Semantic Embeddings of Chemical Elements for Enhanced Materials Inference and Discovery
Pith reviewed 2026-05-23 02:32 UTC · model grok-4.3
The pith
Semantic embeddings of chemical elements derived from alloy literature outperform traditional descriptors in materials property predictions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
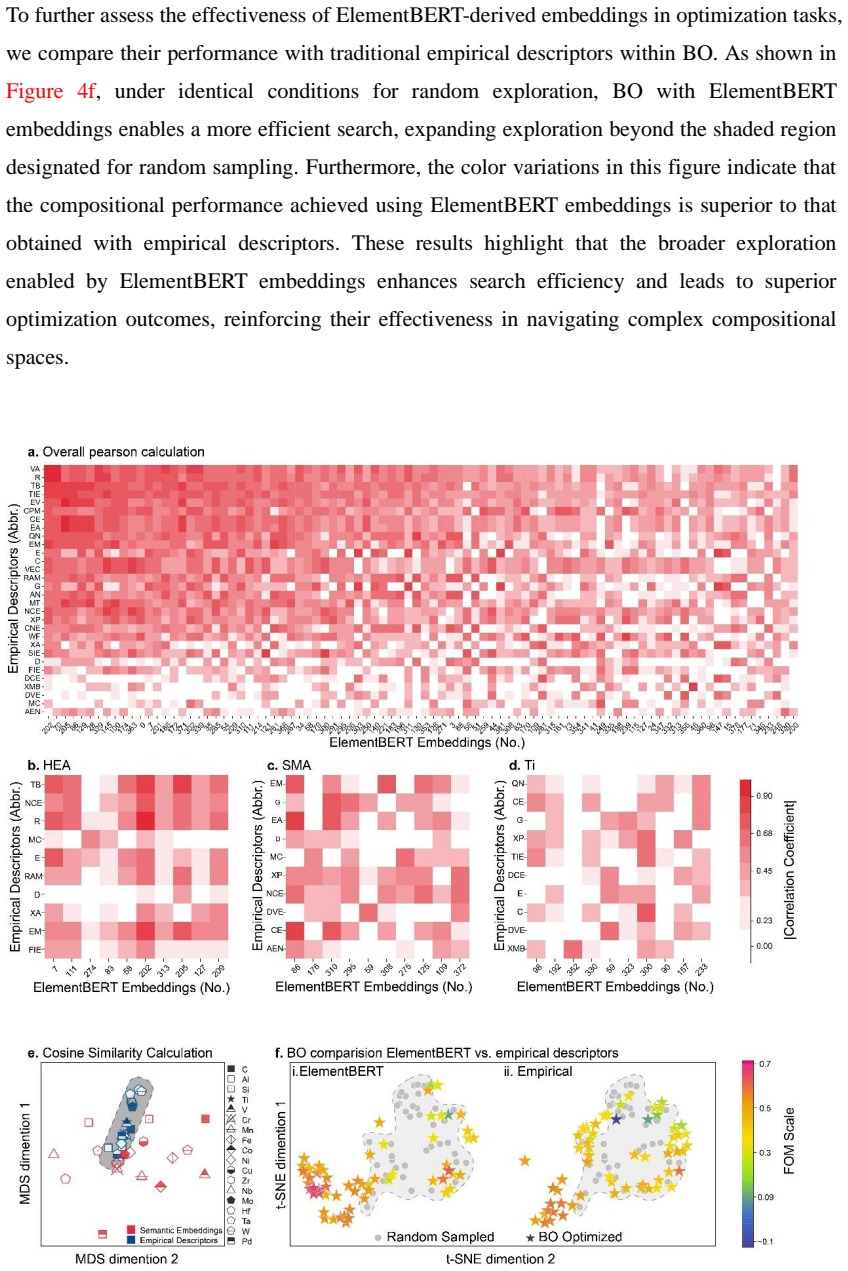
ElementBERT is a BERT-based model trained on 1.29 million abstracts of alloy-related papers that produces semantic embeddings for chemical elements. These embeddings encode latent knowledge and contextual relationships from the literature and serve as robust descriptors that improve performance on downstream materials science tasks including property prediction, phase classification, and optimization.
What carries the argument
ElementBERT, the domain-specific BERT model trained on alloy abstracts to generate semantic embeddings of elements.
