Spectral-inspired Operator Learning with Limited Data and Unknown Physics
Pith reviewed 2026-05-25 08:27 UTC · model grok-4.3
The pith
SINO learns unknown PDE dynamics from just 2-5 trajectories by mapping frequency indices to spatial derivatives without any equation information.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
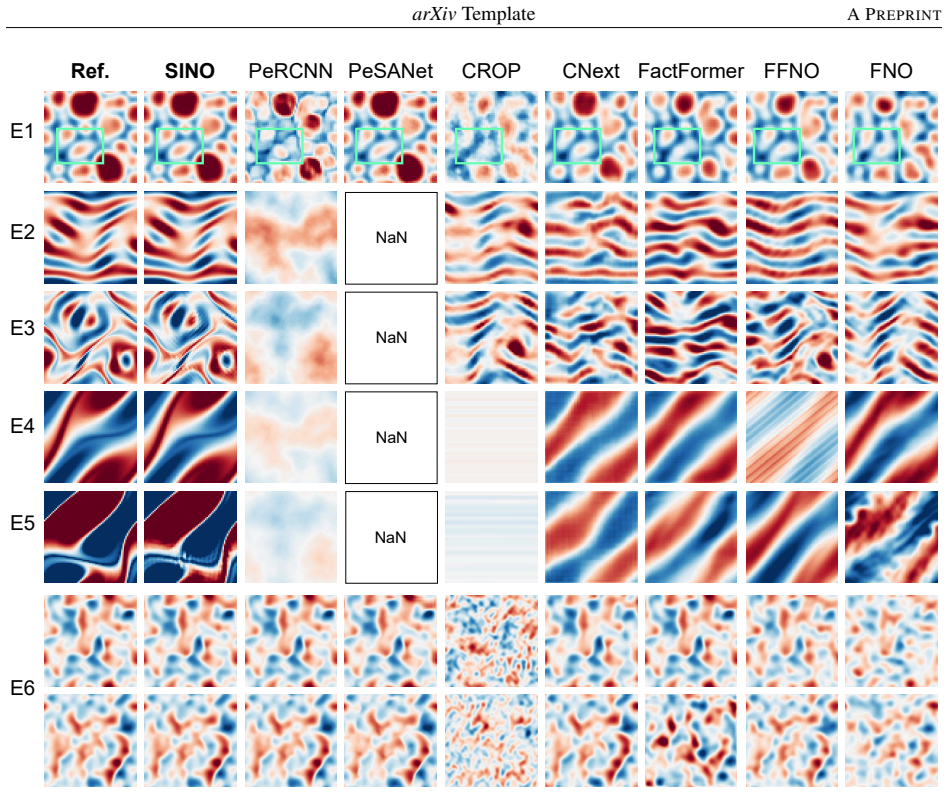
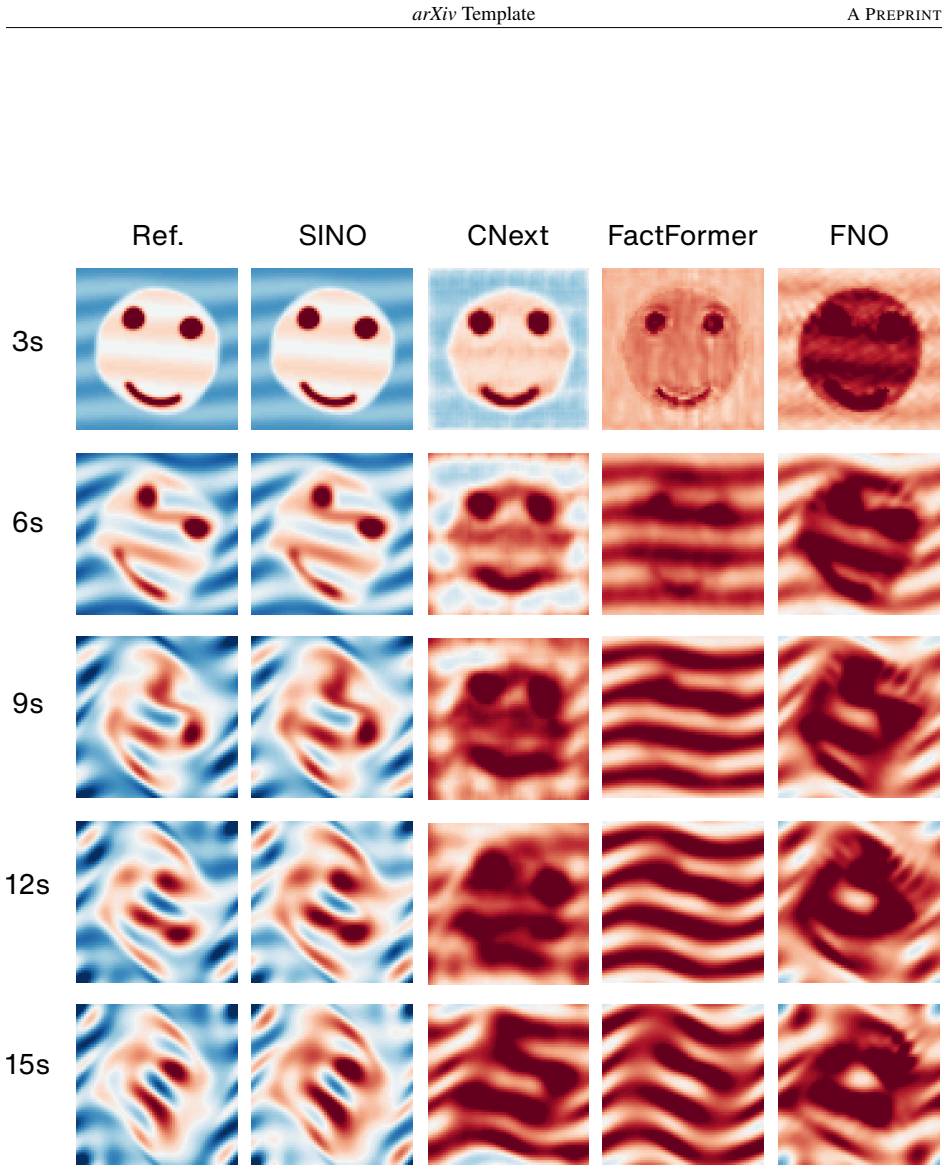
SINO automatically captures both local and global spatial derivatives from frequency indices, enabling a compact representation of the underlying differential operators in physics-agnostic regimes. To model nonlinear effects, it employs a Pi-block that performs multiplicative operations on spectral features, complemented by a low-pass filter to suppress aliasing. With only 5 training trajectories, SINO outperforms data-driven methods trained on 1000 trajectories and remains predictive on challenging out-of-distribution cases where other methods fail.
What carries the argument
Spectral-Inspired Neural Operator (SINO) that uses frequency indices to represent differential operators together with a Pi-block for multiplicative nonlinearities.
If this is right
- Accurate modeling of unknown PDE systems becomes feasible with only a handful of observed trajectories.
- Out-of-distribution generalization improves over existing neural operators on the same limited-data regime.
- Accuracy improves by one to two orders of magnitude on both two- and three-dimensional benchmark problems.
- The method operates without PDE residuals, handcrafted stencils, or any other explicit physics input.
Where Pith is reading between the lines
- The frequency-index approach may reduce the cost of collecting training data for operator learning in experimental settings where large simulation ensembles are impractical.
- The same spectral representation could be tested on operator-learning tasks outside classical PDEs, such as nonlocal or stochastic systems.
- If the low-pass filter proves essential, similar anti-aliasing steps might become standard in other spectral-inspired architectures.
Load-bearing premise
Frequency indices can automatically capture both local and global spatial derivatives to form a compact representation of the underlying differential operators without any explicit PDE information.
