Use of What-if Scenarios to Help Explain Artificial Intelligence Models for Neonatal Health
Pith reviewed 2026-05-23 18:37 UTC · model grok-4.3
The pith
A neural network predicts high-risk deliveries at 0.784 F1 score and explains predictions through changes to two or three factors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
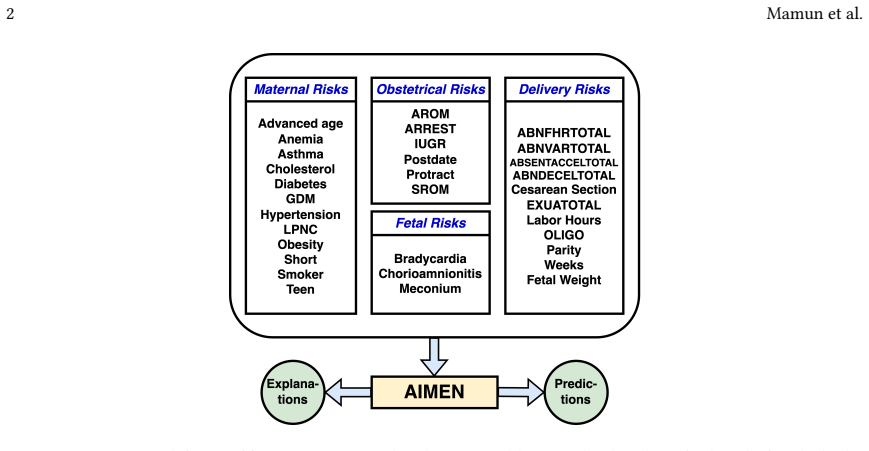
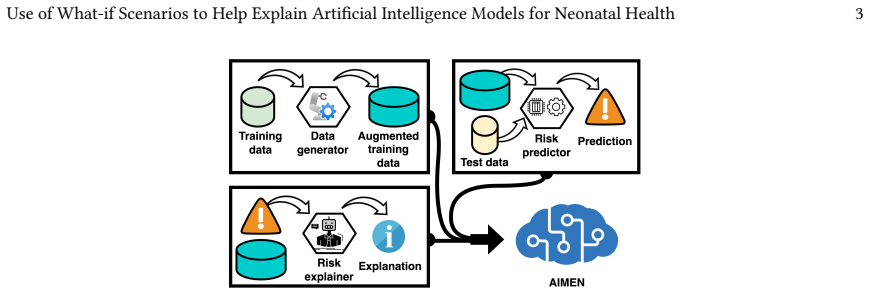
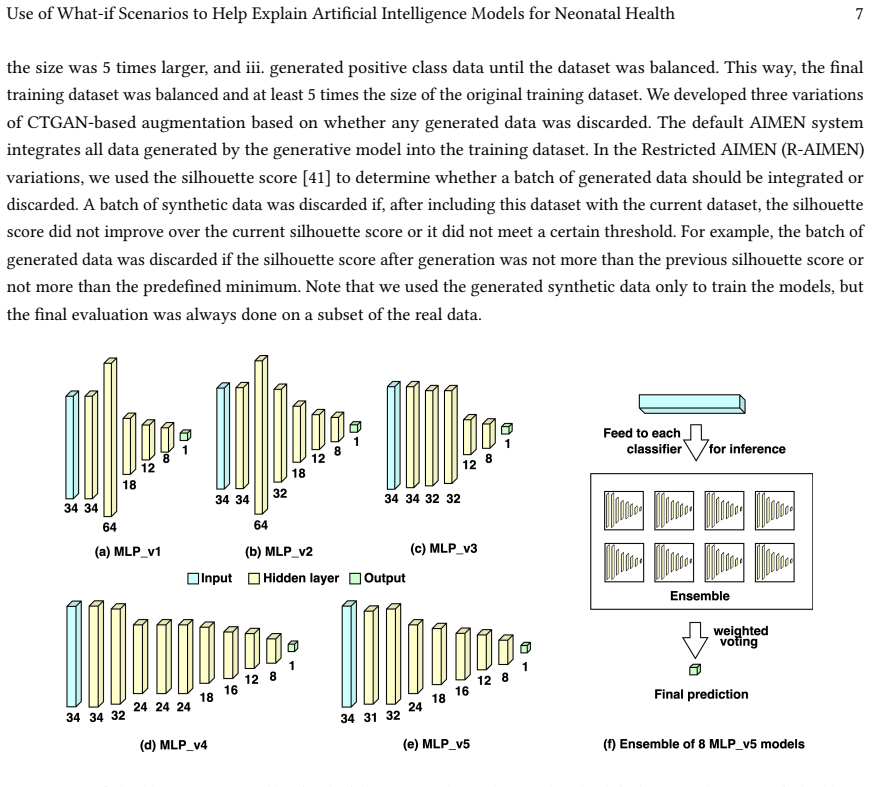
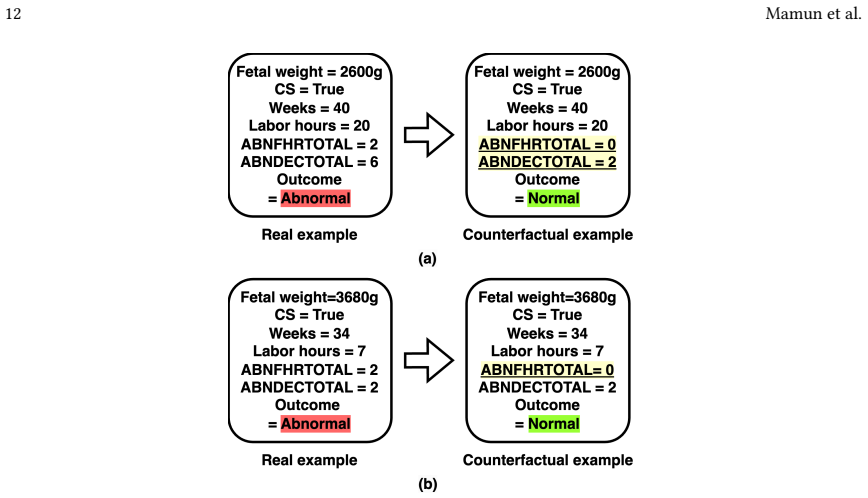
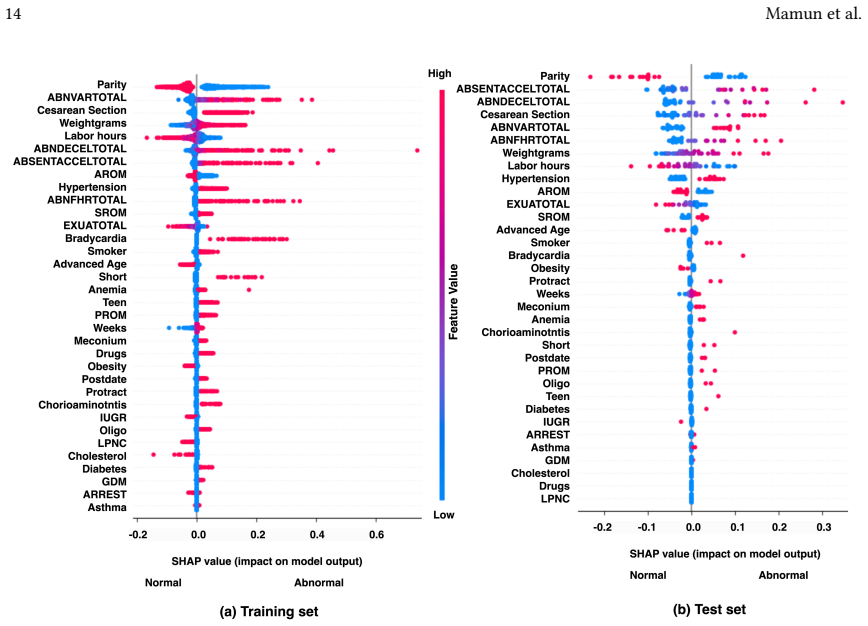
AIMEN is an ensemble of fully connected neural networks trained on real data plus CTGAN-augmented samples that classifies high-risk deliveries more accurately than XGBoost, TabNet, DANet, and LightGBM while generating counterfactual explanations that identify actionable changes to an average of only two to three attributes.
What carries the argument
Counterfactual explanations that search for the smallest set of input-feature modifications sufficient to flip the model's output from high-risk to low-risk.
If this is right
- Higher F1 performance enables earlier detection of intrapartum risks that could prompt timely interventions to reduce adverse outcomes such as cerebral palsy.
- Explanations limited to two or three attributes make the model's reasoning practical for real-time clinical review during delivery.