Load-bearing premise
Contextual patterns learned from scientific abstracts about alloys will translate into better numerical predictions of physical properties even without separate tests confirming the literature data does not overlap with the prediction targets.
What would settle it
A direct test would be to apply the embeddings to predict properties of alloys whose discovery papers were published after the training corpus cutoff, and verify whether the accuracy advantage over traditional descriptors remains.
Figures


read the original abstract
We present a framework for generating universal semantic embeddings of chemical elements to advance materials inference and discovery. This framework leverages ElementBERT, a domain-specific BERT-based natural language processing model trained on 1.29 million abstracts of alloy-related scientific papers, to capture latent knowledge and contextual relationships specific to alloys. These semantic embeddings serve as robust elemental descriptors, consistently outperforming traditional empirical descriptors with significant improvements across multiple downstream tasks. These include predicting mechanical and transformation properties, classifying phase structures, and optimizing materials properties via Bayesian optimization. Applications to titanium alloys, high-entropy alloys, and shape memory alloys demonstrate up to 23% gains in prediction accuracy. Our results show that ElementBERT surpasses general-purpose BERT variants by encoding specialized alloy knowledge. By bridging contextual insights from scientific literature with quantitative inference, our framework accelerates the discovery and optimization of advanced materials, with potential applications extending beyond alloys to other material classes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents ElementBERT, a domain-specific BERT model trained on 1.29 million alloy-related scientific abstracts, to derive semantic embeddings for chemical elements. These embeddings are proposed as improved descriptors for materials properties prediction, outperforming traditional empirical descriptors in tasks such as predicting mechanical and transformation properties, phase structure classification, and Bayesian optimization for alloy design. Applications to titanium, high-entropy, and shape memory alloys are reported to yield up to 23% gains in prediction accuracy, with ElementBERT also surpassing general BERT models.
Significance. Should the reported improvements hold under rigorous controls for data leakage and proper statistical validation, the approach could offer a valuable bridge between natural language processing of scientific literature and quantitative materials science, enabling better use of existing knowledge for discovery. The idea of using contextual embeddings from literature as elemental features is promising for the field.
major comments (2)
- [Abstract] Abstract: The abstract states 'up to 23% gains in prediction accuracy' and 'consistent outperformance' across downstream tasks but supplies no information on baselines, cross-validation, data splits, or statistical significance. Without these details the data cannot be confirmed to support the claim.
- [Abstract] Abstract: The central claim requires that embeddings extracted from contextual co-occurrences in 1.29M alloy abstracts provide genuinely new, transferable descriptors. Because the pretraining corpus consists of the same scientific literature that reports those properties, any overlap between abstracts mentioning the specific test-set alloys and the evaluation data would allow the model to encode literature-reported correlations rather than discover independent semantic structure. The manuscript does not indicate whether such overlap was measured or excluded.
minor comments (2)
- The manuscript would benefit from explicit description of how the ElementBERT embeddings are extracted and featurized for the quantitative prediction models (e.g., input dimensionality, pooling strategy).
- Clarify the exact definition of 'traditional empirical descriptors' used as baselines and provide a table comparing them directly to the semantic embeddings on the same splits.
Simulated Author's Rebuttal
We thank the referee for highlighting issues with the abstract's completeness and the risk of data leakage. We address both points below and will revise the manuscript to strengthen the presentation of results and add the requested analysis.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract states 'up to 23% gains in prediction accuracy' and 'consistent outperformance' across downstream tasks but supplies no information on baselines, cross-validation, data splits, or statistical significance. Without these details the data cannot be confirmed to support the claim.
Authors: We agree the abstract is too concise and omits key evaluation details. The full manuscript specifies the baselines (standard empirical descriptors including atomic radius, electronegativity, and valence electron count), uses 5-fold cross-validation with random stratified splits on the alloy datasets, and reports statistical significance via paired t-tests. To address the referee's concern, we will expand the abstract with a brief clause summarizing the evaluation protocol and the nature of the baselines. revision: yes
-
Referee: [Abstract] Abstract: The central claim requires that embeddings extracted from contextual co-occurrences in 1.29M alloy abstracts provide genuinely new, transferable descriptors. Because the pretraining corpus consists of the same scientific literature that reports those properties, any overlap between abstracts mentioning the specific test-set alloys and the evaluation data would allow the model to encode literature-reported correlations rather than discover independent semantic structure. The manuscript does not indicate whether such overlap was measured or excluded.
