MojoFrame: Dataframe Library in Mojo Language
Pith reviewed 2026-05-25 08:03 UTC · model grok-4.3
The pith
MojoFrame is the first dataframe library built in Mojo and delivers up to 4.60x speedup on TPC-H queries.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
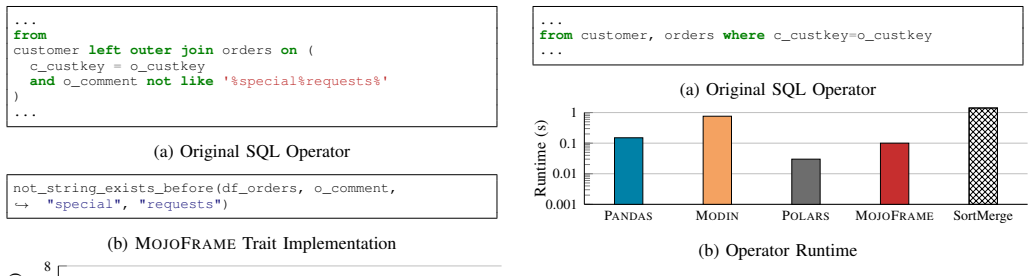
MojoFrame supports all operations for TPC-H queries and a selection of TPC-DS queries with promising performance, achieving up to 4.60x speedup versus existing dataframe libraries in other programming languages, by building on Mojo's tensor operations for numeric columns while using a cardinality-aware approach to integrate non-numeric columns.
What carries the argument
Mojo's tensor operations combined with a cardinality-aware approach for integrating non-numeric columns.
If this is right
- All TPC-H queries can be expressed and executed inside Mojo.
- Selected TPC-DS queries also run correctly.
- Numeric columns achieve high speed through direct tensor use.
- Non-numeric columns remain flexible via the cardinality-aware representation.
- Further gains are possible once in-memory layout and dictionary operations improve.
Where Pith is reading between the lines
- Data scientists could keep entire analytic pipelines inside one high-performance language instead of switching between Python and Mojo.
- The same tensor-plus-cardinality pattern might transfer to other MLIR-based languages that currently lack dataframe support.
- Dictionary-heavy workloads could become a natural next target for language-level improvements in Mojo.
Load-bearing premise
The tensor operations and cardinality-aware method can deliver efficient relational operations without major overheads from data representation or dictionary handling.
What would settle it
Running the full TPC-H benchmark suite on MojoFrame and finding that any query fails to complete or that wall-clock times show no speedup over Polars or pandas on identical hardware.
Figures












read the original abstract
Mojo is an emerging programming language built on MLIR (Multi-Level Intermediate Representation) and supports JIT (Just-in-Time) compilation. It enables transparent hardware-specific optimizations (e.g., for CPUs and GPUs), while allowing users to express their logic using Python-like user-friendly syntax. Mojo has demonstrated strong performance on tensor operations; however, its capabilities for relational operations (e.g., filtering, join, and group-by aggregation) common in data science workflows, remain unexplored. To date, no dataframe implementation exists in the Mojo ecosystem. In this paper, we introduce the first Mojo-native dataframe library, called MojoFrame, that supports core relational operations and user-defined functions (UDFs). MojoFrame is built on top of Mojo's tensor to achieve fast operations on numeric columns, while utilizing a cardinality-aware approach to effectively integrate non-numeric columns for flexible data representation. To achieve high efficiency, MojoFrame takes significantly different approaches than existing libraries. We show that MojoFrame supports all operations for TPC-H queries and a selection of TPC-DS queries with promising performance, achieving up to 4.60x speedup versus existing dataframe libraries in other programming languages. Nevertheless, there remain optimization opportunities for MojoFrame (and the Mojo language), particularly in in-memory data representation and dictionary operations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MojoFrame, the first dataframe library native to the Mojo language. It builds on Mojo's tensor primitives for numeric columns and a cardinality-aware representation for non-numeric columns to implement core relational operators (filter, join, group-by) plus UDF support. The central claim is that MojoFrame executes the full set of TPC-H queries and a selection of TPC-DS queries while delivering up to 4.60x speedup versus existing dataframe libraries.
