A Multi-Level Causal Intervention Framework for Mechanistic Interpretability in Variational Autoencoders
Pith reviewed 2026-05-22 16:33 UTC · model grok-4.3
The pith
A multilevel causal intervention framework interprets variational autoencoders and reveals architecture trade-offs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
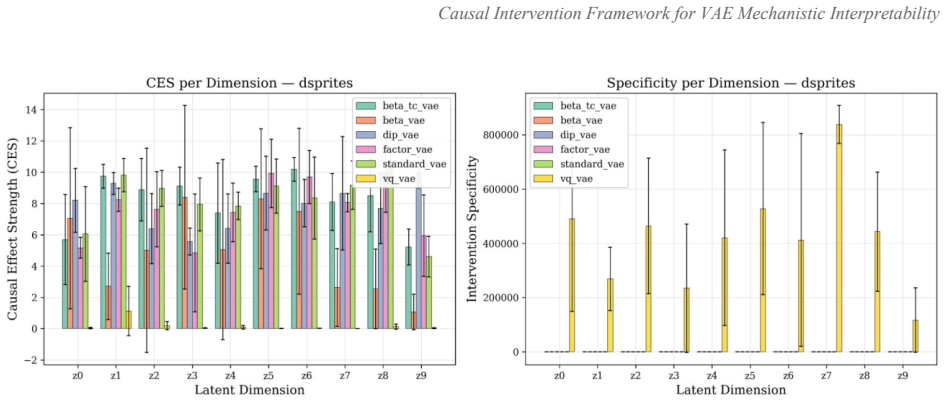
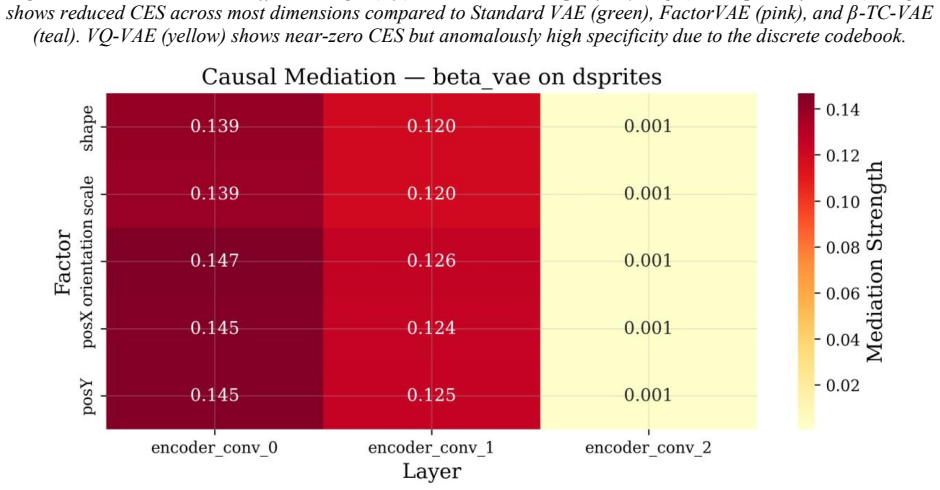
The paper establishes a multilevel causal intervention framework for VAEs that includes input manipulation, latent-space perturbation, activation patching, and causal mediation analysis, along with three new metrics: Causal Effect Strength, intervention specificity, and circuit modularity. This framework is used to conduct a large-scale empirical study showing a negative correlation between CES and DCI disentanglement, capacity bottlenecks in beta-VAE on complex data, no universally best architecture, and limitations of continuous metrics on discrete spaces.
What carries the argument
The multilevel causal intervention framework consisting of four manipulation types and three new quantitative metrics for assessing causal properties in VAE representations.
Where Pith is reading between the lines
- The framework could be adapted to compare causal structures in other generative models like diffusion models.
- Practitioners might use the new metrics to select or regularize VAE architectures based on dataset complexity.
- Extending the approach to larger models could test whether the CES-DCI trade-off scales with model size.
Load-bearing premise
The defined interventions isolate causal mechanisms in VAEs without confounding effects from training or architecture.
