NeurBench: A Benchmark Suite for Learned Database Components with Drift Modeling
Pith reviewed 2026-05-23 00:06 UTC · model grok-4.3
The pith
NeurBench introduces a drift factor and generation framework to evaluate learned database components under measurable and controllable data and workload drift.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
NeurBench is a benchmark suite that quantifies diverse types of drift via a drift factor and supplies a drift-aware data and workload generation framework that simulates real-world drift while preserving inherent correlations, thereby enabling systematic performance evaluation of learned database components under a broad range of measurable and controllable drift conditions.
What carries the argument
The drift factor, which quantifies diverse types of drift, together with the drift-aware data and workload generation framework built upon it.
If this is right
- Learned components can be tested across a broad range of drift scenarios rather than only specific cases.
- Customized drift conditions become available for targeted evaluation.
- Performance insights under varying drift become reproducible and comparable.
- Robustness assessment of learned components moves from ad-hoc checks to systematic coverage.
Where Pith is reading between the lines
- The same drift-factor approach could be adapted to benchmark learned components in other dynamic systems such as caching or query optimizers.
- Standard test suites for learned systems might incorporate drift factors as a default dimension.
- Component designers could use the generation framework to create training data that anticipates future drift.
- Comparative studies across multiple learned components would become feasible under identical drift conditions.
Load-bearing premise
The drift-aware data and workload generation framework effectively simulates real-world drift while preserving inherent correlations.
What would settle it
A direct statistical comparison in which the correlations and distributional properties of data and workloads generated by the framework diverge from those observed in actual production database traces under documented drift.
Figures




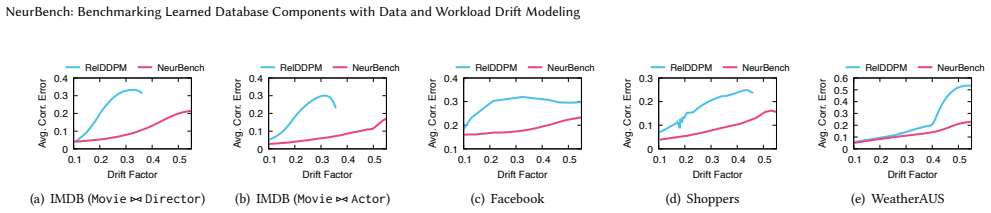
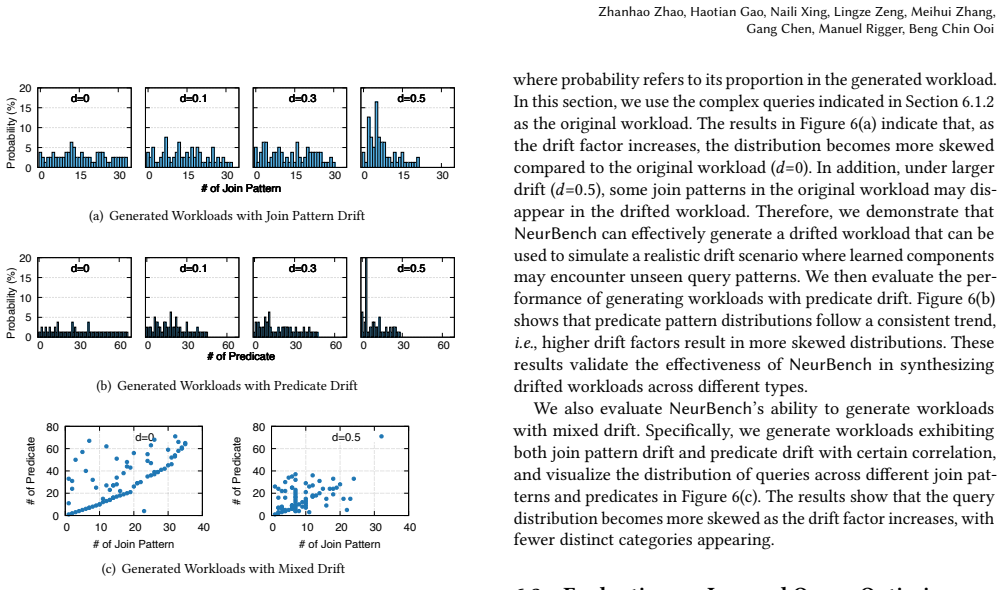

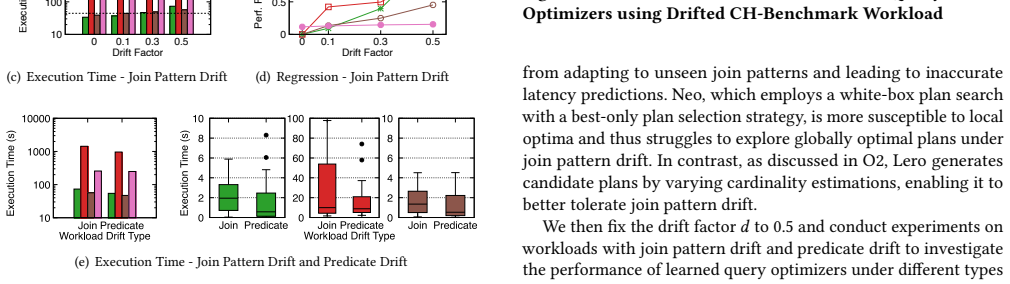




read the original abstract
Learned database components, which deeply integrate machine learning into their design, have been extensively studied in recent years. Given the dynamism of databases, where data and workloads continuously drift, it is crucial for learned database components to remain effective and efficient in the face of data and workload drift. Robustness, therefore, is a key factor in assessing their practical applicability. Although recent works examine learned database components under specific drift, they fail to enable systematic performance evaluations across a broad range of drift or under customized drift as needed. This paper presents NeurBench, a new benchmark suite that supports evaluating