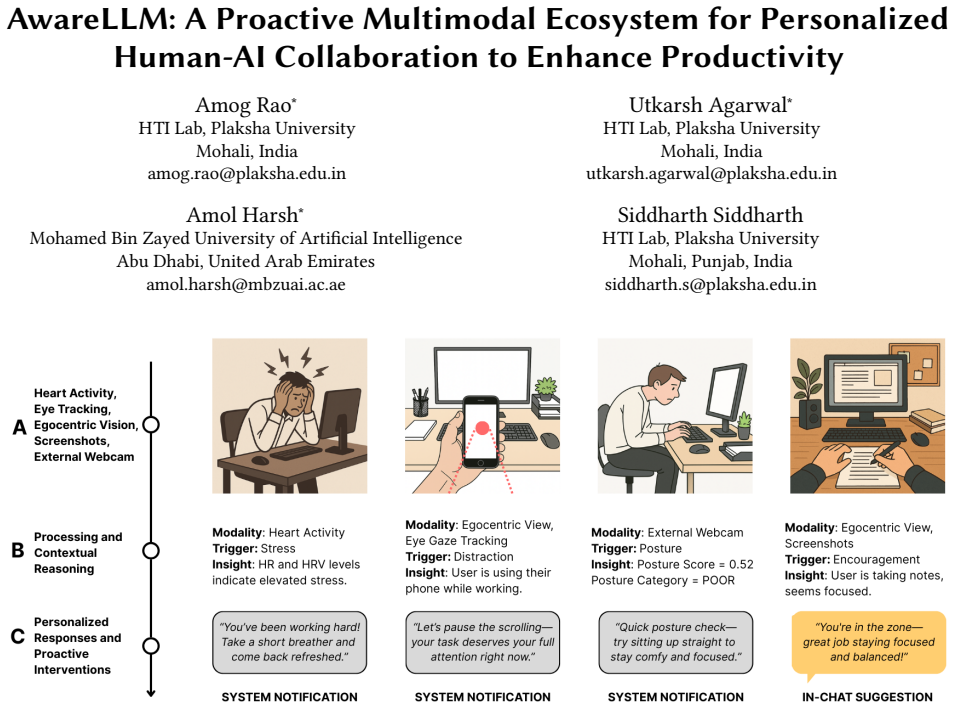
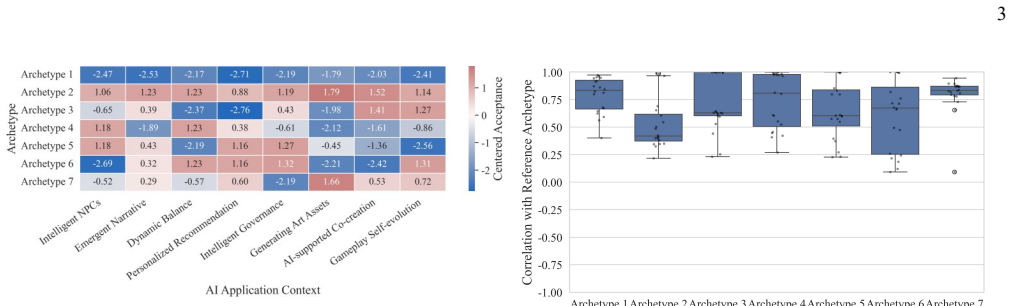
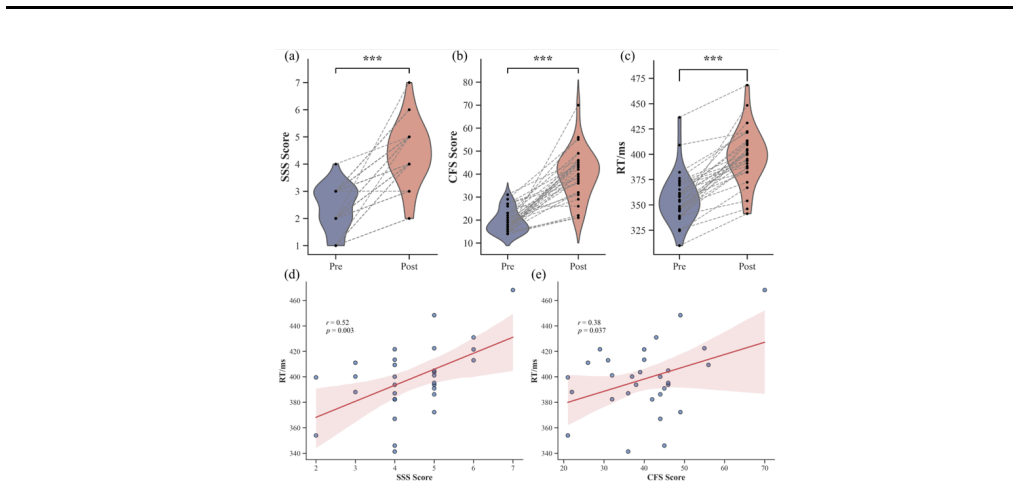
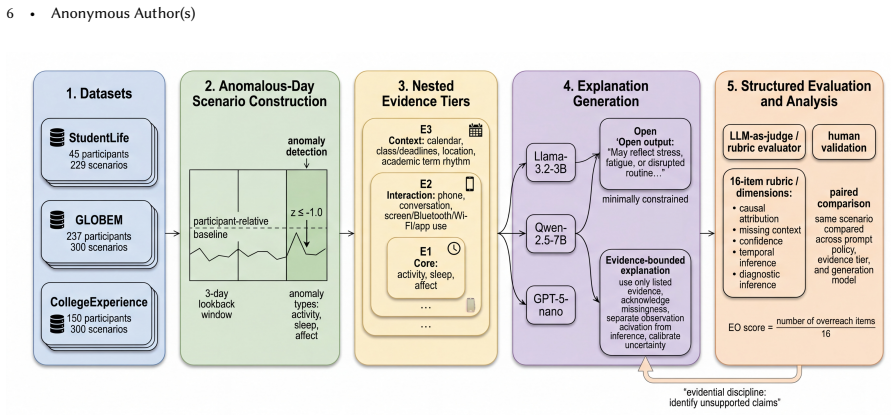
0
AI goals score higher on SMART but cut follow-through
Optimized but Unowned: How AI-Authored Goals Undermine the Motivation They Are Meant to Drive
Ownership loss explains why fewer people act when the model writes the goals instead of the person.
 full image
full image
abstract click to expand
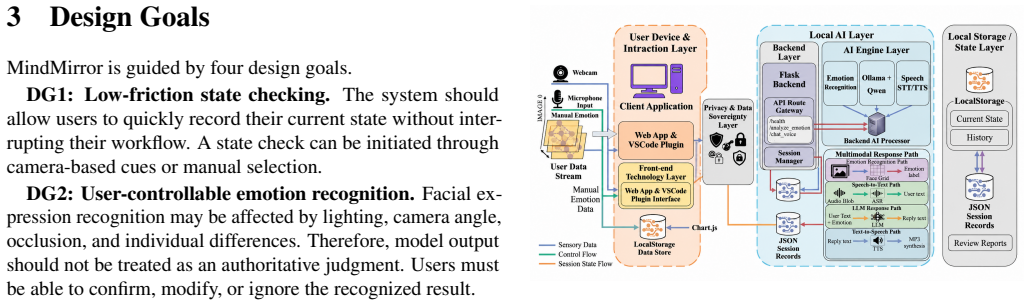
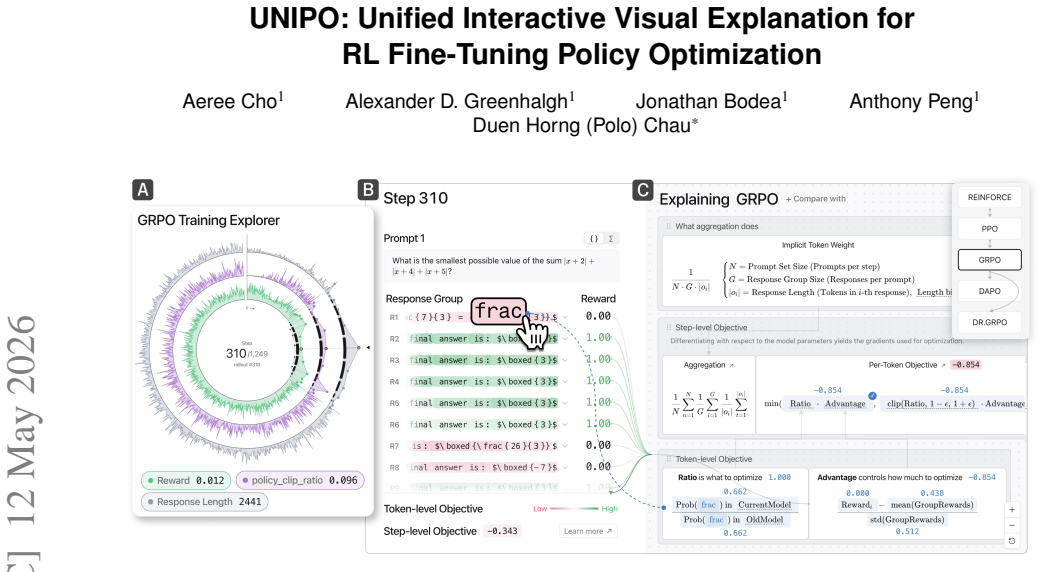
