Talk to Your Slides: High-Efficiency Slide Editing via Language-Driven Structured Data Manipulation
Pith reviewed 2026-05-22 14:20 UTC · model grok-4.3
The pith
Language-driven agent edits slides by manipulating structured data models instead of visuals
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
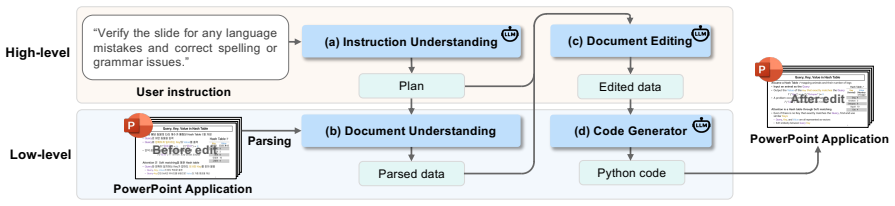
Talk-to-Your-Slides operates via language-driven structured data manipulation on the slide object model, using a hierarchical architecture to bridge high-level user instructions with low-level execution codes, thereby enabling precise content changes and style preservation without visual perception or OCR.
What carries the argument
Hierarchical architecture that translates high-level instructions into execution codes by operating directly on the slide's underlying object model instead of image pixels.
Load-bearing premise
The system assumes reliable access to an accurate underlying object model of the slides that fully captures both content and style details.
What would settle it
A scenario in which the provided object model is incomplete or inaccurate, causing edits to deviate from the intended style or content while visual methods succeed.
Figures
















read the original abstract
Editing presentation slides is a frequent yet tedious task, ranging from creative layout design to repetitive text maintenance. While recent GUI-based agents powered by Multimodal LLMs (MLLMs) excel at tasks requiring visual perception, such as spatial layout adjustments, they often incur high computational costs and latency when handling structured, text-centric, or batch processing tasks. In this paper, we propose Talk-to-Your-Slides, a high-efficiency slide editing agent that operates via language-driven structured data manipulation rather than relying on the image modality. By leveraging the underlying object model instead of screen pixels, our approach ensures precise content modification while preserving style fidelity, addressing the limitations of OCR-based visual agents. Our system features a hierarchical architecture that effectively bridges high-level user instructions with low-level execution codes. Experiments demonstrate that for text-centric and formatting tasks, our method enables 34% faster processing, achieves 34% better instruction fidelity, and operates at an 87% lower cost compared to GUI-based baselines. Furthermore, we introduce TSBench, a human-verified benchmark dataset comprising 379 instructions, including a Hard subset designed to evaluate robustness against complex and visually dependent queries. Our code and benchmark are available at https://github.com/KyuDan1/Talk-to-Your-Slides.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
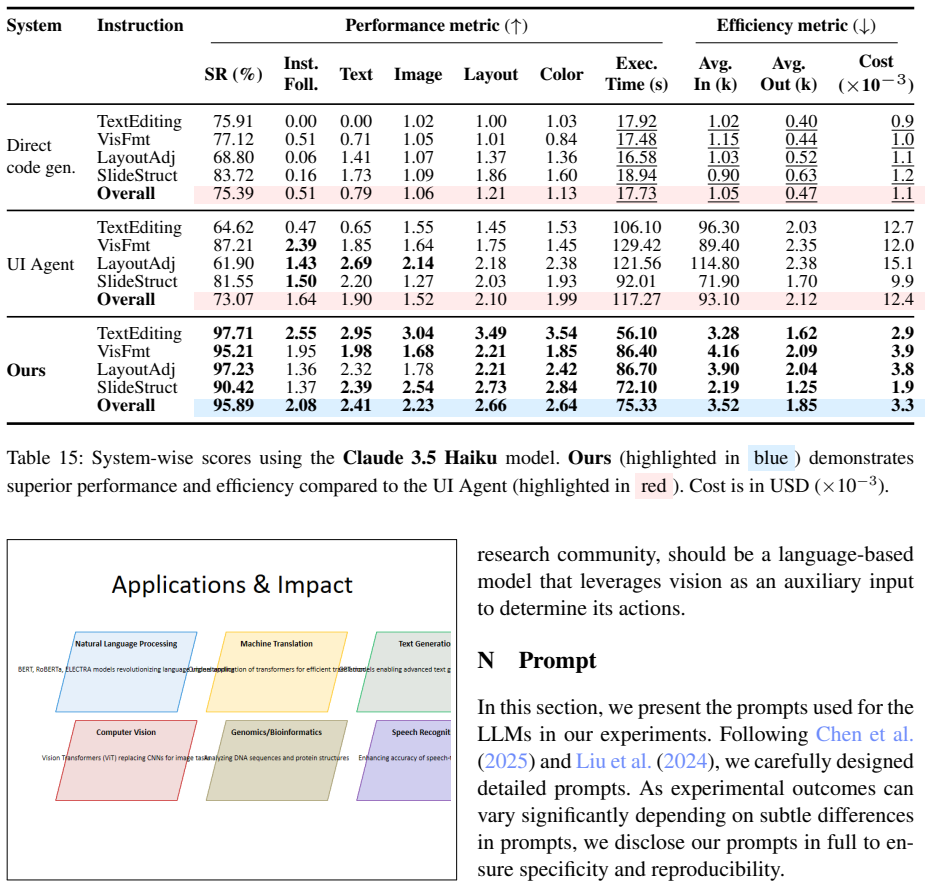
Summary. The paper proposes Talk-to-Your-Slides, a hierarchical agent for editing presentation slides via language-driven structured data manipulation on the underlying object model rather than visual or GUI methods. It claims 34% faster processing, 34% better instruction fidelity, and 87% lower cost than GUI baselines for text-centric and formatting tasks, while introducing TSBench, a human-verified benchmark of 379 instructions with a Hard subset for complex queries.