learned database components under measurable and controllable data and workload drift. We quantify diverse types of drift by introducing a key concept called the drift factor. Building on this formulation, we propose a drift-aware data and workload generation framework that effectively simulates real-world drift while preserving inherent correlations. Experimental results demonstrate the effectiveness of NeurBench in generating realistic data and workload drift, while providing insights into the performance of representative learned database components under different drift scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces NeurBench, a benchmark suite for evaluating learned database components under data and workload drift. It defines a drift factor to quantify diverse drift types and proposes a drift-aware data and workload generation framework claimed to simulate real-world drift while preserving inherent correlations. Experimental results are presented to demonstrate the framework's effectiveness in generating realistic drift scenarios and to provide insights into the performance of representative learned database components under varying drift conditions.
Significance. If the experimental validation holds, NeurBench would fill a notable gap by enabling systematic, measurable, and customizable evaluation of robustness to drift in learned database systems, moving beyond ad-hoc or single-drift studies. The drift factor and generation framework, if shown to preserve correlations, could support reproducible comparisons and development of drift-resilient components, with the reported insights adding immediate practical value to the field.
minor comments (2)
- [Abstract] Abstract: the phrase 'diverse types of drift' is used without enumeration or examples; a short parenthetical list of the quantified drift types would improve immediate readability.
- [Abstract] Abstract: the claim of 'preserving inherent correlations' is central to the framework's value; ensure the experiments section includes explicit quantitative metrics (e.g., correlation coefficients before/after generation) rather than qualitative statements alone.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. No major comments were raised in the report.
Circularity Check
No significant circularity
full rationale
The paper introduces NeurBench as a benchmark suite with a drift factor concept and a drift-aware generation framework. No derivation chain, predictions, or first-principles results are claimed that reduce to fitted parameters or self-citations by construction. The central contribution is the design and experimental validation of the benchmark tool itself, which is self-contained and externally falsifiable via its generated data/workloads. No load-bearing self-citations, ansatzes, or renamings of known results appear in the provided text.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The proposed drift-aware generation framework preserves inherent correlations in data and workloads when simulating drift.
