Beyond the Edge of Function: Unraveling the Patterns of Type Recovery in Binary Code
Pith reviewed 2026-05-23 01:04 UTC · model grok-4.3
The pith
ByteTR leads state-of-the-art in recovering variable types from binary code through inter-procedural data flow analysis.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
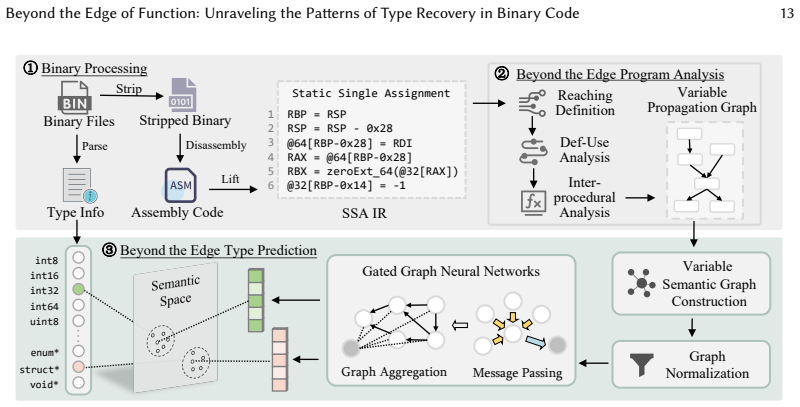
ByteTR leads state-of-the-art works in both effectiveness and efficiency. In real CTF challenge cases, the pseudo code optimized by ByteTR significantly improves readability, surpassing leading tools IDA and Ghidra. The framework decouples the target type set, performs static program analysis for compiler optimization impacts, conducts inter-procedural analysis to trace variable propagation, and employs a gated graph neural network to capture long-range data flow dependencies.
What carries the argument
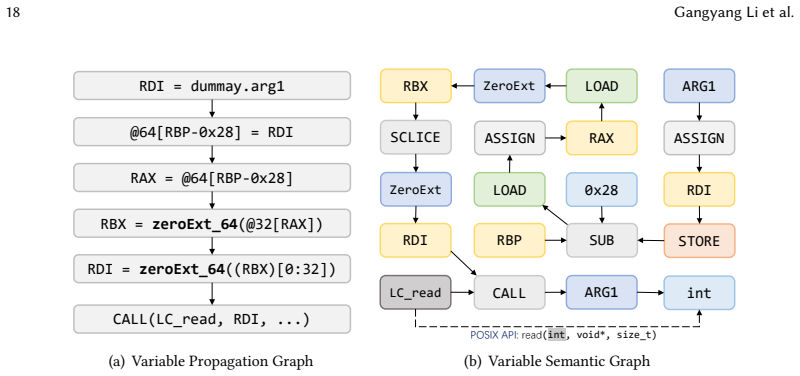
Inter-procedural analysis combined with a gated graph neural network to trace variable propagation and capture data flow dependencies across functions, after decoupling the type set and static analysis.
If this is right
- ByteTR achieves superior effectiveness and efficiency compared to existing type recovery methods.
- The approach handles unbalanced type distributions and the effects of compiler optimizations.
- Optimized pseudo code from ByteTR offers better readability in practical reverse engineering scenarios like CTF challenges.
- Variable type recovery benefits from considering propagation beyond individual functions.
Where Pith is reading between the lines
- The empirical patterns identified could guide similar studies for other binary analysis tasks such as control flow recovery.
- Extending the inter-procedural tracing might further improve performance on heavily optimized or obfuscated code.
- The method's success on four architectures suggests potential for broader applicability in cross-platform analysis.
Load-bearing premise
The TYDA dataset fully reflects the complexity and diversity of real-world programs.
What would settle it
Running ByteTR and competing tools on a new collection of binary programs compiled with different options or from different sources and measuring type recovery accuracy against ground truth.