What would settle it
If targeted causal mediation on one latent factor fails to change only the corresponding output features while leaving others unaffected, the framework's isolation of mechanisms would be undermined.
Figures










read the original abstract
Understanding how generative models represent and transform data is a foundational problem in deep learning interpretability. While mechanistic interpretability of discriminative architectures has yielded substantial insights, relatively little work has addressed variational autoencoders (VAEs). This paper presents the first general-purpose multilevel causal intervention framework for mechanistic interpretability of VAEs. The framework comprises four manipulation types: input manipulation, latent-space perturbation, activation patching, and causal mediation analysis. We also define three new quantitative metrics capturing properties not measured by existing disentanglement metrics alone: Causal Effect Strength (CES), intervention specificity, and circuit modularity. We conduct the largest empirical study to date of VAE causal mechanisms across six architectures (standard VAE, beta-VAE, FactorVAE, beta-TC-VAE, DIP-VAE-II, and VQ-VAE) and five benchmarks (dSprites, 3DShapes, MPI3D, CelebA, and SmallNORB), with three seeds per configuration, totaling 90 independent training runs. Our results reveal several findings: (i) a consistent within-dataset negative correlation between CES and DCI disentanglement (the CES-DCI trade-off); (ii) that the KL reweighting mechanism of beta-VAE induces a capacity bottleneck when generative factors approach latent dimensionality, degrading disentanglement on complex datasets; (iii) that no single VAE architecture dominates across all five datasets, with optimal choice depending on dataset structure; and (iv) that CES-based metrics applied to discrete latent spaces (VQ-VAE) yield near-zero values, revealing a critical limitation of continuous-intervention methods for discrete representations. These results provide both a theoretical foundation and comprehensive empirical evaluation for mechanistic interpretability of generative models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents the first general-purpose multilevel causal intervention framework for mechanistic interpretability of VAEs. The framework includes four manipulation types (input manipulation, latent-space perturbation, activation patching, and causal mediation analysis) and defines three new metrics: Causal Effect Strength (CES), intervention specificity, and circuit modularity. It reports results from the largest empirical study to date, covering six VAE architectures and five datasets across 90 independent training runs, including findings on a CES-DCI trade-off, effects of KL reweighting in beta-VAE, architecture-dependent performance, and limitations of continuous interventions on discrete latents like VQ-VAE.
Significance. If the interventions validly isolate causal mechanisms, the work would provide a useful foundation and metrics for mechanistic interpretability of generative models, extending beyond existing disentanglement measures. The scale of the study (six architectures, five benchmarks, three seeds) and explicit reporting of multiple configurations are strengths that support reproducible comparisons and the observed trade-offs. The empirical findings on architecture-dataset interactions and discrete latent limitations add practical value.
major comments (2)
- [Section 3] The core claim that the four interventions cleanly reveal causal structure rests on the untested assumption that they are unconfounded by joint encoder-decoder training and ELBO optimization. In the intervention definitions and implementation details (Section 3), the manuscript should include ablations or controls demonstrating that CES and related metrics are not driven by reconstruction biases or variational posterior artifacts; without this, the CES-DCI trade-off and architecture comparisons lose mechanistic grounding.
- [Results section] The reported negative CES-DCI correlation is load-bearing for the trade-off claim. The results section should report statistical significance (e.g., p-values or confidence intervals) and controls for dataset complexity or latent dimensionality to confirm the correlation is not an artifact of specific benchmarks like dSprites versus CelebA.
minor comments (2)
- [Abstract] The abstract states 'the largest empirical study to date' but should explicitly note the total of 90 runs for immediate clarity.
- [Methods] Ensure the exact formulas for intervention specificity and circuit modularity are presented with consistent notation and pseudocode in the methods to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback on our manuscript. We address each major comment below and have incorporated revisions to strengthen the empirical grounding of our claims.
read point-by-point responses
-
Referee: [Section 3] The core claim that the four interventions cleanly reveal causal structure rests on the untested assumption that they are unconfounded by joint encoder-decoder training and ELBO optimization. In the intervention definitions and implementation details (Section 3), the manuscript should include ablations or controls demonstrating that CES and related metrics are not driven by reconstruction biases or variational posterior artifacts; without this, the CES-DCI trade-off and architecture comparisons lose mechanistic grounding.