invented entities (1)
-
drift factor
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Cohen, Zhenggang Xu, Prithviraj Pandian, Nikolay Laptev, and Ryan Marcus
Christoph Anneser, Nesime Tatbul, David E. Cohen, Zhenggang Xu, Prithviraj Pandian, Nikolay Laptev, and Ryan Marcus. 2023. AutoSteer: Learned Query Optimization for Any SQL Database.Proc. VLDB Endow. 16, 12 (2023), 3515–3527
work page 2023
-
[2]
Internet Archive. 2025. IMDB Archive . https://web.archive.org/web/ 20240301000000*/https://datasets.imdbws.com/
work page 2025
-
[3]
Lawrence Benson, Carsten Binnig, Jan-Micha Bodensohn, Federico Lorenzi, Jigao Luo, Danica Porobic, Tilmann Rabl, Anupam Sanghi, Russell Sears, Pinar Tözün, and Tobias Ziegler. 2024. Surprise Benchmarking: The Why, What, and How. In DBTest@SIGMOD. ACM, 1–8
work page 2024
-
[4]
Maximilian Böther, Foteini Strati, Viktor Gsteiger, and Ana Klimovic. 2023. To- wards A Platform and Benchmark Suite for Model Training on Dynamic Datasets. In EuroMLSys@EuroSys. ACM, 8–17
work page 2023
-
[5]
Tianyi Chen, Jun Gao, Hedui Chen, and Yaofeng Tu. 2023. LOGER: A Learned Optimizer towards Generating Efficient and Robust Query Execution Plans. Proc. VLDB Endow. 16, 7 (2023), 1777–1789
work page 2023
- [6]
-
[7]
Richard Cole, Florian Funke, Leo Giakoumakis, Wey Guy, Alfons Kemper, Stefan Krompass, Harumi Kuno, Raghunath Nambiar, Thomas Neumann, Meikel Poess, et al. 2011. The mixed workload CH-benCHmark. In Proceedings of the Fourth International Workshop on Testing Database Systems. 1–6
work page 2011
-
[8]
Cooper, Adam Silberstein, Erwin Tam, Raghu Ramakrishnan, and Russell Sears
Brian F. Cooper, Adam Silberstein, Erwin Tam, Raghu Ramakrishnan, and Russell Sears. 2010. Benchmarking cloud serving systems with YCSB. In SoCC. ACM, 143–154
work page 2010
-
[9]
The Transaction Processing Council. 2024. TPC-C. http://www.tpc.org/tpcc/
work page 2024
-
[10]
The Transaction Processing Council. 2024. TPC-H. http://www.tpc.org/tpch/
work page 2024
-
[11]
Prafulla Dhariwal and Alexander Quinn Nichol. 2021. Diffusion Models Beat GANs on Image Synthesis. In NeurIPS. 8780–8794
work page 2021
- [12]
-
[13]
Jialin Ding, Umar Farooq Minhas, Jia Yu, Chi Wang, Jaeyoung Do, Yinan Li, Hantian Zhang, Badrish Chandramouli, Johannes Gehrke, Donald Kossmann, David B. Lomet, and Tim Kraska. 2020. ALEX: An Updatable Adaptive Learned Index. In SIGMOD Conference. ACM, 969–984
work page 2020
-
[14]
Paolo Ferragina and Giorgio Vinciguerra. 2020. The PGM-index: a fully-dynamic compressed learned index with provable worst-case bounds. Proc. VLDB Endow. 13, 8 (2020), 1162–1175
work page 2020
-
[15]
Josh Gardner, Zoran Popovic, and Ludwig Schmidt. 2023. Benchmarking Distri- bution Shift in Tabular Data with TableShift. In NeurIPS
work page 2023
-
[16]
Minas Gjoka, Maciej Kurant, Carter T. Butts, and Athina Markopoulou. 2010. Walking in Facebook: A Case Study of Unbiased Sampling of OSNs. InINFOCOM. IEEE, 2498–2506
work page 2010
-
[17]
Zhihan Guo, Kan Wu, Cong Yan, and Xiangyao Yu. 2021. Releasing Locks As Early As You Can: Reducing Contention of Hotspots by Violating Two-Phase Locking. In SIGMOD Conference. ACM, 658–670
work page 2021
-
[18]
Yuxing Han, Ziniu Wu, Peizhi Wu, Rong Zhu, Jingyi Yang, Liang Wei Tan, Kai Zeng, Gao Cong, Yanzhao Qin, Andreas Pfadler, Zhengping Qian, Jingren Zhou, Jiangneng Li, and Bin Cui. 2021. Cardinality Estimation in DBMS: A Comprehensive Benchmark Evaluation. Proc. VLDB Endow. 15, 4 (2021), 752– 765
work page 2021
-
[19]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. 2020. Denoising Diffusion Probabilistic Models. In NeurIPS
work page 2020
-
[20]
IMDB. 2025. IMDB Dataset. https://www.imdb.com/
work page 2025
-
[21]
Pang Wei Koh, Shiori Sagawa, Henrik Marklund, Sang Michael Xie, Marvin Zhang, Akshay Balsubramani, Weihua Hu, Michihiro Yasunaga, Richard Lanas Phillips, Irena Gao, Tony Lee, Etienne David, Ian Stavness, Wei Guo, Berton Earn- shaw, Imran S. Haque, Sara M. Beery, Jure Leskovec, Anshul Kundaje, Emma Pierson, Sergey Levine, Chelsea Finn, and Percy Liang. 202...
