Direct Preference Optimization for Primitive-Enabled Hierarchical RL: A Bilevel Approach
Pith reviewed 2026-05-23 18:27 UTC · model grok-4.3
The pith
DIPPER applies direct preference optimization to higher-level policies in a bilevel formulation of hierarchical reinforcement learning to overcome non-stationarity and infeasible subgoals.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DIPPER formulates goal-conditioned hierarchical reinforcement learning as a bi-level optimization problem where the higher-level policy is trained using direct preference optimization on stationary preference comparisons over subgoal sequences rather than non-stationary rewards, combined with lower-level value function regularization to promote achievable subgoals, resulting in improved performance on robotic navigation and manipulation tasks.
What carries the argument
Bilevel optimization formulation of goal-conditioned HRL that trains the higher-level policy via direct preference optimization on stationary subgoal-sequence preferences, augmented by lower-level value function regularization.
If this is right
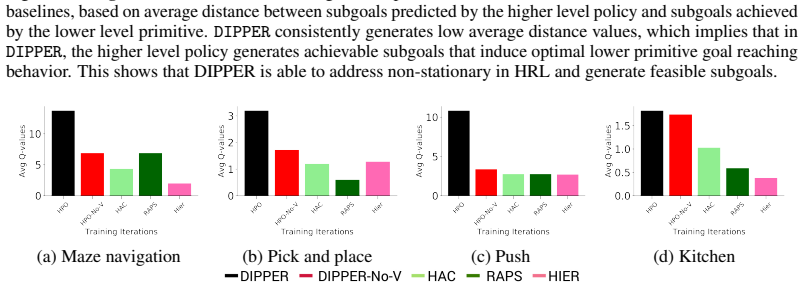
- Stationary preference comparisons allow higher-level learning to proceed independently of lower-level policy changes.
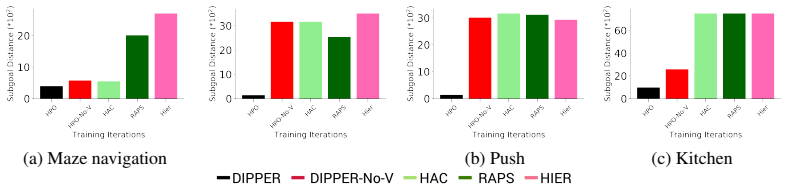
- Lower-level value function regularization reduces generation of infeasible subgoals by the higher level.
- Two new quantitative metrics can verify mitigation of non-stationarity and infeasible subgoal problems.
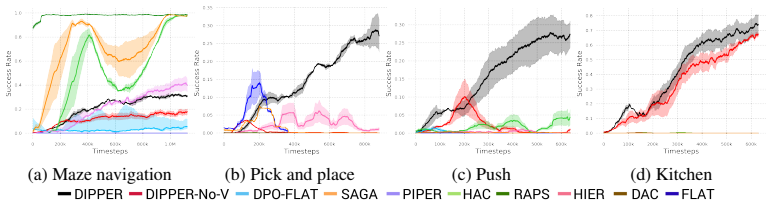
- Empirical gains reach up to 40 percent over prior baselines on robotic navigation and manipulation benchmarks.
Where Pith is reading between the lines
- The bilevel DPO structure may transfer to other settings where one policy level adapts faster than another, such as options frameworks with changing primitives.
- Collecting the required preference labels over subgoal sequences will determine practical cost, since the method assumes such comparisons are easier to obtain than stationary rewards.
- If value regularization reliably signals feasibility, it opens a route to replace hand-crafted subgoal constraints with learned value estimates in other hierarchical methods.
Load-bearing premise
Preference comparisons over subgoal sequences remain stationary and independent of lower-level policy evolution, and lower-level value regularization alone suffices to keep proposed subgoals feasible without new instabilities.
What would settle it
Training curves in which higher-level policy updates continue to track lower-level policy changes despite the use of preferences, or in which the two new metrics show no reduction in non-stationarity or infeasible subgoals when the value regularization term is ablated.