- CTGAN augmentation with bound relaxation and silhouette filtering mitigates class imbalance and small sample size in neonatal datasets.
- The ensemble architecture supports both accurate classification and the generation of minimal-change counterfactuals.
Where Pith is reading between the lines
- If the suggested attribute changes align with known modifiable risk factors, the explanations could directly inform bedside adjustments to maternal or fetal monitoring.
- The same minimal-change counterfactual technique could be adapted to other medical domains that face class imbalance and require interpretable outputs.
- Prospective deployment across multiple hospitals would test whether the performance and explanation simplicity hold under varying population demographics and recording practices.
Load-bearing premise
The CTGAN synthetic samples, after relaxing feature bounds for some points and applying silhouette-score filtering, faithfully represent the true joint distribution of real clinical variables without introducing artifacts that distort the learned decision boundary or the validity of the resulting counterfactual explanations.
What would settle it
A held-out set of real deliveries where the two-to-three-attribute counterfactuals proposed by AIMEN fail to match observed changes in actual patient outcomes or established clinical guidelines.
Figures

read the original abstract
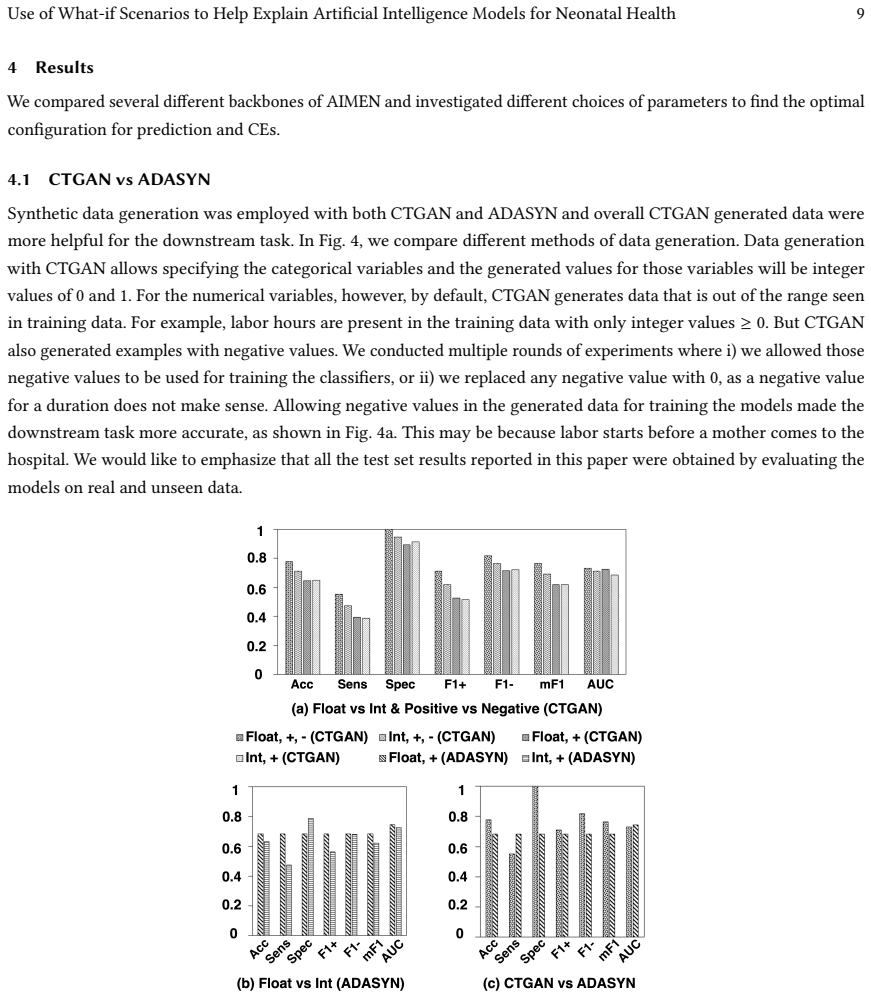
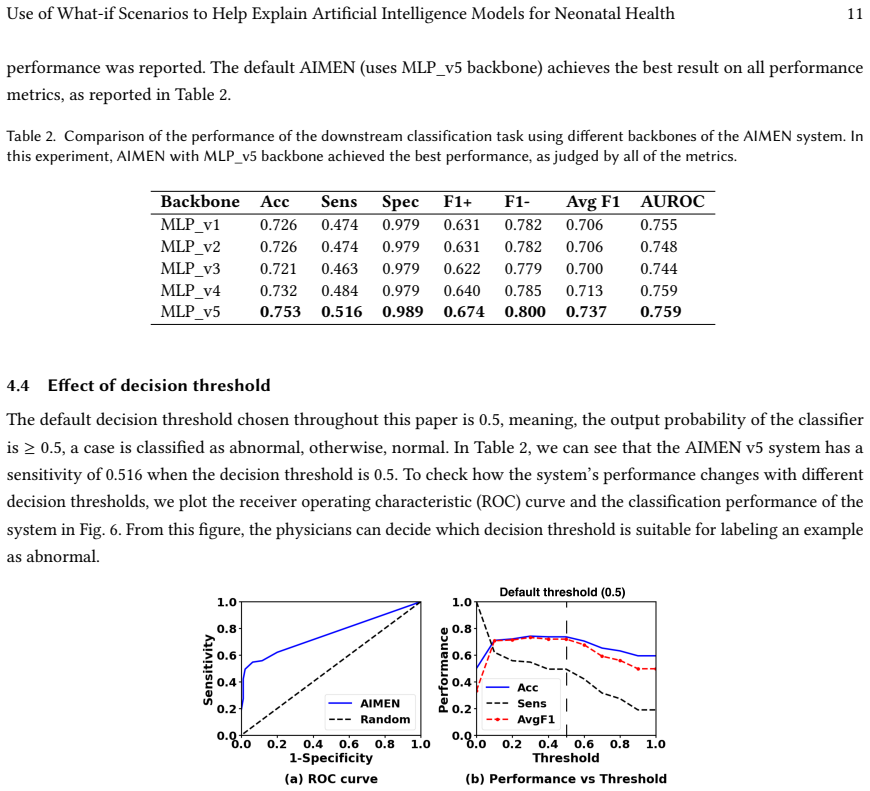
Early detection of intrapartum risks enables timely interventions to prevent or mitigate adverse labor outcomes such as cerebral palsy. However, accurate automated systems to support clinical decision-making during delivery are currently lacking. To address this gap, we propose Artificial Intelligence for Modeling and Explaining Neonatal Health (AIMEN), a deep learning framework that predicts adverse labor outcomes from maternal, fetal, obstetrical, and intrapartum factors while providing interpretable reasoning behind its predictions. AIMEN reveals how specific modifications to input variables could alter predicted