Fragile Preferences: A Deep Dive Into Order Effects in Large Language Models
Pith reviewed 2026-05-19 10:01 UTC · model grok-4.3
The pith
Order effects cause large language models to select strictly inferior options.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors extend the rational choice framework to classify pairwise preferences as robust, fragile, or indifferent. Using this classification across multiple LLMs and domains, they demonstrate that order effects lead models to select strictly inferior options, revealing failure modes distinct from human decision-making.
What carries the argument
The extended rational choice framework that classifies pairwise preferences as robust, fragile, or indifferent to separate superficial tie-breaking from genuine order-induced distortions of judgment.
If this is right
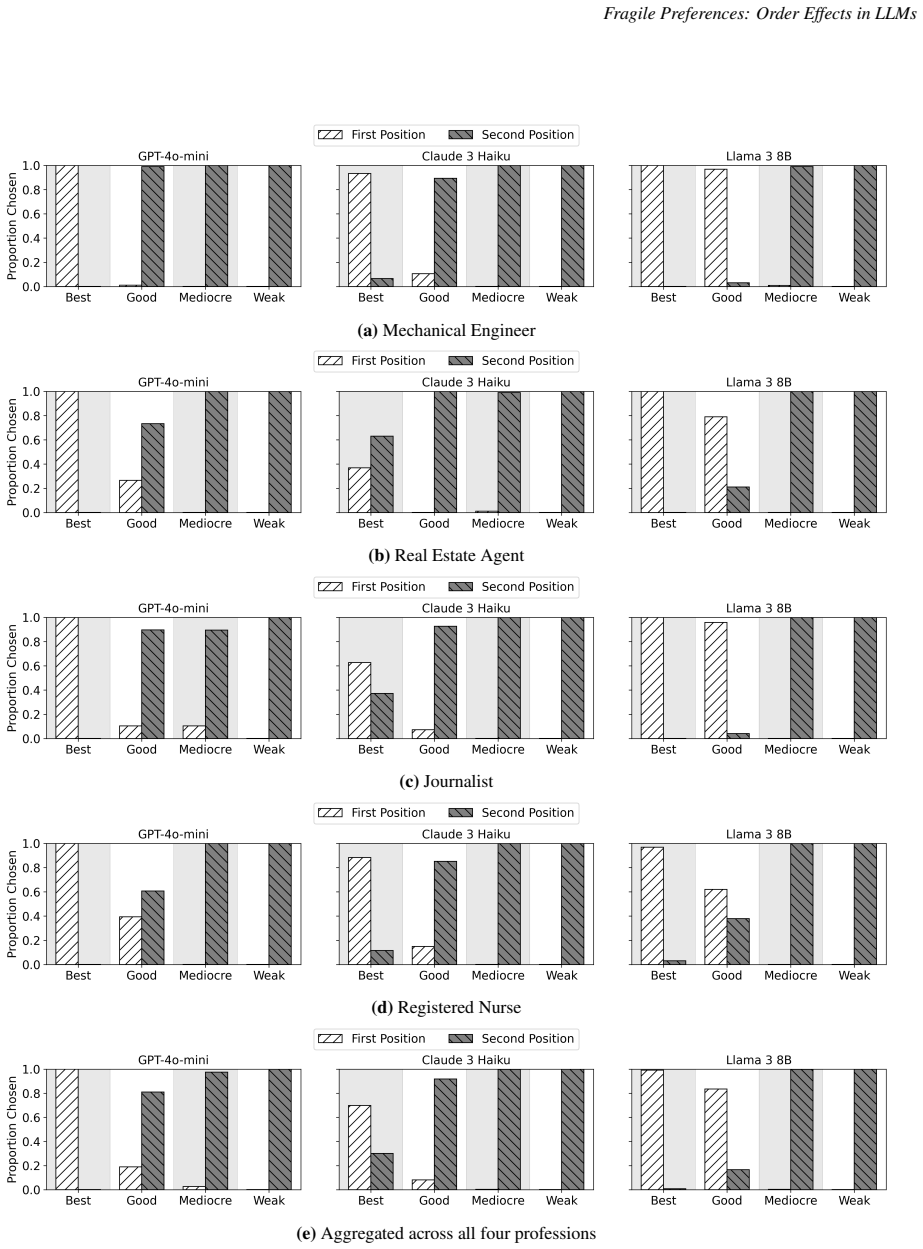
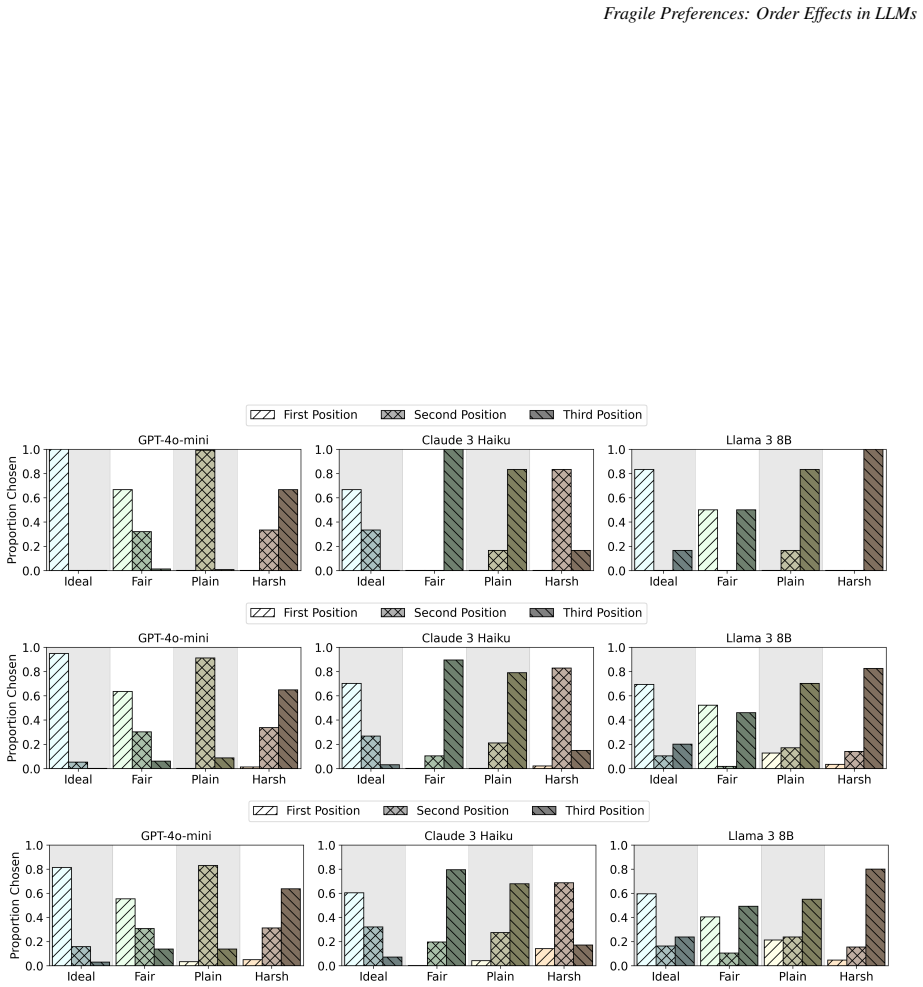
- When all options are high quality, models favor the first presented option.
- When quality is lower, models favor later options instead.
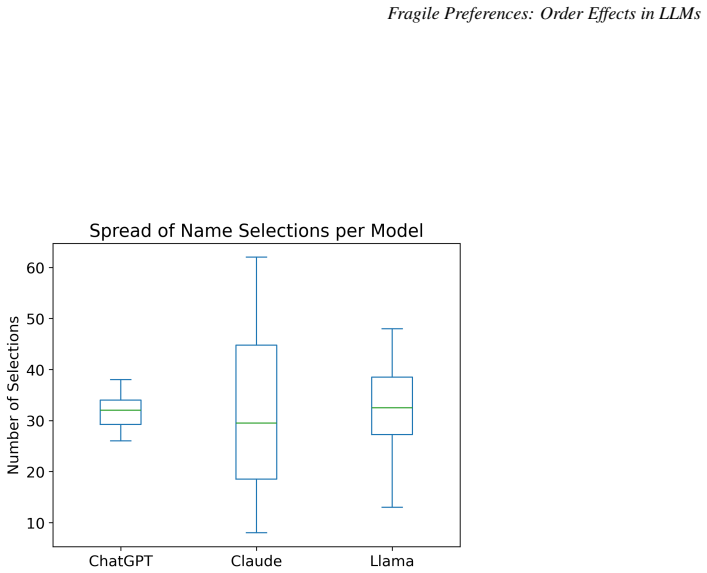
- A name bias favors certain names even after controlling for demographic signals.
