Hypergraph Multi-Modal Learning for EEG-based Emotion Recognition in Conversation
Pith reviewed 2026-05-23 01:51 UTC · model grok-4.3
The pith
Hyper-MML fuses EEG brain signals with audio and video through hypergraphs to recognize emotions in conversations more accurately than prior methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Hyper-MML integrates EEG with audio and video information to capture complex emotional dynamics through an Adaptive Brain Encoder with Mutual-cross Attention module that extracts emotion-relevant features across frequency bands while adapting to subject-specific variations, combined with an Adaptive Hypergraph Fusion Module that actively models higher-order multi-modal relationships in emotion recognition in conversation.
What carries the argument
The Adaptive Hypergraph Fusion Module (AHFM) that models higher-order relationships among multi-modal signals, supported by the Adaptive Brain Encoder with Mutual-cross Attention (ABEMA) for EEG processing across frequency bands.
If this is right
- The model significantly outperforms current state-of-the-art methods on the EAV and AFFEC datasets.
- It can serve as an effective communication tool for healthcare professionals working with patients who struggle to express emotions.
- The framework enables better engagement with individuals who have difficulty voicing their feelings.
- It integrates physiological EEG signals into emotion recognition in conversation systems that previously relied mainly on audio and visual data.
Where Pith is reading between the lines
- The subject-adaptive attention in ABEMA could support personalized versions of the system for long-term use with specific patients.
- Hypergraph fusion of physiological signals may apply to other multi-modal tasks such as mental health monitoring or human-computer interaction.
- Real-time deployment in clinical settings could allow continuous emotion tracking during therapy sessions without relying on verbal reports.
Load-bearing premise
The ABEMA and AHFM modules capture emotion-relevant features and higher-order relationships in a way that generalizes beyond the tested subjects and the EAV and AFFEC datasets.
What would settle it
Evaluation on a new independent dataset with unseen subjects and conversation contexts where Hyper-MML fails to outperform state-of-the-art methods would falsify the performance claim.
Figures

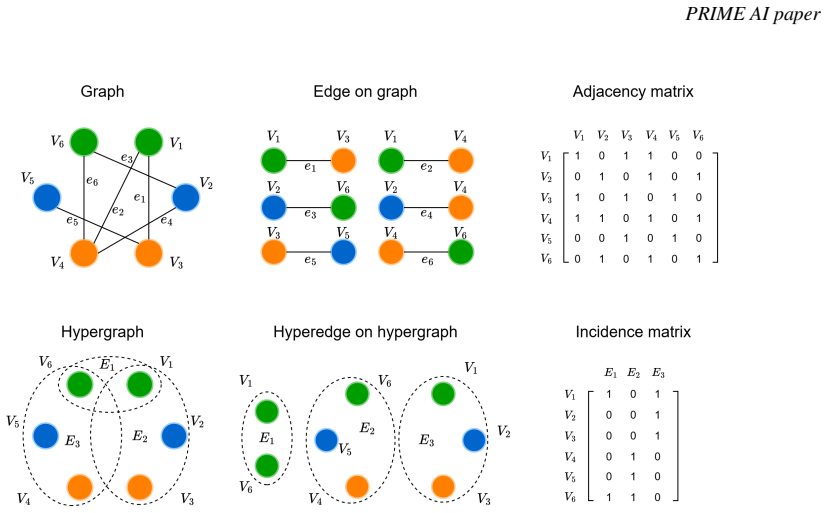

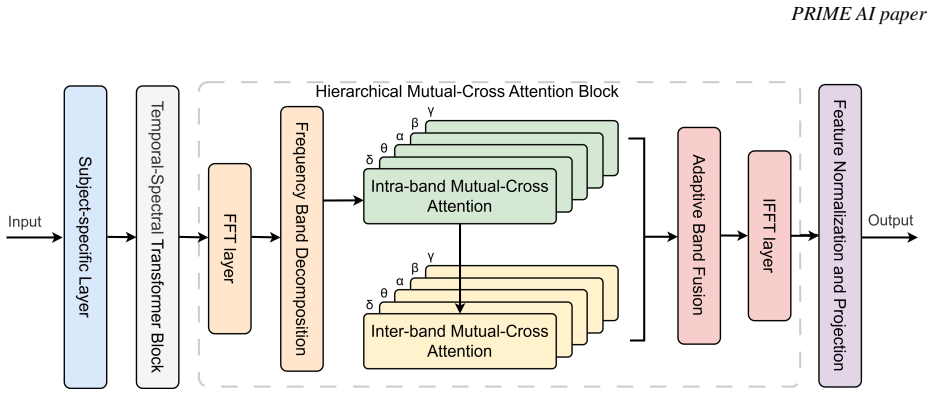


read the original abstract
Emotional Recognition in Conversation (ERC) is valuable for diagnosing health conditions such as autism and depression, and for understanding the emotions of individuals who struggle to express their feelings. Current ERC methods primarily rely on semantic, audio and visual data but face significant challenges in integrating physiological signals such as Electroencephalography (EEG). This research proposes Hypergraph Multi-Modal Learning (Hyper-MML), a novel framework for identifying emotions in conversation. Hyper-MML effectively integrates EEG with audio and video information to capture complex emotional dynamics. Firstly, we introduce an Adaptive Brain Encoder with Mutual-cross Attention (ABEMA) module for processing EEG signals. This module captures emotion-relevant features across different frequency bands and adapts to subject-specific variations through hierarchical mutual-cross