Figures





read the original abstract
Type recovery is a crucial step in binary code analysis, holding significant importance for reverse engineering and various security applications. Existing works typically simply target type identifiers within binary code and achieve type recovery by analyzing variable characteristics within functions. However, we find that the types in real-world binary programs are more complex and often follow specific distribution patterns. In this paper, to gain a profound understanding of the variable type recovery problem in binary code, we first conduct a comprehensive empirical study. We utilize the TYDA dataset, which includes 163,643 binary programs across four architectures and four compiler optimization options, fully reflecting the complexity and diversity of real-world programs. We carefully study the unique patterns that characterize types and variables in binary code, and also investigate the impact of compiler optimizations on them, yielding many valuable insights. Based on our empirical findings, we propose ByteTR, a framework for recovering variable types in binary code. We decouple the target type set to address the issue of unbalanced type distribution and perform static program analysis to tackle the impact of compiler optimizations on variable storage. In light of the ubiquity of variable propagation across functions observed in our study, ByteTR conducts inter-procedural analysis to trace variable propagation and employs a gated graph neural network to capture long-range data flow dependencies for variable type recovery. We conduct extensive experiments to evaluate the performance of ByteTR. The results demonstrate that ByteTR leads state-of-the-art works in both effectiveness and efficiency. Moreover, in real CTF challenge case, the pseudo code optimized by ByteTR significantly improves readability, surpassing leading tools IDA and Ghidra.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports an empirical study of variable type recovery in stripped binaries using the TYDA corpus (163643 programs, four architectures, four optimization levels). It identifies distribution patterns and compiler-induced storage effects, then presents ByteTR: a pipeline that decouples the type vocabulary, performs static analysis to mitigate optimization artifacts, and applies inter-procedural gated graph neural networks to propagate type information across function boundaries. Experiments are said to show ByteTR outperforming prior work in both accuracy and speed; a CTF case study claims improved decompiler output readability relative to IDA and Ghidra.
Significance. If the empirical patterns and performance numbers are reproducible on representative corpora, the work would supply both diagnostic insights into type distributions and a concrete inter-procedural modeling technique that existing intra-procedural type-recovery systems largely omit. The explicit handling of compiler storage effects and the use of GGNNs for long-range data-flow are technically substantive contributions that could be adopted by production reverse-engineering tools.
major comments (2)
- [Abstract / TYDA description] Abstract and § on TYDA construction: the claim that the 163643-program corpus 'fully reflects the complexity and diversity of real-world programs' is load-bearing for every generalization and SOTA claim, yet the manuscript provides no sampling frame, inclusion criteria for stripped or obfuscated binaries, or quantitative comparison against the corpora used by prior type-recovery papers (e.g., those underlying EKLAVYA, TypeMiner, or DIRTY). Without this, the reported 'unique patterns' and ByteTR's measured superiority cannot be assessed for external validity.
- [Experiments / Evaluation] Experimental section (results tables): the abstract asserts leadership in 'effectiveness and efficiency' and superiority on a CTF case, but the provided text contains no precision/recall numbers, baseline implementations, ablation studies, or statistical significance tests. These omissions make it impossible to verify whether the inter-procedural GGNN component is responsible for the claimed gains or whether the results are driven by dataset artifacts.
minor comments (1)
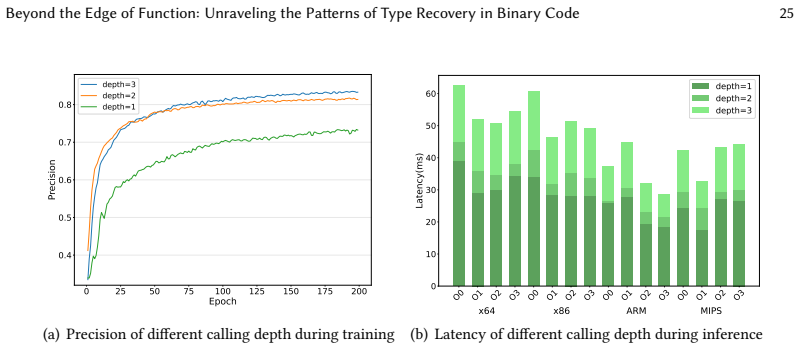
- [ByteTR architecture] Notation for the gated graph neural network message-passing equations should be expanded with explicit update and aggregation functions to allow replication.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. We address each major comment below and describe the revisions we will make to improve clarity and rigor.
read point-by-point responses
-
Referee: [Abstract / TYDA description] Abstract and § on TYDA construction: the claim that the 163643-program corpus 'fully reflects the complexity and diversity of real-world programs' is load-bearing for every generalization and SOTA claim, yet the manuscript provides no sampling frame, inclusion criteria for stripped or obfuscated binaries, or quantitative comparison against the corpora used by prior type-recovery papers (e.g., those underlying EKLAVYA, TypeMiner, or DIRTY). Without this, the reported 'unique patterns' and ByteTR's measured superiority cannot be assessed for external validity.
