Primus: Enforcing Attention Usage for 3D Medical Image Segmentation
Pith reviewed 2026-05-23 01:19 UTC · model grok-4.3
The pith
Pure Transformer models without convolutional blocks now match or beat top CNNs on 3D medical image segmentation benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
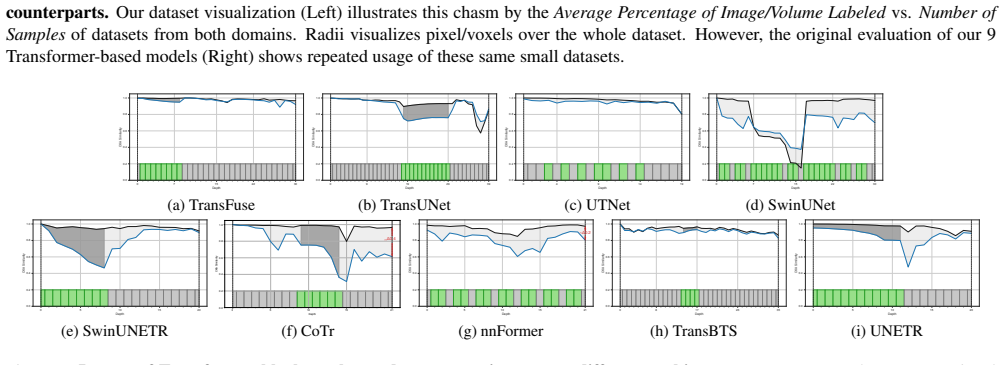
Current Transformer segmentation models are limited because they over-rely on convolutional blocks; performance often stays the same when the Transformer blocks are removed. By moving to fully Transformer-centric designs called Primus (high-resolution tokens plus advances in positional embeddings and block design) and PrimusV2 (adding iterative patch embedding), the authors produce the first models that surpass prior Transformer hybrids, compete with a default nnU-Net, and match state-of-the-art CNNs such as ResEnc-L and MedNeXt on nine public datasets, thereby establishing competitive Transformer-centric segmentation.
What carries the argument
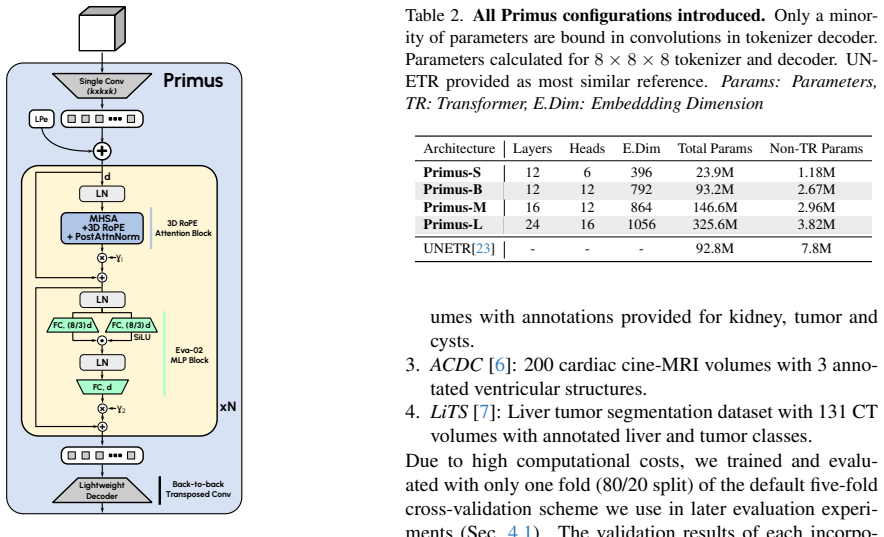
Primus and PrimusV2 architectures that enforce attention usage by removing all convolutional blocks and relying on high-resolution tokens, refined positional embeddings, and iterative patch embedding.
If this is right
- Primus already exceeds earlier Transformer hybrids and matches a default nnU-Net.
- PrimusV2 further surpasses the nnU-Net baseline and reaches parity with leading CNNs across nine datasets.
- Transformers can now be treated as a viable, state-of-the-art backbone for 3D medical segmentation without hybrid crutches.
- Future scaling of these models becomes possible because they no longer hide their capacity inside convolutional layers.
Where Pith is reading between the lines
- If the same enforcement principle applies to other dense-prediction tasks, pure attention models could replace hybrids in video or 3D reconstruction as well.
- The result suggests that earlier comparisons between Transformers and CNNs in medical imaging were confounded by incomplete use of attention, so re-evaluations with forced-attention baselines may be needed.
- Practitioners could now test whether large-scale self-supervised pre-training on unlabeled volumes yields larger gains for Primus-style models than it did for hybrids.
Load-bearing premise
That the measured gains come from forcing the model to use attention rather than from any uncontrolled differences in training schedule, data augmentation, or hyper-parameters between Primus and the baselines it is compared against.
