EAM: Enhancing Anything with Diffusion Transformers for Blind Super-Resolution
Pith reviewed 2026-05-22 15:59 UTC · model grok-4.3
The pith
A diffusion transformer model called EAM guides blind super-resolution by injecting low-resolution latents into pre-trained priors using a new Ψ-DiT block.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
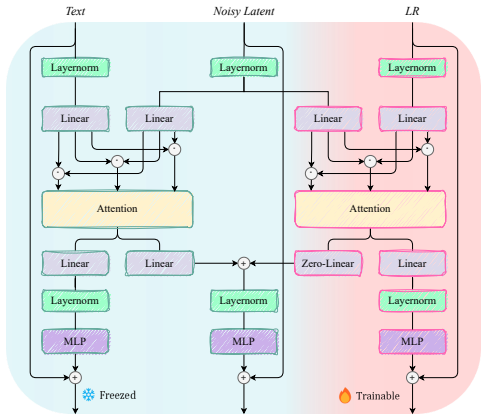
By replacing U-Net backbones with Diffusion Transformers and introducing the Ψ-DiT block that employs low-resolution latent as a separable flow injection control to form a triple-flow architecture, along with progressive Masked Image Modeling and subject-aware prompt generation, EAM effectively leverages pre-trained T2I priors to achieve superior blind super-resolution results compared to previous approaches.
What carries the argument
The Ψ-DiT block, which integrates low-resolution latent injection as a separable flow to guide the pre-trained DiT in a triple-flow architecture for image restoration.
If this is right
- EAM achieves state-of-the-art quantitative metrics and visual quality on multiple blind super-resolution datasets.
- The progressive Masked Image Modeling strategy reduces training costs while fully exploiting the prior guidance of T2I models.
- Subject-aware prompt generation improves the utilization of diffusion priors for better generalization in blind super-resolution.
- Diffusion Transformers can outperform U-Net architectures when properly guided for low-level vision tasks like super-resolution.
Where Pith is reading between the lines
- If the triple-flow injection works well here, similar separable control mechanisms could adapt DiT models to other image enhancement tasks such as denoising or inpainting.
- The automatic prompt generation via in-context learning might be extended to create more precise conditioning for any text-to-image based restoration pipeline.
- Lower training costs from the masked modeling approach could encourage wider adoption of large pre-trained diffusion models in resource-limited settings for fine-tuning on restoration datasets.
Load-bearing premise
The pre-trained DiT already encodes sufficiently rich priors for blind super-resolution restoration, and the low-resolution latent injection plus subject-aware prompts can reliably steer those priors without introducing new artifacts or mode collapse.
What would settle it
Running EAM on a held-out test set of images with novel real-world degradations and finding that its PSNR or perceptual scores fall below those of the leading U-Net based method.
Figures





read the original abstract
Utilizing pre-trained Text-to-Image (T2I) diffusion models to guide Blind Super-Resolution (BSR) has become a predominant approach in the field. While T2I models have traditionally relied on U-Net architectures, recent advancements have demonstrated that Diffusion Transformers (DiT) achieve significantly higher performance in this domain. In this work, we introduce Enhancing Anything Model (EAM), a novel BSR method that leverages DiT and outperforms previous U-Net-based approaches. We introduce a novel block, $\Psi$-DiT, which effectively guides the DiT to enhance image restoration. This block employs a low-resolution latent as a separable flow injection control, forming a triple-flow architecture that effectively leverages the prior knowledge embedded in the pre-trained DiT. To fully exploit the prior guidance capabilities of T2I models and enhance their generalization in BSR, we introduce a progressive Masked Image Modeling strategy, which also reduces training costs. Additionally, we propose a subject-aware prompt generation strategy that employs a robust multi-modal model in an in-context learning framework. This strategy automatically identifies key image areas, provides detailed descriptions, and optimizes the utilization of T2I diffusion priors. Our experiments demonstrate that EAM achieves state-of-the-art results across multiple datasets, outperforming existing methods in both quantitative metrics and visual quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Enhancing Anything Model (EAM) for blind super-resolution. It leverages pre-trained Diffusion Transformers (DiT) rather than U-Nets and proposes a novel Ψ-DiT block that injects low-resolution latent as a separable flow to form a triple-flow architecture, thereby guiding the DiT priors. Additional contributions include a progressive Masked Image Modeling strategy to exploit priors while lowering training costs and a subject-aware prompt generation approach that uses multi-modal models in an in-context learning framework. The paper claims state-of-the-art quantitative and visual results across multiple datasets.