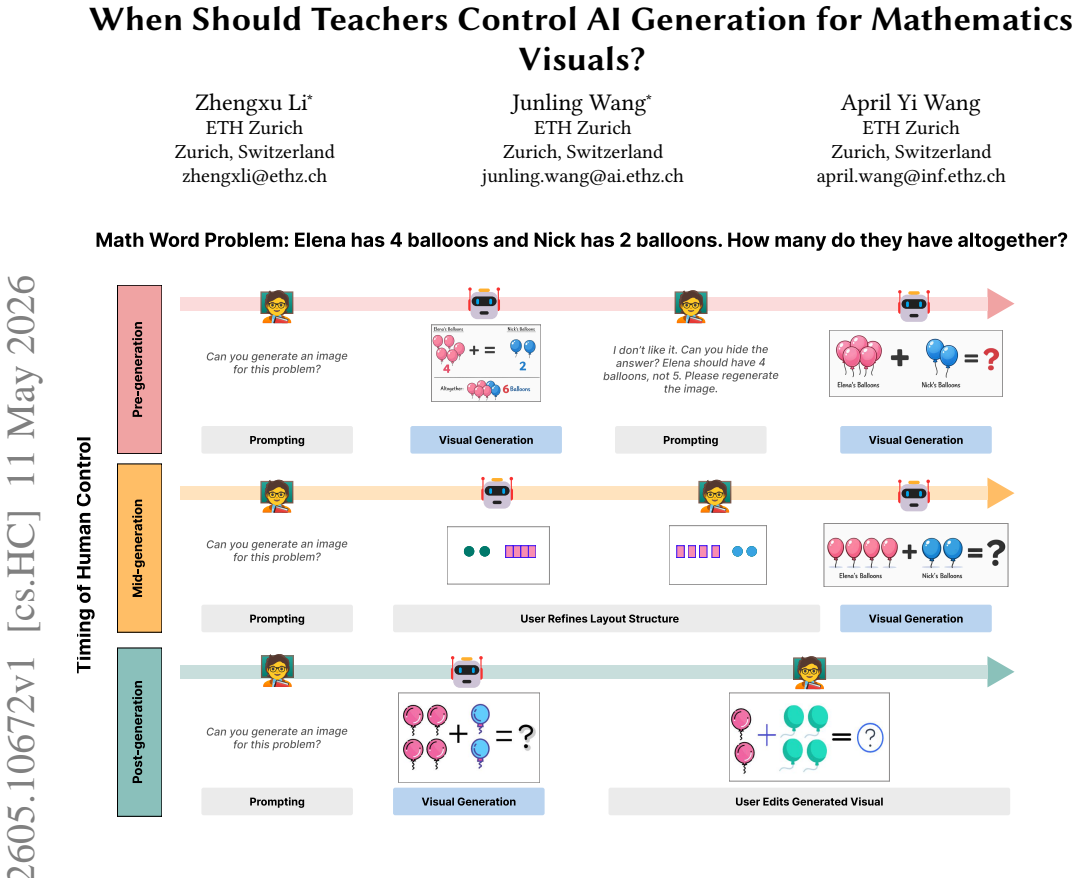
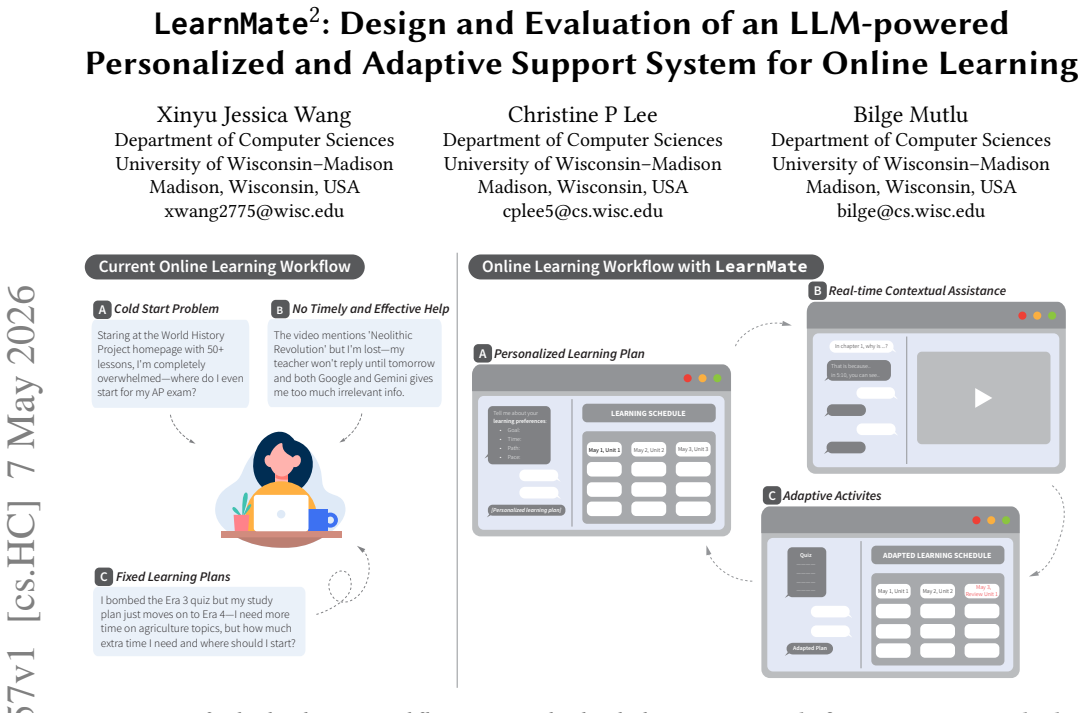
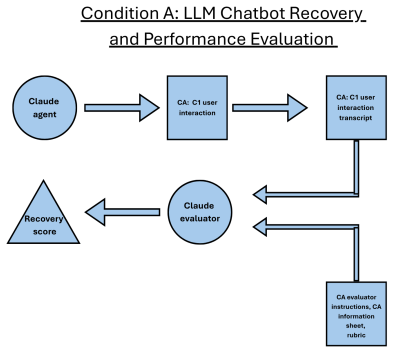
As AI tools become embedded in productivity and self-improvement contexts, a pressing question emerges: what happens when AI does the goal-setting for us? While large language models can generate goals that are objectively well-formed, the motivational consequences of delegating this cognitively and emotionally significant task remain unknown. In a preregistered experiment (N = 470), we compared self-authored goals against LLM-authored goals derived from a personal reflection. Although LLM-generated goals scored higher on SMART criteria (specificity, measurability, achievability, relevance, and time-boundedness; d = 2.26), participants in the LLM condition reported lower psychological ownership (d = 1.38), commitment (d = 1.19), and perceived importance (d = 1.13). At two-week follow-up, 72.8% of self-authored participants had acted on two or more of their goals, compared to 46.6% in the LLM condition. Mediation analyses identified psychological ownership as the mechanism: it mediated the authorship effect on every downstream motivational and behavioral outcome, while objective goal quality did not. Critically, individuals low in trait self-efficacy, those most likely to seek AI assistance, experienced the steepest ownership erosion. These findings reveal a quality-motivation dissociation in AI-assisted goal-setting and identify authorship preservation as a design priority for AI tools deployed in identity-relevant, behavior-dependent tasks.