What would settle it
Retrain the strongest prior hybrid Transformer models using exactly the same training schedule, augmentation pipeline, and hyper-parameters as PrimusV2; if they still lag behind, the claim that architecture alone explains the gap would be weakened.
Figures





read the original abstract
Transformers have achieved remarkable success across multiple fields, yet their impact on 3D medical image segmentation remains limited with convolutional networks still dominating major benchmarks. In this work, (A) we analyze current Transformer-based segmentation models and identify critical shortcomings, particularly their over-reliance on convolutional blocks. Further, we demonstrate that in some architectures, performance is unaffected by the absence of the Transformer, thereby demonstrating their limited effectiveness. To address these challenges, we move away from hybrid architectures and (B) introduce Transformer-centric segmentation architectures, termed Primus and PrimusV2. Primus leverages high-resolution tokens, combined with advances in positional embeddings and block design, to maximally leverage its Transformer blocks, while PrimusV2 expands on this through an iterative patch embedding. Through these adaptations, Primus surpasses current Transformer-based methods and competes with a default nnU-Net while PrimusV2 exceeds it and is on par with the state-of-the-art CNNs such as ResEnc-L and MedNeXt architectures across nine public datasets. In doing so, we introduce the first competitive Transformer-centric model, making Transformers state-of-the-art in 3D medical image segmentation. The code is available here: https://github.com/MIC-DKFZ/nnUNet/blob/master/documentation/primus.md.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper analyzes limitations in existing Transformer-based 3D medical image segmentation models, particularly their over-reliance on convolutional blocks and cases where performance is unaffected by removing the Transformer component. It introduces two Transformer-centric architectures, Primus and PrimusV2, that use high-resolution tokens, advances in positional embeddings and block design, and (for PrimusV2) iterative patch embedding to enforce attention usage. These are reported to surpass prior Transformer-based methods, compete with or exceed a default nnU-Net, and match SOTA CNNs (ResEnc-L, MedNeXt) across nine public datasets, establishing the first competitive pure-Transformer model and making Transformers state-of-the-art in the domain. Code is released.
Significance. If the performance gains are shown to arise specifically from the architectural mechanisms that enforce attention usage under matched training conditions, the work would be significant: it would provide the first credible demonstration that a pure Transformer can reach or exceed the performance of dominant CNN and hybrid models on standard 3D medical segmentation benchmarks. The public code release is a clear strength that enables direct verification and extension.
major comments (2)
- [Abstract] Abstract: the central claim that Primus/PrimusV2 gains are attributable to high-resolution tokens, positional embeddings, block design, and iterative patch embedding (i.e., to enforced attention usage) is load-bearing on the assumption that all compared models were trained under identical schedules, augmentations, optimizers, and hyperparameters; the abstract provides no statement that baselines were re-trained under the authors' protocol, leaving the attribution unestablished.
- [Abstract] Abstract / Experiments: no details are supplied on the number of runs, statistical testing (e.g., paired t-tests or Wilcoxon tests with correction), or variance across the nine datasets; without these, the reported ranking (PrimusV2 on par with ResEnc-L/MedNeXt) cannot be assessed for robustness.
minor comments (1)
- [Abstract] The GitHub link is given but the main text does not describe the exact repository structure or reproduction instructions, which would aid readers.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting the need for clearer statements on training protocols and experimental robustness. We will revise the abstract and experiments section to address these points directly. Our responses to the major comments follow.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that Primus/PrimusV2 gains are attributable to high-resolution tokens, positional embeddings, block design, and iterative patch embedding (i.e., to enforced attention usage) is load-bearing on the assumption that all compared models were trained under identical schedules, augmentations, optimizers, and hyperparameters; the abstract provides no statement that baselines were re-trained under the authors' protocol, leaving the attribution unestablished.
Authors: We agree the abstract should explicitly address the comparison protocol. In the manuscript, comparisons to prior Transformer-based methods use their originally published results; the nnU-Net is the default implementation from the nnU-Net framework; and ResEnc-L/MedNeXt results are from published benchmarks. Our models were trained under the protocol matching the default nnU-Net. We will revise the abstract to state this clearly and add a sentence noting that full re-training of all external baselines under identical conditions was not performed owing to computational cost, while the independent analysis of attention limitations (Section 3) stands on its own. revision: yes
-
Referee: [Abstract] Abstract / Experiments: no details are supplied on the number of runs, statistical testing (e.g., paired t-tests or Wilcoxon tests with correction), or variance across the nine datasets; without these, the reported ranking (PrimusV2 on par with ResEnc-L/MedNeXt) cannot be assessed for robustness.
