Efficient nonparametric estimation with difference-in-differences in the presence of network dependence and interference
Pith reviewed 2026-05-23 03:43 UTC · model grok-4.3
The pith
A doubly robust estimator extends difference-in-differences to networks with interference and latent dependence while remaining consistent and efficient.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under a conditional parallel trends assumption and suitable network dependency and heterogeneity conditions, a doubly robust estimator allowing for data-adaptive nuisance function estimation is proposed and shown to be consistent, asymptotically normal, and efficient for the network-averaged expected exposure effect if units received a specific exposure level.
What carries the argument
The doubly robust estimator combining outcome regression and exposure probability models, adjusted for network features, to estimate network-averaged exposure effects.
If this is right
- The estimator applies directly to longitudinal data with non-identically distributed units and heterogeneous treatment effects.
- It remains valid when treatment of one unit spills over to affect outcomes of its neighbors.
- Data-adaptive methods such as machine learning can be plugged in for the nuisance functions without losing efficiency.
- The approach was evaluated in simulations and applied to county-level effects of power plant emission controls on cardiovascular mortality.
Where Pith is reading between the lines
- The same doubly robust structure could be adapted to other longitudinal causal estimands such as total network effects.
- Researchers studying spatial policies or social networks could use this to relax the no-interference assumption common in standard difference-in-differences.
- Sensitivity checks that vary the definition of network neighbors would test how robust the estimates are to network misspecification.
- Extensions to time-varying exposures or staggered adoption could follow by redefining the exposure mapping accordingly.
Load-bearing premise
Expected potential outcome trajectories are parallel between treatment groups under the counterfactual where all units receive one specific treatment, after conditioning on network features.
What would settle it
A simulation or real dataset with known network structure where the estimator converges to an incorrect value or its asymptotic variance fails to match the efficiency bound despite the conditional parallel trends and dependence conditions holding.
Figures
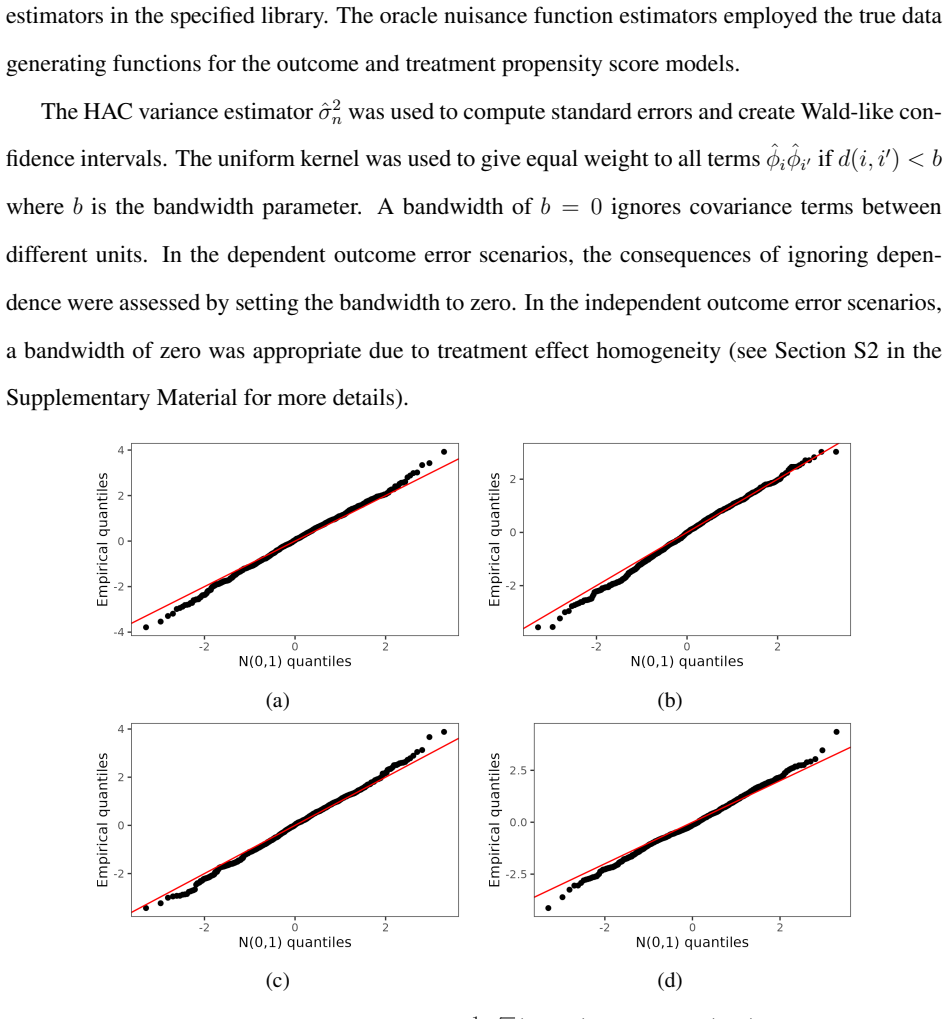


read the original abstract
Differences-in-differences (DiD) is a causal inference method for observational longitudinal data that assumes parallel expected potential outcome trajectories between treatment groups under the counterfactual scenario where all units receive a specific treatment. In this paper DiD is extended to allow for: (i) non-identically distributed treatment effects and exposure probabilities; (ii) interference, where treatment of one unit can affect outcomes in neighboring units; and (iii) latent