Authors: The referee correctly notes that the manuscript does not report any measurement or exclusion of abstract overlap. This is a substantive methodological gap. We will add a dedicated subsection quantifying the fraction of pretraining abstracts that mention the exact compositions or property values appearing in each downstream test set, together with a sensitivity analysis that retrains ElementBERT after removing overlapping abstracts. The revised manuscript will present these results and discuss their impact on the reported gains. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper trains ElementBERT on 1.29M alloy abstracts to produce semantic embeddings, then applies those embeddings as descriptors in separate downstream ML tasks for property prediction and classification. No equations, self-citations, or load-bearing steps are shown that reduce any claimed prediction to the training inputs by construction. The reported accuracy gains are presented as empirical outcomes from using the embeddings versus traditional descriptors, with no self-definitional, fitted-input-renamed-as-prediction, or uniqueness-imported patterns evident. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A domain-specific BERT trained on abstracts captures latent contextual relationships that improve quantitative materials property prediction
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
ElementBERT... trained on 1.29 million abstracts... semantic embeddings... outperform traditional empirical descriptors... up to 23% gains in prediction accuracy
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Applications to titanium alloys, high-entropy alloys, and shape memory alloys
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
This process not only reduces dimensionality but also preserves the most relevant chemical insights
from the comprehensive elemental embedding space. This process not only reduces dimensionality but also preserves the most relevant chemical insights. These findings underscore the potential of NLP techniques in extracting, encoding, and concentrating domain-specific knowledge, paving the way for advances in materials science. Discussion. The BERT model d...
work page 2024
-
[2]
S. Takamoto, C. Shinagawa, D. Motoki, K. Nakago, W. Li, I. Kurata, T. Watanabe, Y . Yayama, H. Iriguchi, Y . Asano, T. Onodera, T. Ishii, T. Kudo, H. Ono, R. Sawada, R. Ishitani, M. Ong, T. Yamaguchi, T. Kataoka, A. Hayashi, N. Charoenphakdee, T. Ibuka, Towards universal neural network potential for material discovery applicable to arbitrary combination o...
work page 2022
-
[3]
C. Wen, Y . Zhang, C. Wang, D. Xue, Y . Bai, S. Antonov, L. Dai, T. Lookman, Y . Su, Machine learning assisted design of high entropy alloys with desired property, Acta Materialia 170 (2019) 109-117
work page 2019
-
[4]
A. Merchant, S. Batzner, S.S. Schoenholz, M. Aykol, G. Cheon, E.D. Cubuk, Scaling deep learning for materials discovery, Nature 624(7990) (2023) 80-85
work page 2023
-
[5]
P. Raccuglia, K.C. Elbert, P.D. Adler, C. Falk, M.B. Wenny, A. Mollo, M. Zeller, S.A. Friedler, J. Schrier, A.J. Norquist, Machine -learning-assisted materials discovery using failed experiments, Nature 533(7601) (2016) 73-6
work page 2016
-
[6]
E.O. Pyzer-Knapp, J.W. Pitera, P.W.J. Staar, S. Takeda, T. Laino, D.P. Sanders, J. Sexton, J.R. Smith, A. Curioni, Accelerating materials discovery using artificial intelligence, high performance computing and robotics, npj Computational Materials 8(1) (2022)
work page 2022
- [7]
-
[8]
P. Dang, J. Hu, Y . Xian, C. Li, Y . Zhou, X. Ding, J. Sun, D. Xue, Elastocaloric Thermal Battery: Ultrahigh Heat -Storage Capacity Based on Generative Learning -Designed Phase - Change Alloys, Adv Mater (2025) e2412198