Authors: We appreciate the referee's emphasis on rigorously ruling out confounds from joint training and ELBO optimization. Our intervention definitions aim to isolate effects at distinct levels, but we agree that explicit ablations would provide stronger evidence that CES, specificity, and modularity reflect causal mechanisms rather than reconstruction biases or posterior artifacts. In the revised manuscript, we will expand Section 3 with new controls, including (i) interventions on models with separately trained encoders/decoders and (ii) comparisons against fixed variational posteriors, to demonstrate that the metrics remain stable and retain their interpretive value. These additions will directly support the validity of the CES-DCI trade-off and cross-architecture comparisons. revision: yes
-
Referee: [Results section] The reported negative CES-DCI correlation is load-bearing for the trade-off claim. The results section should report statistical significance (e.g., p-values or confidence intervals) and controls for dataset complexity or latent dimensionality to confirm the correlation is not an artifact of specific benchmarks like dSprites versus CelebA.
Authors: We agree that statistical rigor and explicit controls are necessary to substantiate the CES-DCI trade-off. In the revised results section, we will report p-values and 95% confidence intervals for all within-dataset correlations. To address potential artifacts from benchmark-specific factors, we will include additional analyses such as partial correlations controlling for dataset complexity (measured by number of generative factors and image resolution) and latent dimensionality. While our study already spans five datasets with varying complexities and six architectures with different latent sizes, these controls will confirm that the negative correlation is not driven by particular dataset-architecture pairings. revision: yes
Circularity Check
No circularity: framework definitions and empirical observations are independent of inputs
full rationale
The paper defines a multilevel causal intervention framework consisting of input manipulation, latent perturbation, activation patching, and causal mediation analysis, then introduces three new metrics (CES, intervention specificity, circuit modularity) as direct functions of those intervention outcomes on trained VAEs. The reported findings, including the CES-DCI trade-off, architecture comparisons, and limitations for discrete latents, are presented as results from 90 independent empirical runs across datasets and models rather than any first-principles derivation or prediction that reduces to the definitions or fitted parameters by construction. No self-citation load-bearing steps, uniqueness theorems, or ansatzes are invoked in the provided text; the contribution is self-contained as definitional plus observational.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Interventions at input, latent, and activation levels correspond to causal manipulations in the generative process of VAEs.
invented entities (3)
-
Causal Effect Strength (CES)
no independent evidence
-
intervention specificity
no independent evidence
-
circuit modularity
no independent evidence
Forward citations
Cited by 2 Pith papers
-
Why Do Large Language Models Generate Harmful Content?
Causal mediation analysis shows harmful LLM outputs arise in late layers from MLP failures and gating neurons, with early layers handling harm context detection and signal propagation.
-
Posterior-Calibrated Causal Circuits in Variational Autoencoders: Why Image-Domain Interpretability Fails on Tabular Data
Tabular VAEs show ~50% lower causal circuit modularity than image VAEs, with beta-VAE CES collapsing to 0.043 versus 0.133 due to reconstruction degradation, challenging direct transfer of image interpretability techniques.