- Order effects can produce selection of strictly inferior options rather than mere tie-breaking.
- Adjusting the temperature parameter can mitigate order distortions and recover underlying preferences.
Where Pith is reading between the lines
- High-stakes systems such as hiring or admissions tools may systematically disadvantage candidates based on presentation order.
- The classification of fragile preferences could audit other AI decision systems for similar order vulnerabilities.
- Prompting or sampling methods beyond temperature might further stabilize preferences against position shifts.
- Order-independent evaluation protocols would be needed to make LLM decisions reliable in sequential review settings.
Load-bearing premise
The color selection task successfully isolates pure position effects by removing all confounding factors such as semantic content or real-world associations.
What would settle it
Run the color selection task with objectively ranked colors presented in varied orders and measure whether models still choose lower-ranked options at rates predicted by the quality-dependent shift.
Figures













read the original abstract
Large language models (LLMs) are increasingly deployed in decision-support systems for high-stakes domains such as hiring and university admissions, where choices often involve selecting among competing alternatives. While prior work has noted position biases in LLM-driven comparisons, these biases have not been systematically analyzed or linked to underlying preference structures. We present the first comprehensive study of position biases across multiple LLMs and two distinct domains: resume comparisons, representing a realistic high-stakes context, and color selection, which isolates position effects by removing confounding factors. We find strong and consistent order effects, including a quality-dependent shift: when all options are high quality, models favor the first option, but when quality is lower, they favor later options. We also identify a previously undocumented bias: a name bias, where certain names are favored despite controlling for demographic signals. To separate superficial tie-breaking from genuine distortions of judgment, we extend the rational choice framework to classify pairwise preferences as robust, fragile, or indifferent. Using this framework, we show that order effects can lead models to select strictly inferior options. These results indicate that LLMs exhibit distinct failure modes not documented in human decision-making. We also propose targeted mitigation strategies, including a novel use of the temperature parameter, to recover underlying preferences when order effects distort model behavior.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a comprehensive empirical study of position biases in LLMs across resume comparison (high-stakes) and color selection (controlled) tasks. It reports consistent order effects, a quality-dependent shift (first-position preference for high-quality options, later-position for lower quality), and a name bias. The authors extend the rational choice framework to classify pairwise preferences as robust, fragile, or indifferent, and use this to argue that order effects cause selection of strictly inferior options. Targeted mitigations, including a novel temperature-based approach, are proposed to recover underlying preferences.
Significance. If substantiated with proper statistical controls and independent quality anchors, the work would be significant for documenting LLM-specific failure modes in decision tasks that differ from documented human biases. The robust/fragile/indifferent classification framework offers a reusable tool for dissecting preference distortions. The quality-dependent shift and name bias findings have direct relevance for LLM deployment in hiring and admissions, while the controlled color task and mitigation proposals could inform practical safeguards.
major comments (3)
- [Preference Classification Framework] The extension of the rational choice framework (detailed in the section introducing the robust/fragile/indifferent classification) defines 'strictly inferior' selections from consistency patterns across order permutations. Without an independent, order-independent quality metric (e.g., pre-defined resume scores or objective color attributes) to anchor baseline superiority, the central claim that order effects produce strictly inferior choices risks circularity, as the prompt-supplied quality manipulation itself may be re-interpreted order-dependently.
- [Color Selection Task Description] The color selection task is presented as isolating pure position effects by removing semantic confounders, which underpins attribution of the quality-dependent shift solely to order. However, if the high/low quality labels supplied in the prompt can be processed by the model in an order-sensitive way, this isolation fails and the shift cannot be cleanly separated from re-ranking rather than a true preference violation.