What would settle it
Train SINO on five trajectories of a new PDE family and compare its out-of-distribution prediction error against a standard neural operator trained on one thousand trajectories of the same family; if SINO error is not lower, the central performance claim does not hold.
Figures












read the original abstract
Learning PDE dynamics from limited data with unknown physics is challenging. Existing neural PDE solvers either require large datasets or rely on known physics (e.g., PDE residuals or handcrafted stencils), leading to limited applicability. To address these challenges, we propose Spectral-Inspired Neural Operator (SINO), which can model complex systems from just 2-5 trajectories, without requiring explicit PDE terms. Specifically, SINO automatically captures both local and global spatial derivatives from frequency indices, enabling a compact representation of the underlying differential operators in physics-agnostic regimes. To model nonlinear effects, it employs a Pi-block that performs multiplicative operations on spectral features, complemented by a low-pass filter to suppress aliasing. Extensive experiments on both 2D and 3D PDE benchmarks demonstrate that SINO achieves state-of-the-art performance, with improvements of 1-2 orders of magnitude in accuracy. Particularly, with only 5 training trajectories, SINO outperforms data-driven methods trained on 1000 trajectories and remains predictive on challenging out-of-distribution cases where other methods fail.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the Spectral-Inspired Neural Operator (SINO) for learning PDE dynamics from limited data (2-5 trajectories) without explicit physics knowledge. It claims that frequency indices automatically capture local and global spatial derivatives to form a compact representation of unknown differential operators in a physics-agnostic regime. Nonlinearity is handled by a Pi-block performing multiplicative operations on spectral features, with a low-pass filter to suppress aliasing. Experiments on 2D and 3D PDE benchmarks are said to yield 1-2 orders of magnitude accuracy gains, with SINO using 5 trajectories outperforming data-driven methods trained on 1000 trajectories and generalizing to out-of-distribution cases.
Significance. If substantiated, the result would be significant for data-scarce, physics-agnostic operator learning, offering a route to model complex systems where collecting large datasets or specifying PDE terms is impractical. The spectral-inspiration approach without handcrafted stencils or residuals could broaden applicability in scientific ML.
major comments (2)
- [Abstract] Abstract: the central claim that frequency indices 'automatically capture both local and global spatial derivatives' to represent differential operators without any PDE information is load-bearing for the 5-trajectory performance advantage, yet no derivation, operator approximation bound, or ablation is supplied showing how index k encodes derivative order or coefficient when the underlying PDE is withheld.
- [Abstract] Abstract: the performance claims (1-2 orders of magnitude improvement; outperforming 1000-trajectory baselines with only 5 trajectories; predictive on OOD cases) are asserted without experimental details, error analysis, or verification of the derivative-capture mechanism, so the limited-data advantage cannot be attributed to the proposed architecture.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on the abstract claims. We address each point below and outline revisions to improve clarity and attribution of results while preserving the manuscript's core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that frequency indices 'automatically capture both local and global spatial derivatives' to represent differential operators without any PDE information is load-bearing for the 5-trajectory performance advantage, yet no derivation, operator approximation bound, or ablation is supplied showing how index k encodes derivative order or coefficient when the underlying PDE is withheld.
Authors: We acknowledge the referee's concern. The manuscript (Sections 2-3) motivates the use of frequency indices k by drawing from spectral methods, where multiplication by powers of k corresponds to spatial derivatives in Fourier space; these indices are provided as explicit input features to allow the network to learn operator approximations from data alone. An ablation on removing the frequency-index channels is reported in the supplementary material, showing degraded performance. However, we agree that no formal derivation or approximation bound is supplied for the unknown-PDE case, as the method is empirical. We will revise the abstract to replace 'automatically capture' with 'inspired by spectral representations that encode' and add a short paragraph in Section 3 discussing the empirical mechanism without claiming a proof. revision: partial
-
Referee: [Abstract] Abstract: the performance claims (1-2 orders of magnitude improvement; outperforming 1000-trajectory baselines with only 5 trajectories; predictive on OOD cases) are asserted without experimental details, error analysis, or verification of the derivative-capture mechanism, so the limited-data advantage cannot be attributed to the proposed architecture.