outcomes, enhancing clinical insight. To address class imbalance and limited sample size, AIMEN employs Conditional Tabular GAN (CTGAN) for data augmentation. This process includes synthetic data generation, and we investigate in detail properties such as relaxing feature bounds for a subset of training points to explore slightly out-of-range physiological values, and applying silhouette-score-based filtering to increase the separability of synthetic samples. AIMEN uses an ensemble of fully connected neural networks for classification and outperforms state-of-the-art models such as XGBoost, TabNet, DANet, and LightGBM, achieving an average F1 score of 0.784 in predicting high-risk deliveries. Moreover, AIMEN generates counterfactual explanations that identify actionable changes involving only two to three attributes on average. Resources: https://github.com/ab9mamun/AIMEN.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes AIMEN, an ensemble of fully-connected neural networks for predicting high-risk deliveries from maternal/fetal/obstetrical/intrapartum features. It augments limited real data via CTGAN, with bound relaxation on a subset of points and silhouette-score filtering, reports an average F1 of 0.784 that outperforms XGBoost/TabNet/DANet/LightGBM, and supplies counterfactual explanations that on average modify only two-to-three attributes.
Significance. If the CTGAN-augmented distribution faithfully matches the real clinical joint statistics, the work would supply a practically useful predictor together with sparse, actionable explanations for intrapartum risk. The absence of any reported fidelity diagnostics for the synthetic data, however, leaves both the performance gain and the validity of the counterfactuals unverified on true patient distributions.
major comments (3)
- [Abstract] Abstract: the headline claim that AIMEN 'outperforms state-of-the-art models … achieving an average F1 score of 0.784' supplies no information on dataset size, class balance, cross-validation scheme, or statistical significance testing, rendering the central empirical result impossible to evaluate.