Authors: We acknowledge the absence of these details. The manuscript reports results from single training runs per model per dataset, which is standard in this domain due to the high cost of 3D training. We will revise the abstract and add a dedicated paragraph in the experiments section stating the number of runs (one per configuration), confirming that formal statistical tests were not applied, and noting that consistent performance across nine heterogeneous datasets provides supporting evidence of robustness. Additional multi-seed variance experiments could be included if requested but would require substantial new compute. revision: partial
Circularity Check
No circularity: empirical architecture comparison with no derivation chain
full rationale
The paper introduces Primus and PrimusV2 as Transformer-centric 3D segmentation models and supports its claims solely through empirical benchmarking on nine public datasets, showing competitive or superior performance versus prior hybrids and CNNs. No equations, first-principles derivations, fitted parameters renamed as predictions, or self-citation load-bearing steps appear in the provided text. The central claim reduces to experimental results rather than any self-referential reduction of outputs to inputs by construction, making the derivation chain self-contained and non-circular.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Uni-Encoder Meets Multi-Encoders: Representation Before Fusion for Brain Tumor Segmentation with Missing Modalities
UniME combines a pretrained unified ViT encoder with modality-specific CNN encoders to improve brain tumor segmentation performance when some MRI modalities are missing.
Reference graph
Works this paper leans on
-
[1]
Trans- formers in time-series analysis: A tutorial
Sabeen Ahmed, Ian E Nielsen, Aakash Tripathi, Shamoon Siddiqui, Ravi P Ramachandran, and Ghulam Rasool. Trans- formers in time-series analysis: A tutorial. Circuits, Systems, and Signal Processing, pages 1–34, 2023. 1
work page 2023
-
[2]
Transformers in remote sens- ing: A survey
Abdulaziz Amer Aleissaee, Amandeep Kumar, Rao Muham- mad Anwer, Salman Khan, Hisham Cholakkal, Gui-Song Xia, and Fahad Shahbaz Khan. Transformers in remote sens- ing: A survey. Remote Sensing, 15(7):1860, 2023. 1
work page 2023
-
[3]
Object de- tection using deep learning, cnns and vision transformers: A review
Ayoub Benali Amjoud and Mustapha Amrouch. Object de- tection using deep learning, cnns and vision transformers: A review. IEEE Access, 2023. 16
work page 2023
-
[4]
Self-supervised learning from images with a joint-embedding predictive architecture
Mahmoud Assran, Quentin Duval, Ishan Misra, Piotr Bo- janowski, Pascal Vincent, Michael Rabbat, Yann LeCun, and Nicolas Ballas. Self-supervised learning from images with a joint-embedding predictive architecture. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15619–15629, 2023. 2
work page 2023
-
[5]
Pedro RAS Bassi, Wenxuan Li, Yucheng Tang, Fabian Isensee, Zifu Wang, Jieneng Chen, Yu-Cheng Chou, Yannick Kirchhoff, Maximilian Rokuss, Ziyan Huang, et al. Touch- stone benchmark: Are we on the right way for evaluating ai algorithms for medical segmentation? arXiv preprint arXiv:2411.03670, 2024. 1, 4
-
[6]
Olivier Bernard, Alain Lalande, Clement Zotti, Cervenansky, and et al. Deep learning techniques for automatic mri cardiac multi-structures segmentation and diagnosis: is the problem solved? IEEE TMI, 2018. 5
work page 2018
-
[7]
The liver tumor segmentation benchmark (lits)
Patrick Bilic, Patrick Christ, Hongwei Bran Li, Eugene V orontsov, Avi Ben-Cohen, Georgios Kaissis, Adi Szeskin, Colin Jacobs, Gabriel Efrain Humpire Mamani, Gabriel Chartrand, et al. The liver tumor segmentation benchmark (lits). Medical Image Analysis, 84:102680, 2023. 5
work page 2023
-
[8]
Swin-unet: Unet-like pure transformer for medical image segmentation
Hu Cao, Yueyue Wang, Joy Chen, Dongsheng Jiang, Xi- aopeng Zhang, Qi Tian, and Manning Wang. Swin-unet: Unet-like pure transformer for medical image segmentation. In European conference on computer vision, pages 205–218. Springer, 2022. 1, 2, 15, 17, 18
work page 2022
-
[9]
A survey on evaluation of large language models
Yupeng Chang, Xu Wang, Jindong Wang, Yuan Wu, Kaijie Zhu, Hao Chen, Linyi Yang, Xiaoyuan Yi, Cunxiang Wang, Yidong Wang, et al. A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109, 2023. 1
