Social media polarization during conflict: Insights from an ideological stance dataset on Israel-Palestine Reddit comments
Pith reviewed 2026-05-23 03:41 UTC · model grok-4.3
The pith
The Scoring and Reflective Re-read prompt in Mixtral 8x7B achieves the highest performance across accuracy, precision, recall, and F1-score for classifying ideological stances in Israel-Palestine Reddit comments.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By evaluating a range of classification techniques on 9,969 manually labeled Reddit comments spanning October 2023 to August 2024, the paper shows that the Scoring and Reflective Re-read prompt strategy used with Mixtral 8x7B produces the highest accuracy, precision, recall, and F1-score for distinguishing Pro-Israel, Pro-Palestine, and Neutral stances.
What carries the argument
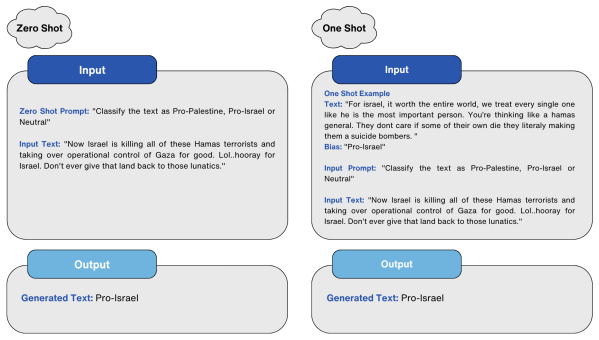
The three-class ideological stance labeling of Reddit comments together with prompt engineering strategies evaluated on the Mixtral 8x7B model.
Load-bearing premise
The three-class manual labeling of comments into Pro-Israel, Pro-Palestine, and Neutral is accurate and consistent enough to serve as ground truth for model evaluation.
What would settle it
Independent re-labeling of a random sample of the comments by multiple annotators yields low inter-annotator agreement, or the Mixtral prompt method shows markedly lower metrics on a fresh collection of comments from the same conflict.
Figures








read the original abstract
In politically sensitive scenarios like wars, social media serves as a platform for polarized discourse and expressions of strong ideological stances. While prior studies have explored ideological stance detection in general contexts, limited attention has been given to conflict-specific settings. This study addresses this gap by analyzing 9,969 Reddit comments related to the Israel-Palestine conflict, collected between October 2023 and August 2024. The comments were categorized into three stance classes: Pro-Israel, Pro-Palestine, and Neutral. Various approaches, including machine learning, pre-trained language models, neural networks, and prompt engineering strategies for open source large language models (LLMs), were employed to classify these stances. Performance was assessed using metrics such as accuracy, precision, recall, and F1-score. Among the tested methods, the Scoring and Reflective Re-read prompt in Mixtral 8x7B demonstrated the highest performance across all metrics. This study provides comparative insights into the effectiveness of different models for detecting ideological stances in highly polarized social media contexts. The dataset used in this research is publicly available for further exploration and validation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper collects 9,969 Reddit comments on the Israel-Palestine conflict (Oct 2023–Aug 2024) and manually labels them into three stance classes (Pro-Israel, Pro-Palestine, Neutral). It then benchmarks traditional ML classifiers, PLMs, neural networks, and multiple prompt-engineering strategies on open LLMs, reporting that a Scoring + Reflective Re-read prompt on Mixtral 8x7B achieves the highest accuracy, precision, recall, and F1.
Significance. If the ground-truth labels prove reliable, the work supplies a publicly released dataset for conflict-specific stance detection and a head-to-head comparison that highlights prompt-engineering gains over conventional baselines; the dataset release itself supports reproducibility and follow-on research.
major comments (2)
- [Dataset Construction / Methods] Dataset section: the manuscript states only that comments “were categorized” into the three classes and supplies no annotation protocol, number of annotators, adjudication procedure, or inter-annotator agreement statistic (Cohen’s/Fleiss’ kappa or percentage agreement). Because every performance number and the ranking of the Mixtral prompt rest on these labels as ground truth, the omission renders the central empirical claims impossible to evaluate.
- [Results / Evaluation] Results section: performance differences between methods (including the claimed superiority of Scoring + Reflective Re-read on Mixtral) are presented without any statistical significance test (McNemar, bootstrap, or paired t-test). It is therefore unclear whether the observed metric gaps exceed what would be expected from label noise or sampling variation.
minor comments (1)
- [Abstract] Abstract: the sentence “the comments were categorized” should be expanded to mention at least the existence of an annotation protocol and agreement measure so readers can immediately gauge the strength of the evaluation.