Significance. If the results hold under realistic conditions, the work offers a promising direction for low-cost, high-precision automation of structured document tasks by avoiding the overhead of multimodal visual agents. The open-sourced code and benchmark provide a concrete resource for follow-up research on language agents for office documents.
major comments (3)
- [§4] §4: The reported gains (34% faster, 34% better fidelity, 87% lower cost) are stated without details on baseline implementations, hardware, statistical tests, or variance across runs, making it impossible to determine whether the improvements are attributable to the structured manipulation or to unstated experimental choices.
- [§3] §3: The central premise that an accurate object model fully captures content and style (allowing language-driven manipulation without OCR or pixels) is load-bearing for all efficiency claims, yet the manuscript provides no experiments measuring degradation under realistic parsing errors, missing elements, or incomplete hierarchies from PPTX files, especially on the Hard subset of TSBench.
- [§4.1] §4.1: The construction, sampling, and human-verification protocol for the 379 instructions (and the definition of the Hard subset) are not described in sufficient detail to support claims that TSBench reliably evaluates robustness against complex or visually dependent queries.
minor comments (2)
- [Abstract] The abstract and §1 could more clearly delimit the method's scope (text-centric tasks only) versus its limitations on spatial layout changes.
- [§3] Figure 1 or the architecture diagram in §3 would benefit from explicit pseudocode or data-flow arrows showing how high-level instructions map to low-level codes.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which have helped us identify areas for improvement in the manuscript. We address each major comment below and outline the revisions we will make.
read point-by-point responses
-
Referee: [§4] The reported gains (34% faster, 34% better fidelity, 87% lower cost) are stated without details on baseline implementations, hardware, statistical tests, or variance across runs, making it impossible to determine whether the improvements are attributable to the structured manipulation or to unstated experimental choices.
Authors: We agree with this observation. The current manuscript lacks sufficient experimental details to fully support the claims. In the revised version, we will add a new subsection in §4 detailing the baseline implementations (including how GUI-based agents were set up), the hardware configuration, the number of experimental runs, standard deviations, and p-values from statistical tests to demonstrate the significance of the improvements. revision: yes
-
Referee: [§3] The central premise that an accurate object model fully captures content and style (allowing language-driven manipulation without OCR or pixels) is load-bearing for all efficiency claims, yet the manuscript provides no experiments measuring degradation under realistic parsing errors, missing elements, or incomplete hierarchies from PPTX files, especially on the Hard subset of TSBench.
