MSEarth: A Multimodal Benchmark for Earth Science Phenomenon Discovery with MLLMs
Pith reviewed 2026-05-19 14:02 UTC · model grok-4.3
The pith
MSEarth introduces a benchmark of over 289K real figures from Earth science papers to test multimodal models on graduate-level geoscience reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
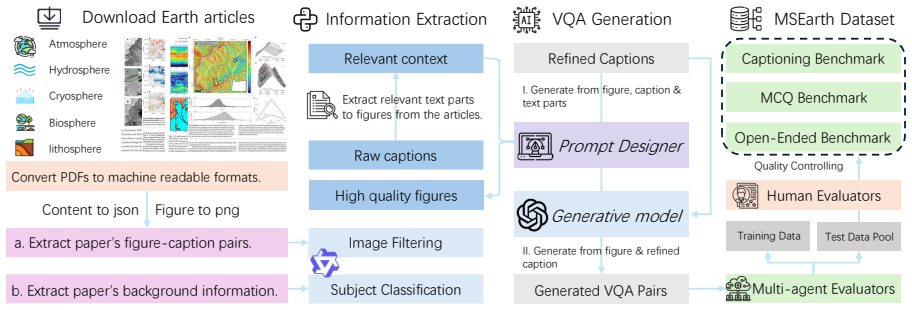
MSEarth is a multimodal scientific dataset and benchmark curated from high-quality, open-access publications, featuring over 289K figures with refined captions that include contextual discussions and reasoning, covering the five major spheres of Earth science, and supporting tasks such as scientific figure captioning, multiple choice questions, and open-ended reasoning.
What carries the argument
The curation of figures and context-rich captions directly from original open-access papers to create authentic examples of geoscientific reasoning.
If this is right
- MLLMs can be evaluated more accurately on their ability to handle complex Earth science phenomena.
- The resource supports development of models for multimodal scientific reasoning across multiple Earth spheres.
- It enables tasks that require integrating visual data with textual context from actual research publications.
- The benchmark scales to allow ongoing testing as models improve.
Where Pith is reading between the lines
- Similar curation methods could be applied to create benchmarks in other scientific fields that rely on figures and detailed reasoning.
- Improved models from this data might help analyze large volumes of Earth observation imagery for pattern discovery.
- The emphasis on real papers points toward future use of AI to assist in interpreting unpublished or interdisciplinary geoscience data.
Load-bearing premise
That figures and captions taken from published papers accurately capture the nuanced graduate-level geoscientific reasoning needed for real applications.
What would settle it
A comparison showing that models trained or tested on MSEarth perform no better than those using simpler datasets when applied to new, real-world Earth science problems.
Figures

























read the original abstract
The rapid advancement of multimodal large language models (MLLMs) offers new opportunities for complex scientific challenges, yet their application in earth science-especially at the graduate level-remains underexplored due to a lack of benchmarks reflecting the depth and complexity of geoscientific reasoning. Existing datasets often rely on synthetic data or simple figure-caption pairs, failing to capture the nuanced reasoning required for real-world applications. To address this, we introduce MSEarth, a multimodal scientific dataset and benchmark curated from high-quality, open-access publications. Covering the five major spheres of Earth science-atmosphere, cryosphere, hydrosphere, lithosphere, and biosphere-MSEarth features over 289K figures with refined captions enriched by contextual discussions and reasoning from the original papers. The benchmark supports tasks such as scientific figure captioning, multiple choice questions, and open-ended reasoning, providing a scalable, high-fidelity resource for developing and evaluating MLLMs in scientific reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MSEarth, a multimodal dataset and benchmark for Earth science phenomenon discovery with MLLMs. Curated from high-quality open-access publications, it covers the five major spheres (atmosphere, cryosphere, hydrosphere, lithosphere, biosphere) and contains over 289K figures accompanied by refined captions that incorporate contextual discussions and reasoning drawn from the source papers. The benchmark is positioned to support tasks including scientific figure captioning, multiple-choice questions, and open-ended reasoning, addressing gaps in existing resources that rely on synthetic data or basic figure-caption pairs.