-
[10]
Transattunet: Multi-level attention- guided u-net with transformer for medical image segmenta- tion
Bingzhi Chen, Yishu Liu, Zheng Zhang, Guangming Lu, and Adams Wai Kin Kong. Transattunet: Multi-level attention- guided u-net with transformer for medical image segmenta- tion. IEEE Transactions on Emerging Topics in Computa- tional Intelligence, 2023. 17
work page 2023
-
[11]
TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation
Jieneng Chen, Yongyi Lu, Qihang Yu, Xiangde Luo, Ehsan Adeli, Yan Wang, Le Lu, Alan L. Yuille, and Yuyin Zhou. TransUNet: Transformers Make Strong Encoders for Medi- cal Image Segmentation. arXiv preprint arXiv:2102.04306,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Jieneng Chen, Jieru Mei, Xianhang Li, Yongyi Lu, Qihang Yu, Qingyue Wei, Xiangde Luo, Yutong Xie, Ehsan Adeli, Yan Wang, et al. Transunet: Rethinking the u-net architec- ture design for medical image segmentation through the lens of transformers. Medical Image Analysis, 97:103280, 2024. 1
work page 2024
-
[13]
Mask2former for video instance segmentation
Bowen Cheng, Anwesa Choudhuri, Ishan Misra, Alexan- der Kirillov, Rohit Girdhar, and Alexander G Schwing. Mask2former for video instance segmentation. arXiv preprint arXiv:2112.10764, 2021. 1
-
[14]
Per- pixel classification is not all you need for semantic segmen- tation
Bowen Cheng, Alex Schwing, and Alexander Kirillov. Per- pixel classification is not all you need for semantic segmen- tation. Advances in Neural Information Processing Systems, 34:17864–17875, 2021. 1
work page 2021
-
[15]
Vision Transformers Need Registers
Timoth ´ee Darcet, Maxime Oquab, Julien Mairal, and Pi- otr Bojanowski. Vision transformers need registers. arXiv preprint arXiv:2309.16588, 2023. 7 9
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Syl- vain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. In 9th International Conference on Learning Rep- resentations, ICLR. O...
work page 2021
-
[17]
Eva-02: A visual representation for neon genesis
Yuxin Fang, Quan Sun, Xinggang Wang, Tiejun Huang, Xin- long Wang, and Yue Cao. Eva-02: A visual representation for neon genesis. Image and Vision Computing, 149:105171,
-
[18]
Utnet: a hybrid transformer architecture for medical image segmen- tation
Yunhe Gao, Mu Zhou, and Dimitris N Metaxas. Utnet: a hybrid transformer architecture for medical image segmen- tation. In Medical Image Computing and Computer Assisted Intervention–MICCAI 2021: 24th International Conference, Strasbourg, France, September 27–October 1, 2021, Pro- ceedings, Part III 24 , pages 61–71. Springer, 2021. 2, 14, 15, 17, 18
work page 2021
-
[19]
Lidia Garrucho, Claire-Anne Reidel, Kaisar Kushibar, Sm- riti Joshi, Richard Osuala, Apostolia Tsirikoglou, Ma- ciej Bobowicz, Javier del Riego, Alessandro Catanese, Katarzyna Gwo ´zdziewicz, Maria-Laura Cosaka, Pasant M. Abo-Elhoda, Sara W. Tantawy, Shorouq S. Sakrana, Norhan O. Shawky-Abdelfatah, Amr Muhammad Abdo- Salem, Androniki Kozana, Eugen Divjak,...
work page 2024
-
[20]
Endre Grøvik, Darvin Yi, Michael Iv, Elizabeth Tong, Daniel Rubin, and Greg Zaharchuk. Deep learning enables au- tomatic detection and segmentation of brain metastases on multisequence mri. Journal of Magnetic Resonance Imag- ing, 51(1):175–182, 2020. 7
work page 2020
-
[21]
Developing general- ist foundation models from a multimodal dataset for 3d com- puted tomography
Ibrahim Ethem Hamamci, Sezgin Er, Furkan Almas, Ayse Gulnihan Simsek, Sevval Nil Esirgun, Irem Dogan, Muhammed Furkan Dasdelen, Omer Faruk Durugol, Bastian Wittmann, Tamaz Amiranashvili, et al. Developing general- ist foundation models from a multimodal dataset for 3d com- puted tomography. 2024. 2
work page 2024
-
[22]
Swin unetr: Swin transformers for semantic segmentation of brain tumors in mri images
Ali Hatamizadeh, Vishwesh Nath, Yucheng Tang, Dong Yang, Holger R Roth, and Daguang Xu. Swin unetr: Swin transformers for semantic segmentation of brain tumors in mri images. In International MICCAI Brainlesion Workshop, pages 272–284. Springer, 2021. 1, 2, 7, 8, 15, 16, 17, 18
work page 2021
-
[23]
Unetr: Transformers for 3d med- ical image segmentation