Simulated Author's Rebuttal
We thank the referee for these constructive comments, which highlight important aspects of transparency and statistical rigor. We will revise the manuscript to address both points fully.
read point-by-point responses
-
Referee: [Dataset Construction / Methods] Dataset section: the manuscript states only that comments “were categorized” into the three classes and supplies no annotation protocol, number of annotators, adjudication procedure, or inter-annotator agreement statistic (Cohen’s/Fleiss’ kappa or percentage agreement). Because every performance number and the ranking of the Mixtral prompt rest on these labels as ground truth, the omission renders the central empirical claims impossible to evaluate.
Authors: We agree that the annotation details are essential for assessing label reliability. The submitted manuscript provided only a brief statement on categorization. In the revised version we will insert a new subsection under Methods that fully describes the annotation protocol, number of annotators, annotation guidelines, adjudication process for disagreements, and inter-annotator agreement statistics (Cohen’s kappa and percentage agreement). revision: yes
-
Referee: [Results / Evaluation] Results section: performance differences between methods (including the claimed superiority of Scoring + Reflective Re-read on Mixtral) are presented without any statistical significance test (McNemar, bootstrap, or paired t-test). It is therefore unclear whether the observed metric gaps exceed what would be expected from label noise or sampling variation.
Authors: We concur that statistical testing is required to substantiate performance differences. The current manuscript reports raw metrics only. In the revision we will add McNemar’s tests (or bootstrap confidence intervals with p-values) for all pairwise comparisons among the top-performing methods, including the Mixtral prompt, to determine whether observed differences are statistically significant. revision: yes
Circularity Check
No circularity; standard empirical evaluation against external labels
full rationale
The paper collects 9,969 Reddit comments, manually assigns them to Pro-Israel/Pro-Palestine/Neutral classes, then reports accuracy/precision/recall/F1 for ML, PLM, NN, and LLM-prompt baselines against those fixed labels. No equations, no fitted parameters renamed as predictions, no self-citation chains, and no derivation that reduces to its own inputs by construction. The evaluation is a straightforward comparison on held-out manual annotations; the absence of IAA details affects validity but does not create circularity under the defined patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Reddit comments can be reliably and consistently categorized into Pro-Israel, Pro-Palestine, and Neutral by human annotators.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The comments were categorized into three stance classes: Pro-Israel, Pro-Palestine, and Neutral... Fleiss’ Kappa... 0.93
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Scoring and Reflective Re-read prompt in Mixtral 8x7B demonstrated the highest performance across all metrics
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Instruction Complexity Induces Positional Collapse in Adversarial LLM Evaluation
Complex adversarial instructions induce positional collapse in LLMs, with extreme cases showing 99.9% concentration on a single response position and zero content sensitivity.
Reference graph
Works this paper leans on
-
[1]
Jackson MO, Morelli M. Political Bias and War. American Economic Review. 2007;97(4):1353–1373. doi:10.1257/aer.97.4.1353
-
[2]
The role of (social) media in political polarization: a systematic review
Kubin E, von Sikorski C. The role of (social) media in political polarization: a systematic review. Annals of the International Communication Association. 2021;45(3):188–206. doi:10.1080/23808985.2021.1976070
-
[3]
Kuila A, Sarkar S. Deciphering Political Entity Sentiment in News with Large Language Models: Zero-Shot and Few-Shot Strategies. In: Proceedings of the Second Workshop on Natural Language Processing for Political Sciences (PoliticalNLP 2024). ELRA Language Resource Association; 2024. p. 1–11
work page 2024
-
[4]
Kwon OH, Vu K, Bhargava N, et al. Sentiment analysis of the United States public support of nuclear power on social media using large language models. Renewable and Sustainable Energy Reviews. 2024;200:114570. doi:10.1016/j.rser.2024.114570
-
[5]
Analysis of Political Sentiment Orientations on Twitter
Ansari MZ, Aziz MB, Siddiqui MO, Mehra H, Singh KP. Analysis of Political Sentiment Orientations on Twitter. Procedia Computer Science. 2020;167:1821–1828. doi:10.1016/j.procs.2020.03.201. February 4, 2025 22/26
-
[6]