work page 2025
-
[9]
Y . Xian, P. Dang, Y . Tian, X. Jiang, Y . Zhou, X. Ding, J. Sun, T. Lookman, D. Xue, Compositional design of multicomponent alloys using reinforcement learning, Acta Materialia 274 (2024)
work page 2024
-
[10]
M. Hu, Q. Tan, R. Knibbe, M. Xu, B. Jiang, S. Wang, X. Li, M. -X. Zhang, Recent applications of machine learning in alloy design: A review, Materials Science and Engineering: R: Reports 155 (2023)
work page 2023
-
[11]
Z. Rao, P.-Y . Tung, R. Xie, Y . Wei, H. Zhang, A. Ferrari, T.P.C. Klaver, F. Kö rmann, P .T. Sukumar, A. Kwiatkowski da Silva, Y . Chen, Z. Li, D. Ponge, J. Neugebauer, O. Gutfleisch, S. Bauer, D. Raabe, Machine learning–enabled high-entropy alloy discovery, Science 378(6615) (2022) 78-85
work page 2022
-
[12]
W. Hou, Z. Ji, Assessing GPT-4 for cell type annotation in single -cell RNA-seq analysis, Nat Methods 21(8) (2024) 1462-1465
work page 2024
- [13]
-
[14]
Y . Chen, J. Zou, Simple and effective embedding model for single-cell biology built from ChatGPT, Nat Biomed Eng (2024)
work page 2024
-
[15]
X. Cai, S. Liu, L. Yang, Y . Lu, J. Zhao, D. Shen, T. Liu, COVIDSum: A linguistically enriched SciBERT-based summarization model for COVID -19 scientific papers, J Biomed Inform 127 (2022) 103999
work page 2022
-
[16]
C. Kuenneth, R. Ramprasad, polyBERT: a chemical language model to enable fully machine-driven ultrafast polymer informatics, Nat Commun 14(1) (2023) 4099
work page 2023
-
[17]
M.C. Ramos, C.J. Collison, A.D. White, A review of large language models and autonomous agents in chemistry, Chem Sci 16(6) (2025) 2514-2572
work page 2025
-
[18]
S. Yu, N. Ran, J. Liu, Large -language models: The game -changers for materials science research, Artificial Intelligence Chemistry 2(2) (2024)
work page 2024
-
[19]
S. Liu, T. Wen, A.S.L.S. Pattamatta, D.J. Srolovitz, A prompt-engineered large language model, deep learning workflow for materials classification, Materials Today 80 (2024) 240 - 249
work page 2024
-
[20]
Eric Tang, Xingyou Son, Understanding LLM Embeddings for Regression, arXiv (2025)
B.Y . Eric Tang, Xingyou Son, Understanding LLM Embeddings for Regression, arXiv (2025)
work page 2025
-
[21]
V . Tshitoyan, J. Dagdelen, L. Weston, A. Dunn, Z. Rong, O. Kononova, K.A. Persson, G. Ceder, A. Jain, Unsupervised word embeddings capture latent knowledge from materials science literature, Nature 571(7763) (2019) 95-98
work page 2019
-
[22]
Z. Pei, J. Yin, P.K. Liaw, D. Raabe, Toward the design of ultrahigh -entropy alloys via mining six million texts, Nat Commun 14(1) (2023) 54
work page 2023
-
[23]
S.L. Bo Hu, Beilin Ye, Yun Hao, Tongqi Wen, A Multi -agent Framework for Materials Laws Discovery, arXiv (2024)
work page 2024
-
[24]
Q.Z. Tung Nguyen, Bangding Yang, Chansoo Lee, Jorg Bornschein,Sagi Perel ,Yutian Chen , Xingyou Song, Predicting from Strings: Language Model Embeddings for Bayesian Optimization, OpenReview.net (2024)
work page 2024
-
[25]
S. Huang, J.M. Cole, BatteryBERT: A Pretrained Language Model for Battery Database Enhancement, J Chem Inf Model 62(24) (2022) 6365-6377
work page 2022
-
[26]
P. Shetty, A.C. Rajan, C. Kuenneth, S. Gupta, L.P . Panchumarti, L. Holm, C. Zhang, R. Ramprasad, A general-purpose material property data extraction pipeline from large polymer corpora using natural language processing, NPJ Comput Mater 9(1) (2023) 52
work page 2023
-
[27]
J. Zhao, S. Huang, J.M. Cole, OpticalBERT and OpticalTable -SQA: Text- and Table- Based Language Models for the Optical -Materials Domain, J Chem Inf Model 63(7) (2023) 1961-1981
work page 2023
- [28]
-
[29]
A. Chaudhari, C. Guntuboina, H. Huang, A.B. Farimani, AlloyBERT: Alloy property prediction with large language models, Computational Materials Science 244 (2024)