Significance. If the central claims hold, the work would be significant for demonstrating that DiT architectures can outperform prior U-Net-based T2I-guided methods in blind super-resolution. The Ψ-DiT triple-flow design and progressive MIM strategy represent concrete architectural and training innovations for steering generative priors in restoration tasks, with potential benefits for generalization and efficiency. The subject-aware prompt mechanism addresses a practical challenge in utilizing T2I models for low-level vision.
major comments (2)
- [Ψ-DiT block (methods)] In the Ψ-DiT block description (methods section): the low-resolution latent is presented as a separable flow injection that steers pre-trained DiT priors without artifacts or mode collapse for arbitrary degradations, yet no derivation of the injection operator, explicit alignment with timestep/conditioning spaces, or ablation isolating its contribution from the subject-aware prompts is provided. This assumption is load-bearing for the SOTA claim.
- [Experiments] Experiments section: the assertion of state-of-the-art results across datasets lacks accompanying quantitative tables, error bars, or ablations on the progressive Masked Image Modeling strategy, preventing verification that performance gains are attributable to the proposed components rather than dataset or metric choices.
minor comments (2)
- [Abstract] The abstract repeats the phrase 'prior knowledge' and 'T2I priors' in consecutive sentences; rephrasing would improve readability.
- [Figure 2 or methods] A diagram illustrating the triple-flow architecture of the Ψ-DiT block would clarify the separable injection mechanism for readers.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review of our manuscript. The feedback highlights key areas where additional clarity and validation can strengthen the presentation of the Ψ-DiT block and the experimental results. We address each major comment below and commit to incorporating the suggested revisions in the next version of the paper.
read point-by-point responses
-
Referee: [Ψ-DiT block (methods)] In the Ψ-DiT block description (methods section): the low-resolution latent is presented as a separable flow injection that steers pre-trained DiT priors without artifacts or mode collapse for arbitrary degradations, yet no derivation of the injection operator, explicit alignment with timestep/conditioning spaces, or ablation isolating its contribution from the subject-aware prompts is provided. This assumption is load-bearing for the SOTA claim.
Authors: We agree that a more formal treatment of the injection mechanism would improve rigor. The current methods section describes the Ψ-DiT as a triple-flow architecture in which the low-resolution latent is injected as a separable flow to condition the pre-trained DiT priors. In the revised manuscript we will add an explicit mathematical derivation of the injection operator, including its formulation and how it aligns with the diffusion timestep embedding and cross-attention conditioning spaces. We will also include a new ablation that fixes the subject-aware prompting strategy and varies only the presence of the Ψ-DiT block, thereby isolating its contribution to the reported performance gains. revision: yes
-
Referee: [Experiments] Experiments section: the assertion of state-of-the-art results across datasets lacks accompanying quantitative tables, error bars, or ablations on the progressive Masked Image Modeling strategy, preventing verification that performance gains are attributable to the proposed components rather than dataset or metric choices.
Authors: We acknowledge that the experimental section would benefit from greater transparency. While the manuscript reports state-of-the-art quantitative and visual results, the revised version will expand the experiments section to include complete quantitative tables with PSNR, SSIM, and LPIPS scores across all evaluated datasets, accompanied by error bars obtained from multiple independent runs with different random seeds. We will further add dedicated ablations that isolate the progressive Masked Image Modeling strategy, comparing it against non-progressive and baseline MIM variants while holding other components fixed. These additions will allow readers to attribute performance differences directly to the proposed training strategy. revision: yes
Circularity Check
No circularity: novel architectural blocks and empirical SOTA claims are self-contained
full rationale
The paper's core contributions consist of a new Ψ-DiT block implementing low-resolution latent injection into a pre-trained DiT, a progressive Masked Image Modeling training strategy, and a subject-aware prompt generation method. These are presented as engineering innovations whose performance is validated through experiments on multiple datasets rather than derived mathematically from prior fitted quantities or self-citations. No equations or claims reduce a prediction to its own inputs by construction, and the abstract and methods description contain no load-bearing self-citations or uniqueness theorems imported from the authors' prior work. The derivation chain is therefore independent of the reported results.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce a novel block, Ψ-DiT, which effectively guides the DiT to enhance image restoration. This block employs a low-resolution latent as a separable flow injection control, forming a triple-flow architecture
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we introduce a progressive Masked Image Modeling strategy, which also reduces training costs
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Ntire 2017 challenge on single image super-resolution: Dataset and study
Eirikur Agustsson and Radu Timofte. Ntire 2017 challenge on single image super-resolution: Dataset and study. InCVPRW, 2017
work page 2017
-
[2]
Image super-resolution using deep convolutional networks, 2015
Chao Dong, Chen Change Loy, Kaiming He, and Xiaoou Tang. Image super-resolution using deep convolutional networks, 2015
work page 2015
-
[3]
Scaling rectified flow transformers for high-resolution image synthesis, 2024
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, Dustin Podell, Tim Dockhorn, Zion English, Kyle Lacey, Alex Goodwin, Yannik Marek, and Robin Rombach. Scaling rectified flow transformers for high-resolution image synthesis, 2024
work page 2024
-
[4]
Scaling up to excellence: Practicing model scaling for photo-realistic image restoration in the wild
Zheyuan Li Fanghua Yu, Jinjin Gu. Scaling up to excellence: Practicing model scaling for photo-realistic image restoration in the wild. InCVPR, 2024. 10
work page 2024
-
[5]
Generative adversarial nets.Advances in neural information processing systems, 27, 2014
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets.Advances in neural information processing systems, 27, 2014
work page 2014
-
[6]
Masked autoencoders are scalable vision learners, 2021
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick. Masked autoencoders are scalable vision learners, 2021
work page 2021
-
[7]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
work page 2020
-
[8]
Minicpm: Unveiling the potential of small language models with scalable training strategies, 2024
Shengding Hu, Yuge Tu, Xu Han, Chaoqun He, Ganqu Cui, Xiang Long, Zhi Zheng, Yewei Fang, Yuxiang Huang, Weilin Zhao, Xinrong Zhang, Zheng Leng Thai, Kaihuo Zhang, Chongyi Wang, Yuan Yao, Chenyang Zhao, Jie Zhou, Jie Cai, Zhongwu Zhai, Ning Ding, Chao Jia, Guoyang Zeng, Dahai Li, Zhiyuan Liu, and Maosong Sun. Minicpm: Unveiling the potential of small langu...
