SMPL-GPTexture: Dual-View 3D Human Texture Estimation using Text-to-Image Generation Models
Pith reviewed 2026-05-22 19:47 UTC · model grok-4.3
The pith
A pipeline turns text prompts into complete high-resolution 3D human textures by generating consistent front and back views then projecting them onto SMPL meshes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
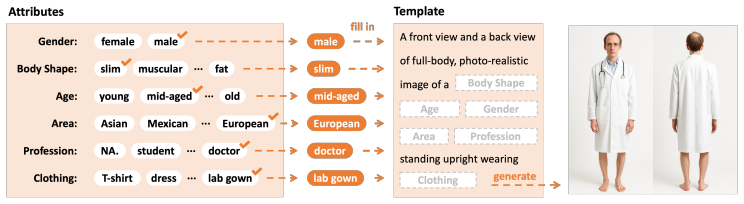
SMPL-GPTexture takes natural language prompts as input and leverages a state-of-the-art text-to-image generation model to produce paired high-resolution front and back images of a human subject. Using the generated paired dual-view images, a human mesh recovery model obtains robust 2D-to-3D SMPL alignment between image pixels and the 3D model's UV coordinates for each view. An inverted rasterization technique then projects the observed colour from the input images into the UV space to produce accurate complete texture maps. A diffusion-based inpainting module fills missing regions and a fusion mechanism combines the results into a unified full texture map.
What carries the argument
Dual-view text-to-image generation followed by SMPL mesh recovery and inverted rasterization to project colors from the two views into a unified UV texture map.
If this is right
- Custom 3D avatars can be produced at high resolution directly from user text descriptions.
- Texture creation no longer requires access to real paired front and back photographs.
- Missing regions in the projected texture are completed by diffusion inpainting before final fusion.
- The output texture maps remain aligned with the semantics of the original language prompt.
Where Pith is reading between the lines
- The same dual-view generation step could be tested on prompts for non-standard body shapes or clothing styles to measure robustness.
- Once a texture map exists, it could be fed into existing animation pipelines to animate the prompt-described character without additional image inputs.
Load-bearing premise
Text-to-image models can reliably produce front and back images that are structurally consistent and free of artifacts sufficient for accurate SMPL alignment and UV projection.
What would settle it
Run the pipeline on a prompt describing a specific clothing pattern and check whether the resulting 3D avatar shows that exact pattern without distortion or seams when rotated to a side view not present in the generated front or back image.
Figures


read the original abstract
Generating high-quality, photorealistic textures for 3D human avatars remains a fundamental yet challenging task in computer vision and multimedia field. However, real paired front and back images of human subjects are rarely available with privacy, ethical and cost of acquisition, which restricts scalability of the data. Additionally, learning priors from image inputs using deep generative models, such as GANs or diffusion models, to infer unseen regions such as the human back often leads to artifacts, structural inconsistencies, or loss of fine-grained detail. To address these issues, we present SMPL-GPTexture (skinned multi-person linear model - general purpose Texture), a novel pipeline that takes natural language prompts as input and leverages a state-of-the-art text-to-image generation model to produce paired high-resolution front and back images of a human subject as the starting point for texture estimation. Using the generated paired dual-view images, we first employ a human mesh recovery model to obtain a robust 2D-to-3D SMPL alignment between image pixels and the 3D model's UV coordinates for each views. Second, we use an inverted rasterization technique that explicitly projects the observed colour from the input images into the UV space, thereby producing accurate, complete texture maps. Finally, we apply a diffusion-based inpainting module to fill in the missing regions, and the fusion mechanism then combines these results into a unified full texture map. Extensive experiments shows that our SMPL-GPTexture can generate high resolution texture aligned with user's prompts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents SMPL-GPTexture, a pipeline that takes natural language prompts as input and uses a text-to-image model to generate paired high-resolution front and back images of a human subject. These images are processed with a human mesh recovery model to obtain SMPL alignments per view, followed by inverted rasterization to project observed colors into UV space, diffusion-based inpainting to fill missing regions, and a fusion step to produce a unified full texture map for 3D human avatars.
Significance. If the pipeline produces consistent, prompt-aligned, high-resolution textures without view discrepancies, the work would offer a practical way to bypass the scarcity and ethical issues of real paired front-back image data, extending generative texture estimation beyond current GAN- or diffusion-based priors that introduce artifacts in unseen regions. The use of pre-trained T2I models for dual-view starting points is a potentially useful direction for scalable avatar creation in graphics and multimedia applications.
major comments (2)
- [Section 3] Pipeline description (Section 3): The method generates front and back images via independent calls to the text-to-image model from the same prompt, with no described mechanism (shared latent, cross-view conditioning, pose consistency loss, or post-generation alignment) to enforce identical body shape, clothing geometry, or fine details across views. This is load-bearing for the central claim because any pose drift, asymmetry, or lighting mismatch directly corrupts the per-view SMPL fits and the inverted rasterization into UV space before inpainting or fusion can intervene.