attention mechanisms. Secondly, we propose an Adaptive Hypergraph Fusion Module (AHFM) to actively model the higher-order relationships among multi-modal signals in ERC. Experimental results on the EAV and AFFEC datasets demonstrate that our Hyper-MML model significantly outperforms current state-of-the-art methods. The proposed Hyper-MML can serve as an effective communication tool for healthcare professionals, enabling better engagement with patients who have difficulty expressing their emotions. The official implementation codes are available at https://github.com/NZWANG/Hyper-MML.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Hyper-MML, a multi-modal framework for emotion recognition in conversation that fuses EEG with audio and video modalities. It introduces the ABEMA module to process EEG via hierarchical mutual-cross attention across frequency bands while adapting to subject-specific variations, and the AHFM module to model higher-order relationships among modalities via hypergraphs. The central claim is that Hyper-MML significantly outperforms current SOTA methods on the EAV and AFFEC datasets, with code released at the provided GitHub link.
Significance. If the reported gains hold under subject-independent validation, the work would advance ERC by incorporating EEG signals, with potential utility in healthcare settings for patients with expression difficulties. The explicit release of implementation code is a clear strength for reproducibility.
major comments (2)
- [§4 (Experimental Setup) and Table 1/2] §4 (Experimental Setup) and Table 1/2: The claim that ABEMA 'adapts to subject-specific variations' and enables generalization is load-bearing for the central outperformance result, yet the manuscript does not report whether leave-one-subject-out (LOSO) cross-validation was used on EAV or AFFEC. Within-subject or random splits would allow subject-specific overfitting to explain the gains, undermining the adaptation mechanism.
- [§3.2 (AHFM) and ablation studies] §3.2 (AHFM) and ablation studies: No ablation isolates the contribution of the hypergraph fusion versus simpler concatenation or graph baselines; without this, it is unclear whether the reported improvements on multi-modal relationships are attributable to AHFM or to other factors such as increased model capacity.
minor comments (2)
- [Abstract] Abstract: The statement 'significantly outperforms current state-of-the-art methods' lacks any quantitative deltas, baseline names, or statistical test references.
- [§3.1] Notation in §3.1: The hierarchical mutual-cross attention equations use symbols (e.g., Q, K, V variants) that are not defined until later in the section, reducing readability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify key aspects of our experimental validation and module contributions. We address each major point below with plans for revision.
read point-by-point responses
-
Referee: [§4 (Experimental Setup) and Table 1/2] §4 (Experimental Setup) and Table 1/2: The claim that ABEMA 'adapts to subject-specific variations' and enables generalization is load-bearing for the central outperformance result, yet the manuscript does not report whether leave-one-subject-out (LOSO) cross-validation was used on EAV or AFFEC. Within-subject or random splits would allow subject-specific overfitting to explain the gains, undermining the adaptation mechanism.