work page 2024
-
[9]
Lightweight image super-resolution with information multi-distillation network
Zheng Hui, Xinbo Gao, Yunchu Yang, and Xiumei Wang. Lightweight image super-resolution with information multi-distillation network. InProceedings of the 27th ACM International Conference on Multimedia, MM ’19. ACM, October 2019
work page 2019
-
[10]
Ntire 2024 restore any image model (raim) in the wild challenge
Qiaosi Yi Jie Liang, Radu Timofte. Ntire 2024 restore any image model (raim) in the wild challenge. InCVPR, 2024
work page 2024
-
[11]
A style-based generator architecture for generative adversarial networks
Tero Karras, Samuli Laine, and Timo Aila. A style-based generator architecture for generative adversarial networks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4401–4410, 2019
work page 2019
-
[12]
Musiq: Multi-scale image quality transformer, 2021
Junjie Ke, Qifei Wang, Yilin Wang, Peyman Milanfar, and Feng Yang. Musiq: Multi-scale image quality transformer, 2021
work page 2021
-
[13]
Accurate image super-resolution using very deep convolutional networks, 2016
Jiwon Kim, Jung Kwon Lee, and Kyoung Mu Lee. Accurate image super-resolution using very deep convolutional networks, 2016
work page 2016
-
[14]
Photo- realistic single image super-resolution using a generative adversarial network, 2017
Christian Ledig, Lucas Theis, Ferenc Huszar, Jose Caballero, Andrew Cunningham, Alejandro Acosta, Andrew Aitken, Alykhan Tejani, Johannes Totz, Zehan Wang, and Wenzhe Shi. Photo- realistic single image super-resolution using a generative adversarial network, 2017
work page 2017
-
[15]
Controlnet++: Improving conditional controls with efficient consistency feedback, 2024
Ming Li, Taojiannan Yang, Huafeng Kuang, Jie Wu, Zhaoning Wang, Xuefeng Xiao, and Chen Chen. Controlnet++: Improving conditional controls with efficient consistency feedback, 2024
work page 2024
-
[16]
Lsdir: A large scale dataset for image restoration
Yawei Li, Kai Zhang, Jingyun Liang, Jiezhang Cao, Ce Liu, Rui Gong, Yulun Zhang, Hao Tang, Yun Liu, Denis Demandolx, et al. Lsdir: A large scale dataset for image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1775–1787, 2023
work page 2023
-
[17]
Zhimin Li, Jianwei Zhang, Qin Lin, Jiangfeng Xiong, Yanxin Long, Xinchi Deng, Yingfang Zhang, Xingchao Liu, Minbin Huang, Zedong Xiao, Dayou Chen, Jiajun He, Jiahao Li, Wenyue Li, Chen Zhang, Rongwei Quan, Jianxiang Lu, Jiabin Huang, Xiaoyan Yuan, Xiaoxiao Zheng, Yixuan Li, Jihong Zhang, Chao Zhang, Meng Chen, Jie Liu, Zheng Fang, Weiyan Wang, Jinbao Xue,...