Authors: The quantitative claims are substantiated in Section 4 and the supplementary material, which report relative L2 errors with standard deviations over multiple random seeds, direct comparisons against baselines trained on 5 vs. 1000 trajectories, and OOD test cases with visualized predictions. Tables 1-3 and Figures 3-6 provide the supporting numbers and error analysis. We concur that the abstract does not reference these details or include a dedicated verification of the frequency-index mechanism. We will revise the abstract to briefly note the experimental protocol and add a short mechanistic analysis subsection (or expand the existing ablation) to better attribute the limited-data gains to the spectral features. revision: yes
Circularity Check
No significant circularity; architecture proposal is self-contained
full rationale
The paper presents SINO as a new neural operator architecture that processes frequency indices to capture spatial derivatives without explicit PDE knowledge, using a Pi-block for nonlinearity and a low-pass filter. No derivation chain, equations, or claims reduce by construction to fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations. The central claims rest on empirical benchmarks rather than any mathematical reduction to inputs. This matches the default expectation for non-circular papers; the 5-trajectory performance is an experimental result, not a tautological output of the method definition.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Neural networks can learn mappings from frequency indices to spatial differential operators.
- domain assumption Multiplicative operations on spectral features can represent nonlinear PDE effects.
Reference graph
Works this paper leans on
-
[1]
URL https: //openreview.net/forum?id=2DbVeuoa6a. Salah A Faroughi, Nikhil Pawar, Celio Fernandes, Maziar Raissi, Subasish Das, Nima K Kalantari, and Seyed Kourosh Mahjour. Physics-guided, physics-informed, and physics-encoded neural networks in scientific computing.arXiv preprint arXiv:2211.07377,
-
[2]
Unisolver: Pde-conditional transformers are universal pde solvers.arXiv preprint arXiv:2405.17527,
Zhou Hang, Yuezhou Ma, Haixu Wu, Haowen Wang, and Mingsheng Long. Unisolver: Pde-conditional transformers are universal pde solvers.arXiv preprint arXiv:2405.17527,
-
[3]
Dmitrii Kochkov, Jamie A Smith, Ayya Alieva, Qing Wang, Michael P Brenner, and Stephan Hoyer
ISSN 2790-2048. Dmitrii Kochkov, Jamie A Smith, Ayya Alieva, Qing Wang, Michael P Brenner, and Stephan Hoyer. Machine learning– accelerated computational fluid dynamics.Proceedings of the National Academy of Sciences, 118(21):e2101784118,
work page 2048
-
[4]
ISSN 0021-9991. doi:10.1016/j.jcp.2019.108925. URLhttp://dx.doi.org/10.1016/j.jcp.2019.108925. Lu Lu, Pengzhan Jin, Guofei Pang, Zhongqiang Zhang, and George Em Karniadakis. Learning nonlinear operators via deeponet based on the universal approximation theorem of operators.Nature Machine Intelligence, 3(3):218–229,
-
[5]
11 arXivTemplateA PREPRINT Haixin Wang, Yadi Cao, Zijie Huang, Yuxuan Liu, Peiyan Hu, Xiao Luo, Zezheng Song, Wanjia Zhao, Jilin Liu, Jinan Sun, et al. Recent advances on machine learning for computational fluid dynamics: A survey.arXiv preprint arXiv:2408.12171, 2024a. Haixin Wang, Jiaxin LI, Anubhav Dwivedi, Kentaro Hara, and Tailin Wu. BENO: Boundary-e...