Significance. If the performance results can be reproduced with full experimental disclosure, the work would demonstrate that Mojo's MLIR-based JIT can be leveraged for relational workloads, providing a new high-performance option for dataframe operations in a Python-like syntax. This could influence future language-specific dataframe designs and highlight trade-offs in tensor versus dictionary-based representations.
major comments (2)
- [Abstract] Abstract: The claim of 'up to 4.60x speedup versus existing dataframe libraries' is presented without any description of hardware platform, baseline library versions (Polars, Pandas, etc.), query selection or exclusion rules, data scale, or statistical reporting (error bars, multiple runs). This absence directly undermines verification of the central performance claim.
- [Abstract] Abstract and implementation description: The cardinality-aware approach for non-numeric columns is asserted to integrate 'effectively' with tensor operations for joins and group-by, yet the text explicitly flags remaining optimization needs in 'in-memory data representation and dictionary operations.' No cost model, overhead measurements, or mixed-type workload results are supplied to show that dictionary handling does not erode the reported speedups on realistic TPC-H/TPC-DS queries.
minor comments (1)
- The manuscript should include a dedicated experimental section with full reproducibility details (hardware, software versions, command lines) rather than embedding performance numbers only in the abstract.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and the description of the cardinality-aware representation. We address each major comment below, indicating where revisions will strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim of 'up to 4.60x speedup versus existing dataframe libraries' is presented without any description of hardware platform, baseline library versions (Polars, Pandas, etc.), query selection or exclusion rules, data scale, or statistical reporting (error bars, multiple runs). This absence directly undermines verification of the central performance claim.
Authors: We agree that the abstract would benefit from additional context on the experimental parameters to support the central claim. While the full details—including hardware platform, baseline versions (Polars 1.0+, Pandas 2.0+), TPC-H query coverage (all 22 queries), TPC-DS selection, data scale (SF=1), and statistical reporting (5 runs with standard deviation)—appear in Section 5, we will revise the abstract to include a concise summary of these elements. This change will improve verifiability without altering the manuscript's core results. revision: yes
-
Referee: [Abstract] Abstract and implementation description: The cardinality-aware approach for non-numeric columns is asserted to integrate 'effectively' with tensor operations for joins and group-by, yet the text explicitly flags remaining optimization needs in 'in-memory data representation and dictionary operations.' No cost model, overhead measurements, or mixed-type workload results are supplied to show that dictionary handling does not erode the reported speedups on realistic TPC-H/TPC-DS queries.
Authors: The manuscript already notes remaining optimization opportunities in dictionary operations. The reported speedups (up to 4.60x) were measured on the full TPC-H and selected TPC-DS queries, which contain mixed numeric and non-numeric columns; thus the results inherently reflect the combined tensor and cardinality-aware implementation. We did not develop a separate cost model or isolated overhead benchmarks for dictionary components. We will add a short discussion in the experimental section quantifying the contribution of non-numeric columns to overall runtime and clarifying that the observed gains demonstrate effective integration despite the acknowledged limitations. revision: partial
Circularity Check
No circularity: empirical implementation and benchmark paper
full rationale
This is an implementation paper introducing MojoFrame, a new dataframe library. It describes an approach using Mojo tensors for numeric columns and a cardinality-aware method for non-numeric columns, then reports empirical results on TPC-H and selected TPC-DS queries with speedups versus other libraries. No mathematical derivations, equations, fitted parameters, or predictions appear in the provided text. No self-citations are invoked as load-bearing premises for any claim. The central performance results are direct benchmarks, not reductions to prior results by construction. The paper is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Mojo language provides efficient tensor operations that can be leveraged for numeric columns in dataframes.