Predicting political sentiments of voters from Twitter in multi-party contexts
Khatua A, Khatua A, Cambria E. Predicting political sentiments of voters from Twitter in multi-party contexts. Applied Soft Computing. 2020;97:106743. doi:10.1016/j.asoc.2020.106743
-
[7]
Political Ideology Detection Using Recursive Neural Networks
Iyyer M, Enns P, Boyd-Graber J, Resnik P. Political Ideology Detection Using Recursive Neural Networks. In: Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers); 2014. p. 1117–1127
work page 2014
-
[8]
NewsMTSC: A Dataset for (Multi-)Target-dependent Sentiment Classification in Political News Articles
Hamborg F, Donnay K. NewsMTSC: A Dataset for (Multi-)Target-dependent Sentiment Classification in Political News Articles. In: Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics; 2021. p. 1663–1675
work page 2021
-
[9]
Ideology detection using transformer-based machine learning models; 2024
¨Ozt¨ urk O,¨Ozcan A. Ideology detection using transformer-based machine learning models; 2024
work page 2024
-
[10]
ParlVote: A Corpus for Sentiment Analysis of Political Debates
Abercrombie G, Batista-Navarro R. ParlVote: A Corpus for Sentiment Analysis of Political Debates. In: Proceedings of the 12th Conference on Language Resources and Evaluation (LREC 2020). European Language Resources Association (ELRA); 2020. p. 5073–5078
work page 2020
-
[11]
Sentiment analysis on Twitter data towards climate action
Rosenberg E, Tarazona C, Mallor F, Eivazi H, Pastor-Escuredo D, Fuso-Nerini F, et al. Sentiment analysis on Twitter data towards climate action. Results in Engineering. 2023;19:101287. doi:10.1016/j.rineng.2023.101287
-
[12]
Feng S, Park CY, Liu Y, Tsvetkov Y. From Pretraining Data to Language Models to Downstream Tasks: Tracking the Trails of Political Biases Leading to Unfair NLP Models. In: Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics; 2023. p. 11737–11762
work page 2023
-
[13]
Abrar A, Oeshy NT, Kabir M, Ananiadou S. Religious Bias Landscape in Language and Text-to-Image Models: Analysis, Detection, and Debiasing Strategies. arXiv preprint arXiv:250108441. 2025
work page 2025
-
[14]
Antypas D, Preece A, Camacho-Collados J. Negativity spreads faster: A large-scale multilingual Twitter analysis on the role of sentiment in political February 4, 2025 23/26 communication. Online Social Networks and Media. 2023;33:100242. doi:10.1016/j.osnem.2023.100242
-
[15]
An integrated approach for political bias prediction and explanation based on discursive structure
Ferracane E, Baly R, Martino GDS, Barr´ on-Cede˜ no A, Nakov P. An integrated approach for political bias prediction and explanation based on discursive structure. In: Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers); 2023. p. 11195–11205
work page 2023
-
[16]
CLoSE: Contrastive Learning of Subframe Embeddings for Political Bias Classification of News Media
Kim MY, Johnson KM. CLoSE: Contrastive Learning of Subframe Embeddings for Political Bias Classification of News Media. In: Proceedings of the 29th International Conference on Computational Linguistics; 2022. p. 2780–2793
work page 2022
-
[17]
Topic-specific sentiment analysis can help identify political ideology
Bhatia S, Deepak P. Topic-specific sentiment analysis can help identify political ideology. In: Proceedings of the 9th Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis; 2018. p. 79–84
work page 2018
-
[18]
Analyzing ELMo and DistilBERT on Socio-political News Classification
B¨ uy¨ ukoz B, H¨ urriyetoglu A,¨Ozg¨ ur A. Analyzing ELMo and DistilBERT on Socio-political News Classification. In: Proceedings of AESPEN 2020, Language Resources and Evaluation Conference (LREC 2020); 2020. p. 9–18
work page 2020
-
[19]
Hernandes R. LLMs left, right, and center: Assessing GPT’s capabilities to label political bias from web domains; 2024
work page 2024
-
[20]
Whose side are you on? Investigating the political stance of large language models
Pit P, Ma X, Conway M, Chen Q, Bailey J, Pit H, et al. Whose side are you on? Investigating the political stance of large language models. New Media & Society. 2023
work page 2023
-
[21]
Al-Sarraj WF, Lubbad HM. Bias Detection of Palestinian/Israeli Conflict in Western Media: A Sentiment Analysis Experimental Study. In: 2018 International Conference on Promising Electronic Technologies (ICPET). Gaza, Palestine: Islamic University of Gaza; 2018
work page 2018
-
[22]
Taking sides: Public Opinion over the Israel-Palestine Conflict in 2021; 2022
Imtiaz A, Khan D, Lyu H, Luo J. Taking sides: Public Opinion over the Israel-Palestine Conflict in 2021; 2022. Available from: https://arxiv.org/abs/2201.05961
-
[23]
Daily Public Opinion on Israel-Palestine War; 2024
Asaniczka. Daily Public Opinion on Israel-Palestine War; 2024. Kaggle. Available from: https://doi.org/10.34740/KAGGLE/DSV/9367906. February 4, 2025 24/26