Authors: We agree that the validation procedure must be explicitly reported to substantiate the generalization claims for ABEMA. The revised manuscript will clearly state the cross-validation strategy used on EAV and AFFEC. In addition, we will perform and report new leave-one-subject-out (LOSO) experiments to confirm that the reported gains hold under subject-independent settings, directly addressing concerns about potential overfitting. revision: yes
-
Referee: [§3.2 (AHFM) and ablation studies] §3.2 (AHFM) and ablation studies: No ablation isolates the contribution of the hypergraph fusion versus simpler concatenation or graph baselines; without this, it is unclear whether the reported improvements on multi-modal relationships are attributable to AHFM or to other factors such as increased model capacity.
Authors: We acknowledge the value of isolating AHFM's contribution. The revised manuscript will include a new ablation study that directly compares the full AHFM hypergraph fusion against controlled baselines using concatenation and standard graph fusion, with model capacity matched across variants. This will clarify that performance gains stem from higher-order relational modeling rather than capacity differences. revision: yes
Circularity Check
No circularity: empirical claims rest on dataset experiments, not derivations or self-referential fits
full rationale
The paper introduces ABEMA and AHFM modules for EEG-audio-video fusion in ERC and supports its claims solely via performance numbers on the EAV and AFFEC datasets. No equations, derivations, parameter-fitting steps, or uniqueness theorems appear in the provided text. The central assertion (outperformance of SOTA) is therefore an empirical observation rather than a quantity that reduces by construction to its own inputs. No self-citation load-bearing steps, ansatzes, or renamings are present. This is the normal non-circular case for an applied ML methods paper whose validity hinges on external benchmarks.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 2 Pith papers
-
EEG-Based Multimodal Learning via Hyperbolic Mixture-of-Curvature Experts
EEG-MoCE uses learnable-curvature hyperbolic mixture-of-experts to capture hierarchical structures in multimodal EEG data and achieves state-of-the-art performance on emotion recognition, sleep staging, and cognitive ...
-
EEG-Based Multimodal Learning via Hyperbolic Mixture-of-Curvature Experts
EEG-MoCE assigns each modality to a learnable-curvature hyperbolic expert and applies curvature-aware fusion to achieve state-of-the-art results on emotion recognition, sleep staging, and cognitive assessment benchmarks.
Reference graph
Works this paper leans on
-
[1]
Autism and Depression: clinical presentation, evaluation and treatment
Amaia Hervás. Autism and Depression: clinical presentation, evaluation and treatment. Medicina (Argentina), 83(Suppl 2):37–42, 2023
work page 2023
-
[2]
Emotion recognition in conversation: Research challenges, datasets, and recent advances
Soujanya Poria, Navonil Majumder, Rada Mihalcea, and Eduard Hovy. Emotion recognition in conversation: Research challenges, datasets, and recent advances. IEEE access, 7:100943–100953, 2019
work page 2019
-
[3]
MMGCN: Multimodal fusion via deep graph convolution network for emotion recognition in conversation
Jingwen Hu, Yuchen Liu, Jinming Zhao, and Qin Jin. MMGCN: Multimodal fusion via deep graph convolution network for emotion recognition in conversation. arXiv preprint arXiv:2107.06779, 2021
-
[4]
EEG based emotion recognition: A tutorial and review
Xiang Li, Yazhou Zhang, Prayag Tiwari, Dawei Song, Bin Hu, Meihong Yang, Zhigang Zhao, Neeraj Kumar, and Pekka Marttinen. EEG based emotion recognition: A tutorial and review. ACM Computing Surveys, 55(4):1–57, 2022. 16 PRIME AI paper