Authors: We agree that the current description of TYDA does not sufficiently document its construction to support the strong claim of representativeness. The dataset was assembled from open-source C/C++ projects compiled for the four architectures and optimization levels, with a focus on stripped binaries; however, explicit sampling frames, inclusion/exclusion criteria, and direct quantitative comparisons to the corpora of EKLAVYA, TypeMiner, and DIRTY are absent. We will revise the TYDA section to add these details (including a comparison table) and will moderate the abstract language from 'fully reflects the complexity and diversity of real-world programs' to 'captures substantial complexity and diversity across common architectures and optimization levels.' These changes will allow better evaluation of external validity. revision: yes
-
Referee: [Experiments / Evaluation] Experimental section (results tables): the abstract asserts leadership in 'effectiveness and efficiency' and superiority on a CTF case, but the provided text contains no precision/recall numbers, baseline implementations, ablation studies, or statistical significance tests. These omissions make it impossible to verify whether the inter-procedural GGNN component is responsible for the claimed gains or whether the results are driven by dataset artifacts.
Authors: We acknowledge that the experimental presentation must be strengthened for verifiability. While the manuscript reports comparative results and a CTF case study, we will expand the evaluation section to include (1) explicit precision/recall tables with all baselines, (2) ablation studies isolating the gated GNN and inter-procedural components, (3) references to baseline implementations, and (4) statistical significance tests. We will also add analysis addressing potential dataset artifacts by relating results back to the empirical patterns identified earlier in the paper. These additions will make the contribution of each ByteTR component clearer. revision: yes
Circularity Check
No circularity; empirical pipeline is self-contained
full rationale
The paper first collects and analyzes the external TYDA dataset of 163643 binaries to extract observed type-distribution patterns and compiler effects, then builds ByteTR by applying standard decoupling, static analysis, inter-procedural tracing, and GGNN components to those observations, and finally reports performance numbers on the same corpus. None of the load-bearing steps (pattern identification, model construction, or evaluation) reduce by definition or by self-citation to the target claims; the derivation remains independent of its own outputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Types in real-world binary programs follow specific distribution patterns that can be leveraged for recovery.
- domain assumption Variable propagation across functions is ubiquitous in binary code.
Reference graph
Works this paper leans on
-
[1]
How far we have come: Testing decompilation correctness of c decompilers
Zhibo Liu and Shuai Wang. How far we have come: Testing decompilation correctness of c decompilers. InProceedings of the 29th ACM SIGSOFT International Symposium on Software Testing and Analysis , pages 475–487, 2020
work page 2020
-
[2]
Arbiter: Bridging the static and dynamic divide in vulnerability discovery on binary programs
Jayakrishna Vadayath, Moritz Eckert, Kyle Zeng, Nicolaas Weideman, Gokulkrishna Praveen Menon, Yanick Fratantonio, Davide Balzarotti, Adam Doupé, Tiffany Bao, Ruoyu Wang, et al. Arbiter: Bridging the static and dynamic divide in vulnerability discovery on binary programs. In 31st USENIX Security Symposium (USENIX Security 22) , pages 413–430, 2022