Figures







read the original abstract
Hierarchical reinforcement learning (HRL) enables agents to solve complex, long-horizon tasks by decomposing them into manageable sub-tasks. However, HRL methods face two fundamental challenges: (i) non-stationarity caused by the evolving lower-level policy during training, which destabilizes higher-level learning, and (ii) the generation of infeasible subgoals that lower-level policies cannot achieve. To address these challenges, we introduce DIPPER, a novel HRL framework that formulates goal-conditioned HRL as a bi-level optimization problem and leverages direct preference optimization (DPO) to train the higher-level policy. By learning from stationary preference comparisons over subgoal sequences rather than rewards that depend on the evolving lower-level policy, DIPPER mitigates the impact of non-stationarity on hierarchical learning. To address infeasible subgoals, DIPPER incorporates lower-level value function regularization that encourages the higher-level policy to propose achievable subgoals. We also introduce two novel metrics to quantitatively verify that DIPPER mitigates non-stationarity and infeasible subgoal generation issues in HRL. We perform empirical evaluations on challenging robotic navigation and manipulation benchmarks and show that DIPPER achieves upto 40% improvements over state-of-the-art baselines, demonstrating that preference-based methods can effectively alleviate persistent challenges in hierarchical
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DIPPER, a bi-level optimization framework for goal-conditioned hierarchical RL that applies direct preference optimization (DPO) to the higher-level policy using preference comparisons over subgoal sequences. This is intended to mitigate non-stationarity arising from concurrent lower-level policy updates, while lower-level value function regularization encourages feasible subgoals. The work introduces two new metrics to quantify mitigation of non-stationarity and infeasible subgoal issues, and reports empirical gains of up to 40% over baselines on robotic navigation and manipulation benchmarks.
Significance. If the stationarity of the preference dataset and the effectiveness of the regularization can be rigorously established, the approach would offer a practical way to stabilize higher-level learning in HRL without relying on non-stationary rewards. The empirical evaluation on standard robotic benchmarks provides concrete evidence of improvement, and the introduction of quantitative metrics for the two core HRL challenges is a useful contribution for future comparisons. The work applies an existing preference optimization technique to a standard bi-level HRL skeleton rather than deriving new theoretical primitives.
major comments (2)
- [Abstract, §3] Abstract and §3 (bi-level formulation): The central claim that 'preference comparisons over subgoal sequences' are stationary and independent of lower-level policy evolution is load-bearing for the non-stationarity mitigation argument. However, generating such preferences requires evaluating whether a subgoal sequence leads to task success, which depends on the lower-level policy's success rate for individual subgoals. If the lower-level policy is updated concurrently (standard in HRL), these success rates change, so the preference labels are not guaranteed to remain stationary. The lower-level value regularization addresses feasibility but does not decouple the labels from lower-level dynamics; a concrete description of the preference dataset construction and whether it is held fixed or regenerated is required to verify the claim.
- [§4] §4 (empirical evaluation): The reported 'up to 40% improvements' and the two new metrics for non-stationarity and infeasibility are central to the contribution, yet the abstract and available description supply no error bars, statistical tests, or details on how the metrics are computed from the learned policies. Without these, it is impossible to assess whether the gains are robust or whether the metrics actually isolate the claimed effects versus other factors such as hyperparameter tuning.
minor comments (2)
- [Abstract] The abstract sentence is truncated at 'hierarchical'; this should be completed in the final version.
- [§3] Notation for the bi-level objective and the DPO loss applied to the higher-level policy should be introduced with explicit equations early in §3 to allow readers to trace how the preference loss replaces the usual non-stationary reward signal.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point-by-point below. Both points identify areas where additional detail will strengthen the manuscript, and we will revise accordingly.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (bi-level formulation): The central claim that 'preference comparisons over subgoal sequences' are stationary and independent of lower-level policy evolution is load-bearing for the non-stationarity mitigation argument. However, generating such preferences requires evaluating whether a subgoal sequence leads to task success, which depends on the lower-level policy's success rate for individual subgoals. If the lower-level policy is updated concurrently (standard in HRL), these success rates change, so the preference labels are not guaranteed to remain stationary. The lower-level value regularization addresses feasibility but does not decouple the labels from lower-level dynamics; a concrete description of the preference dataset construction and whether it is held fixed or regenerated is required to verify the claim.