Reference graph
Works this paper leans on
-
[1]
C. Olah, A. Mordvintsev, and L. Schubert, "Feature visualization," Distill, vol. 2, no. 11, p. e7, 2017
work page 2017
-
[2]
A mathematical framework for transformer circuits,
N. Elhage et al., "A mathematical framework for transformer circuits," Anthropic, Tech. Rep., 2021
work page 2021
-
[3]
Interpretability in the wild: A circuit for indirect object identification in GPT -2 small,
K. Wang et al., "Interpretability in the wild: A circuit for indirect object identification in GPT -2 small," in Proc. Int. Conf. Learn. Represent. (ICLR), 2023
work page 2023
-
[4]
Network dissection: Quantifying interpretability of deep visual representations,
D. Bau, B. Zhou, A. Khosla, A. Oliva, and A. Torralba, "Network dissection: Quantifying interpretability of deep visual representations," in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2017, pp. 6541 –6549
work page 2017
-
[5]
Auto-encoding variational Bayes,
D. P. Kingma and M. Welling, "Auto-encoding variational Bayes," in Proc. Int. Conf. Learn. Represent. (ICLR), 2014
work page 2014
-
[6]
β-VAE: Learning basic visual concepts with a constrained variational framework,
I. Higgins et al., "β-VAE: Learning basic visual concepts with a constrained variational framework," in Proc. Int. Conf. Learn. Represent. (ICLR), 2017
work page 2017
-
[7]
H. Kim and A. Mnih, "Disentangling by factorising," in Proc. Int. Conf. Mach. Learn. (ICML), 2018, pp. 2649 – 2658
work page 2018
-
[8]
Isolating sources of disentanglement in variational autoencoders,
R. T. Q. Chen, X. Li, R. Grosse, and D. Duvenaud, "Isolating sources of disentanglement in variational autoencoders," in Adv. Neural Inf. Process. Syst. (NeurIPS), vol. 31, 2018
work page 2018
-
[9]
Variational inference of disentangled latent concepts from unlabeled observations,
A. Kumar, P. Sattigeri, and A. Balakrishnan, "Variational inference of disentangled latent concepts from unlabeled observations," in Proc. Int. Conf. Learn. Represent. (ICLR), 2018
work page 2018
-
[10]
Neural discrete representation learning,
A. van den Oord, O. Vinyals, and K. Kavukcuoglu, "Neural discrete representation learning," in Adv. Neural Inf. Process. Syst. (NeurIPS), vol. 30, 2017
work page 2017
-
[11]
A framework for the quantitative evaluation of disentangled representations,
C. Eastwood and C. K. I. Williams, "A framework for the quantitative evaluation of disentangled representations," in Proc. Int. Conf. Learn. Represent. (ICLR), 2018
work page 2018
-
[12]
Separated attribute predictability (SAP) score,
A. Kumar, P. Sattigeri, and A. Balakrishnan, "Separated attribute predictability (SAP) score," in Workshop Adv. Neural Inf. Process. Syst., 2018
work page 2018
-
[13]
Progress measures for grokking via mechanistic interpretability,
N. Nanda, L. Chan, T. Lieberum, J. Smith, and J. Steinhardt, "Progress measures for grokking via mechanistic interpretability," in Proc. Int. Conf. Learn. Represent. (ICLR), 2023
work page 2023
-
[14]
Challenging common assumptions in the unsupervised learning of disentangled representations,
F. Locatello et al., "Challenging common assumptions in the unsupervised learning of disentangled representations," in Proc. Int. Conf. Mach. Learn. (ICML), 2019, pp. 4114 –4124
work page 2019
-
[15]
Causal abstractions of neural networks,
A. Geiger, H. Lu, T. Icard, and C. Potts, "Causal abstractions of neural networks," in Adv. Neural Inf. Process. Syst. (NeurIPS), vol. 34, 2021
work page 2021
-
[16]
Locating and editing factual associations in GPT,
K. Meng, D. Bau, A. Andonian, and Y. Belinkov, "Locating and editing factual associations in GPT," in Adv. Neural Inf. Process. Syst. (NeurIPS), vol. 35, 2022
work page 2022
-
[17]
Investigating gender bias in language models using causal mediation analysis,
J. Vig, S. Gehrmann, Y. Belinkov, S. Qian, D. Nishi, Y. Zhang, and Y. Jernite, "Investigating gender bias in language models using causal mediation analysis," in Adv. Neural Inf. Process. Syst. (NeurIPS), vol. 33, 2020
work page 2020
-
[18]
N. Cammarata, S. Carter, G. Goh, C. Olah, M. Petrov, and L. Schubert, "Curve circuits," Distill, 2021