Authors: This is a fair point, as the robustness to parsing inaccuracies is important for real-world applicability. Although the paper focuses on the benefits assuming a correct object model, we will include additional experiments in the revision that introduce controlled parsing errors and evaluate performance degradation, with particular emphasis on the Hard subset of TSBench. revision: yes
-
Referee: [§4.1] The construction, sampling, and human-verification protocol for the 379 instructions (and the definition of the Hard subset) are not described in sufficient detail to support claims that TSBench reliably evaluates robustness against complex or visually dependent queries.
Authors: We acknowledge the need for more transparency in the benchmark construction. We will revise §4.1 to include detailed descriptions of how the 379 instructions were collected and sampled, the specific criteria used to define the Hard subset for complex and visually dependent queries, and the full human-verification protocol including the number of annotators and agreement statistics. revision: yes
Circularity Check
No circularity: empirical system evaluation with direct baseline comparisons
full rationale
The paper describes a hierarchical agent architecture for slide editing via structured data manipulation and reports empirical results (34% faster, 34% better fidelity, 87% lower cost) from direct comparisons to GUI-based MLLM baselines on TSBench. No equations, fitted parameters, predictions, or derivations are present in the provided text. Central claims rest on experimental measurements rather than any self-referential reduction or self-citation chain. The assumption of an accurate object model is an engineering premise, not a circular derivation. This is a standard non-circular systems paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Presentation software exposes an accurate, manipulable object model that captures both content and style independently of pixel rendering.
invented entities (1)
-
Hierarchical architecture bridging high-level user instructions with low-level execution codes
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
operates via language-driven structured data manipulation rather than relying on the image modality... hierarchical architecture that effectively bridges high-level user instructions with low-level execution codes
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
34% faster processing... 87% lower cost compared to GUI-based baselines
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 3 Pith papers
-
PresentAgent-2: Towards Generalist Multimodal Presentation Agents
PresentAgent-2 generates query-driven multimodal presentation videos with research grounding, supporting single-speaker, multi-speaker discussion, and interactive question-answering modes.
-
AeSlides: Incentivizing Aesthetic Layout in LLM-Based Slide Generation via Verifiable Rewards
AeSlides is a GRPO-based RL framework that uses verifiable aesthetic metrics to optimize LLM slide generation, achieving large gains in layout quality metrics and human scores with only 5K prompts.
-
AI for Auto-Research: Roadmap & User Guide
The paper delivers a stage-by-stage roadmap for AI in research, showing reliable assistance in retrieval and tool tasks but fragility in novelty and judgment, advocating human-governed collaboration.
Reference graph
Works this paper leans on
-
[1]
13 Ozan Caldiran, Kadir Haspalamutgil, Abdullah Ok, Can Palaz, Esra Erdem, and V olkan Patoglu
Automatikz: Text-guided synthesis of sci- entific vector graphics with tikz.arXiv preprint arXiv:2310.00367. 13 Ozan Caldiran, Kadir Haspalamutgil, Abdullah Ok, Can Palaz, Esra Erdem, and V olkan Patoglu. 2009. Bridging the gap between high-level reasoning and low-level control. InInternational Conference on Logic Programming and Nonmonotonic Reasoning, p...
-
[2]
A survey on in-context learning. InProc. of the Conference on Empirical Methods in Nat- ural Language Processing (EMNLP), pages 1107– 1128, Miami, Florida, USA. Association for Com- putational Linguistics. 4 Joshua P Ellis. 2017. Tikz-feynman: Feynman dia- grams with tikz.Computer Physics Communica- tions, 210:103–123. 13 Difei Gao and 1 others. 2024. Ass...
-
[3]
4 Athar Sefid, Prasenjit Mitra, and Lee Giles
Tptu: Large language model-based ai agents for task planning and tool usage.Preprint, arXiv:2308.03427. 4 Athar Sefid, Prasenjit Mitra, and Lee Giles. 2021. Slidegen: an abstractive section-based slide gener- ator for scholarly documents. InProceedings of the 21st ACM Symposium on Document Engineering, DocEng ’21, New York, NY , USA. Association for Compu...