Authors: We agree that a precise account of dataset construction is necessary to substantiate the stationarity claim. In DIPPER the preference dataset is generated once, offline, by rolling out subgoal sequences with a fixed snapshot of the lower-level policy and labeling each sequence according to whether it produces task success under that snapshot; the resulting preference pairs are then held fixed for the entire higher-level DPO phase. Because the labels are never regenerated during concurrent lower-level updates, the preference comparisons remain stationary by construction. The value-function regularization operates only on the higher-level objective and does not alter the fixed labels. We will add an explicit subsection in §3 (with pseudocode) describing this offline collection and freezing procedure. revision: yes
-
Referee: [§4] §4 (empirical evaluation): The reported 'up to 40% improvements' and the two new metrics for non-stationarity and infeasibility are central to the contribution, yet the abstract and available description supply no error bars, statistical tests, or details on how the metrics are computed from the learned policies. Without these, it is impossible to assess whether the gains are robust or whether the metrics actually isolate the claimed effects versus other factors such as hyperparameter tuning.
Authors: We concur that error bars, statistical tests, and explicit metric definitions are required for rigorous assessment. In the revised §4 we will report means and standard errors over at least five independent random seeds, include paired t-test p-values for the performance deltas, and provide the exact formulas used to compute the non-stationarity and infeasibility metrics from policy rollouts (including the precise window sizes and success thresholds employed). These additions will allow readers to evaluate both robustness and the metrics' specificity. revision: yes
Circularity Check
No circularity: standard application of DPO inside bi-level HRL with external stationarity assumption
full rationale
The provided abstract and reader summary describe DIPPER as a bi-level formulation that applies existing DPO (imported from prior non-self work) to preference comparisons over subgoal sequences, plus lower-level value regularization. No equations, derivations, or self-citations are quoted that reduce a claimed prediction or uniqueness result to a fitted input or prior self-result by construction. The stationarity claim is presented as an assumption rather than derived from the method itself, and no load-bearing step renames a fit as a prediction or smuggles an ansatz via self-citation. The central claims therefore remain independent of the paper's own fitted quantities.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Preference comparisons over subgoal sequences remain stationary and independent of the evolving lower-level policy
Forward citations
Cited by 1 Pith paper
-
HiPO: Hierarchical Preference Optimization for Adaptive Reasoning in LLMs
HiPO improves LLM reasoning performance by optimizing preferences separately on response segments rather than entire outputs.
Reference graph
Works this paper leans on
-
[1]
Marcin Andrychowicz, Filip Wolski, Alex Ray, Jonas Schneider, Rachel Fong, Peter Welinder, Bob McGrew, Josh Tobin, Pieter Abbeel, and Wojciech Zaremba. Hindsight experience replay. CoRR, abs/1707.01495, 2017. URL http://arxiv.org/abs/1707.01495
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[2]
Andrew G. Barto and Sridhar Mahadevan. Recent advances in hierarchical reinforcement learning. Discrete Event Dynamic Systems, 13:341–379, 2003. 10
work page 2003
-
[3]
Ralph Allan Bradley and Milton E. Terry. Rank analysis of incomplete block designs: I. the method of paired comparisons. Biometrika, 39:324, 1952. URL https://api. semanticscholar.org/CorpusID:125209808
work page 1952
-
[4]
Human preference scaling with demonstrations for deep reinforcement learning
Zehong Cao, Kaichiu Wong, and Chin-Teng Lin. Human preference scaling with demonstrations for deep reinforcement learning. arXiv preprint arXiv:2007.12904, 2020
-
[5]
Goal-conditioned reinforcement learning with imagined subgoals
Elliot Chane-Sane, Cordelia Schmid, and Ivan Laptev. Goal-conditioned reinforcement learning with imagined subgoals. In International Conference on Machine Learning, pages 1430–1440. PMLR, 2021