Ali Hatamizadeh, Yucheng Tang, Vishwesh Nath, Dong Yang, Andriy Myronenko, Bennett Landman, Holger R Roth, and Daguang Xu. Unetr: Transformers for 3d med- ical image segmentation. In Proceedings of the IEEE/CVF winter conference on applications of computer vision, pages 574–584, 2022. 1, 2, 4, 5, 7, 8, 15, 16, 17, 18
work page 2022
-
[24]
Masked autoencoders are scalable vision learners
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Doll´ar, and Ross Girshick. Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages 16000– 16009, 2022. 2
work page 2022
-
[25]
Transformers in medical image analysis
Kelei He, Chen Gan, Zhuoyuan Li, Islem Rekik, Zihao Yin, Wen Ji, Yang Gao, Qian Wang, Junfeng Zhang, and Ding- gang Shen. Transformers in medical image analysis. Intelli- gent Medicine, 3(1):59–78, 2023. 17
work page 2023
-
[26]
Yufan He, Vishwesh Nath, Dong Yang, Yucheng Tang, An- driy Myronenko, and Daguang Xu. Swinunetr-v2: Stronger swin transformers with stagewise convolutions for 3d med- ical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Interven- tion, pages 416–426. Springer, 2023. 1
work page 2023
-
[27]
Nicholas Heller, Niranjan Sathianathen, Arveen Kalapara, Edward Walczak, Keenan Moore, Heather Kaluzniak, Joel Rosenberg, Paul Blake, Zachary Rengel, Makinna Oestre- ich, et al. The kits19 challenge data: 300 kidney tumor cases with clinical context, ct semantic segmentations, and surgi- cal outcomes. arXiv preprint arXiv:1904.00445 , 2019. 2, 15
-
[28]
Nicholas Heller, Fabian Isensee, Dasha Trofimova, Re- sha Tejpaul, and et al. The kits21 challenge: Automatic segmentation of kidneys, renal tumors, and renal cysts in corticomedullary-phase ct, 2023. 5
work page 2023
-
[29]
Missformer: An effective medical image segmentation transformer
Xiaohong Huang, Zhifang Deng, Dandan Li, and Xueguang Yuan. Missformer: An effective medical image segmentation transformer. arXiv preprint arXiv:2109.07162, 2021. 17
-
[30]
Ziyan Huang, Haoyu Wang, Zhongying Deng, Jin Ye, Yanzhou Su, Hui Sun, Junjun He, Yun Gu, Lixu Gu, Shaot- ing Zhang, et al. Stu-net: Scalable and transferable med- ical image segmentation models empowered by large-scale supervised pre-training. arXiv preprint arXiv:2304.06716 ,
-
[31]
Chexpert: A large chest radiograph dataset with uncertainty labels and expert comparison
Jeremy Irvin, Pranav Rajpurkar, Michael Ko, Yifan Yu, Sil- viana Ciurea-Ilcus, Chris Chute, Henrik Marklund, Behzad Haghgoo, Robyn Ball, Katie Shpanskaya, et al. Chexpert: A large chest radiograph dataset with uncertainty labels and expert comparison. In Proceedings of the AAAI conference on artificial intelligence, pages 590–597, 2019. 2
work page 2019
-
[32]
Fabian Isensee, Paul F. Jaeger, Simon A.A. Kohl, Jens Petersen, and Klaus H. Maier-Hein. nnU-Net: a self- configuring method for deep learning-based biomedical im- age segmentation. Nature Methods, 18(2):203–211, 2021. 1, 2, 3, 7, 8, 14, 15, 17, 19
work page 2021
-
[33]
nnu-net revisited: A call for rigorous validation in 3d medical image segmentation
Fabian Isensee, Tassilo Wald, Constantin Ulrich, Michael Baumgartner, Saikat Roy, Klaus Maier-Hein, and Paul F Jaeger. nnu-net revisited: A call for rigorous validation in 3d medical image segmentation. In International Confer- ence on Medical Image Computing and Computer-Assisted Intervention, pages 488–498. Springer, 2024. 1, 2, 4, 5, 7, 8, 15, 16
work page 2024
-
[34]
Amos: A large-scale abdominal multi- organ benchmark for versatile medical image segmentation
Yuanfeng Ji, Haotian Bai, Chongjian Ge, Jie Yang, Ye Zhu, Ruimao Zhang, Zhen Li, Lingyan Zhanng, Wanling Ma, Xiang Wan, et al. Amos: A large-scale abdominal multi- organ benchmark for versatile medical image segmentation. Advances in Neural Information Processing Systems , 35: 36722–36732, 2022. 5, 15
work page 2022
-
[35]
Bitr-unet: a cnn-transformer com- bined network for mri brain tumor segmentation
Qiran Jia and Hai Shu. Bitr-unet: a cnn-transformer com- bined network for mri brain tumor segmentation. In Interna- 10 tional MICCAI Brainlesion Workshop, pages 3–14. Springer,
-
[36]
Swinbts: A method for 3d mul- timodal brain tumor segmentation using swin transformer
Yun Jiang, Yuan Zhang, Xin Lin, Jinkun Dong, Tongtong Cheng, and Jing Liang. Swinbts: A method for 3d mul- timodal brain tumor segmentation using swin transformer. Brain sciences, 12(6):797, 2022. 17