-
[24]
Measuring nominal scale agreement among many raters
Fleiss JL. Measuring nominal scale agreement among many raters. Psychological bulletin. 1971;76(5):378
work page 1971
-
[25]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Devlin J, Chang MW, Lee K, Toutanova K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Association for Computational Linguistics; 2019. p. 4171–4186
work page 2019
-
[26]
Fundamentals of Recurrent Neural Network (RNN) and Long Short-Term Memory (LSTM) network
Sherstinsky A. Fundamentals of Recurrent Neural Network (RNN) and Long Short-Term Memory (LSTM) network. Physica D: Nonlinear Phenomena. 2020;404:132306. doi:10.1016/j.physd.2019.132306
-
[27]
Cui Z, Ke R, Pu Z, Wang Y. Deep Bidirectional and Unidirectional LSTM Recurrent Neural Network for Network-wide Traffic Speed Prediction; 2019. Available from: https://arxiv.org/abs/1801.02143
-
[28]
Gate-Variants of Gated Recurrent Unit (GRU) Neural Networks
Dey R, Salem FM. Gate-Variants of Gated Recurrent Unit (GRU) Neural Networks. In: Circuits, Systems, and Neural Networks (CSANN) Lab. East Lansing, MI, USA: Department of Electrical and Computer Engineering, Michigan State University; 2017
work page 2017
-
[29]
Unsupervised Cross-lingual Representation Learning at Scale
Conneau A, Khandelwal K, Goyal N, Chaudhary V, Wenzek G, Guzm´ an F, et al. Unsupervised Cross-lingual Representation Learning at Scale. In: Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics; 2020.Available from: https://arxiv.org/abs/1911.02116
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[30]
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
Sanh V, Debut L, Chaumond J, Wolf T. DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter. In: NeurIPS 2019 Workshop on Energy Efficient Machine Learning and Cognitive Computing; 2019.Available from: https://arxiv.org/abs/1910.01108
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[31]
ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
Clark K, Luong MT, Le QV, Manning CD. ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators. In: International Conference on Learning Representations; 2020.Available from: https://arxiv.org/abs/2003.10555. February 4, 2025 25/26
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[32]
Jiang AQ, Sablayrolles A, Mensch A, Bamford C, Chaplot DS, de las Casas D, et al.. Mistral 7B; 2023. Available from: https://arxiv.org/abs/2310.06825
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
Jiang AQ, Sablayrolles A, Roux A, Mensch A, Savary B, Bamford C, et al.. Mixtral of Experts; 2024. Available from: https://arxiv.org/abs/2401.04088
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
Gemma: Open Models Based on Gemini Research and Technology
Team G, Mesnard T, Hardin C, Dadashi R, Bhupatiraju S, Pathak S, et al.. Gemma: Open Models Based on Gemini Research and Technology; 2024. Available from: https://arxiv.org/abs/2403.08295
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
The Falcon Series of Open Language Models
Almazrouei E, Alobeidli H, Alshamsi A, Cappelli A, Cojocaru RA, Hesslow D, et al. The Falcon Series of Open Language Models. ArXiv. 2023;abs/2311.16867
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[36]
Language Models are Few-Shot Learners
Brown TB, Mann B, Ryder N, Subbiah M, Kaplan J, Dhariwal P, et al.. Language Models are Few-Shot Learners; 2020. Available from: https://arxiv.org/abs/2005.14165
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[37]
Agustian S, Syah M, Fatiara N, Abdillah R. New Directions in Text Classification Research: Maximizing The Performance of Sentiment Classification from Limited Data. ArXiv. 2024;abs/2407.05627. doi:10.48550/arXiv.2407.05627
-
[38]
Hote P, Pandey D. OPEN-AMZPRE : Optimized Preprocessing with Ensemble Classification for Amazon Product Reviews Sentiment Prediction. International Journal of Scientific Research in Science and Technology. 2023;doi:10.32628/ijsrst52310672
-
[39]
Cahya L, Luthfiarta A, Krisna J, Winarno S, Nugraha A. Improving Multi-label Classification Performance on Imbalanced Datasets Through SMOTE Technique and Data Augmentation Using IndoBERT Model. Jurnal Nasional Teknologi dan Sistem Informasi. 2024;doi:10.25077/teknosi.v9i3.2023.290-298
-
[40]
Shakith A, Arockiam L. Enhancing classification accuracy on code-mixed and imbalanced data using an adaptive deep autoencoder and XGBoost. The Scientific Temper. 2024;doi:10.58414/scientifictemper.2024.15.3.27
-
[41]
Threshold optimization for F measure of macro-averaged precision and recall
Berger A, Guda S. Threshold optimization for F measure of macro-averaged precision and recall. Pattern Recognition. 2020;102:107250. doi:10.1016/j.patcog.2020.107250. February 4, 2025 26/26
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.