work page 2021
-
[22]
Akim Kotelnikov, Dmitry Baranchuk, Ivan Rubachev, and Artem Babenko. 2023. TabDDPM: Modelling Tabular Data with Diffusion Models. In ICML (Proceedings of Machine Learning Research, Vol. 202) . PMLR, 17564–17579
work page 2023
-
[23]
Chi, Jeffrey Dean, and Neoklis Polyzotis
Tim Kraska, Alex Beutel, Ed H. Chi, Jeffrey Dean, and Neoklis Polyzotis. 2018. The Case for Learned Index Structures. In SIGMOD Conference. ACM, 489–504
work page 2018
-
[24]
Meghdad Kurmanji, Eleni Triantafillou, and Peter Triantafillou. 2024. Machine Unlearning in Learned Databases: An Experimental Analysis. Proc. ACM Manag. Data 2, 1 (2024), 49:1–49:26
work page 2024
-
[25]
Meghdad Kurmanji and Peter Triantafillou. 2023. Detect, Distill and Update: Learned DB Systems Facing Out of Distribution Data. Proc. ACM Manag. Data 1, 1 (2023), 33:1–33:27
work page 2023
-
[26]
Shane Culpepper, and Renata Borovica-Gajic
Hai Lan, Zhifeng Bao, J. Shane Culpepper, and Renata Borovica-Gajic. 2023. Updatable Learned Indexes Meet Disk-Resident DBMS - From Evaluations to Design Choices. Proc. ACM Manag. Data 1, 2 (2023), 139:1–139:22
work page 2023
-
[27]
Claude Lehmann, Pavel Sulimov, and Kurt Stockinger. 2024. Is Your Learned Query Optimizer Behaving As You Expect? A Machine Learning Perspective. Proc. VLDB Endow. 17, 7 (2024), 1565–1577. NeurBench: Benchmarking Learned Database Components with Data and Workload Drift Modeling
work page 2024
-
[28]
Boncz, Alfons Kemper, and Thomas Neumann
Viktor Leis, Andrey Gubichev, Atanas Mirchev, Peter A. Boncz, Alfons Kemper, and Thomas Neumann. 2015. How Good Are Query Optimizers, Really? Proc. VLDB Endow. 9, 3 (2015), 204–215
work page 2015
-
[29]
Viktor Leis, Alfons Kemper, and Thomas Neumann. 2013. The adaptive radix tree: ARTful indexing for main-memory databases. In ICDE. IEEE Computer Society, 38–49
work page 2013
-
[30]
Viktor Leis, Florian Scheibner, Alfons Kemper, and Thomas Neumann. 2016. The ART of practical synchronization. In DaMoN. ACM, 3:1–3:8
work page 2016
-
[31]
Beibin Li, Yao Lu, and Srikanth Kandula. 2022. Warper: Efficiently Adapting Learned Cardinality Estimators to Data and Workload Drifts. In SIGMOD Con- ference. ACM, 1920–1933
work page 2022
-
[32]
Pengfei Li, Wenqing Wei, Rong Zhu, Bolin Ding, Jingren Zhou, and Hua Lu. 2023. ALECE: An Attention-based Learned Cardinality Estimator for SPJ Queries on Dynamic Workloads. Proc. VLDB Endow. 17, 2 (2023), 197–210
work page 2023
-
[33]
Wendi Li, Xiao Yang, Weiqing Liu, Yingce Xia, and Jiang Bian. 2022. DDG-DA: Data Distribution Generation for Predictable Concept Drift Adaptation. In AAAI. AAAI Press, 4092–4100
work page 2022
-
[34]
Yu-Shan Lin, Ching Tsai, Tz-Yu Lin, Yun-Sheng Chang, and Shan-Hung Wu
-
[35]
Don’t Look Back, Look into the Future: Prescient Data Partitioning and Migration for Deterministic Database Systems. In SIGMOD Conference. ACM, 1156–1168
-
[36]
Mandic, Wenwu Wang, and Mark D
Haohe Liu, Zehua Chen, Yi Yuan, Xinhao Mei, Xubo Liu, Danilo P. Mandic, Wenwu Wang, and Mark D. Plumbley. 2023. AudioLDM: Text-to-Audio Gener- ation with Latent Diffusion Models. In ICML (Proceedings of Machine Learning Research, Vol. 202). PMLR, 21450–21474