- [Section 4] Experiments and evaluation (Section 4): The abstract states that 'extensive experiments shows that our SMPL-GPTexture can generate high resolution texture aligned with user's prompts,' yet the manuscript provides no quantitative metrics (e.g., texture PSNR, perceptual similarity scores, or alignment error), ablation studies on the consistency issue, or error analysis comparing against baselines that use real paired images. Without these, the support for the claim that the generated textures are high-resolution and prompt-aligned remains unverifiable.
minor comments (2)
- [Abstract] Abstract: The sentence 'Extensive experiments shows...' contains a subject-verb agreement error ('shows' should be 'show').
- [Abstract] Notation: The acronym expansion 'skinned multi-person linear model - general purpose Texture' is non-standard; consider aligning with the established SMPL definition and clarifying 'GPTexture' usage throughout.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments on our manuscript. We address each major point below, providing clarifications and indicating where revisions will be made to strengthen the paper.
read point-by-point responses
-
Referee: [Section 3] Pipeline description (Section 3): The method generates front and back images via independent calls to the text-to-image model from the same prompt, with no described mechanism (shared latent, cross-view conditioning, pose consistency loss, or post-generation alignment) to enforce identical body shape, clothing geometry, or fine details across views. This is load-bearing for the central claim because any pose drift, asymmetry, or lighting mismatch directly corrupts the per-view SMPL fits and the inverted rasterization into UV space before inpainting or fusion can intervene.
Authors: We agree that the manuscript does not describe an explicit cross-view consistency mechanism such as shared latents or conditioning. The pipeline relies on issuing two separate generations from the identical prompt, which the pre-trained T2I model often renders with reasonable subject-level coherence when the prompt is sufficiently detailed. Minor residual inconsistencies are intended to be handled downstream by the per-view SMPL fitting, inverted rasterization, and diffusion inpainting. To address the referee's concern, we will revise Section 3 to explicitly acknowledge this design choice, discuss its limitations, and describe how the subsequent stages provide robustness. We will also add a brief note on potential future extensions such as post-generation alignment. revision: partial
-
Referee: [Section 4] Experiments and evaluation (Section 4): The abstract states that 'extensive experiments shows that our SMPL-GPTexture can generate high resolution texture aligned with user's prompts,' yet the manuscript provides no quantitative metrics (e.g., texture PSNR, perceptual similarity scores, or alignment error), ablation studies on the consistency issue, or error analysis comparing against baselines that use real paired images. Without these, the support for the claim that the generated textures are high-resolution and prompt-aligned remains unverifiable.
Authors: We acknowledge that the current experimental section is primarily qualitative. While the abstract refers to extensive experiments demonstrating prompt alignment and visual quality, we did not include numerical metrics or ablations in the submitted version. In the revision we will add quantitative evaluations, including CLIP-based prompt-alignment scores, perceptual metrics such as LPIPS on rendered views, and an ablation isolating the effect of view consistency. Where feasible we will also provide comparisons against texture estimation methods trained on real paired data. revision: yes
Circularity Check
No circularity: pipeline uses external pre-trained models without self-referential derivations
full rationale
The paper describes a sequential pipeline that invokes off-the-shelf text-to-image generation and human mesh recovery models to produce front/back images, followed by SMPL alignment, inverted rasterization into UV space, diffusion inpainting, and fusion. No equations, fitted parameters, or derivations are presented that reduce the target texture output to the method's own inputs by construction. All load-bearing components are external and independently trained, so the approach remains self-contained against external benchmarks with no self-definitional, fitted-prediction, or self-citation-load-bearing steps.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Pre-trained text-to-image models can generate structurally consistent front-back human image pairs from natural language prompts
- domain assumption Human mesh recovery models produce accurate 2D-to-3D alignments on synthetically generated images
Reference graph
Works this paper leans on
-
[1]
Video-based reconstruction of 3d people models
Thiemo Alldieck, Marcus Magnor, Weipeng Xu, Christian Theobalt, and Gerard Pons-Moll. Video-based reconstruction of 3d people models. In CVPR, pages 8387–8397, 2018