-
[6]
12 arXivTemplateA PREPRINT Appendix Overview A Proof of Theorem 1 13 B Experimental Details 14 B.1 Data Generation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14 B.2 Baseline Models . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15 B.3 Metrics . . . . . . . . . . ...
work page 2021
-
[7]
Numerical solutions were obtained using a 2/3 dealiased pseudo-spectral method with periodic boundary conditions, implemented in Python with PyTorch, consistent with prior classical papers (Li et al., 2021; Tran et al., 2023). In particular, the NSE dataset was generated using an open-source implementation from (Li et al., 2021). To ensure reproducibility...
work page 2021
-
[8]
and CROP (Gao et al., 2025), as well as physics-encoded models including PeRCNN (Rao et al.,
work page 2025
-
[9]
Details of baseline models are provided as follows: Fourier Neural Operator (FNO)(Li et al., 2021)
and PeSANet (Wan et al., 2025). Details of baseline models are provided as follows: Fourier Neural Operator (FNO)(Li et al., 2021). FNO is one of the most classical data-driven neural operator model that captures features in the frequency domain. Its ability to capture information in the frequency domain allows it to effectively utilize global information...
work page 2025
-
[10]
Factorized Fourier Neural Operator (FFNO)(Tran et al., 2023)
and Fourier modes (12, 16), and selected the best configuration according to the performance on the validation set. Factorized Fourier Neural Operator (FFNO)(Tran et al., 2023). FFNO is an improved neural operator model based on FNO, and its core involves the introduction of factorized Fourier representation. This factorization method and improved network...
work page 2023
-
[11]
CNext(Liu et al., 2022; Ohana et al., 2024)
and network depth (4, 6), and selected the optimal configuration according to the validation set. CNext(Liu et al., 2022; Ohana et al., 2024). CNext is a family of modernized ConvNet models, inspired by the design principles of Vision Transformers (ViTs) while retaining the efficiency and simplicity of convolutional architectures. In the latest benchmark ...
work page 2022
-
[12]
Cross-Resolution Operator-learning Pipeline (CROP)(Gao et al., 2025)
and number of layers (2, 3, 4), and selected the best configuration according to validation performance. Cross-Resolution Operator-learning Pipeline (CROP)(Gao et al., 2025). CROP is a method proposed to address problems with generalization and discretization mismatch error in existing neural operators across different data resolutions. Equipped with a sp...
work page 2025
-
[13]
Physics-embedded Recurrent-Convolutional Neural Network (PeRCNN)(Rao et al., 2023)
and Fourier modes (12, 16), and selected the best configuration according to validation performance. Physics-embedded Recurrent-Convolutional Neural Network (PeRCNN)(Rao et al., 2023). PeRCNN is a physics- encoded learning methodology that directly embeds physical laws into the neural network architecture. It employs multiple parallel convolutional neural...
work page 2023
-
[14]
Physics-encoded Spectral Attention Network (PeSANet)(Wan et al., 2025)
and input kernel size (5, 7), selecting the best configuration based on validation performance. Physics-encoded Spectral Attention Network (PeSANet)(Wan et al., 2025). PeSANet includes a physics-encoded block for approximating local differential operators and a spectral-enhanced block which, combined with spectral 15 arXivTemplateA PREPRINT Table 4:Parame...
work page 2025
-
[15]
For hyperparameter tuning, we searched over the network width (32, 64,
10116 10116 10116 10116 10116 19716 1924 SINO (ours) 1708 9278 9278 9278 9278 11133 2951 attention, captures global features in the frequency domain, allowing it to perform excellently, especially in long-term forecasting accuracy, under scarce data and incomplete physical priors. For hyperparameter tuning, we searched over the network width (32, 64,
work page 1924
-
[16]
This scheme provides stable backpropagation and encourages the models to generalize across different rollout horizons (Brandstetter et al., 2022). 16 arXivTemplateA PREPRINT C Additional Numerical Results C.1 Data Efficiency To evaluate the data efficiency and scalability of SINO, we conduct experiments on KSE (E1) with varying numbers of training traject...
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.