- [Abstract] Abstract (CTGAN paragraph): the augmentation pipeline (CTGAN generation, feature-bound relaxation, silhouette-score filtering) is presented as essential to both the reported F1 gain and the counterfactuals, yet no marginal/conditional distribution checks, correlation preservation metrics, or real-only ablation results are supplied to confirm that the filtered synthetics do not distort decision boundaries or introduce separability artifacts.
- [Abstract] Abstract: the claim that counterfactuals 'identify actionable changes involving only two to three attributes on average' rests on the same unvalidated augmented distribution; without fidelity evidence the sparsity and actionability of the explanations cannot be trusted on real clinical data.
minor comments (1)
- The GitHub link is supplied but the manuscript does not state whether the released code includes the exact CTGAN hyperparameters, silhouette threshold, and bound-relaxation fraction used for the reported results.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and the validation of the CTGAN augmentation. We address each major comment below and will revise the manuscript to incorporate the requested details and analyses.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim that AIMEN 'outperforms state-of-the-art models … achieving an average F1 score of 0.784' supplies no information on dataset size, class balance, cross-validation scheme, or statistical significance testing, rendering the central empirical result impossible to evaluate.
Authors: We agree that the abstract should provide sufficient context. In the revised version we will expand the abstract to report the original dataset size, class balance (imbalance ratio), the cross-validation scheme (stratified k-fold), and results of statistical significance testing against the baselines. These details already appear in the methods and results sections of the full manuscript. revision: yes
-
Referee: [Abstract] Abstract (CTGAN paragraph): the augmentation pipeline (CTGAN generation, feature-bound relaxation, silhouette-score filtering) is presented as essential to both the reported F1 gain and the counterfactuals, yet no marginal/conditional distribution checks, correlation preservation metrics, or real-only ablation results are supplied to confirm that the filtered synthetics do not distort decision boundaries or introduce separability artifacts.
Authors: This point is correct; the current manuscript does not report explicit fidelity diagnostics. We will add marginal and conditional distribution comparisons, correlation preservation metrics, and a real-data-only ablation study in the revision to demonstrate that the filtered synthetic samples do not introduce decision-boundary artifacts. revision: yes
-
Referee: [Abstract] Abstract: the claim that counterfactuals 'identify actionable changes involving only two to three attributes on average' rests on the same unvalidated augmented distribution; without fidelity evidence the sparsity and actionability of the explanations cannot be trusted on real clinical data.
Authors: We acknowledge that the counterfactual sparsity claim depends on the fidelity of the augmented distribution. The revision will include the fidelity checks noted above and, where feasible, evaluate counterfactual sparsity on held-out real samples or clearly articulate the associated assumptions and limitations in the discussion. revision: yes
Circularity Check
No circularity; performance and explanations are empirical outputs of standard supervised training
full rationale
The paper describes training an ensemble of fully connected neural networks on data augmented by CTGAN (with bound relaxation and silhouette filtering) to address imbalance, then reports F1=0.784 and 2-3 attribute counterfactuals as direct results of that training. No step equates a fitted parameter to a prediction by construction, renames a known result, or reduces the central claim to a self-citation chain or self-definition. The augmentation is presented as preprocessing whose validity is assumed rather than enforced by the reported metrics themselves. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (4)
- CTGAN training hyperparameters
- Silhouette-score filtering threshold
- Feature-bound relaxation fraction
- Ensemble architecture and training hyperparameters
axioms (2)
- domain assumption The original clinical dataset is representative of the population on which the model will be deployed.
- domain assumption Counterfactual changes identified by the model correspond to clinically feasible and causally relevant interventions.
Forward citations
Cited by 1 Pith paper
-
GlyTwin: Digital Twin for Glucose Control in Type 1 Diabetes Through Optimal Behavioral Modifications Using Patient-Centric Counterfactuals
GlyTwin generates patient-centric counterfactual behavioral interventions to reduce hyperglycemia in type 1 diabetes, evaluated on a new dataset from 50 patients showing 85.8% valid explanations and 87.3% effectiveness.