work page 2018
-
[2]
A. Author and B. Author. Sith: A diffusion-based pipeline for hallucinating back-view textures from a front photo. In arXiv preprint arXiv:230X.XXXXX, 2023
work page 2023
-
[3]
C. Author and D. Author. Contex-human: Back-view synthesis for consistent 3d human texture estimation. In CVPR, pages 2345–2353, 2024
work page 2024
-
[4]
X. Author and Y . Author. Mvhumannet: Large-scale multi-view human dataset for 3d recon- struction. In CVPR, 2024
work page 2024
-
[5]
Simone Foti, Bongjin Koo, Danail Stoyanov, and Matthew J Clarkson. 3d shape variational autoencoder latent disentanglement via mini-batch feature swapping for bodies and faces. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages 18730–18739, 2022
work page 2022
-
[6]
Thuman2.0: A high-quality 3d human dataset
Qianru Guo et al. Thuman2.0: A high-quality 3d human dataset. In CVPR, 2020
work page 2020
-
[7]
Infinity: Scaling bitwise autoregressive modeling for high-resolution image synthesis
Jian Han, Jinlai Liu, Yi Jiang, Bin Yan, Yuqi Zhang, Zehuan Yuan, Bingyue Peng, and Xiaobing Liu. Infinity: Scaling bitwise autoregressive modeling for high-resolution image synthesis. arXiv preprint arXiv:2412.04431, 2024. 6
-
[8]
Avatarclip: Zero-shot text-driven generation and animation of 3d avatars,
Fangzhou Hong, Mingyuan Zhang, Liang Pan, Zhongang Cai, Lei Yang, and Ziwei Liu. Avatarclip: Zero-shot text-driven generation and animation of 3d avatars. arXiv preprint arXiv:2205.08535, 2022
-
[9]
Knuth: Computers and typesetting
Donald Knuth. Knuth: Computers and typesetting. URL http://www-cs-faculty. stanford.edu/~{}uno/abcde.html
-
[10]
Texdreamer: Towards zero-shot high-fidelity 3d human texture generation
Yufei Liu, Junwei Zhu, Junshu Tang, Shijie Zhang, Jiangning Zhang, Weijian Cao, Chengjie Wang, Yunsheng Wu, and Dongjin Huang. Texdreamer: Towards zero-shot high-fidelity 3d human texture generation. In European Conference on Computer Vision , pages 184–202. Springer, 2024
work page 2024
-
[11]
Deepfashion: Powering robust clothes recognition and retrieval
Ziwei Liu, Ping Luo, Shi Qiu, Xiaogang Wang, and Xiaoou Tang. Deepfashion: Powering robust clothes recognition and retrieval. In CVPR, pages 1096–1104, 2016
work page 2016
-
[12]
Smpl: A skinned multi-person linear model
Matthew Loper, Naureen Mahmood, Javier Romero, Gerard Pons-Moll, and Michael J Black. Smpl: A skinned multi-person linear model. In Seminal Graphics Papers: Pushing the Boundaries, V olume 2, pages 851–866. 2023
work page 2023
-
[13]
Addendum to GPT-4o system card: 4o image generation
OpenAI. Addendum to GPT-4o system card: 4o image generation. https://openai.com/ index/gpt-4o-image-generation-system-card-addendum/ , 2025. Accessed: 2025- 04-02
work page 2025
-
[14]
Training language models to follow instructions with human feedback
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. Advances in neural information processing systems , 35:27730–27744, 2022
work page 2022
-
[15]
Expressive body capture: 3d hands, face, and body from a single image
Georgios Pavlakos, Vasileios Choutas, Nima Ghorbani, Timo Bolkart, Ahmed AA Osman, Dimitrios Tzionas, and Michael J Black. Expressive body capture: 3d hands, face, and body from a single image. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10975–10985, 2019
work page 2019
-
[16]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International conference on machine learning , pages 8748–8763. PmLR, 2021
work page 2021
-
[17]
High- resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High- resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages 10684–10695, 2022
work page 2022
-
[18]
Score-guided diffusion for 3d human recovery
Anastasis Stathopoulos, Ligong Han, and Dimitris Metaxas. Score-guided diffusion for 3d human recovery. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 906–915, 2024
work page 2024
-
[19]
3d human texture estimation from a single image with transformers
Xiangyu Xu and Chen Change Loy. 3d human texture estimation from a single image with transformers. In Proceedings of the IEEE/CVF international conference on computer vision , pages 13849–13858, 2021
work page 2021
-
[20]
Human parsing based texture transfer from single image to 3d human via cross-view consistency
Fang Zhao, Shengcai Liao, Kaihao Zhang, and Ling Shao. Human parsing based texture transfer from single image to 3d human via cross-view consistency. In NeurIPS, pages 11240–11250, 2020
work page 2020
-
[21]
Market-1501: A benchmark for large scale person re-identification
Liang Zheng, Liyue Shen, Lu Tian, Shengjin Wang, Jingdong Wang, and Qiao Qi. Market-1501: A benchmark for large scale person re-identification. In ICCV, pages 1116–1124, 2015
work page 2015
-
[22]
Text-driven 3d human generation via contrastive preference optimization
Pengfei Zhou, Xukun Shen, and Yong Hu. Text-driven 3d human generation via contrastive preference optimization. arXiv preprint arXiv:2502.08977, 2025. 7
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.