Reference graph
Works this paper leans on
-
[1]
Enhancing the interactiv- ity of dataframe queries by leveraging think time,
D. Xin, D. Petersohn, D. Tang, Y . Wu, J. E. Gonzalez, J. M. Hellerstein, A. D. Joseph, and A. G. Parameswaran, “Enhancing the interactiv- ity of dataframe queries by leveraging think time,”arXiv preprint arXiv:2103.02145, 2021
-
[2]
Seedb: Efficient data-driven visualization recommendations to support visual analytics,
M. Vartak, S. Rahman, S. Madden, A. Parameswaran, and N. Polyzotis, “Seedb: Efficient data-driven visualization recommendations to support visual analytics,” inProceedings of the VLDB Endowment International Conference on Very Large Data Bases, vol. 8, no. 13, 2015, p. 2182
work page 2015
-
[3]
Northstar: An interactive data science system,
T. Kraska, “Northstar: An interactive data science system,” 2021
work page 2021
-
[4]
Data cleaning: Overview and emerging challenges,
X. Chu, I. F. Ilyas, S. Krishnan, and J. Wang, “Data cleaning: Overview and emerging challenges,” inProceedings of the 2016 international conference on management of data, 2016, pp. 2201–2206
work page 2016
-
[5]
E. De Jonge and M. Van Der Loo,An introduction to data cleaning with R. Statistics Netherlands The Hague, 2013
work page 2013
-
[6]
Scaling joins to a thousand gpus
H. Gao and N. Sakharnykh, “Scaling joins to a thousand gpus.” in ADMS@ VLDB, 2021, pp. 55–64
work page 2021
-
[7]
G. Dong and H. Liu,Feature engineering for machine learning and data analytics. CRC press, 2018
work page 2018
-
[8]
Enhancing computational notebooks with code+data space versioning,
H. Fang, S. Chockchowwat, H. Sundaram, and Y . Park, “Enhancing computational notebooks with code+data space versioning,” inCHI Conference on Human Factors in Computing Systems (Chi ’25), 2025
work page 2025
-
[9]
Large-scale evaluation of notebook checkpointing with ai agents,
——, “Large-scale evaluation of notebook checkpointing with ai agents,” inLate-breaking work in CHI Conference on Human Factors in Computing Systems (Chi ’25), 2025
work page 2025
-
[10]
Learning multi-agent intention-aware commu- nication for optimal multi-order execution in finance,
Y . Fang, Z. Tang, K. Ren, W. Liu, L. Zhao, J. Bian, D. Li, W. Zhang, Y . Yu, and T.-Y . Liu, “Learning multi-agent intention-aware commu- nication for optimal multi-order execution in finance,” inProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2023, pp. 4003–4012
work page 2023
-
[11]
Towards scalable dataframe systems,
D. Petersohn, S. Macke, D. Xin, W. Ma, D. Lee, X. Mo, J. E. Gonzalez, J. M. Hellerstein, A. D. Joseph, and A. Parameswaran, “Towards scalable dataframe systems,”arXiv preprint arXiv:2001.00888, 2020
-
[12]
Y . Wu, “Is a dataframe just a table?” in10th Workshop on Evaluation and Usability of Programming Languages and Tools (PLATEAU 2019). Schloss Dagstuhl–Leibniz-Zentrum für Informatik, 2020, pp. 6–1
work page 2019
-
[13]
Petersohn,Dataframe systems: Theory, architecture, and implemen- tation
D. Petersohn,Dataframe systems: Theory, architecture, and implemen- tation. University of California, Berkeley, 2021
work page 2021
- [14]
-
[15]
Flexible rule-based decom- position and metadata independence in modin: a parallel dataframe system,
D. Petersohn, D. Tang, R. Durrani, A. Melik-Adamyan, J. E. Gonzalez, A. D. Joseph, and A. G. Parameswaran, “Flexible rule-based decom- position and metadata independence in modin: a parallel dataframe system,”Proceedings of the VLDB Endowment, vol. 15, no. 3, 2021
work page 2021
-
[16]
Polars - dataframes for the new era,
Polars, “Polars - dataframes for the new era,” https://pola.rs/, 2024, [Accessed: Apr. 27, 2025]
work page 2024
-
[17]
Rdocumentation, “R - data.frame: Data frames,” https://www.rdocum entation.org/packages/base/versions/3.6.2/topics/data.frame, 2024, [Accessed: Apr. 27, 2025]
work page 2024
-
[18]
Spark sql, dataframes and datasets guide,
Spark, “Spark sql, dataframes and datasets guide,” https://spark.apac he.org/docs/latest/sql-programming-guide.html, 2024, [Accessed: Apr. 27, 2025]
work page 2024
-
[19]
K. Kho, “Pandas udf benchmark,” https://medium.com/fugue-project /benchmarking-pyspark-pandas-pandas-udfs-and-fugue-polars-198c3 109a226, 2024, [Accessed: Apr. 27, 2025]
work page 2024
-
[20]
Polars, “Polars - lazyframe,” https://docs.pola.rs/py-polars/html/refer ence/lazyframe/index.html, 2024, [Accessed: Apr. 27, 2025]
work page 2024
-
[21]
——, “Polars - series,” https://docs.rs/polars/latest/polars/prelude/struc t.Series.html, 2024, [Accessed: Apr. 27, 2025]
work page 2024
-
[22]
Jit compilation policy for modern machines,
P. A. Kulkarni, “Jit compilation policy for modern machines,” in Proceedings of the 2011 ACM international conference on Object oriented programming systems languages and applications, 2011, pp. 773–788
work page 2011
-
[23]
Mlir: A compiler infrastructure for the end of moore’s law,
C. Lattner, M. Amini, U. Bondhugula, A. Cohen, A. Davis, J. Pienaar, R. Riddle, T. Shpeisman, N. Vasilache, and O. Zinenko, “Mlir: A compiler infrastructure for the end of moore’s law,”arXiv preprint arXiv:2002.11054, 2020
-
[24]
Mojo - powerful cpu+gpu programming,
Modular, “Mojo - powerful cpu+gpu programming,” https://www.mo dular.com/mojo, 2024, [Accessed: Apr. 27, 2025]
work page 2024
-
[25]
Mojo vs python - performance benchmark,
A. Upadhyay, “Mojo vs python - performance benchmark,” https://ww w.linkedin.com/pulse/mojo-vs-python-performance-comparison-abhin av-upadhyay/, 2024, [Accessed: Apr. 27, 2025]
work page 2024
-
[26]
Mojo vs. rust: what are the differences?