work page 2022
-
[3]
Vulhawk: Cross-architecture vulnerability detection with entropy-based binary code search
Zhenhao Luo, Pengfei Wang, Baosheng Wang, Yong Tang, Wei Xie, Xu Zhou, Danjun Liu, and Kai Lu. Vulhawk: Cross-architecture vulnerability detection with entropy-based binary code search. In NDSS, 2023
work page 2023
-
[4]
When malware changed its mind: An empirical study of variable program behaviors in the real world
Erin Avllazagaj, Ziyun Zhu, Leyla Bilge, Davide Balzarotti, and Tudor Dumitras,. When malware changed its mind: An empirical study of variable program behaviors in the real world. In 30th USENIX Security Symposium (USENIX Security 21), pages 3487–3504, 2021
work page 2021
-
[5]
Lightweight, obfuscation-resilient detection and family iden- tification of android malware
Joshua Garcia, Mahmoud Hammad, and Sam Malek. Lightweight, obfuscation-resilient detection and family iden- tification of android malware. ACM Transactions on Software Engineering and Methodology (TOSEM) , 26(3):1–29, 2018
work page 2018
-
[6]
On benign features in malware detection
Michael Cao, Sahar Badihi, Khaled Ahmed, Peiyu Xiong, and Julia Rubin. On benign features in malware detection. In Proceedings of the 35th IEEE/ACM International Conference on Automated Software Engineering , pages 1234–1238, 2020
work page 2020
-
[7]
Airtaint: Making dynamic taint analysis faster and easier
Qian Sang, Yanhao Wang, Yuwei Liu, Xiangkun Jia, Tiffany Bao, and Purui Su. Airtaint: Making dynamic taint analysis faster and easier. In 2024 IEEE Symposium on Security and Privacy (SP) , pages 3998–4014. IEEE, 2024
work page 2024
-
[8]
Taintmini: Detecting flow of sensitive data in mini-programs with static taint analysis
Chao Wang, Ronny Ko, Yue Zhang, Yuqing Yang, and Zhiqiang Lin. Taintmini: Detecting flow of sensitive data in mini-programs with static taint analysis. In 2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE), pages 932–944. IEEE, 2023
work page 2023
-
[9]
Pata: Fuzzing with path aware taint analysis
Jie Liang, Mingzhe Wang, Chijin Zhou, Zhiyong Wu, Yu Jiang, Jianzhong Liu, Zhe Liu, and Jiaguang Sun. Pata: Fuzzing with path aware taint analysis. In 2022 IEEE Symposium on Security and Privacy (SP) , pages 1–17. IEEE, 2022
work page 2022
-
[10]
Hex-Rays SA. IDA Pro. https://www.hex-rays.com/products/ida, 2023
work page 2023
-
[11]
NationalSecurityAgency. Ghidra. https://github.com/NationalSecurityAgency/ghidra, 2023
work page 2023
- [12]
-
[13]
Recovery of class hierarchies and composition relationships from machine code
Venkatesh Srinivasan and Thomas Reps. Recovery of class hierarchies and composition relationships from machine code. In International Conference on Compiler Construction , pages 61–84. Springer, 2014
work page 2014
-
[14]
Schwartz, Claire Le Goues, Graham Neubig, and Bogdan Vasilescu
Qibin Chen, Jeremy Lacomis, Edward J. Schwartz, Claire Le Goues, Graham Neubig, and Bogdan Vasilescu. Augmenting decompiler output with learned variable names and types. In 31st USENIX Security Symposium , Boston, MA, August 2022
work page 2022
-
[15]
Stateformer: fine-grained type recovery from binaries using generative J
Kexin Pei, Jonas Guan, Matthew Broughton, Zhongtian Chen, Songchen Yao, David Williams-King, Vikas Ummadisetty, Junfeng Yang, Baishakhi Ray, and Suman Jana. Stateformer: fine-grained type recovery from binaries using generative J. ACM, Vol. 37, No. 4, Article . Publication date: July 2025. 30 Gangyang Li et al. state modeling. In Proceedings of the 29th A...