work page 2021
-
[6]
Deep reinforcement learning from human preferences
Paul F Christiano, Jan Leike, Tom Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep reinforcement learning from human preferences. Advances in neural information processing systems, 30, 2017
work page 2017
-
[7]
Accelerating robotic reinforcement learning via parameterized action primitives
Murtaza Dalal, Deepak Pathak, and Russ R Salakhutdinov. Accelerating robotic reinforcement learning via parameterized action primitives. Advances in Neural Information Processing Systems, 34:21847–21859, 2021
work page 2021
-
[8]
Active reward learning with a novel acquisition function
Christian Daniel, Oliver Kroemer, Malte Viering, Jan Metz, and Jan Peters. Active reward learning with a novel acquisition function. Autonomous Robots, 39:389–405, 2015
work page 2015
-
[9]
Peter Dayan and Geoffrey E Hinton. Feudal reinforcement learning. Advances in neural information processing systems, 5, 1992
work page 1992
-
[10]
Thomas G. Dietterich. Hierarchical reinforcement learning with the MAXQ value function decomposition. CoRR, cs.LG/9905014, 1999. URL https://arxiv.org/abs/cs/9905014
-
[11]
Iq-learn: Inverse soft-q learning for imitation
Divyansh Garg, Shuvam Chakraborty, Chris Cundy, Jiaming Song, and Stefano Ermon. Iq-learn: Inverse soft-q learning for imitation. Advances in Neural Information Processing Systems, 34: 4028–4039, 2021
work page 2021
-
[12]
Relay policy learning: Solving long-horizon tasks via imitation and reinforcement learning
Abhishek Gupta, Vikash Kumar, Corey Lynch, Sergey Levine, and Karol Hausman. Relay policy learning: Solving long-horizon tasks via imitation and reinforcement learning. arXiv preprint arXiv:1910.11956, 2019
-
[14]
URL http://arxiv.org/abs/1801.01290
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
When waiting is not an option: Learning options with a deliberation cost
Jean Harb, Pierre-Luc Bacon, Martin Klissarov, and Doina Precup. When waiting is not an option: Learning options with a deliberation cost. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 32, 2018
work page 2018
-
[16]
Contrastive prefence learning: Learning from human feedback without rl
Joey Hejna, Rafael Rafailov, Harshit Sikchi, Chelsea Finn, Scott Niekum, W Bradley Knox, and Dorsa Sadigh. Contrastive prefence learning: Learning from human feedback without rl. arXiv preprint arXiv:2310.13639, 2023
-
[17]
Reward learning from human preferences and demonstrations in atari, 2018
Borja Ibarz, Jan Leike, Tobias Pohlen, Geoffrey Irving, Shane Legg, and Dario Amodei. Reward learning from human preferences and demonstrations in atari, 2018
work page 2018
-
[18]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[19]
Interactively shaping agents via human reinforcement: The tamer framework
W Bradley Knox and Peter Stone. Interactively shaping agents via human reinforcement: The tamer framework. In Proceedings of the fifth international conference on Knowledge capture, pages 9–16, 2009
work page 2009
-
[20]
Ilya Kostrikov, Kumar Krishna Agrawal, Debidatta Dwibedi, Sergey Levine, and Jonathan Tompson. Discriminator-actor-critic: Addressing sample inefficiency and reward bias in adversarial imitation learning. arXiv preprint arXiv:1809.02925, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[21]
Kimin Lee, Laura Smith, and Pieter Abbeel. Pebble: Feedback-efficient interactive reinforce- ment learning via relabeling experience and unsupervised pre-training, 2021. 11
work page 2021
-
[22]
Reinforcement Learning and Control as Probabilistic Inference: Tutorial and Review
Sergey Levine. Reinforcement learning and control as probabilistic inference: Tutorial and review. arXiv preprint arXiv:1805.00909, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[23]
Learning multi-level hierar- chies with hindsight
Andrew Levy, George Konidaris, Robert Platt, and Kate Saenko. Learning multi-level hierar- chies with hindsight. In International Conference on Learning Representations, 2018
work page 2018
-
[24]
Bome! bilevel optimization made easy: A simple first-order approach
Bo Liu, Mao Ye, Stephen Wright, Peter Stone, and Qiang Liu. Bome! bilevel optimization made easy: A simple first-order approach. Advances in neural information processing systems, 35:17248–17262, 2022