- [Experimental Methods] No sample sizes, number of trials, statistical tests, confidence intervals, or exact prompting templates are reported in the methods or results. This absence directly affects evaluation of the strength and reliability of the order effects and the claim of strictly inferior selections.
minor comments (2)
- [Introduction] The abstract and introduction would benefit from explicit comparison to prior position-bias studies in LLMs to better situate the novelty of the quality-dependent shift.
- [Results Figures] Figures illustrating the quality-dependent shift and name bias should include error bars or significance markers and ensure axis labels are fully descriptive.
Simulated Author's Rebuttal
We thank the referee for their insightful and constructive comments on our manuscript. We address each major comment point by point below, indicating where revisions have been made to improve clarity, rigor, and reporting.
read point-by-point responses
-
Referee: [Preference Classification Framework] The extension of the rational choice framework (detailed in the section introducing the robust/fragile/indifferent classification) defines 'strictly inferior' selections from consistency patterns across order permutations. Without an independent, order-independent quality metric (e.g., pre-defined resume scores or objective color attributes) to anchor baseline superiority, the central claim that order effects produce strictly inferior choices risks circularity, as the prompt-supplied quality manipulation itself may be re-interpreted order-dependently.
Authors: We appreciate the referee's concern about potential circularity. The quality levels in our experiments were defined through explicit, objective manipulations in the prompts (standardized rubrics for resume attributes such as years of experience and education level; specific measurable attributes such as hue and saturation for colors). To directly address the risk of order-dependent reinterpretation, we have added a new subsection describing an independent quality anchoring procedure: a separate set of order-agnostic evaluations (using fixed prompts without positional variation and, where feasible, reference to external objective metrics) to establish baseline superiority before the main pairwise trials. This anchors the 'strictly inferior' classification more firmly outside the order-permutation consistency patterns. revision: partial
-
Referee: [Color Selection Task Description] The color selection task is presented as isolating pure position effects by removing semantic confounders, which underpins attribution of the quality-dependent shift solely to order. However, if the high/low quality labels supplied in the prompt can be processed by the model in an order-sensitive way, this isolation fails and the shift cannot be cleanly separated from re-ranking rather than a true preference violation.
Authors: We agree that quality labels embedded in prompts could in principle be processed in an order-sensitive manner. However, the color task was constructed with deliberately minimal semantic content precisely to isolate positional effects from domain-specific reasoning. The quality-dependent shift we report is replicated across both the resume and color domains, which would be unlikely if the effect were driven solely by label re-ranking. We have revised the task description to clarify the neutral presentation of labels and added a control condition (quality labels omitted) whose results are now reported; the positional bias persists, supporting that the shift reflects a genuine preference distortion rather than label re-ordering alone. revision: partial
-
Referee: [Experimental Methods] No sample sizes, number of trials, statistical tests, confidence intervals, or exact prompting templates are reported in the methods or results. This absence directly affects evaluation of the strength and reliability of the order effects and the claim of strictly inferior selections.
Authors: We thank the referee for highlighting this reporting gap. The Experimental Methods and Results sections have been expanded to include complete details: 500 pairwise comparisons per model per task (with 10 independent runs for robustness), exact trial counts, statistical tests (binomial tests for order preference, ANOVA for quality-by-position interactions, with all p-values, effect sizes, and 95% confidence intervals now reported), and the full prompting templates placed in a new appendix. These additions allow direct assessment of statistical reliability and reproducibility. revision: yes
Circularity Check
No significant circularity; empirical observations and framework extension are self-contained
full rationale
The paper reports direct experimental results from LLM queries on resume comparisons and color selection tasks, with quality levels and position orders explicitly manipulated in prompts. The extension of the rational choice framework classifies pairwise preferences as robust/fragile/indifferent based on consistency across those controlled permutations, then applies the labels to identify order-induced selections. This classification operates on the observed model outputs rather than deriving new quantities from fitted parameters or prior self-citations; the color task is presented as isolating position effects via removal of semantic content, providing an independent anchor for attributing shifts to order. No equations reduce by construction to inputs, no load-bearing self-citations justify core premises, and results remain falsifiable against the raw model responses under the stated prompt conditions.
Axiom & Free-Parameter Ledger
invented entities (1)
-
robust/fragile/indifferent preference classification
no independent evidence
Forward citations
Cited by 2 Pith papers
-
Active Learners as Efficient PRP Rerankers
Active learning rankers outperform sorting-based aggregation of noisy LLM pairwise judgments and a randomized single-call oracle removes position bias without extra queries.