work page 2025
-
[16]
Debin: Predicting debug information in stripped binaries
Jingxuan He, Pesho Ivanov, Petar Tsankov, Veselin Raychev, and Martin Vechev. Debin: Predicting debug information in stripped binaries. In Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security , pages 1667–1680, 2018
work page 2018
-
[17]
Gated Graph Sequence Neural Networks
Yujia Li, Daniel Tarlow, Marc Brockschmidt, and Richard Zemel. Gated graph sequence neural networks.arXiv preprint arXiv:1511.05493, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[18]
{TYGR}: Type inference on stripped binaries using graph neural networks
Chang Zhu, Ziyang Li, Anton Xue, Ati Priya Bajaj, Wil Gibbs, Yibo Liu, Rajeev Alur, Tiffany Bao, Hanjun Dai, Adam Doupé, et al. {TYGR}: Type inference on stripped binaries using graph neural networks. In 33rd USENIX Security Symposium (USENIX Security 24) , pages 4283–4300, 2024
work page 2024
-
[19]
GNU Binutils. objdump. https://sourceware.org/binutils/docs/binutils/objdump.html, 2023
work page 2023
-
[20]
Llm4decompile: Decompiling binary code with large language models
Hanzhuo Tan, Qi Luo, Jing Li, and Yuqun Zhang. Llm4decompile: Decompiling binary code with large language models. arXiv preprint arXiv:2403.05286, 2024
-
[21]
Beyond the c: Retargetable decompilation using neural machine translation
Iman Hosseini and Brendan Dolan-Gavitt. Beyond the c: Retargetable decompilation using neural machine translation. arXiv preprint arXiv:2212.08950, 2022
-
[22]
Shouguo Yang, Zhengzi Xu, Yang Xiao, Zhe Lang, Wei Tang, Yang Liu, Zhiqiang Shi, Hong Li, and Limin Sun. Towards practical binary code similarity detection: Vulnerability verification via patch semantic analysis. ACM Transactions on Software Engineering and Methodology , 32(6):1–29, 2023
work page 2023
-
[23]
Shouguo Yang, Chaopeng Dong, Yang Xiao, Yiran Cheng, Zhiqiang Shi, Zhi Li, and Limin Sun. Asteria-pro: Enhancing deep learning-based binary code similarity detection by incorporating domain knowledge. ACM Trans. Softw. Eng. Methodol., 33(1), November 2023
work page 2023
-
[24]
A lightweight framework for function name reassignment based on large-scale stripped binaries
Han Gao, Shaoyin Cheng, Yinxing Xue, and Weiming Zhang. A lightweight framework for function name reassignment based on large-scale stripped binaries. In Proceedings of the 30th ACM SIGSOFT International Symposium on Software Testing and Analysis (ISSTA), ISSTA 2021. Association for Computing Machinery, 2021
work page 2021
-
[25]
Zirui Song, Jiongyi Chen, and Kehuan Zhang. Bin2summary: Beyond function name prediction in stripped binaries with functionality-specific code embeddings. Proc. ACM Softw. Eng., 1(FSE), July 2024
work page 2024
-
[26]
Palmtree: Learning an assembly language model for instruction embedding
Xuezixiang Li, Yu Qu, and Heng Yin. Palmtree: Learning an assembly language model for instruction embedding. In Proceedings of the 2021 ACM SIGSAC Conference on Computer and Communications Security , pages 3236–3251, 2021
work page 2021
-
[27]
Binary code similarity detection via graph contrastive learning on intermediate representations
Xiuwei Shang, Li Hu, Shaoyin Cheng, Guoqiang Chen, Benlong Wu, Weiming Zhang, and Nenghai Yu. Binary code similarity detection via graph contrastive learning on intermediate representations. arXiv preprint arXiv:2410.18561, 2024
-
[28]
Dire: A neural approach to decompiled identifier naming
Jeremy Lacomis, Pengcheng Yin, Edward Schwartz, Miltiadis Allamanis, Claire Le Goues, Graham Neubig, and Bogdan Vasilescu. Dire: A neural approach to decompiled identifier naming. In 2019 34th IEEE/ACM International Conference on Automated Software Engineering (ASE) , pages 628–639. IEEE, 2019
work page 2019
-
[29]
Steven T Piantadosi. Zipf’s word frequency law in natural language: A critical review and future directions.Psychonomic bulletin & review, 21:1112–1130, 2014
work page 2014
-
[30]
Applications and explanations of zipf’s law
David MW Powers. Applications and explanations of zipf’s law. In New methods in language processing and computa- tional natural language learning , 1998
work page 1998
-
[31]
Zipf’ s law and heaps’s law can predict the size of potential words