Reference graph
Works this paper leans on
-
[1]
Ki Hoon Ahn and Kwang-Sig Lee. 2022. Artificial intelligence in obstetrics. Obstetrics & Gynecology Science 65, 2 (2022), 113–124
work page 2022
-
[2]
Virginia Apgar. 1953. A proposal for a new method of evaluation of the newborn infant. Anesthesia & Analgesia 32, 4 (1953), 260–267
work page 1953
-
[3]
Asiful Arefeen and Hassan Ghasemzadeh. 2023. Glysim: Modeling and simulating glycemic response for behavioral lifestyle interventions. In 2023 IEEE EMBS International Conference on Biomedical and Health Informatics (BHI). IEEE, 1–5
work page 2023
-
[4]
Sercan Ö Arik and Tomas Pfister. 2021. Tabnet: Attentive interpretable tabular learning. In Proceedings of the AAAI conference on artificial intelligence, Vol. 35. 6679–6687
work page 2021
-
[5]
Reza Rahimi Azghan, Nicholas C Glodosky, Ramesh Kumar Sah, Carrie Cuttler, Ryan McLaughlin, Michael J Cleveland, and Hassan Ghasemzadeh
-
[6]
In 2023 IEEE 19th International Conference on Body Sensor Networks (BSN)
Personalized Modeling and Detection of Moments of Cannabis Use in Free-Living Environments. In 2023 IEEE 19th International Conference on Body Sensor Networks (BSN). IEEE, 1–4
work page 2023
-
[7]
Gregor Bachmann, Sotiris Anagnostidis, and Thomas Hofmann. 2024. Scaling mlps: A tale of inductive bias. Advances in Neural Information Processing Systems 36 (2024)
work page 2024
-
[8]
Jacques Balayla and Guy Shrem. 2019. Use of artificial intelligence (AI) in the interpretation of intrapartum fetal heart rate (FHR) tracings: a systematic review and meta-analysis. Archives of gynecology and obstetrics 300 (2019), 7–14
work page 2019
-
[9]
Andrew P Bradley. 1997. The use of the area under the ROC curve in the evaluation of machine learning algorithms. Pattern recognition 30, 7 (1997), 1145–1159
work page 1997
-
[10]
Dieter Brughmans, Pieter Leyman, and David Martens. 2023. Nice: an algorithm for nearest instance counterfactual explanations. Data Mining and Knowledge Discovery (2023), 1–39
work page 2023
-
[11]
Tianqi Chen and Carlos Guestrin. 2016. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining. 785–794
work page 2016
-
[12]
Lena Davidson and Mary Regina Boland. 2021. Towards deep phenotyping pregnancy: a systematic review on artificial intelligence and machine learning methods to improve pregnancy outcomes. Briefings in Bioinformatics 22, 5 (2021), bbaa369
work page 2021
-
[13]
Lawrence Devoe, Steven Golde, Yevgeny Kilman, Debra Morton, Kimberly Shea, and Jennifer Waller. 2000. A comparison of visual analyses of intrapartum fetal heart rate tracings according to the new national institute of child health and human development guidelines with computer 16 Mamun et al. analyses by an automated fetal heart rate monitoring system. Am...
work page 2000
-
[14]
Lawrence D Devoe. 2016. Future perspectives in intrapartum fetal surveillance. Best Practice & Research Clinical Obstetrics & Gynaecology 30 (2016), 98–106
work page 2016
-
[15]
Finale Doshi-Velez and Been Kim. 2017. Towards a rigorous science of interpretable machine learning. arXiv preprint arXiv:1702.08608 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[16]
Mark I Evans, David W Britt, Shara M Evans, and Lawrence D Devoe. 2021. Changing perspectives of electronic fetal monitoring. Reproductive Sciences (2021), 1–21
work page 2021
-
[17]
Joshua Guedalia, Michal Lipschuetz, Michal Novoselsky-Persky, Sarah M Cohen, Amihai Rottenstreich, Gabriel Levin, Simcha Yagel, Ron Unger, and Yishai Sompolinsky. 2020. Real-time data analysis using a machine learning model significantly improves prediction of successful vaginal deliveries. American Journal of Obstetrics and Gynecology 223, 3 (2020), 437–e1
work page 2020
-
[18]
J Guedalia, Y Sompolinsky, M Novoselsky Persky, SM Cohen, D Kabiri, S Yagel, R Unger, and M Lipschuetz. 2021. Prediction of severe adverse neonatal outcomes at the second stage of labour using machine learning: a retrospective cohort study.BJOG: An International Journal of Obstetrics & Gynaecology 128, 11 (2021), 1824–1832