Significance. If the curation and enrichment process can be shown to reliably capture nuanced, graduate-level geoscientific reasoning, MSEarth would constitute a useful large-scale resource for training and evaluating MLLMs on authentic scientific material. The scale and domain coverage could help move the field beyond simplistic or synthetic benchmarks toward more realistic evaluation of scientific reasoning capabilities.
major comments (1)
- [Abstract / Curation description] The central claim that the refined captions deliver 'contextual discussions and reasoning from the original papers' and constitute a 'high-fidelity' resource is load-bearing, yet the manuscript supplies no description of the refinement protocol (manual vs. automated, quality controls, inter-annotator agreement, or validation against original paper context). Without this information, it is impossible to evaluate whether the output genuinely exceeds simple figure-caption pairs in depth or introduces bias.
minor comments (1)
- [Abstract] The abstract contains a minor typographical issue ('earth science-especially' lacks a space after the hyphen).
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive review. The feedback highlights an important gap in the current manuscript regarding the description of our caption refinement process. We address this point below and will incorporate the necessary revisions to improve clarity and transparency.
read point-by-point responses
-
Referee: [Abstract / Curation description] The central claim that the refined captions deliver 'contextual discussions and reasoning from the original papers' and constitute a 'high-fidelity' resource is load-bearing, yet the manuscript supplies no description of the refinement protocol (manual vs. automated, quality controls, inter-annotator agreement, or validation against original paper context). Without this information, it is impossible to evaluate whether the output genuinely exceeds simple figure-caption pairs in depth or introduces bias.
Authors: We agree that the manuscript currently lacks a detailed account of the caption refinement protocol, which is necessary to substantiate claims about the enriched captions providing contextual discussions and reasoning. This omission limits the ability to assess fidelity and potential biases. In the revised manuscript, we will add a new subsection in the Methods or Dataset Curation section that explicitly describes the refinement process. This will include: (1) whether enrichment was performed manually by Earth science experts or via automated LLM-assisted methods with human verification; (2) quality control procedures such as spot-checking against source papers; (3) any inter-annotator agreement metrics collected during the process; and (4) validation steps to confirm that added context reflects the original papers' discussions without introducing unsupported inferences or biases. We believe this addition will directly address the concern and strengthen the paper's contribution. revision: yes
Circularity Check
No circularity in dataset curation or benchmark claims
full rationale
The paper presents MSEarth as a curated multimodal dataset drawn from open-access publications, with no mathematical derivations, equations, fitted parameters, predictions, or self-referential loops of any kind. Its central claims concern the scale (289K figures), coverage across five Earth science spheres, and enrichment of captions with contextual reasoning; these are descriptive of an external data resource rather than derived quantities that reduce to the paper's own inputs by construction. No self-citation chains, ansatzes, or uniqueness theorems are invoked to support load-bearing steps. The absence of any derivation chain means the contribution stands or falls on the independent quality of the curation process, which is not circular even if its validation details are limited.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Real-world figures and captions from scientific publications better capture nuanced geoscientific reasoning than synthetic data or simple figure-caption pairs.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
MSEarth features over 289K figures with refined captions enriched by contextual discussions and reasoning from the original papers... covering the five major spheres of Earth science
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We employ GPT-4o for refined caption generation... multi-agent voting... expert validation
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
Maestro: Reinforcement Learning to Orchestrate Hierarchical Model-Skill Ensembles
Maestro uses outcome-based RL to train a lightweight policy that orchestrates ensembles of frozen expert models and skills, reporting 70.1% average accuracy across ten multimodal benchmarks and outperforming GPT-5 and...
-
GeoR-Bench: Evaluating Geoscience Visual Reasoning
GeoR-Bench shows top multimodal models reach only 42.7% strict accuracy on geoscience visual reasoning tasks while open-source models reach 10.3%, with outputs often visually plausible yet scientifically inaccurate.