variable dependence, where outcomes, treatments, and covariates may exhibit between-unit correlation. The causal estimand of interest is the network-averaged expected exposure effect if units received a specific exposure level, where a unit's exposure is a function of its own treatment and its neighbors' treatments. Under a conditional parallel trends assumption and suitable network dependency and heterogeneity conditions, a doubly robust estimator allowing for data-adaptive nuisance function estimation is proposed and shown to be consistent, asymptotically normal, and efficient. The proposed methods are evaluated in simulations and applied to study the effects of adopting emission control technologies in coal power plants on county-level mortality due to cardiovascular disease.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper extends difference-in-differences to observational longitudinal data with non-iid treatment effects, interference (treatment of one unit affecting neighbors), and latent variable dependence. The target is the network-averaged expected exposure effect under a specific exposure level. Under a conditional parallel trends assumption plus network dependency and heterogeneity conditions, it proposes a doubly robust estimator that permits data-adaptive nuisance estimation and claims to establish consistency, asymptotic normality, and efficiency. The approach is assessed via simulations and an empirical application to emission-control adoption by coal plants and county-level cardiovascular mortality.
Significance. If the asymptotic claims hold under the stated conditions, the work would supply a practical, doubly robust tool for causal inference in networked settings where standard DiD fails due to interference and dependence. The explicit allowance for data-adaptive nuisances and the real-data application are strengths that could increase adoption in applied work.
major comments (1)
- [Abstract] The manuscript states that consistency, asymptotic normality, and efficiency are shown, yet the actual proof steps, the precise network-dependence conditions, the form of the influence function, and the handling of data-adaptive nuisance estimators are not verifiable from the text provided. These derivations are load-bearing for the central claim.
minor comments (1)
- The abstract refers to 'suitable network dependency and heterogeneity conditions' without enumerating them; these should be stated explicitly early in the paper so readers can assess their plausibility.
Simulated Author's Rebuttal
We thank the referee for their careful reading and for identifying the need for clearer verifiability of the asymptotic results. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] The manuscript states that consistency, asymptotic normality, and efficiency are shown, yet the actual proof steps, the precise network-dependence conditions, the form of the influence function, and the handling of data-adaptive nuisance estimators are not verifiable from the text provided. These derivations are load-bearing for the central claim.