work page 2022
-
[37]
Mimic-cxr, a de- identified publicly available database of chest radiographs with free-text reports
Alistair EW Johnson, Tom J Pollard, Seth J Berkowitz, Nathaniel R Greenbaum, Matthew P Lungren, Chih-ying Deng, Roger G Mark, and Steven Horng. Mimic-cxr, a de- identified publicly available database of chest radiographs with free-text reports. Scientific data, 6(1):317, 2019. 2
work page 2019
-
[38]
Transformers in medical image segmentation: a narrative re- view
Rabeea Fatma Khan, Byoung-Dai Lee, and Mu Sook Lee. Transformers in medical image segmentation: a narrative re- view. Quantitative Imaging in Medicine and Surgery, 13(12): 8747, 2023. 2
work page 2023
-
[39]
Transformers in vision: A survey
Salman Khan, Muzammal Naseer, Munawar Hayat, Syed Waqas Zamir, Fahad Shahbaz Khan, and Mubarak Shah. Transformers in vision: A survey. ACM computing surveys (CSUR), 54(10s):1–41, 2022. 1, 16
work page 2022
-
[40]
Similarity of neural network representa- tions revisited
Simon Kornblith, Mohammad Norouzi, Honglak Lee, and Geoffrey Hinton. Similarity of neural network representa- tions revisited. In 36th International Conference on Machine Learning, ICML 2019, pages 6156–6175, 2019. 25
work page 2019
-
[41]
Miccai multi-atlas la- beling beyond the cranial vault–workshop and challenge
Bennett Landman, Zhoubing Xu, J Igelsias, Martin Styner, T Langerak, and Arno Klein. Miccai multi-atlas la- beling beyond the cranial vault–workshop and challenge. In Proc. MICCAI Multi-Atlas Labeling Beyond Cranial Vault—Workshop Challenge , page 12, 2015. 15
work page 2015
-
[42]
A systematic collection of medical image datasets for deep learning
Johann Li, Guangming Zhu, Cong Hua, Mingtao Feng, Ping Li, Xiaoyuan Lu, Juan Song, Peiyi Shen, Xu Xu, Lin Mei, et al. A systematic collection of medical image datasets for deep learning. arXiv preprint arXiv:2106.12864 , 2021. 4, 17, 24
-
[43]
Wenxuan Li, Chongyu Qu, Xiaoxi Chen, Pedro RAS Bassi, Yijia Shi, Yuxiang Lai, Qian Yu, Huimin Xue, Yixiong Chen, Xiaorui Lin, et al. Abdomenatlas: A large-scale, detailed- annotated, & multi-center dataset for efficient transfer learn- ing and open algorithmic benchmarking. Medical Image Analysis, 97:103285, 2024. 4, 24
work page 2024
-
[44]
Transformer for object detection: Review and benchmark
Yong Li, Naipeng Miao, Liangdi Ma, Feng Shuang, and Xingwen Huang. Transformer for object detection: Review and benchmark. Engineering Applications of Artificial Intel- ligence, 126:107021, 2023. 16
work page 2023
-
[45]
Sook-Lei Liew, Bethany P Lo, Miranda R Donnelly, Artemis Zavaliangos-Petropulu, Jessica N Jeong, Giuseppe Barisano, Alexandre Hutton, Julia P Simon, Julia M Juliano, Anisha Suri, et al. A large, curated, open-source stroke neuroimag- ing dataset to improve lesion segmentation algorithms. Sci- entific data, 9(1):320, 2022. 7
work page 2022
-
[46]
Ds-transunet: Dual swin transformer u-net for medical image segmentation
Ailiang Lin, Bingzhi Chen, Jiayu Xu, Zheng Zhang, Guang- ming Lu, and David Zhang. Ds-transunet: Dual swin transformer u-net for medical image segmentation. IEEE Transactions on Instrumentation and Measurement , 71:1– 15, 2022. 17
work page 2022
-
[47]
A survey on deep learning in medical image analysis
Geert Litjens, Thijs Kooi, Babak Ehteshami Bejnordi, Ar- naud Arindra Adiyoso Setio, Francesco Ciompi, Mohsen Ghafoorian, Jeroen Awm Van Der Laak, Bram Van Gin- neken, and Clara I S ´anchez. A survey on deep learning in medical image analysis. Medical image analysis, 42:60–88,
-
[48]
Efficient training of visual trans- formers with small datasets
Yahui Liu, Enver Sangineto, Wei Bi, Nicu Sebe, Bruno Lepri, and Marco Nadai. Efficient training of visual trans- formers with small datasets. Advances in Neural Information Processing Systems, 34:23818–23830, 2021. 4, 23
work page 2021
-
[49]
A survey of visual transformers
Yang Liu, Yao Zhang, Yixin Wang, Feng Hou, Jin Yuan, Jiang Tian, Yang Zhang, Zhongchao Shi, Jianping Fan, and Zhiqiang He. A survey of visual transformers. IEEE Trans- actions on Neural Networks and Learning Systems, 2023. 16
work page 2023
-
[50]
Swin transformer: Hierarchical vision transformer using shifted windows
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF international conference on computer vision, pages 10012–10022, 2021. 17