work page 2023
-
[37]
Tongyu Liu, Ju Fan, Nan Tang, Guoliang Li, and Xiaoyong Du. 2024. Controllable Tabular Data Synthesis Using Diffusion Models. Proc. ACM Manag. Data 2, 1 (2024), 28:1–28:29
work page 2024
-
[38]
Chaohong Ma, Xiaohui Yu, Yifan Li, Xiaofeng Meng, and Aishan Maoliniyazi
-
[39]
FILM: a Fully Learned Index for Larger-than-Memory Databases. Proc. VLDB Endow. 16, 3 (2022), 561–573
work page 2022
-
[40]
Christopher D. Manning and Hinrich Schütze. 2001. Foundations of statistical natural language processing. MIT Press
work page 2001
-
[41]
Ryan Marcus, Parimarjan Negi, Hongzi Mao, Nesime Tatbul, Mohammad Al- izadeh, and Tim Kraska. 2021. Bao: Making Learned Query Optimization Practical. In SIGMOD Conference. ACM, 1275–1288
work page 2021
-
[42]
Ryan Marcus, Parimarjan Negi, Hongzi Mao, Chi Zhang, Mohammad Alizadeh, Tim Kraska, Olga Papaemmanouil, and Nesime Tatbul. 2019. Neo: A Learned Query Optimizer. Proc. VLDB Endow. 12, 11 (2019), 1705–1718
work page 2019
-
[43]
Songsong Mo, Yile Chen, Hao Wang, Gao Cong, and Zhifeng Bao. 2023. Lemo: A Cache-Enhanced Learned Optimizer for Concurrent Queries. Proc. ACM Manag. Data 1, 4 (2023), 247:1–247:26
work page 2023
-
[44]
Lili Mou, Ge Li, Lu Zhang, Tao Wang, and Zhi Jin. 2016. Convolutional Neural Networks over Tree Structures for Programming Language Processing. In AAAI. AAAI Press, 1287–1293
work page 2016
-
[45]
NeurBench. 2025. NeurBench Implementation . https://github.com/neurdb/ neurbench
work page 2025
- [46]
-
[47]
Piotr Porwik and Benjamin Mensah Dadzie. 2022. Detection of data drift in a two-dimensional stream using the Kolmogorov-Smirnov test. In KES (Procedia Computer Science, Vol. 207). Elsevier, 168–175
work page 2022
-
[48]
Cemal Okan Sakar, Suleyman Olcay Polat, Mete Katircioglu, and Yomi Kastro
-
[49]
Real-time prediction of online shoppers’ purchasing intention using multi- layer perceptron and LSTM recurrent neural networks. Neural Comput. Appl. 31, 10 (2019), 6893–6908
work page 2019
-
[50]
Weiss, Niru Maheswaranathan, and Surya Ganguli
Jascha Sohl-Dickstein, Eric A. Weiss, Niru Maheswaranathan, and Surya Ganguli
-
[51]
Deep Unsupervised Learning using Nonequilibrium Thermodynamics. In Proceedings of the 32nd International Conference on Machine Learning, ICML 2015, Lille, France, 6-11 July 2015 (JMLR Workshop and Conference Proceedings, Vol. 37) , Francis R. Bach and David M. Blei (Eds.). JMLR.org, 2256–2265
work page 2015
-
[52]
Zhaoyan Sun, Xuanhe Zhou, and Guoliang Li. 2023. Learned Index: A Compre- hensive Experimental Evaluation. Proc. VLDB Endow. 16, 8 (2023), 1992–2004
work page 2023
-
[53]
Kai Sheng Tai, Richard Socher, and Christopher D. Manning. 2015. Improved Semantic Representations From Tree-Structured Long Short-Term Memory Net- works. In ACL (1). The Association for Computer Linguistics, 1556–1566
work page 2015
-
[54]
Chuzhe Tang, Youyun Wang, Zhiyuan Dong, Gansen Hu, Zhaoguo Wang, Minjie Wang, and Haibo Chen. 2020. XIndex: a scalable learned index for multicore data storage. In PPoPP. ACM, 308–320
work page 2020
-
[55]