Authors: We agree that explicit pointers improve readability. The consistency, asymptotic normality, and semiparametric efficiency of the doubly robust estimator are stated in Theorem 3.1 (Section 3). The proof appears in full in Appendix A, which derives the influence function (Equation A.12) under the network dependence conditions of Assumption 2.3 (Section 2.3) and the conditional parallel trends assumption. Data-adaptive nuisance estimation is handled via cross-fitting in Section 3.3, with the efficiency result following from the Neyman orthogonality of the influence function. In the revision we will insert forward references from the abstract and introduction to these specific locations so that the derivations are immediately locatable without searching the supplement. revision: yes
Circularity Check
No significant circularity
full rationale
The paper states a conditional parallel trends assumption, derives an identification result for the network-averaged exposure effect, and constructs a doubly robust estimator whose consistency, asymptotic normality, and efficiency follow from standard influence-function arguments under the listed network dependence and heterogeneity conditions. No equation reduces a claimed result to a fitted quantity by construction, no uniqueness theorem is imported from the authors' prior work, and no self-citation is load-bearing for the central claims. The derivation is self-contained given the explicit assumptions.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption conditional parallel trends assumption
- domain assumption suitable network dependency and heterogeneity conditions
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Under a conditional parallel trends assumption and suitable network dependency and heterogeneity conditions, a doubly robust estimator allowing for data-adaptive nuisance function estimation is proposed and shown to be consistent, asymptotically normal, and efficient.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The causal estimand of interest is the network-averaged expected exposure effect if units received a specific exposure level
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[3]
*Corresponding author. Email: jetsupphasuk@unc.edu 37 Assumption S2 provides regularity conditions of the parametric model forP( ¯Git =¯ gt)≡ pi1(¯ gt)in the case when there is network effect and exposure heterogeneity. These assumptions are standard assumptions for parametric models and estimators. Assumption S2(Regularity assumptions of parametric model...
work page 2021
-
[4]
In particular, Theorem 1 in Sant’Anna and Zhao (2020) can be applied, replacing treatmentDin Sant’Anna and Zhao (2020) with1( ¯Gt =¯ gt), 1−Dwith1( ¯Gt =¯ g′ t), and generalizing the time periods from{0,1}to{t−δ, t}. S1.4 Proof of Proposition 2 Proof of Proposition 2.Letϕ ∗(O;P)as stated in Proposition 2 be the conjectured efficient influ- ence function. ...
work page 2020
-
[5]
40 S1.5 Proof of Theorem 1 Proof ofTheorem 1.By Theorem 3.1 in Kojevnikov, Marmer, and Song (2021) and Assumptions 7 – 9, the following result holds asn→ ∞: n−1 nX i=1 (ˆh1( ¯Git)− ˆh0( ¯Git,X i; ˆπi))(∆δYi −ˆµi,¯ g′ t,δ(Xi))− E[(ˆh1( ¯Git)− ˆh0( ¯Git,X i; ˆπi))(∆δYi −ˆµi,¯ g′ t,δ(Xi))] →p
work page 2021
-
[6]
The expression above can be decomposed into the following: (∗) := E n−1 nX i=1 ˆh1( ¯Git)∆δYi −h 1( ¯Git)∆δYi | {z } 1 (S3) − ˆh1( ¯Git)ˆµi,¯ g′ t,δ(Xi)−h 1( ¯Git)ˆµi,¯ g′ t,δ(Xi) | {z } 2 − ˆh0( ¯Git,X i; ˆπi)∆δYi −h 0( ¯Git,X i;π i)∆δYi | {z } 3 + ˆh0( ¯Git,X i; ˆπi)ˆµi,¯ g′ t,δ(Xi)−h 0( ¯Git,X i;π i)µi,¯ g′ t,δ(Xi) | {z } 4 . The first term, 1 , in (S3...