work page 2022
-
[5]
Yueyang Li, Weiming Zeng, Wenhao Dong, Di Han, Lei Chen, Hongyu Chen, Zijian Kang, Shengyu Gong, Hongjie Yan, Wai Ting Siok, et al. A tale of single-channel electroencephalogram: Devices, datasets, signal processing, applications, and future directions. IEEE Transactions on Instrumentation and Measurement, 2025
work page 2025
-
[6]
Feature fusion based on mutual-cross-attention mechanism for eeg emotion recognition
Yimin Zhao and Jin Gu. Feature fusion based on mutual-cross-attention mechanism for eeg emotion recognition. In International Conference on Medical Image Computing and Computer-Assisted Intervention, pages 276–285. Springer, 2024
work page 2024
-
[7]
Hongyu Chen, Weiming Zeng, Chengcheng Chen, Luhui Cai, Fei Wang, Yuhu Shi, Lei Wang, Wei Zhang, Yueyang Li, Hongjie Yan, et al. Eeg emotion copilot: Optimizing lightweight llms for emotional eeg interpretation with assisted medical record generation. Neural Networks, page 107848, 2025
work page 2025
-
[8]
Hypergcn: A new method for training graph convolutional networks on hypergraphs
Naganand Yadati, Madhav Nimishakavi, Prateek Yadav, Vikram Nitin, Anand Louis, and Partha Talukdar. Hypergcn: A new method for training graph convolutional networks on hypergraphs. Advances in Neural Information Processing Systems, 32, 2019
work page 2019
-
[9]
Min-Ho Lee, Adai Shomanov, Balgyn Begim, Zhuldyz Kabidenova, Aruna Nyssanbay, Adnan Yazici, and Seong- Whan Lee. EA V: EEG-Audio-Video dataset for emotion recognition in conversational contexts.Scientific data, 11(1):1026, 2024
work page 2024
-
[10]
Advancing face-to-face emotion communication: A multimodal dataset (affec)
Meisam J Sekiavandi, Laurits Dixen, Jostein Fimland, Sree Keerthi Desu, Antonia-Bianca Zserai, Ye Sul Lee, Maria Barrett, and Paolo Burelli. Advancing face-to-face emotion communication: A multimodal dataset (affec). arXiv preprint arXiv:2504.18969, 2025
-
[11]
Dialoguernn: An attentive rnn for emotion detection in conversations
Navonil Majumder, Soujanya Poria, Devamanyu Hazarika, Rada Mihalcea, Alexander Gelbukh, and Erik Cambria. Dialoguernn: An attentive rnn for emotion detection in conversations. In Proceedings of the AAAI conference on artificial intelligence, volume 33, pages 6818–6825, 2019
work page 2019
-
[12]
Dialoguegcn: A graph convolutional neural network for emotion recognition in conversation
Deepanway Ghosal, Navonil Majumder, Soujanya Poria, Niyati Chhaya, and Alexander Gelbukh. Dialoguegcn: A graph convolutional neural network for emotion recognition in conversation. arXiv preprint arXiv:1908.11540, 2019
-
[13]
Rui Liu, Haolin Zuo, Zheng Lian, Björn W Schuller, and Haizhou Li. Contrastive learning based modality-invariant feature acquisition for robust multimodal emotion recognition with missing modalities. IEEE Transactions on Affective Computing, 15(4):1856–1873, 2024
work page 2024
-
[14]
Mind the gap: Under- standing the modality gap in multi-modal contrastive representation learning
Victor Weixin Liang, Yuhui Zhang, Yongchan Kwon, Serena Yeung, and James Y Zou. Mind the gap: Under- standing the modality gap in multi-modal contrastive representation learning. Advances in Neural Information Processing Systems, 35:17612–17625, 2022
work page 2022
-
[15]
Eegnet: a compact convolutional neural network for eeg-based brain–computer interfaces
Vernon J Lawhern, Amelia J Solon, Nicholas R Waytowich, Stephen M Gordon, Chou P Hung, and Brent J Lance. Eegnet: a compact convolutional neural network for eeg-based brain–computer interfaces. Journal of neural engineering, 15(5):056013, 2018
work page 2018
-
[16]