work page 2022
-
[25]
Data-efficient hierarchical reinforcement learning
Ofir Nachum, Shixiang Shane Gu, Honglak Lee, and Sergey Levine. Data-efficient hierarchical reinforcement learning. Advances in neural information processing systems, 31, 2018
work page 2018
-
[26]
Ofir Nachum, Haoran Tang, Xingyu Lu, Shixiang Gu, Honglak Lee, and Sergey Levine. Why does hierarchy (sometimes) work so well in reinforcement learning? arXiv preprint arXiv:1909.10618, 2019
-
[27]
Augmenting reinforcement learning with behavior primitives for diverse manipulation tasks
Soroush Nasiriany, Huihan Liu, and Yuke Zhu. Augmenting reinforcement learning with behavior primitives for diverse manipulation tasks. CoRR, abs/2110.03655, 2021. URL https://arxiv.org/abs/2110.03655
-
[28]
Reinforcement learning with hierarchies of machines
Ronald Parr and Stuart Russell. Reinforcement learning with hierarchies of machines. In M. Jordan, M. Kearns, and S. Solla, editors, Advances in Neural Information Processing Systems, volume 10. MIT Press, 1998
work page 1998
-
[29]
Online human training of a myoelectric prosthesis controller via actor-critic reinforcement learning
Patrick M Pilarski, Michael R Dawson, Thomas Degris, Farbod Fahimi, Jason P Carey, and Richard S Sutton. Online human training of a myoelectric prosthesis controller via actor-critic reinforcement learning. In 2011 IEEE international conference on rehabilitation robotics, pages 1–7. IEEE, 2011
work page 2011
-
[30]
Rafael Rafailov, Joey Hejna, Ryan Park, and Chelsea Finn. From r to qˆ* : Your language model is secretly a q-function. arXiv preprint arXiv:2404.12358, 2024
-
[31]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. Advances in Neural Information Processing Systems, 36, 2024
work page 2024
-
[32]
Crisp: Curriculum inducing primitive informed subgoal prediction
Utsav Singh and Vinay P Namboodiri. Crisp: Curriculum inducing primitive informed subgoal prediction. arXiv preprint arXiv:2304.03535, 2023
-
[33]
Pear: Primitive enabled adaptive relabeling for boosting hierarchical reinforcement learning
Utsav Singh and Vinay P Namboodiri. Pear: Primitive enabled adaptive relabeling for boosting hierarchical reinforcement learning. arXiv preprint arXiv:2306.06394, 2023
-
[34]
Utsav Singh, Wesley A Suttle, Brian M Sadler, Vinay P Namboodiri, and Amrit Singh Bedi. Piper: Primitive-informed preference-based hierarchical reinforcement learning via hindsight relabeling. arXiv preprint arXiv:2404.13423, 2024
-
[35]
Between mdps and semi-mdps: A framework for temporal abstraction in reinforcement learning
Richard S Sutton, Doina Precup, and Satinder Singh. Between mdps and semi-mdps: A framework for temporal abstraction in reinforcement learning. Artificial intelligence, 112(1-2): 181–211, 1999
work page 1999
-
[36]
Feudal networks for hierarchical reinforcement learning
Alexander Sasha Vezhnevets, Simon Osindero, Tom Schaul, Nicolas Heess, Max Jaderberg, David Silver, and Koray Kavukcuoglu. Feudal networks for hierarchical reinforcement learning. In International Conference on Machine Learning, pages 3540–3549. PMLR, 2017
work page 2017
-
[37]
State- conditioned adversarial subgoal generation
Vivienne Huiling Wang, Joni Pajarinen, Tinghuai Wang, and Joni-Kristian Kämäräinen. State- conditioned adversarial subgoal generation. In Proceedings of the AAAI conference on artificial intelligence, volume 37, pages 10184–10191, 2023
work page 2023
-
[38]
A bayesian approach for policy learning from trajectory preference queries
Aaron Wilson, Alan Fern, and Prasad Tadepalli. A bayesian approach for policy learning from trajectory preference queries. Advances in neural information processing systems, 25, 2012
work page 2012
-
[39]
Modeling purposeful adaptive behavior with the principle of maximum causal entropy
Brian D Ziebart. Modeling purposeful adaptive behavior with the principle of maximum causal entropy. Carnegie Mellon University, 2010. 12 Contents 1 Introduction 1 2 Related Work 3 3 Problem Formulation 3 3.1 Hierarchical Reinforcement Learning ( HRL) . . . . . . . . . . . . . . . . . . . . . 3 3.1.1 Hierarchical Setup . . . . . . . . . . . . . . . . . . ...
work page 2010
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.