Modular, “Mojo vs. rust: what are the differences?” https://www.mo dular.com/blog/mojo-vs-rust, 2024, [Accessed: Apr. 27, 2025]
work page 2024
-
[27]
What is the mojo way of using/replacing pandas/- dataframes?
C. Johnson, “What is the mojo way of using/replacing pandas/- dataframes?” https://github.com/modular/max/discussions/1446, 2024, [Accessed: Apr. 27, 2025]
work page 2024
-
[28]
mojo/stdlib/src/collections/dict.mojo,
Modular, “mojo/stdlib/src/collections/dict.mojo,” https://github.com/m odular/max/blob/ae1fd8000b5904341dcb40460bec93381f534acc/moj o/stdlib/src/collections/dict.mojo, 2024, [Accessed: Apr. 27, 2025]
work page 2024
-
[29]
Why is mojo’s dictionary (or for loop) slower than python’s?
E. Brown, “Why is mojo’s dictionary (or for loop) slower than python’s?” https://github.com/modular/max/discussions/1747, 2024, [Accessed: Apr. 27, 2025]
work page 2024
-
[30]
Description of the CUDF Format
R. Treinen and S. Zacchiroli, “Description of the cudf format,”arXiv preprint arXiv:0811.3621, 2008
work page internal anchor Pith review Pith/arXiv arXiv 2008
-
[31]
Cupy: A numpy-compatible library for nvidia gpu calculations,
R. Nishino and S. H. C. Loomis, “Cupy: A numpy-compatible library for nvidia gpu calculations,”31st confernce on neural information processing systems, vol. 151, no. 7, 2017
work page 2017
-
[32]
Sql for gpu data frames in rapids accelerating end-to-end data science workflows using gpus,
A. Ocsa, “Sql for gpu data frames in rapids accelerating end-to-end data science workflows using gpus,” inLatinX in AI Research at ICML 2019, 2019
work page 2019
-
[33]
anilshanbhag, “Crystal gpu library,” https://github.com/anilshanbhag/ crystal, 2024, [Accessed: Apr. 27, 2025]
work page 2024
- [34]
-
[35]
S/c: Speeding up data materialization with bounded memory,
Z. Li, X. Pi, and Y . Park, “S/c: Speeding up data materialization with bounded memory,” in2023 IEEE 39th international conference on data engineering (ICDE). IEEE, 2023, pp. 1981–1994
work page 2023
-
[36]
An overview of decision support benchmarks: Tpc-ds, tpc-h and ssb,
M. Barata, J. Bernardino, and P. Furtado, “An overview of decision support benchmarks: Tpc-ds, tpc-h and ssb,”New Contributions in Information Systems and Technologies: Volume 1, pp. 619–628, 2015
work page 2015
-
[37]
Tensorflow, “Tensorflow graph,” https://www.tensorflow.org/api_docs /python/tf/Graph, 2024, [Accessed: Apr. 27, 2025]
work page 2024
-
[38]
Modin - scale your pandas workflows by changing one line of code,
modin project, “Modin - scale your pandas workflows by changing one line of code,” https://github.com/modin-project/modin, 2024, [Accessed: Apr. 27, 2025]
work page 2024
-
[39]
Dask, “Dask dataframe,” https://docs.dask.org/en/stable/dataframe.ht ml, 2024, [Accessed: Apr. 27, 2025]
work page 2024
-
[40]
Dias: Dynamic rewriting of pandas code,
S. Baziotis, D. Kang, and C. Mendis, “Dias: Dynamic rewriting of pandas code,”Proceedings of the ACM on Management of Data, vol. 2, no. 1, pp. 1–27, 2024
work page 2024
-
[41]
Julia discourse, “Frustrated using dataframes,” https://discourse.julial ang.org/t/frustrated-using-dataframes/67833, 2024, [Accessed: Apr. 27, 2025]
work page 2024
-
[42]
Scaling your hybrid cpu-gpu dbms to multiple gpus,
B. Yogatama, W. Gong, and X. Yu, “Scaling your hybrid cpu-gpu dbms to multiple gpus,”Proceedings of the VLDB Endowment, vol. 17, no. 13, pp. 4709–4722, 2024
work page 2024
-
[43]