Pgcn: Pyramidal graph convolutional network for eeg emotion recognition
Ming Jin, Changde Du, Huiguang He, Ting Cai, and Jinpeng Li. Pgcn: Pyramidal graph convolutional network for eeg emotion recognition. IEEE Transactions on Multimedia, 26:9070–9082, 2024
work page 2024
-
[17]
Cunbo Li, Tian Tang, Yue Pan, Lei Yang, Shuhan Zhang, Zhaojin Chen, Peiyang Li, Dongrui Gao, Huafu Chen, Fali Li, et al. An efficient graph learning system for emotion recognition inspired by the cognitive prior graph of eeg brain network. IEEE Transactions on Neural Networks and Learning Systems, 36(4):7130–7144, 2024
work page 2024
-
[18]
Emotion recognition using multimodal residual lstm network
Jiaxin Ma, Hao Tang, Wei-Long Zheng, and Bao-Liang Lu. Emotion recognition using multimodal residual lstm network. In Proceedings of the 27th ACM international conference on multimedia, pages 176–183, 2019
work page 2019
-
[19]
Spatial–temporal recurrent neural network for emotion recognition
Tong Zhang, Wenming Zheng, Zhen Cui, Yuan Zong, and Yang Li. Spatial–temporal recurrent neural network for emotion recognition. IEEE transactions on cybernetics, 49(3):839–847, 2018
work page 2018
-
[20]
Tsception: Capturing temporal dynamics and spatial asymmetry from eeg for emotion recognition
Yi Ding, Neethu Robinson, Su Zhang, Qiuhao Zeng, and Cuntai Guan. Tsception: Capturing temporal dynamics and spatial asymmetry from eeg for emotion recognition. IEEE Transactions on Affective Computing, 14(3):2238– 2250, 2022
work page 2022
-
[21]
Accnet: Adaptive cross-frequency coupling graph attention for eeg emotion recognition
Dongyuan Tian, Yucheng Wang, Peiliang Gong, Zhewen Xu, Zhenghua Chen, Xiaohui Wei, and Min Wu. Accnet: Adaptive cross-frequency coupling graph attention for eeg emotion recognition. Neural Networks, page 107853, 2025
work page 2025
-
[22]
Eeg-based multimodal representation learning for emotion recognition
Kang Yin, Hye-Bin Shin, Dan Li, and Seong-Whan Lee. Eeg-based multimodal representation learning for emotion recognition. In 2025 13th International Conference on Brain-Computer Interface (BCI), pages 1–4. IEEE, 2025
work page 2025
-
[23]
A survey on hypergraph representation learning
Alessia Antelmi, Gennaro Cordasco, Mirko Polato, Vittorio Scarano, Carmine Spagnuolo, and Dingqi Yang. A survey on hypergraph representation learning. ACM Computing Surveys, 56(1):1–38, 2023. 17 PRIME AI paper
work page 2023
-
[24]
Random walks on hypergraphs with edge-dependent vertex weights
Uthsav Chitra and Benjamin Raphael. Random walks on hypergraphs with edge-dependent vertex weights. In International Conference on Machine Learning, pages 1172–1181. PMLR, 2019
work page 2019
-
[25]
Yue Gao, Yifan Feng, Shuyi Ji, and Rongrong Ji. Hgnn+: General hypergraph neural networks.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(3):3181–3199, 2022
work page 2022
-
[26]
Self-supervised hypergraph transformer for recommender systems
Lianghao Xia, Chao Huang, and Chuxu Zhang. Self-supervised hypergraph transformer for recommender systems. In Proceedings of the 28th ACM SIGKDD conference on knowledge discovery and data mining, pages 2100–2109, 2022
work page 2022
-
[27]
Exploiting spatial-temporal data for sleep stage classification via hypergraph learning
Yuze Liu, Ziming Zhao, Tiehua Zhang, Kang Wang, Xin Chen, Xiaowei Huang, Jun Yin, and Zhishu Shen. Exploiting spatial-temporal data for sleep stage classification via hypergraph learning. In ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 5430–5434. IEEE, 2024
work page 2024
-
[28]
Ding Ruan, Shuyi Ji, Chenggang Yan, Junjie Zhu, Xibin Zhao, Yuedong Yang, Yue Gao, Changqing Zou, and Qionghai Dai. Exploring complex and heterogeneous correlations on hypergraph for the prediction of drug-target interactions. Patterns, 2(12), 2021