-
[4]
Struct-x: Enhancing the reasoning capabili- ties of large language models in structured data sce- narios. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Min- ing V .1, KDD ’25, page 2584–2595, New York, NY , USA. Association for Computing Machinery. 4 Evan Z Wang, Federico Cassano, Catherine Wu, Yun- feng Bai, William Song...
-
[5]
Code to think, think to code: A survey on code-enhanced reasoning and reasoning-driven code intelligence in llms.Preprint, arXiv:2502.19411. 4 Ke Yang, Jiateng Liu, John Wu, Chaoqi Yang, Yi Fung, Sha Li, Zixuan Huang, Xu Cao, Xingyao Wang, Heng Ji, and ChengXiang Zhai. 2024. If LLM is the wizard, then code is the wand: A survey on how code empowers large ...
-
[6]
Attempt 1 (Generated Code): # Agent incorrectly tries to assign a tuple slide.Shapes(1)...Font.Color.RGB = (255, 0, 0) Execution Error: TypeError: Objects of type ’tuple’ can not be converted to a COM VARIANT
-
[7]
However, the PowerPoint COM interface expects a single integer
Refinement Step (Self-Reflection): ”I attempted to assign a tuple (255, 0, 0) directly. However, the PowerPoint COM interface expects a single integer... I must convert it.”
-
[8]
Attempt 2 (Regenerated Code): # Agent corrects the format to an integer slide.Shapes(1)...Font.Color.RGB = 255 Result:Success(Color updated to red) Figure 4: A real-world example of the self-reflection mechanism handling a data type error during execution. Variant Visual-DependentSR(%) AmbiguousSR(%)Multi-stepSR(%)OverallSR(%)CF(%) Ours (w/o self-reflecti...
work page 2023
-
[9]
Move the title text box on slide 5 so that its bottom edge touches the top of the bar chart
It inherits the core strengths of the flagship GPT-4.1 series—state-of-the-art coding ability, robust instruction following, and support for very long (up to one million-token) contexts—while reducing model size to cut inference latency by roughly 50% and lower operational cost. This makes GPT-4.1-mini an ideal choice for applica- tions that demand the la...
work page 2024
-
[10]
Specific slides to modify (by page number)
-
[11]
Specific sections within slides (title, body, notes, headers, footers, etc.)
-
[12]
Specific object elements to add, remove, or change (text boxes, images, shapes, charts, tables, etc.)
-
[13]
Precise formatting changes (font, size, color, alignment, etc.)
-
[14]
The logical sequence of operations with clear dependen- cies Please write one task for one slide page. Format your response as a JSON format with the following structure:{{”understanding”: ”Detailed summary of what the user wants to achieve”, ”tasks”: [{{”page number”: 1, ”description”: ”Specific task description”, ”target”: ”Precise target location (e.g....
work page 2025
-
[15]
Only perform the work described in the ’action’ within ’tasks’
-
[16]
Only modify the elements specified in ’target’ within ’tasks’
-
[17]
Output must contain pure JSON only - no explanations or additional text
-
[18]
Preserve all formatting information (fonts, sizes, colors, etc.)
-
[19]
Verify that the JSON format is valid after completing the task Before starting the task:
-
[20]
Check the ’understanding’ field to grasp the overall task objective
-
[21]
Review ’page number’, ’description’, ’target’, and ’ac- tion’ within ’tasks’
-
[22]
Identify all text elements in ’Objects Detail’ The output must maintain the identical structure as the orig- inal JSON, with only the necessary text modified according to the task. Give only the JSON. Response: JSON Figure 14: A prompt used in Document Editing. shown in Figure N.5, while the prompt used for evaluating text, image, layout, and color,based ...
work page 2025
-
[23]
Find activate powerpoint app with ppt app = win32com.client.GetActiveObject (”Power- Point.Application”) active presentation = ppt app.ActivePresentation
-
[24]
Find the slide specified by page number:{slide num}
-
[25]
Target to change:{before}
-
[26]
New content to apply:{after}
-
[27]
Generate ONLY executable code that will directly modify the PowerPoint. CRITICAL REQUIREMENTS: - DO NOT create a new PowerPoint application - use the existing one - Please check if the slide number you want to work on ex- ists and proceed with the work. The index starts with 1. - The code should NOT be written as a complete program with imports - it will ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.