Reference graph
Works this paper leans on
-
[1]
Test-takers will analyze this image to answer the questions
Figure:A scientific or illustrative figure provided as the primary visual input. Test-takers will analyze this image to answer the questions. 2.Caption:A concise summary describing key aspects of the Figure
-
[2]
However, test-takers cannot access this information
Supplementary:In-depth information (e.g., summarized expert insight, detailed analysis, or background knowledge) that you can use to assist in designing advanced and meaningful questions. However, test-takers cannot access this information. Input Information Provided: •Caption:{raw caption} •Supplementary:{refined caption} Task Instructions:
-
[3]
•Supplementary Usage:The correct answers are encouraged to be derived from
Use of Input Sources: • Ensure that no question can be answered entirely using Caption without observations. •Supplementary Usage:The correct answers are encouraged to be derived from
-
[4]
Question Types: • Multiple Choice Questions (MCQs):At least2questions must be of this type, with 4 distinct options (A-D) and one correct answer. • Open-Ended Questions:At least2questions must be open-ended, requiring concise and precise answers (no more than 4 words)
-
[5]
The chain explains the logical process by which the correct answer can be determined
Reasoning Chains: • For every question, you must include a reasoning chain. The chain explains the logical process by which the correct answer can be determined. • The reasoning chain must:
-
[6]
Output Structure: The output must be written inJSON format
-
[7]
Questions that are grounded in the Supplementary context are highly encouraged. These ques- tions should require the test-taker to refer to in-depth knowledge and insights not immediately visible in the Figure or Caption
-
[8]
According to the Supplementary
Avoid referencing the Supplementary in any question andreasoning_chain (e.g., "According to the Supplementary" or "The Supplementary states"). Provide your response below: Figure 12: Prompt for generating VQAs. Aquatic Ecology and Limnological Ecology, Biogeochemistry, Biogeography. Hydrology: Hydrology, Hydrogeology, Limnol- ogy, River Hydrology and Estu...
-
[9]
Carefully analyze the input image and the provided query
-
[10]
Based on the image, select the correct option (e.g., ’A’, ’B’, ’C’) or directly state the correct option content
-
[11]
Provide reasoning explaining how to derive the correct answer. Input: •Query:{query} Output Format: The output must be written inJSON formatusing the structure below: { "answer": "Correct option or short answer", "Explanation": "Explaining how to derive correct answer." } Figure 13: Prompt for generating normal answers for MCQs. orology, Hydrological Meas...
-
[12]
for local testing; for proprietary models, we conduct tests via API calls. The download paths for specific models and the versions of models ac- cessed via API are provided in Figure 10. J Evaluation Metrics J.1 MLLM-based Metrics Following G-Eval (Liu et al., 2023b), we utilize MLLM (Qwen2.5-VL-72B) with a specialized prompt to compute a factual scientif...
-
[13]
Carefully analyze the input image and its caption
-
[14]
Based on the image and caption, select the correct option (e.g., ’A’, ’B’, ’C’) or directly state the correct option content. Output Format: The output must be written inJSON formatusing the structure below: { "answer": "Correct option or short answer", "Explanation": "Explaining how to derive correct answer." } Figure 14: Prompt for generating enhanced a...
-
[15]
Scientific Accuracy:Does the generated caption accurately describe the scientific content of the figure or image?
-
[16]
Clarity and Coherence:Is the caption well-structured, logically organized, and easy to understand?
-
[17]
Relevance and Completeness:Does the caption provide all necessary information to under- stand the figure or image? Evaluation Steps:
-
[18]
Compare theGenerated Captionto theStandard Caption. Assess whether the generated caption aligns with the scientific content and intent of the standard caption
-
[19]
Assign a score for coherence on a scale of 1 to 5, where 1 is the lowest and 5 is the highest, based on the Evaluation Criteria. Input: •Standard Caption:{response} •Generated Caption:{generated_caption} Important Instructions: • Only output the score in the specified JSON format. • Do not provide any explanations, comments, or additional text. Output For...
-
[20]
Based on the refined caption, question, and standard answer, determine if the generated answer is correct
-
[21]
Only output the determination in the specified JSON format
-
[22]
Do not provide any explanations, comments, or additional text. Output Format: The output must be written inJSON formatusing the structure below: { "is_correct": true or false } Figure 20: Prompt for evaluating the quality of generated answers to open-ended questions. Gemini2.5-Pro-thinking Gemini2.5-Flash InternVL3-78B Qwen2.5-VL-72B 25 30 35 40 45 50 55P...
work page 1992
-
[23]
RS=Atmospheric Remote Sensing, Ecosys
Abbreviations: Meteor.=Meteorology, Climat.=Climatology, Atmos. RS=Atmospheric Remote Sensing, Ecosys. Ecol.=Ecosystem Ecology, Landsc. Ecol.=Landscape Ecology, Aquat. Ecol.=Aquatic & Limnological Ecology, Phys. Geog.=Physical Geography, Reg. Geog.=Regional Geography, Sediment.=Sedimentology, Struct. Geol.=Structural Geology, Quat. Geol.=Quaternary Geolog...
work page 2010
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.