work page 2021
-
[29]
Zijian Yi, Ziming Zhao, Zhishu Shen, and Tiehua Zhang. Multimodal fusion via hypergraph autoencoder and contrastive learning for emotion recognition in conversation. In Proceedings of the 32nd ACM international conference on multimedia, pages 4341–4348, 2024
work page 2024
-
[30]
Neural-mcrl: Neural multimodal contrastive representation learning for eeg-based visual decoding
Yueyang Li, Zijian Kang, Shengyu Gong, Wenhao Dong, Weiming Zeng, Hongjie Yan, Wai Ting Siok, and Nizhuan Wang. Neural-mcrl: Neural multimodal contrastive representation learning for eeg-based visual decoding. arXiv preprint arXiv:2412.17337, 2024
-
[31]
iTransformer: Inverted Transformers Are Effective for Time Series Forecasting
Yong Liu, Tengge Hu, Haoran Zhang, Haixu Wu, Shiyu Wang, Lintao Ma, and Mingsheng Long. itransformer: Inverted transformers are effective for time series forecasting. arXiv preprint arXiv:2310.06625, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
Opensmile: the munich versatile and fast open-source audio feature extractor
Florian Eyben, Martin Wöllmer, and Björn Schuller. Opensmile: the munich versatile and fast open-source audio feature extractor. In Proceedings of the 18th ACM international conference on Multimedia, pages 1459–1462, 2010
work page 2010
-
[33]
Zengqun Zhao, Qingshan Liu, and Shanmin Wang. Learning deep global multi-scale and local attention features for facial expression recognition in the wild. IEEE Transactions on Image Processing, 30:6544–6556, 2021
work page 2021
-
[34]
Feiyu Chen, Jie Shao, Shuyuan Zhu, and Heng Tao Shen. Multivariate, multi-frequency and multimodal: Rethinking graph neural networks for emotion recognition in conversation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10761–10770, 2023
work page 2023
-
[35]
Mm-dfn: Multimodal dynamic fusion network for emotion recognition in conversations
Dou Hu, Xiaolong Hou, Lingwei Wei, Lianxin Jiang, and Yang Mo. Mm-dfn: Multimodal dynamic fusion network for emotion recognition in conversations. In ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 7037–7041. IEEE, 2022
work page 2022
-
[36]
Graphmft: A graph network based multimodal fusion technique for emotion recognition in conversation
Jiang Li, Xiaoping Wang, Guoqing Lv, and Zhigang Zeng. Graphmft: A graph network based multimodal fusion technique for emotion recognition in conversation. Neurocomputing, 550:126427, 2023
work page 2023
-
[37]
A multi-view cnn with novel variance layer for motor imagery brain computer interface
Ravikiran Mane, Neethu Robinson, A Prasad Vinod, Seong-Whan Lee, and Cuntai Guan. A multi-view cnn with novel variance layer for motor imagery brain computer interface. In 2020 42nd annual international conference of the IEEE engineering in medicine & biology society (EMBC), pages 2950–2953. Ieee, 2020
work page 2020
-
[38]
Yuntao Shou, Tao Meng, Wei Ai, Fuchen Zhang, Nan Yin, and Keqin Li. Adversarial alignment and graph fusion via information bottleneck for multimodal emotion recognition in conversations. Information Fusion, 112:102590, 2024
work page 2024
-
[39]
Decoding natural images from eeg for object recognition
Yonghao Song, Bingchuan Liu, Xiang Li, Nanlin Shi, Yijun Wang, and Xiaorong Gao. Decoding natural images from eeg for object recognition. arXiv preprint arXiv:2308.13234, 2023
-
[40]
Visual decoding and reconstruction via eeg embeddings with guided diffusion
Dongyang Li, Chen Wei, Shiying Li, Jiachen Zou, Haoyang Qin, and Quanying Liu. Visual decoding and reconstruction via eeg embeddings with guided diffusion. arXiv preprint arXiv:2403.07721, 2024. 18
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.