work page 2024
-
[30]
D. Chen, K. Gao, D.D. Nguyen, X. Chen, Y . Jiang, G.W. Wei, F. Pan, Algebraic graph- assisted bidirectional transformers for molecular property prediction, Nat Commun 12(1) (2021) 3521
work page 2021
-
[31]
A.P.O. Costa, M.R.R. Seabra, J.M.A. Cé sar de Sá , A.D. Santos, Manufacturing process encoding through natural language processing for prediction of material properties, Computational Materials Science 237 (2024)
work page 2024
-
[32]
K.M. Jablonka, P. Schwaller, A. Ortega -Guerrero, B. Smit, Leveraging large language models for predictive chemistry, Nature Machine Intelligence 6(2) (2024) 161-169
work page 2024
-
[33]
P. Liu, J. Tao, Z. Ren, A quantitative analysis of knowledge-learning preferences in large language models in molecular science, Nature Machine Intelligence (2025)
work page 2025
-
[34]
S. Tian, X. Jiang, W. Wang, Z. Jing, C. Zhang, C. Zhang, T. Lookman, Y . Su, Steel design based on a large language model, Acta Materialia 285 (2025)
work page 2025
-
[35]
K.N. Sasidhar, N.H. Siboni, J.R. Mianroodi, M. Rohwerder, J. Neugebauer, D. Raabe, Enhancing corrosion -resistant alloy design through natural language processing and deep learning, Science Advances 9(32) (2023) eadg7992
work page 2023
-
[36]
P. He, X. Liu, J. Gao, W. Chen, Deberta: Decoding -enhanced bert with disentangled attention, arXiv preprint arXiv:2006.03654 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[37]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
J. Devlin, Bert: Pre -training of deep bidirectional transformers for language understanding, arXiv preprint arXiv:1810.04805 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[38]
P . He, J. Gao, W. Chen, Debertav3: Improving deberta using electra -style pre-training with gradient-disentangled embedding sharing, arXiv preprint arXiv:2111.09543 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[39]
Y . Xian, Leveraging Feature Gradient for Efficient Acquisition Function Maximization in Material Composition design, in Review in npj Computational Materials (2025)
work page 2025
-
[40]
Distilling the Knowledge in a Neural Network
G. Hinton, Distilling the Knowledge in a Neural Network, arXiv preprint arXiv:1503.02531 (2015)
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[41]
S.L. France, J.D. Carroll, Two -Way Multidimensional Scaling: A Review, IEEE Transactions on Systems, Man, and Cybernetics, Part C (Applications and Reviews) 41(5) (2011) 644-661
work page 2011
-
[42]
S. Shen, J. Liu, L. Lin, Y . Huang, L. Zhang, C. Liu, Y . Feng, D. Wang, SsciBERT: A pre- trained language model for social science texts, Scientometrics 128(2) (2023) 1241-1263
work page 2023
- [43]
-
[44]
T. Wolf, L. Debut, V . Sanh, J. Chaumond, C. Delangue, A. Moi, P. Cistac, T. Rault, R. Louf, M. Funtowicz, J. Davison, S. Shleifer, P. von Platen, C. Ma, Y . Jernite, J. Plu, C. Xu, T. Le Scao, S. Gugger, M. Drame, Q. Lhoest, A. Rush, Transformers: State -of-the-Art Natural Language Processing, Association for Computational Linguistics, Online, 2020, pp. 38-45
work page 2020
-
[45]
F. Pedregosa, G. V aroquaux, A. Gramfort, V . Michel, B. Thirion, O. Grisel, M. Blondel, P . Prettenhofer, R. Weiss, V . Dubourg, J. Vanderplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, É . Duchesnay, Scikit-learn: Machine Learning in Python, J. Mach. Learn. Res. 12(null) (2011) 2825–2830
work page 2011
-
[46]
Nogueira, Bayesian Optimization: Open source constrained global optimization tool for Python, (2014)
F. Nogueira, Bayesian Optimization: Open source constrained global optimization tool for Python, (2014)
work page 2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.