work page 2021
-
[19]
Haibo He, Yang Bai, Edwardo A Garcia, and Shutao Li. 2008. ADASYN: Adaptive synthetic sampling approach for imbalanced learning. In 2008 IEEE international joint conference on neural networks (IEEE world congress on computational intelligence). Ieee, 1322–1328
work page 2008
-
[20]
Niloofar Hezarjaribi, Sepideh Mazrouee, and Hassan Ghasemzadeh. 2017. Speech2Health: a mobile framework for monitoring dietary composition from spoken data. IEEE journal of biomedical and health informatics 22, 1 (2017), 252–264
work page 2017
-
[21]
Cornelius A James, Robert M Wachter, and James O Woolliscroft. 2022. Preparing clinicians for a clinical world influenced by artificial intelligence. Jama 327, 14 (2022), 1333–1334
work page 2022
-
[22]
Robert DF Keith, Sarah Beckley, Jonathan M Garibaldi, Jenny A Westgate, Emmanuel C Ifeachor, and Keith R Greene. 1995. A multicentre comparative study of 17 experts and an intelligent computer system for managing labour using the cardiotocogram. BJOG: an international journal of obstetrics & gynaecology 102, 9 (1995), 688–700
work page 1995
-
[23]
So Ling Lau, Zara Lin Zau Lok, Shuk Yi Annie Hui, Genevieve Po Gee Fung, Hugh Simon Lam, and Tak Yeung Leung. 2023. Neonatal outcome of infants with umbilical cord arterial pH less than 7. Acta Obstetricia et Gynecologica Scandinavica 102, 2 (2023), 174–180
work page 2023
-
[24]
Hanxiao Liu, Zihang Dai, David So, and Quoc V Le. 2021. Pay attention to mlps. Advances in neural information processing systems 34 (2021), 9204–9215
work page 2021
-
[25]
Scott M Lundberg and Su-In Lee. 2017. A unified approach to interpreting model predictions. Advances in neural information processing systems 30 (2017)
work page 2017
-
[26]
Yuanfei Luo, Hao Zhou, Wei-Wei Tu, Yuqiang Chen, Wenyuan Dai, and Qiang Yang. 2020. Network on network for tabular data classification in real-world applications. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval. 2317–2326
work page 2020
-
[27]
Abdullah Mamun, Chia-Cheng Kuo, David W. Britt, Lawrence D. Devoe, Mark I. Evans, Hassan Ghasemzadeh, and Judith Klein-Seetharaman. 2023. Neonatal Risk Modeling and Prediction. In 2023 IEEE 19th International Conference on Body Sensor Networks (BSN). 1–4. https://doi.org/10.1109/ BSN58485.2023.10331196
-
[28]
Abdullah Mamun, Krista S Leonard, Matthew P Buman, and Hassan Ghasemzadeh. 2022. Multimodal Time-Series Activity Forecasting for Adaptive Lifestyle Intervention Design. In2022 IEEE-EMBS International Conference on Wearable and Implantable Body Sensor Networks (BSN). IEEE, 1–4
work page 2022
-
[29]
Abdullah Mamun, Seyed Iman Mirzadeh, and Hassan Ghasemzadeh. 2022. Designing deep neural networks robust to sensor failure in mobile health environments. In 2022 44th Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC). IEEE, 2442–2446
work page 2022
-
[30]
Abimbola Michael-Asalu, Genevieve Taylor, Heather Campbell, Latashia-Lika Lelea, and Russell S Kirby. 2019. Cerebral palsy: diagnosis, epidemiology, genetics, and clinical update. Advances in pediatrics 66 (2019), 189–208
work page 2019
-
[31]
Christoph Molnar. 2020. Interpretable machine learning. Lulu. com
work page 2020
-
[32]
Ramaravind K Mothilal, Amit Sharma, and Chenhao Tan. 2020. Explaining machine learning classifiers through diverse counterfactual explanations. In Proceedings of the 2020 conference on fairness, accountability, and transparency. 607–617
work page 2020
-
[33]
Khushboo Munir, Hassan Elahi, Afsheen Ayub, Fabrizio Frezza, and Antonello Rizzi. 2019. Cancer diagnosis using deep learning: a bibliographic review. Cancers 11, 9 (2019), 1235
work page 2019
-
[34]
Jun Ogasawara, Satoru Ikenoue, Hiroko Yamamoto, Motoshige Sato, Yoshifumi Kasuga, Yasue Mitsukura, Yuji Ikegaya, Masato Yasui, Mamoru Tanaka, and Daigo Ochiai. 2021. Deep neural network-based classification of cardiotocograms outperformed conventional algorithms. Scientific reports 11, 1 (2021), 13367