work page 2024
-
[18]
Swinir: Image restoration using swin transformer, 2021
Jingyun Liang, Jiezhang Cao, Guolei Sun, Kai Zhang, Luc Van Gool, and Radu Timofte. Swinir: Image restoration using swin transformer, 2021
work page 2021
-
[19]
Enhanced deep residual networks for single image super-resolution, 2017
Bee Lim, Sanghyun Son, Heewon Kim, Seungjun Nah, and Kyoung Mu Lee. Enhanced deep residual networks for single image super-resolution, 2017
work page 2017
-
[20]
Diff- bir: Towards blind image restoration with generative diffu- sion prior
Xinqi Lin, Jingwen He, Ziyan Chen, Zhaoyang Lyu, Ben Fei, Bo Dai, Wanli Ouyang, Yu Qiao, and Chao Dong. Diffbir: Towards blind image restoration with generative diffusion prior.arXiv preprint arXiv:2308.15070, 2023
-
[21]
An introduction to convolutional neural networks, 2015
Keiron O’Shea and Ryan Nash. An introduction to convolutional neural networks, 2015
work page 2015
-
[22]
Scalable diffusion models with transformers, 2023
William Peebles and Saining Xie. Scalable diffusion models with transformers, 2023
work page 2023
-
[23]
Control- next: Powerful and efficient control for image and video generation, 2024
Bohao Peng, Jian Wang, Yuechen Zhang, Wenbo Li, Ming-Chang Yang, and Jiaya Jia. Control- next: Powerful and efficient control for image and video generation, 2024. 11
work page 2024
-
[24]
Sdxl: Improving latent diffusion models for high-resolution image synthesis, 2023
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis, 2023
work page 2023
-
[25]
High-resolution image synthesis with latent diffusion models, 2022
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models, 2022
work page 2022
-
[26]
U-net: Convolutional networks for biomedical image segmentation, 2015
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation, 2015
work page 2015
-
[27]
Ntire 2017 challenge on single image super-resolution: Methods and results
Radu Timofte, Eirikur Agustsson, Luc Van Gool, Ming-Hsuan Yang, and Lei Zhang. Ntire 2017 challenge on single image super-resolution: Methods and results. InCVPRW, pages 114–125, 2017
work page 2017
-
[28]
Jianyi Wang, Kelvin C. K. Chan, and Chen Change Loy. Exploring clip for assessing the look and feel of images, 2022
work page 2022
-
[29]
Jianyi Wang, Zongsheng Yue, Shangchen Zhou, Kelvin CK Chan, and Chen Change Loy. Ex- ploiting diffusion prior for real-world image super-resolution.arXiv preprint arXiv:2305.07015, 2023
-
[30]
A survey on curriculum learning, 2021
Xin Wang, Yudong Chen, and Wenwu Zhu. A survey on curriculum learning, 2021
work page 2021
-
[31]
Real-esrgan: Training real-world blind super-resolution with pure synthetic data
Xintao Wang, Liangbin Xie, Chao Dong, and Ying Shan. Real-esrgan: Training real-world blind super-resolution with pure synthetic data. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 1905–1914, 2021
work page 1905
-
[32]
Recovering realistic texture in image super-resolution by deep spatial feature transform
Xintao Wang, Ke Yu, Chao Dong, and Chen Change Loy. Recovering realistic texture in image super-resolution by deep spatial feature transform. InCVPR, 2018
work page 2018
-
[33]
Seesr: Towards semantics-aware real-world image super-resolution, 2024
Rongyuan Wu, Tao Yang, Lingchen Sun, Zhengqiang Zhang, Shuai Li, and Lei Zhang. Seesr: Towards semantics-aware real-world image super-resolution, 2024
work page 2024
-
[34]
Maniqa: Multi-dimension attention network for no-reference image quality assessment, 2022
Sidi Yang, Tianhe Wu, Shuwei Shi, Shanshan Lao, Yuan Gong, Mingdeng Cao, Jiahao Wang, and Yujiu Yang. Maniqa: Multi-dimension attention network for no-reference image quality assessment, 2022
work page 2022
-
[35]
Tao Yang, Peiran Ren, Xuansong Xie, and Lei Zhang. Pixel-aware stable diffusion for realistic image super-resolution and personalized stylization.arXiv preprint arXiv:2308.14469, 2023
-
[36]
Ip-adapter: Text compatible image prompt adapter for text-to-image diffusion models, 2023
Hu Ye, Jun Zhang, Sibo Liu, Xiao Han, and Wei Yang. Ip-adapter: Text compatible image prompt adapter for text-to-image diffusion models, 2023
work page 2023
-
[37]
Fanghua Yu, Jinjin Gu, Zheyuan Li, Jinfan Hu, Xiangtao Kong, Xintao Wang, Jingwen He, Yu Qiao, and Chao Dong. Scaling up to excellence: Practicing model scaling for photo-realistic image restoration in the wild, 2024
work page 2024
-
[38]
Designing a practical degradation model for deep blind image super-resolution
Kai Zhang, Jingyun Liang, Luc Van Gool, and Radu Timofte. Designing a practical degradation model for deep blind image super-resolution. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 4791–4800, 2021
work page 2021
-
[39]
Adding conditional control to text-to-image diffusion models, 2023
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models, 2023. 12
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.