Yukie Sano, Hideki Takayasu, and Misako Takayasu. Zipf’ s law and heaps’s law can predict the size of potential words. Progress of Theoretical Physics Supplement , 194:202–209, 2012
work page 2012
-
[32]
Exploring regularity in source code: Software science and zipf’s law
Hongyu Zhang. Exploring regularity in source code: Software science and zipf’s law. In 2008 15th Working Conference on Reverse Engineering, pages 101–110. IEEE, 2008
work page 2008
-
[33]
Discovering power laws in computer programs
Hongyu Zhang. Discovering power laws in computer programs. Information processing & management , 45(4):477–483, 2009
work page 2009
-
[34]
Peter J Denning. The locality principle. Communications of the ACM, 48(7):19–24, 2005
work page 2005
-
[35]
Gcc, the gnu compiler collection, 2024
GNU Project. Gcc, the gnu compiler collection, 2024. Accessed: 2024-01-04
work page 2024
-
[36]
Unleashing the hidden power of compiler optimization on binary code difference: An empirical study
Xiaolei Ren, Michael Ho, Jiang Ming, Yu Lei, and Li Li. Unleashing the hidden power of compiler optimization on binary code difference: An empirical study. In Proceedings of the 42nd ACM SIGPLAN International Conference on Programming Language Design and Implementation , pages 142–157, 2021
work page 2021
-
[37]
Bincola: Diversity-sensitive contrastive learning for binary code similarity detection
Shuai Jiang, Cai Fu, Shuai He, Jianqiang Lv, Lansheng Han, and Hong Hu. Bincola: Diversity-sensitive contrastive learning for binary code similarity detection. IEEE Transactions on Software Engineering , 2024
work page 2024
-
[38]
Kuntal Kumar Pal, Ati Priya Bajaj, Pratyay Banerjee, Audrey Dutcher, Mutsumi Nakamura, Zion Leonahenahe Basque, Himanshu Gupta, Saurabh Arjun Sawant, Ujjwala Anantheswaran, Yan Shoshitaishvili, et al. len or index or count, anything but v1”: Predicting variable names in decompilation output with transfer learning. In 2024 IEEE Symposium on Security and Pr...
work page 2024
-
[39]
System V application binary interface: AMD64 architecture processor supplement
Michael Matz and Jan Hubicka and Andreas Jaeger and Mark Mitchell. System V application binary interface: AMD64 architecture processor supplement. Technical report, x86-64 ABI, 2018. Available at https://gitlab.com/x86-psABIs/x86- J. ACM, Vol. 37, No. 4, Article . Publication date: July 2025. Beyond the Edge of Function: Unraveling the Patterns of Type Re...
work page 2018
-
[40]
CEA IT Security. Miasm. https://github.com/cea-sec/miasm, 2023
work page 2023
-
[41]
A survey of data flow analysis techniques
Ken Kennedy. A survey of data flow analysis techniques . IBM Thomas J. Watson Research Division, 1979
work page 1979
-
[42]
Graph matching networks for learning the similarity of graph structured objects
Yujia Li, Chenjie Gu, Thomas Dullien, Oriol Vinyals, and Pushmeet Kohli. Graph matching networks for learning the similarity of graph structured objects. In International conference on machine learning , pages 3835–3845. PMLR, 2019
work page 2019
-
[43]
Exploring gnn based program embedding technologies for binary related tasks
Yixin Guo, Pengcheng Li, Yingwei Luo, Xiaolin Wang, and Zhenlin Wang. Exploring gnn based program embedding technologies for binary related tasks. In Proceedings of the 30th IEEE/ACM International Conference on Program Comprehension, pages 366–377, 2022
work page 2022
-
[44]
Haojie He, Xingwei Lin, Ziang Weng, Ruijie Zhao, Shuitao Gan, Libo Chen, Yuede Ji, Jiashui Wang, and Zhi Xue. Code is not natural language: Unlock the power of semantics-oriented graph representation for binary code similarity detection. In 33rd USENIX Security Symposium (USENIX Security 24), PHILADELPHIA, PA , 2024
work page 2024
-
[45]
Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation
Kyunghyun Cho, Bart Van Merriënboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. Learning phrase representations using rnn encoder-decoder for statistical machine translation. arXiv preprint arXiv:1406.1078, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[46]
Sok:(state of) the art of war: Offensive techniques in binary analysis