work page 2021
-
[35]
Deborah Plana, Dennis L Shung, Alyssa A Grimshaw, Anurag Saraf, Joseph JY Sung, and Benjamin H Kann. 2022. Randomized clinical trials of machine learning interventions in health care: a systematic review. JAMA Network Open 5, 9 (2022), e2233946–e2233946
work page 2022
-
[36]
Ninlapa Pruksanusak, Natthicha Chainarong, Siriwan Boripan, and Alan Geater. 2022. Comparison of the predictive ability for perinatal acidemia in neonates between the NICHD 3-tier FHR system combined with clinical risk factors and the fetal reserve index. Plos one 17, 10 (2022), e0276451
work page 2022
-
[37]
Ishraq R Rahman, Shovito Barua Soumma, and Faisal Bin Ashraf. 2022. Machine learning approaches to metastasis bladder and secondary pulmonary cancer classification using gene expression data. In 2022 25th International Conference on Computer and Information Technology (ICCIT). IEEE, 430–435
work page 2022
-
[38]
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. 2015. U-net: Convolutional networks for biomedical image segmentation. In Medical image computing and computer-assisted intervention–MICCAI 2015: 18th international conference, Munich, Germany, October 5-9, 2015, proceedings, Use of What-if Scenarios to Help Explain Artificial Intelligence Models for Neo...
work page 2015
-
[39]
Ramyar Saeedi, Brian Schimert, and Hassan Ghasemzadeh. 2014. Cost-sensitive feature selection for on-body sensor localization. In Proceedings of the 2014 ACM International Joint Conference on Pervasive and Ubiquitous Computing: Adjunct Publication. 833–842
work page 2014
-
[40]
Laura Sarno, Daniele Neola, Luigi Carbone, Gabriele Saccone, Annunziata Carlea, Marco Miceli, Giuseppe Gabriele Iorio, Ilenia Mappa, Giuseppe Rizzo, Raffaella Di Girolamo, et al. 2023. Use of artificial intelligence in obstetrics: not quite ready for prime time. American Journal of Obstetrics & Gynecology MFM 5, 2 (2023), 100792
work page 2023
-
[41]
Thomas P Sartwelle and James C Johnston. 2018. Continuous electronic fetal monitoring during labor: a critique and a reply to contemporary proponents. The Surgery Journal 4, 01 (2018), e23–e28
work page 2018
-
[42]
Ketan Rajshekhar Shahapure and Charles Nicholas. 2020. Cluster quality analysis using silhouette score. In 2020 IEEE 7th international conference on data science and advanced analytics (DSAA). IEEE, 747–748
work page 2020
-
[43]
Sherif A Shazly, Bijan J Borah, Che G Ngufor, Vanessa E Torbenson, Regan N Theiler, and Abimbola O Famuyide. 2022. Impact of labor characteristics on maternal and neonatal outcomes of labor: A machine-learning model. Plos one 17, 8 (2022), e0273178
work page 2022
-
[44]
Edoardo Spairani, Beniamino Daniele, Maria Gabriella Signorini, and Giovanni Magenes. 2022. A deep learning mixed-data type approach for the classification of FHR signals. Frontiers in Bioengineering and Biotechnology 10 (2022)
work page 2022
-
[45]
Max Wiznitzer. 2017. Electronic fetal monitoring: are we asking the correct questions? , 344–345 pages
work page 2017
-
[46]
Lei Xu, Maria Skoularidou, Alfredo Cuesta-Infante, and Kalyan Veeramachaneni. 2019. Modeling tabular data using conditional gan. Advances in neural information processing systems 32 (2019)
work page 2019
-
[47]
Ming Zeng, Le T Nguyen, Bo Yu, Ole J Mengshoel, Jiang Zhu, Pang Wu, and Joy Zhang. 2014. Convolutional neural networks for human activity recognition using mobile sensors. In 6th international conference on mobile computing, applications and services. IEEE, 197–205
work page 2014
-
[48]
Jun Zhang, Helain J Landy, D Ware Branch, Ronald Burkman, Shoshana Haberman, Kimberly D Gregory, Christos G Hatjis, Mildred M Ramirez, Jennifer L Bailit, Victor H Gonzalez-Quintero, et al. 2010. Contemporary patterns of spontaneous labor with normal neonatal outcomes. Obstetrics and gynecology 116, 6 (2010), 1281
work page 2010
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.