work page 2021
-
[51]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101, 2017. 14
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[52]
Xiangde Luo, Wenjun Liao, Jianghong Xiao, Jieneng Chen, Tao Song, Xiaofan Zhang, Kang Li, Dimitris N Metaxas, Guotai Wang, and Shaoting Zhang. Word: A large scale dataset, benchmark and clinical applicable study for abdom- inal organ segmentation from ct image.Medical Image Anal- ysis, 82:102642, 2022. 7
work page 2022
-
[53]
Jun Ma, Yao Zhang, Song Gu, Cheng Ge, Ershuai Wang, Qin Zhou, Ziyan Huang, Pengju Lyu, Jian He, and Bo Wang. Au- tomatic organ and pan-cancer segmentation in abdomen ct: the flare 2023 challenge. arXiv preprint arXiv:2408.12534,
-
[54]
Thao Nguyen, Maithra Raghu, and Simon Kornblith. Do wide and deep networks learn the same things? uncover- ing how neural network representations vary with width and depth. arXiv preprint arXiv:2010.15327, 2020. 25
-
[55]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[56]
A robust volumetric transformer for accurate 3d tumor segmentation
Himashi Peiris, Munawar Hayat, Zhaolin Chen, Gary Egan, and Mehrtash Harandi. A robust volumetric transformer for accurate 3d tumor segmentation. In International Confer- ence on Medical Image Computing and Computer-Assisted Intervention, pages 162–172. Springer, 2022. 17
work page 2022
-
[57]
U-net transformer: Self and cross attention for medical image segmentation
Olivier Petit, Nicolas Thome, Clement Rambour, Loic The- myr, Toby Collins, and Luc Soler. U-net transformer: Self and cross attention for medical image segmentation. In Machine Learning in Medical Imaging: 12th International Workshop, MLMI 2021, Held in Conjunction with MICCAI 2021, Strasbourg, France, September 27, 2021, Proceedings 12, pages 267–276. S...
work page 2021
-
[58]
Irada Pfl ¨uger, Tassilo Wald, Fabian Isensee, Marianne Schell, Hagen Meredig, Kai Schlamp, Denise Bernhardt, Gi- anluca Brugnara, Claus Peter Heußel, Juergen Debus, et al. Automated detection and quantification of brain metastases on clinical mri data using artificial neural networks. Neuro- oncology advances, 4(1):vdac138, 2022. 8
work page 2022
-
[59]
Abdomenatlas-8k: An- notating 8,000 ct volumes for multi-organ segmentation in 11 three weeks
Chongyu Qu, Tiezheng Zhang, Hualin Qiao, Yucheng Tang, Alan L Yuille, Zongwei Zhou, et al. Abdomenatlas-8k: An- notating 8,000 ct volumes for multi-organ segmentation in 11 three weeks. Advances in Neural Information Processing Systems, 36, 2024. 4, 24
work page 2024
-
[60]
Mednext: transformer-driven scal- ing of convnets for medical image segmentation
Saikat Roy, Gregor Koehler, Constantin Ulrich, Michael Baumgartner, Jens Petersen, Fabian Isensee, Paul F Jaeger, and Klaus H Maier-Hein. Mednext: transformer-driven scal- ing of convnets for medical image segmentation. In In- ternational Conference on Medical Image Computing and Computer-Assisted Intervention , pages 405–415. Springer,
-
[61]
Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, San- jeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, Alexander C. Berg, and Li Fei-Fei. ImageNet Large Scale Visual Recognition Chal- lenge. International Journal of Computer Vision (IJCV), 115 (3):211–252, 2015. 23
work page 2015
-
[62]
Transformers in medical imaging: A survey
Fahad Shamshad, Salman Khan, Syed Waqas Zamir, Muhammad Haris Khan, Munawar Hayat, Fahad Shahbaz Khan, and Huazhu Fu. Transformers in medical imaging: A survey. Medical Image Analysis, page 102802, 2023. 17
work page 2023
-
[63]
The curious case of absolute position embeddings.arXiv preprint arXiv:2210.12574, 2022
Koustuv Sinha, Amirhossein Kazemnejad, Siva Reddy, Joelle Pineau, Dieuwke Hupkes, and Adina Williams. The curious case of absolute position embeddings.arXiv preprint arXiv:2210.12574, 2022. 6
-
[64]
Feature selection via dependence maxi- mization
Le Song, Alex Smola, Arthur Gretton, Justin Bedo, and Karsten Borgwardt. Feature selection via dependence maxi- mization. Journal of Machine Learning Research, 13:1393– 1434, 2012. 25
work page 2012
-
[65]
Raphael Stock, Stefan Denner, Yannick Kirchhoff, Con- stantin Ulrich, Maximilian Rouven Rokuss, Saikat Roy, Nico Disch, and Klaus Maier-Hein. From generalist to specialist: Incorporating domain-knowledge into flamingo for chest x- ray report generation. In Medical Imaging with Deep Learn- ing, 2024. 2