Dixin Tang, Hao Jiang, and Aaron J. Elmore. 2017. Adaptive Concurrency Control: Despite the Looking Glass, One Concurrency Control Does Not Fit All. In CIDR. www.cidrdb.org
work page 2017
-
[56]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. Attention is All you Need. In NIPS. 5998–6008
work page 2017
-
[57]
Jia-Chen Wang, Ding Ding, Huan Wang, Conrad Christensen, Zhaoguo Wang, Haibo Chen, and Jinyang Li. 2021. Polyjuice: High-Performance Transactions via Learned Concurrency Control. In OSDI. USENIX Association, 198–216
work page 2021
-
[58]
Zhaoguo Wang, Shuai Mu, Yang Cui, Han Yi, Haibo Chen, and Jinyang Li. 2016. Scaling Multicore Databases via Constrained Parallel Execution. In SIGMOD Conference. ACM, 1643–1658
work page 2016
- [59]
-
[60]
WeatherAUS. 2025. WeatherAUS DataSet. https://www.kaggle.com/jsphyg/ weather-dataset-rattle-package
work page 2025
-
[61]
Wikipedia. 2025. Pearson Correlation Coefficient. https://en.wikipedia.org/wiki/ Pearson_correlation_coefficient
work page 2025
-
[62]
Olivia Wiles, Sven Gowal, Florian Stimberg, Sylvestre-Alvise Rebuffi, Ira Ktena, Krishnamurthy Dvijotham, and Ali Taylan Cemgil. 2022. A Fine-Grained Analysis on Distribution Shift. In ICLR. OpenReview.net
work page 2022
-
[63]
Chaichon Wongkham, Baotong Lu, Chris Liu, Zhicong Zhong, Eric Lo, and Tianzheng Wang. 2022. Are Updatable Learned Indexes Ready? Proc. VLDB Endow. 15, 11 (2022), 3004–3017
work page 2022
-
[64]
Jiacheng Wu, Yong Zhang, Shimin Chen, Yu Chen, Jin Wang, and Chunxiao Xing
-
[65]
Updatable Learned Index with Precise Positions. Proc. VLDB Endow. 14, 8 (2021), 1276–1288
work page 2021
-
[66]
Peizhi Wu and Zachary G. Ives. 2024. Modeling Shifting Workloads for Learned Database Systems. Proc. ACM Manag. Data 2, 1 (2024), 38:1–38:27
work page 2024
-
[67]
Yu Xia, Xiangyao Yu, Matthew Butrovich, Andrew Pavlo, and Srinivas Devadas
-
[68]
Litmus: Towards a Practical Database Management System with Verifiable ACID Properties and Transaction Correctness. In SIGMOD Conference. ACM, 1478–1492
-
[69]
Xiang Yu, Chengliang Chai, Guoliang Li, and Jiabin Liu. 2022. Cost-based or Learning-based? A Hybrid Query Optimizer for Query Plan Selection. Proc. VLDB Endow. 15, 13 (2022), 3924–3936
work page 2022
-
[70]
Shunkang Zhang, Ji Qi, Xin Yao, and André Brinkmann. 2024. Hyper: A High- Performance and Memory-Efficient Learned Index via Hybrid Construction.Proc. ACM Manag. Data 2, 3 (2024), 145
work page 2024
-
[71]
Zhou Zhang, Zhaole Chu, Peiquan Jin, Yongping Luo, Xike Xie, Shouhong Wan, Yun Luo, Xufei Wu, Peng Zou, Chunyang Zheng, Guoan Wu, and Andy Rudoff
-
[72]
PLIN: A Persistent Learned Index for Non-Volatile Memory with High Performance and Instant Recovery. Proc. VLDB Endow. 16, 2 (2022), 243–255
work page 2022
-
[73]
Rong Zhu, Wei Chen, Bolin Ding, Xingguang Chen, Andreas Pfadler, Ziniu Wu, and Jingren Zhou. 2023. Lero: A Learning-to-Rank Query Optimizer. Proc. VLDB Endow. 16, 6 (2023), 1466–1479
work page 2023
-
[74]
Rong Zhu, Lianggui Weng, Bolin Ding, and Jingren Zhou. 2024. Learned Query Optimizer: What is New and What is Next. In SIGMOD Conference Companion. ACM, 561–569
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.