B. Yogatama, B. Miller, Y . Wang, G. Markall, J. Hemstad, G. Kimball, and X. Yu, “Accelerating user-defined aggregate functions (udaf) with block-wide execution and jit compilation on gpus,” inProceedings of the 19th International Workshop on Data Management on New Hardware, 2023, pp. 19–26
work page 2023
-
[44]
Farber,CUDA application design and development
R. Farber,CUDA application design and development. Elsevier, 2011
work page 2011
-
[45]
Accelerated pytorch training on mac,
Apple, “Accelerated pytorch training on mac,” https://developer.apple. com/metal/pytorch/, 2024, [Accessed: Apr. 27, 2025]
work page 2024
-
[46]
PyTorch, “Getting started on intel gpu,” https://pytorch.org/docs/stabl e/notes/get_start_xpu.html, 2024, [Accessed: Apr. 27, 2025]
work page 2024
-
[47]
Modular, “Mojo - gpu operations,” https://docs.modular.com/max/tut orials/build-custom-ops/, 2024, [Accessed: Apr. 27, 2025]
work page 2024
-
[48]
Mojo - gpu programming tutorial,
——, “Mojo - gpu programming tutorial,” https://docs.modular.com /mojo/manual/gpu/intro-tutorial/, 2024, [Accessed: Apr. 27, 2025]
work page 2024
- [49]
-
[50]
TensorFlow, “tf.tensor,” https://www.tensorflow.org/api_docs/python/tf /Tensor, 2024, [Accessed: Apr. 27, 2025]
work page 2024
-
[51]
Scipy - fundamental algorithms for scientific computing in python,
SciPy, “Scipy - fundamental algorithms for scientific computing in python,” https://scipy.org/, 2024, [Accessed: Apr. 27, 2025]
work page 2024
-
[52]
The Matplotlib Development Team, “Matplotlib,” https://matplotlib.o rg/, 2023
work page 2023
-
[53]
seaborn: statistical data visualization,
M. Waskom, “seaborn: statistical data visualization,” https://seaborn. pydata.org/, 2024, [Accessed: Apr. 27, 2025]
work page 2024
-
[54]
The case for a next-generation ai developer platform,
Modular, “The case for a next-generation ai developer platform,” https: //www.modular.com/blog/the-case-for-a-next-generation-ai-developer -platform, 2024, [Accessed: Apr. 27, 2025]
work page 2024
-
[55]
Python, “The python standard library,” https://docs.python.org/3/librar y/index.html, 2024, [Accessed: Apr. 27, 2025]
work page 2024
-
[56]
Enhancing ai development with mojo: Code examples and best practices,
T. Leonard, “Enhancing ai development with mojo: Code examples and best practices,” https://medium.com/artificial-corner/enhancing-ai-dev elopment-with-mojo-code-examples-and-best-practices-6341c3e66e1 5, 2024, [Accessed: Apr. 27, 2025]
work page 2024
- [57]
-
[58]
parquet, “Apache parquet,” parquet.apache.org, [Accessed: Apr. 27, 2025]
work page 2025
-
[59]
Pandas, “Orc table format,” https://github.com/pandas-dev/pandas/bl ob/main/pandas/core/reshape/merge.py, [Accessed: Apr. 27, 2025]
work page 2025
-
[60]
Apache arrow - pandas integration,
Apache Arrow, “Apache arrow - pandas integration,” https://arrow.ap ache.org/docs/python/pandas.html, 2024, [Accessed: Apr. 27, 2025]
work page 2024
-
[61]
G. Fritchey, “Row-by-row processing,” inSQL Server Query Perfor- mance Tuning. Springer, 2014, pp. 459–481
work page 2014
-
[62]
Pola-rs, “Polars - df.apply,” https://docs.pola.rs/docs/python/version /0.18/reference/dataframe/api/polars.DataFrame.apply.html, 2024, [Accessed: Apr. 27, 2025]
work page 2024
-
[63]
Pandas, “Pandas - df.apply,” https://pandas.pydata.org/docs/reference/a pi/pandas.DataFrame.apply.html, 2024, [Accessed: Apr. 27, 2025]
work page 2024
-
[64]
Functional-style sql udfs with a capital’f’,