work page 2024
-
[66]
Segmenter: Transformer for semantic segmenta- tion
Robin Strudel, Ricardo Garcia, Ivan Laptev, and Cordelia Schmid. Segmenter: Transformer for semantic segmenta- tion. In Proceedings of the IEEE/CVF international confer- ence on computer vision, pages 7262–7272, 2021. 16
work page 2021
-
[67]
Roformer: Enhanced transformer with rotary position embedding
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding. Neurocomputing, 568:127063,
-
[68]
Revisiting unreasonable effectiveness of data in deep learning era
Chen Sun, Abhinav Shrivastava, Saurabh Singh, and Abhi- nav Gupta. Revisiting unreasonable effectiveness of data in deep learning era. In 2017 IEEE International Conference on Computer Vision (ICCV), pages 843–852, 2017. 23
work page 2017
-
[69]
Self-supervised pre-training of swin trans- formers for 3d medical image analysis
Yucheng Tang, Dong Yang, Wenqi Li, Holger R Roth, Bennett Landman, Daguang Xu, Vishwesh Nath, and Ali Hatamizadeh. Self-supervised pre-training of swin trans- formers for 3d medical image analysis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20730–20740, 2022. 17
work page 2022
-
[70]
Training data-efficient image transformers & distillation through at- tention
Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, and Herv ´e J´egou. Training data-efficient image transformers & distillation through at- tention. In International conference on machine learning , pages 10347–10357. PMLR, 2021. 1, 4
work page 2021
-
[71]
Going deeper with im- age transformers
Hugo Touvron, Matthieu Cord, Alexandre Sablayrolles, Gabriel Synnaeve, and Herv´e J´egou. Going deeper with im- age transformers. In Proceedings of the IEEE/CVF interna- tional conference on computer vision, pages 32–42, 2021. 6
work page 2021
-
[72]
Hugo Touvron, Matthieu Cord, and Herv ´e J ´egou. Deit iii: Revenge of the vit. In European conference on computer vision, pages 516–533. Springer, 2022. 4
work page 2022
-
[73]
Multitalent: A multi-dataset approach to medical image seg- mentation
Constantin Ulrich, Fabian Isensee, Tassilo Wald, Maximil- ian Zenk, Michael Baumgartner, and Klaus H Maier-Hein. Multitalent: A multi-dataset approach to medical image seg- mentation. arXiv preprint arXiv:2303.14444, 2023. 2, 24
-
[74]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention Is All You Need. IEEE Industry Ap- plications Magazine, 8(1):8–15, 2017. 1
work page 2017
-
[75]
Transbts: Multimodal brain tumor seg- mentation using transformer
Wenxuan Wang, Chen Chen, Meng Ding, Hong Yu, Sen Zha, and Jiangyun Li. Transbts: Multimodal brain tumor seg- mentation using transformer. In Medical Image Computing and Computer Assisted Intervention–MICCAI 2021: 24th In- ternational Conference, Strasbourg, France, September 27– October 1, 2021, Proceedings, Part I 24 , pages 109–119. Springer, 2021. 1, 2...
work page 2021
-
[76]
Medclip: Contrastive learning from unpaired medical images and text
Zifeng Wang, Zhenbang Wu, Dinesh Agarwal, and Jimeng Sun. Medclip: Contrastive learning from unpaired medical images and text. arXiv preprint arXiv:2210.10163, 2022. 2
-
[77]
URL http://arxiv.org/abs/2208.05868
Jakob Wasserthal, M. Meyer, Hanns-Christian Breit, Joshy Cyriac, Shan Yang, and Martin Segeroth. Totalsegmentator: robust segmentation of 104 anatomical structures in ct im- ages. ArXiv, abs/2208.05868, 2022. 2, 4, 15, 24
-
[78]
High-resolution swin transformer for automatic medical image segmentation
Chen Wei, Shenghan Ren, Kaitai Guo, Haihong Hu, and Jimin Liang. High-resolution swin transformer for automatic medical image segmentation. Sensors, 23(7):3420, 2023. 5
work page 2023
-
[79]
D-former: A u- shaped dilated transformer for 3d medical image segmenta- tion
Yixuan Wu, Kuanlun Liao, Jintai Chen, Jinhong Wang, Danny Z Chen, Honghao Gao, and Jian Wu. D-former: A u- shaped dilated transformer for 3d medical image segmenta- tion. Neural Computing and Applications, 35(2):1931–1944,
work page 1931
-
[80]
Transformers in medical image segmentation: A review
Hanguang Xiao, Li Li, Qiyuan Liu, Xiuhong Zhu, and Qi- hang Zhang. Transformers in medical image segmentation: A review. Biomedical Signal Processing and Control , 84: 104791, 2023. 17
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.