Yan Shoshitaishvili, Ruoyu Wang, Christopher Salls, Nick Stephens, Mario Polino, Andrew Dutcher, John Grosen, Siji Feng, Christophe Hauser, Christopher Kruegel, et al. Sok:(state of) the art of war: Offensive techniques in binary analysis. In 2016 IEEE symposium on security and privacy (SP) , pages 138–157. IEEE, 2016
work page 2016
-
[47]
llasm: Naming functions in binaries by fusing encoder-only and decoder-only llms
Zihan Sha, Hao Wang, Zeyu Gao, Hui Shu, Bolun Zhang, Ziqing Wang, and Chao Zhang. llasm: Naming functions in binaries by fusing encoder-only and decoder-only llms. ACM Transactions on Software Engineering and Methodology , 2024
work page 2024
-
[48]
Enhancing function name prediction using votes-based name tokenization and multi-task learning
Xiaoling Zhang, Zhengzi Xu, Shouguo Yang, Zhi Li, Zhiqiang Shi, and Limin Sun. Enhancing function name prediction using votes-based name tokenization and multi-task learning. Proceedings of the ACM on Software Engineering , 1(FSE):1679–1702, 2024
work page 2024
-
[49]
Xin Jin, Kexin Pei, Jun Yeon Won, and Zhiqiang Lin. Symlm: Predicting function names in stripped binaries via context-sensitive execution-aware code embeddings. In Proceedings of the 2022 ACM SIGSAC Conference on Computer and Communications Security, pages 1631–1645, 2022
work page 2022
-
[50]
Direct: A transformer-based model for decompiled variable name recov-ery
Vikram Nitin, Anthony Saieva, Baishakhi Ray, and Gail Kaiser. Direct: A transformer-based model for decompiled variable name recov-ery. NLP4Prog 2021, page 48, 2021
work page 2021
-
[51]
Cp-bcs: Binary code summarization guided by control flow graph and pseudo code
Tong Ye, Lingfei Wu, Tengfei Ma, Xuhong Zhang, Yangkai Du, Peiyu Liu, Shouling Ji, and Wenhai Wang. Cp-bcs: Binary code summarization guided by control flow graph and pseudo code. arXiv preprint arXiv:2310.16853, 2023
-
[52]
Binary code summarization: Benchmarking chatgpt/gpt-4 and other large language models
Xin Jin, Jonathan Larson, Weiwei Yang, and Zhiqiang Lin. Binary code summarization: Benchmarking chatgpt/gpt-4 and other large language models. arXiv preprint arXiv:2312.09601, 2023
-
[53]
How far have we gone in binary code understanding using large language models
Xiuwei Shang, Shaoyin Cheng, Guoqiang Chen, Yanming Zhang, Li Hu, Xiao Yu, Gangyang Li, Weiming Zhang, and Nenghai Yu. How far have we gone in binary code understanding using large language models. In 2024 IEEE International Conference on Software Maintenance and Evolution (ICSME) , pages 1–12. IEEE, 2024
work page 2024
-
[54]
Binvuldet: Detecting vulnerability in binary program via decompiled pseudo code and bilstm-attention
Yan Wang, Peng Jia, Xi Peng, Cheng Huang, and Jiayong Liu. Binvuldet: Detecting vulnerability in binary program via decompiled pseudo code and bilstm-attention. Computers & Security, 125:103023, 2023
work page 2023
-
[55]
Resym: Harnessing llms to recover variable and data structure symbols from stripped binaries
Danning Xie, Zhuo Zhang, Nan Jiang, Xiangzhe Xu, Lin Tan, and Xiangyu Zhang. Resym: Harnessing llms to recover variable and data structure symbols from stripped binaries. In Proceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security , pages 4554–4568, 2024
work page 2024
-
[56]
Cati: Context-assisted type inference from stripped binaries
Ligeng Chen, Zhongling He, and Bing Mao. Cati: Context-assisted type inference from stripped binaries. In 2020 50th Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN) , pages 88–98. IEEE, 2020
work page 2020
-
[57]
Tie: Principled reverse engineering of types in binary programs
JongHyup Lee, Thanassis Avgerinos, and David Brumley. Tie: Principled reverse engineering of types in binary programs. 2011
work page 2011
-
[58]
Polymorphic type inference for machine code
Matt Noonan, Alexey Loginov, and David Cok. Polymorphic type inference for machine code. In Proceedings of the 37th ACM SIGPLAN Conference on Programming Language Design and Implementation , pages 27–41, 2016
work page 2016
-
[59]
Scalable variable and data type detection in a binary rewriter
Khaled ElWazeer, Kapil Anand, Aparna Kotha, Matthew Smithson, and Rajeev Barua. Scalable variable and data type detection in a binary rewriter. In Proceedings of the 34th ACM SIGPLAN conference on Programming language design and implementation, pages 51–60, 2013