work page 2021
-
[19]
dSprites: Disentanglement testing sprites dataset,
L. Matthey, I. Higgins, D. Hassabis, and A. Lerchner, "dSprites: Disentanglement testing sprites dataset," GitHub Repository, 2017
work page 2017
-
[20]
C. Burgess and H. Kim, "3D shapes dataset," GitHub Repository, 2018
work page 2018
-
[21]
On the transfer of inductive bias from simulation to the real world: A new disentanglement dataset,
M. Gondal et al., "On the transfer of inductive bias from simulation to the real world: A new disentanglement dataset," in Adv. Neural Inf. Process. Syst. (NeurIPS), vol. 32, 2019
work page 2019
-
[22]
Deep learning face attributes in the wild,
Z. Liu, P. Luo, X. Wang, and X. Tang, "Deep learning face attributes in the wild," in Proc. IEEE Int. Conf. Comput. Vis. (ICCV), 2015, pp. 3730–3738. Causal Intervention Framework for VAE Mechanistic Interpretability 33
work page 2015
-
[23]
Learning methods for generic object recognition with invariance to pose and lighting,
Y. LeCun, F. J. Huang, and L. Bottou, "Learning methods for generic object recognition with invariance to pose and lighting," in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), vol. 2, 2004, pp. II –97
work page 2004
-
[24]
Experiment tracking with Weights and Biases,
L. Biewald, "Experiment tracking with Weights and Biases," Software available from wandb.com, 2020
work page 2020
-
[25]
Deep learning and the information bottleneck principle,
N. Tishby and N. Zaslavsky, "Deep learning and the information bottleneck principle," in Proc. IEEE Inf. Theory Workshop (ITW), 2015, pp. 1–5
work page 2015
-
[26]
Pearl, Causality: Models, Reasoning, and Inference, 2nd ed
J. Pearl, Causality: Models, Reasoning, and Inference, 2nd ed. Cambridge, U.K.: Cambridge Univ. Press, 2009
work page 2009
-
[27]
InfoVAE: Balancing learning and inference in variational autoencoders,
S. Zhao, J. Song, and S. Ermon, "InfoVAE: Balancing learning and inference in variational autoencoders," in Proc. AAAI Conf. Artif. Intell., vol. 33, 2019, pp. 5885–5892
work page 2019
-
[28]
Theory and evaluation metrics for learning disentangled representations,
K. Do and T. Tran, "Theory and evaluation metrics for learning disentangled representations," in Proc. Int. Conf. Learn. Represent. (ICLR), 2020
work page 2020
-
[29]
Visualizing and understanding generative adversarial networks,
D. Bau, J.-Y. Zhu, H. Strobelt, A. Lapedriza, B. Zhou, and A. Torralba, "Visualizing and understanding generative adversarial networks," in Proc. Int. Conf. Learn. Represent. (ICLR), 2019
work page 2019
-
[30]
Testing relational understanding in text-guided image generation,
C. Conwell, D. Mayo, M. Barbu, G. Buice, M. Cusimano, and B. Katz, "Testing relational understanding in text-guided image generation," arXiv preprint arXiv:2208.00005, 2022
-
[31]
CausalVAE: Disentangled representation learning via neural structural causal models,
M. Yang, F. Liu, Z. Chen, X. Shen, J. Hao, and J. Wang, "CausalVAE: Disentangled representation learning via neural structural causal models," in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2021, pp. 9593 – 9602
work page 2021
-
[32]
R. Suter, D. Miladinovic, B. Schölkopf, and S. Bauer, "Robustly disentangled causal mechanisms: Validating deep representations for interventional robustness," in Proc. Int. Conf. Mach. Learn. (ICML), 2019, pp. 6056 –6065
work page 2019
-
[33]
Disentangling disentanglement in variational autoencoders,
E. Mathieu, T. Rainforth, N. Siddharth, and Y. W. Teh, "Disentangling disentanglement in variational autoencoders," in Proc. Int. Conf. Mach. Learn. (ICML), 2019, pp. 4402–4412
work page 2019
-
[34]
Similarity of neural network representations revisited,
S. Kornblith, M. Norouzi, H. Lee, and G. Hinton, "Similarity of neural network representations revisited," in Proc. Int. Conf. Mach. Learn. (ICML), 2019, pp. 3519–3529
work page 2019
-
[35]
Deep variational information bottleneck,
A. A. Alemi, I. Fischer, J. V. Dillon, and K. Murphy, "Deep variational information bottleneck," in Proc. Int. Conf. Learn. Represent. (ICLR), 2017
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.