work page 2021
-
[7]
=n −1 nX i=1 E[(h1( ¯Git)−h 0( ¯Gt,X i;π 0 i ))(∆δYi −µ i,¯ g′ t,δ(Xi))], ˆτ(π0) =n −1 nX i=1 (ˆh1( ¯Git)− ˆh0( ¯Gt,X i; ˆπ0 i ))(∆δYi −ˆµi,¯ g′ t,δ(Xi)) Theorem 1 in Sant’Anna and Zhao (2020) shows thatτ(π
work page 2020
-
[8]
S1.6 Proof of Theorem 2 Letϕ ∗(O1:n;P) =n −1Pn i=1 ϕi(O1:n;P)denote the influence function whose form is given in the main text. In the absence of network heterogeneity,ϕ ∗(O1:n;P) =ϕ i(Oi;P)and is equal to the efficient influence function (EIF) discussed in Sant’Anna and Zhao (2020). In the following proof, we generally considerφ(O 1:n;P) =ϕ ∗(O1:n;P)sin...
work page 2020
-
[9]
Then,Ψ( ˆP)−Ψ(P)can be further decomposed (whereP nϕ∗ =ϕ ∗ sinceϕ ∗ is already a sample average), Ψ(ˆP)−Ψ(P) =−P{ϕ ∗(ˆP)}+R 2(ˆP,P), = (Pn −P)ϕ ∗(ˆP)−(P n −P)ϕ ∗(P) + (Pn −P)ϕ ∗(P) +R 2(ˆP,P) = (Pn −P)ϕ ∗(P) + (Pn −P)(ϕ ∗(ˆP)−ϕ ∗(P)) +R 2(ˆP,P), where the second equality usesP nϕ∗(ˆP) = 0and adds and subtracts(P n −P)ϕ ∗(P); and the third equality re-arra...
work page 2021
-
[10]
The remainder of the proof shows that the variance estimator is consistent for the first term σ2,∗ n = 1 n P s≥0 P i∈Nn P k∈N ∂n (i;s) E[ϕi(P)ϕk(P)]and is therefore conservative forσ 2 n with the bias equal toV n = 1 n P s≥0 P i∈Nn P k∈N ∂n (i;s)(Ψi(P)−Ψ(P))(Ψ k(P)−Ψ(P)), or the sample covariance of the network exposure effects. Consider the following, ˜σ...
work page 2021
-
[11]
= 0.5 +α i, the true individual effects wereAEE i = 5 +θ i, and the true total effect wasAEE =n −1Pn i=1(5 +θ i). Table S2: Results from 1000 simulations. Data generation Estimator parameters Results Exposure prob. het. Network corr. Exposure prob. estimator Bias + variance correction Bias ESE ASE Coverage (%) No NA Sample average No 0.000 0.040 0.048 98....
work page 2024
-
[12]
These summary statistics were similar for other study 68 Table S3: Number (percent) of counties within each exposure cohort. Exposure cohort Low interference burden High interference burden <2007 0 (0.0%) 27 (4.2%) 2007 5 (0.8%) 98 (15.2%) 2008 70 (10.9%) 198 (30.7%) 2009 367 (57.1%) 288 (44.7%) 2010 147 (22.9%) 27 (4.2%) >2010 54 (8.4%) 6 (0.9%) years. T...
work page 2007
-
[13]
Semiparametric Difference-in-Differences Estimators
Covariate Mean (SD) Quartile 3 Quartile 4 County Proportion White 0.849 (0.163) 0.857 (0.162) Proportion Black 0.118 (0.161) 0.108 (0.146) Proportion Hispanic 0.026 (0.029) 0.025 (0.04) Proportion female 0.508 (0.015) 0.51 (0.016) Median age 36.8 (2.9) 37.2 (3.0) Average household size 2.5 (0.1) 2.5 (0.1) Proportion urban 0.419 (0.287) 0.468 (0.304) Propo...
-
[14]
Butts, Kyle (2021).Difference-in-Differences Estimation with Spatial Spillovers.DOI:10.48550/ arXiv.2105.03737. Callaway, Brantly and Pedro H. C. Sant’Anna (2021). “Difference-in-Differences with multiple time periods”. In:Journal of Econometrics. Themed Issue: Treatment Effect 1 225.2, pp. 200– 230.ISSN: 0304-4076.DOI:10.1016/j.jeconom.2020.12.001. Card,...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.