work page 2013
-
[60]
Osprey: Recovery of variable and data structure via probabilistic analysis for stripped binary
Zhuo Zhang, Yapeng Ye, Wei You, Guanhong Tao, Wen-chuan Lee, Yonghwi Kwon, Yousra Aafer, and Xiangyu Zhang. Osprey: Recovery of variable and data structure via probabilistic analysis for stripped binary. In 2021 IEEE Symposium on Security and Privacy (SP) , pages 813–832. IEEE, 2021
work page 2021
-
[61]
Howard: A dynamic excavator for reverse engineering data structures
Asia Slowinska, Traian Stancescu, and Herbert Bos. Howard: A dynamic excavator for reverse engineering data structures. In NDSS, 2011
work page 2011
-
[62]
Automatic reverse engineering of data structures from binary execution
Zhiqiang Lin, Xiangyu Zhang, and Dongyan Xu. Automatic reverse engineering of data structures from binary execution. In Proceedings of the 11th Annual Information Security Symposium , pages 1–1, 2010. J. ACM, Vol. 37, No. 4, Article . Publication date: July 2025. 32 Gangyang Li et al
work page 2010
-
[63]
Typeminer: Recovering types in binary programs using machine learning
Alwin Maier, Hugo Gascon, Christian Wressnegger, and Konrad Rieck. Typeminer: Recovering types in binary programs using machine learning. In Detection of Intrusions and Malware, and Vulnerability Assessment: 16th International Conference, DIMV A 2019, Gothenburg, Sweden, June 19–20, 2019, Proceedings 16 , pages 288–308. Springer, 2019
work page 2019
-
[64]
Neural nets can learn function type signatures from binaries
Zheng Leong Chua, Shiqi Shen, Prateek Saxena, and Zhenkai Liang. Neural nets can learn function type signatures from binaries. In 26th USENIX Security Symposium (USENIX Security 17) , pages 99–116, 2017
work page 2017
-
[65]
Hyunjin Kim, Jinyeong Bak, Kyunghyun Cho, and Hyungjoon Koo. A transformer-based function symbol name inference model from an assembly language for binary reversing. In Proceedings of the 2023 ACM Asia Conference on Computer and Communications Security , pages 951–965, 2023
work page 2023
-
[66]
Xfl: Naming functions in binaries with extreme multi-label learning
James Patrick-Evans, Moritz Dannehl, and Johannes Kinder. Xfl: Naming functions in binaries with extreme multi-label learning. In 2023 IEEE Symposium on Security and Privacy (SP) , pages 2375–2390. IEEE, 2023
work page 2023
-
[67]
Abdullah Qasem, Mourad Debbabi, Bernard Lebel, and Marthe Kassouf. Binary function clone search in the presence of code obfuscation and optimization over multi-cpu architectures. In Proceedings of the 2023 acm asia conference on computer and communications security , pages 443–456, 2023
work page 2023
-
[68]
Clap: Learning transferable binary code representations with natural language supervision
Hao Wang, Zeyu Gao, Chao Zhang, Zihan Sha, Mingyang Sun, Yuchen Zhou, Wenyu Zhu, Wenju Sun, Han Qiu, and Xi Xiao. Clap: Learning transferable binary code representations with natural language supervision. In Proceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis , pages 503–515, 2024
work page 2024
-
[69]
Xiaoya Zhu, Junfeng Wang, Zhiyang Fang, Xiaokang Yin, and Shengli Liu. Bbdetector: A precise and scalable third- party library detection in binary executables with fine-grained function-level features. Applied Sciences, 13(1):413, 2022
work page 2022
-
[70]
Libam: An area matching framework for detecting third-party libraries in binaries
Siyuan Li, Yongpan Wang, Chaopeng Dong, Shouguo Yang, Hong Li, Hao Sun, Zhe Lang, Zuxin Chen, Weijie Wang, Hongsong Zhu, et al. Libam: An area matching framework for detecting third-party libraries in binaries. ACM Transactions on Software Engineering and Methodology , 33(2):1–35, 2023
work page 2023
-
[71]
Libdb: An effective and efficient framework for detecting third-party libraries in binaries
Wei Tang, Yanlin Wang, Hongyu Zhang, Shi Han, Ping Luo, and Dongmei Zhang. Libdb: An effective and efficient framework for detecting third-party libraries in binaries. In Proceedings of the 19th International Conference on Mining Software Repositories, pages 423–434, 2022. J. ACM, Vol. 37, No. 4, Article . Publication date: July 2025
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.