C. Duta and T. Grust, “Functional-style sql udfs with a capital’f’,” in Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data, 2020, pp. 1273–1287
work page 2020
-
[65]
Automated translation of functional big data queries to sql,
G. Zhang, B. Mariano, X. Shen, and I. Dillig, “Automated translation of functional big data queries to sql,”Proceedings of the ACM on Programming Languages, vol. 7, no. OOPSLA1, pp. 580–608, 2023
work page 2023
-
[66]
Numba, “Numba - argsort,” https://github.com/numba/numba/issues/ 4636, 2024, [Accessed: Apr. 27, 2025]
work page 2024
-
[67]
Pandas, “Pandas - hashing,” https://github.com/pandas-dev/pandas/bl ob/v2.2.3/pandas/_libs/hashing.pyx, 2024, [Accessed: Apr. 27, 2025]
work page 2024
-
[68]
xxhash - extremely fast non-cryptographic hash algorithm,
Y . Collet, “xxhash - extremely fast non-cryptographic hash algorithm,” https://github.com/Cyan4973/xxHash, 2023, [Accessed: Apr. 27, 2025]
work page 2023
-
[69]
[bug] dict.getitem always returns immutable references,
S. Fischer, “[bug] dict.getitem always returns immutable references,” https://github.com/modular/modular/issues/4695, 2024, [Accessed: Apr. 27, 2025]
work page 2024
-
[70]
Tpc-h version 2 and version 3,
TPC, “Tpc-h version 2 and version 3,” https://www.tpc.org/tpch/, 2024, [Accessed: Apr. 27, 2025]
work page 2024
-
[71]
Pandas, “Pandas - factorize,” https://pandas.pydata.org/docs/reference /api/pandas.factorize.html, [Accessed: Apr. 27, 2025]
work page 2025
-
[72]
——, “Pandas - join,” https://github.com/pandas-dev/pandas/blob/mai n/pandas/core/reshape/merge.py, [Accessed: Apr. 27, 2025]
work page 2025
-
[73]
The quest for faster join algorithms (invited talk),
P. Koutris, S. Deep, A. Fan, and H. Zhao, “The quest for faster join algorithms (invited talk),” in28th International Conference on Database Theory (ICDT 2025). Schloss Dagstuhl–Leibniz-Zentrum für Informatik, 2025, pp. 1–1
work page 2025
-
[74]
R. Barber, G. Lohman, I. Pandis, V . Raman, R. Sidle, G. Attaluri, N. Chainani, S. Lightstone, and D. Sharpe, “Memory-efficient hash joins,”Proceedings of the VLDB Endowment, vol. 8, no. 4, pp. 353– 364, 2014
work page 2014
-
[75]
Method chaining redux: An empirical study of method chaining in java, kotlin, and python,
A. M. Keshk and R. Dyer, “Method chaining redux: An empirical study of method chaining in java, kotlin, and python,” in2023 IEEE/ACM 20th International Conference on Mining Software Repositories (MSR). IEEE, 2023, pp. 546–557
work page 2023
-
[76]
Polars, “polars - read parquet,” https://docs.pola.rs/api/python/stable /reference/api/polars.read_parquet.html, 2024, [Accessed: Apr. 27, 2025]
work page 2024
-
[77]
[feature request] short string optimization (sso) when a string is constructed from a literal,
N. Smith, “[feature request] short string optimization (sso) when a string is constructed from a literal,” https://github.com/modular/modul ar/issues/4395, 2025, [Accessed: Apr. 27, 2025]
work page 2025
-
[78]
Mojoframe: Dataframe library in mojo language,
Mojo community, “Mojoframe: Dataframe library in mojo language,” https://discord.com/channels/1087530497313357884/1371394518062 075976, 2024, [Accessed: Apr. 27, 2025]
-
[79]
Modular, “Mojo roadmap,” https://docs.modular.com/mojo/roadmap/, 2024, [Accessed: Apr. 27, 2025]
work page 2024
-
[80]
Microsoft Azure, “Azure vm - disk types,” https://learn.microsoft.com/ en-us/azure/virtual-machines/disks-types, 2024, [Accessed: Apr. 27, 2025]
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.