi, and C Lee Giles. Neural network classification and prior class probabilities. In Neural networks: tricks of the trade, pages 299–313. Springer, 2002
work page 2002
-
[71]
Neural network classifiers estimate bayesian a posteriori probabilities
Michael D Richard and Richard P Lippmann. Neural network classifiers estimate bayesian a posteriori probabilities. Neural computation, 3(4):461–483, 1991
work page 1991
-
[72]
Distri- butionally robust post-hoc classifiers under prior shifts
Jiaheng Wei, Harikrishna Narasimhan, Ehsan Amid, Wen-Sheng Chu, Yang Liu, and Abhishek Kumar. Distri- butionally robust post-hoc classifiers under prior shifts. In The Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[73]
Focal loss for dense object detection
Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollár. Focal loss for dense object detection. In Proceedings of the IEEE international conference on computer vision, pages 2980–2988, 2017
work page 2017
-
[74]
Learning imbalanced datasets with label-distribution-aware margin loss
Kaidi Cao, Colin Wei, Adrien Gaidon, Nikos Arechiga, and Tengyu Ma. Learning imbalanced datasets with label-distribution-aware margin loss. Advances in neural information processing systems, 32, 2019
work page 2019
-
[75]
Balanced meta-softmax for long-tailed visual recognition
Jiawei Ren, Cunjun Yu, Xiao Ma, Haiyu Zhao, Shuai Yi, et al. Balanced meta-softmax for long-tailed visual recognition. Advances in neural information processing systems, 33:4175–4186, 2020
work page 2020
-
[76]
Aditya Krishna Menon, Sadeep Jayasumana, Ankit Singh Rawat, Himanshu Jain, Andreas Veit, and Sanjiv Kumar. Long-tail learning via logit adjustment. arXiv preprint arXiv:2007.07314, 2020. 13 PRIME AI paper Appendix The appendix is organized as follows: • Appendix A includes additional detailed algorithms in the Automatic-Dataset-Construction pipeline. • Ap...
-
[77]
The hyper-parameters for each baseline method are as follows. For backward and forward correction, we train the model using cross-entropy (CE) loss for the first 10 epochs. We estimate the transition matrix every epoch from the 10th to the 20th epoch. For the positive and negative label smoothing, the smoothed labels are used at the 10th epoch. The smooth...
work page 2097
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.