-
Active Learners as Efficient PRP Rerankers
Active learning applied to noisy LLM pairwise judgments improves NDCG@10 per call in budget-constrained reranking and enables unbiased aggregation via a randomized-direction single-call oracle.
Reference graph
Works this paper leans on
-
[1]
Systematic review: The use of large language models as medical chatbots in digestive diseases
Mauro Giuffr `e, Simone Kresevic, Kisung You, Johannes Dupont, Jack Huebner, Alyssa Ann Grimshaw, and Dennis Legen Shung. Systematic review: The use of large language models as medical chatbots in digestive diseases. Alimentary pharmacology & therapeutics, 60(2):144–166, 2024
work page 2024
- [2]
-
[3]
Regulation 2024/1689 of the eur
Nathalie A Smuha. Regulation 2024/1689 of the eur. parl. & council of june 13, 2024 (eu artificial intelligence act). International Legal Materials, pages 1–148, 2025
work page 2024
-
[4]
Auditing work: Exploring the new york city algorithmic bias audit regime
Lara Groves, Jacob Metcalf, Alayna Kennedy, Briana Vecchione, and Andrew Strait. Auditing work: Exploring the new york city algorithmic bias audit regime. In Proceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency, pages 1107–1120, 2024
work page 2024
-
[5]
Dennis, David Graus, Philipp Hacker, Jorge Saldivar, Frederik Zuiderveen Borgesius, and Asia J
Alessandro Fabris, Nina Baranowska, Matthew J. Dennis, David Graus, Philipp Hacker, Jorge Saldivar, Frederik Zuiderveen Borgesius, and Asia J. Biega. Fairness and bias in algorithmic hiring: A multidisciplinary survey. ACM Transactions on Intelligent Systems and Technology, 16(1):1–54, January 2025
work page 2025
-
[6]
Application of LLM Agents in Recruitment: A Novel Framework for Automated Resume Screening
Chengguang Gan, Qinghao Zhang, and Tatsunori Mori. Application of LLM Agents in Recruitment: A Novel Framework for Automated Resume Screening. Journal of Information Processing, 32:881–893, 2024
work page 2024
-
[7]
Gender, race, and intersectional bias in resume screening via language model retrieval
Kyra Wilson and Aylin Caliskan. Gender, race, and intersectional bias in resume screening via language model retrieval. In Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society, volume 7, pages 1578–1590, 2024. 10 Fragile Preferences: Order Effects in LLMs
work page 2024
-
[8]
Gaebler, Sharad Goel, Aziz Huq, and Prasanna Tambe
Johann D. Gaebler, Sharad Goel, Aziz Huq, and Prasanna Tambe. Auditing the use of language models to guide hiring decisions. arXiv [Preprint], 2024. . https://arxiv.org/abs/2404.03086 (accessed 4 July 2025)
-
[9]
Jobfair: A framework for benchmarking gender hiring bias in large language models
Ze Wang, Zekun Wu, Xin Guan, Michael Thaler, Adriano Koshiyama, Skylar Lu, Sachin Beepath, Ediz Ertekin Jr, and Maria Perez-Ortiz. Jobfair: A framework for benchmarking gender hiring bias in large language models. arXiv [Preprint], 2024. . https://arxiv.org/abs/2406.15484 (accessed 4 July 2025)
-
[10]
Prometheus: Inducing fine-grained evaluation capability in language mod- els
Seungone Kim, Jamin Shin, Yejin Cho, Joel Jang, Shayne Longpre, Hwaran Lee, Sangdoo Yun, Seongjin Shin, Sungdong Kim, James Thorne, et al. Prometheus: Inducing fine-grained evaluation capability in language mod- els. In The Twelfth International Conference on Learning Representations, 2023
work page 2023
-
[11]
Learning evaluation models from large language models for sequence generation
Chenglong Wang, Hang Zhou, Kaiyan Chang, Tongran Liu, Chunliang Zhang, Quan Du, Tong Xiao, and Jingbo Zhu. Learning evaluation models from large language models for sequence generation. arXiv [Preprint], 2023. . https://arxiv.org/abs/2308.04386 (accessed 4 July 2025)
-
[12]
Self-judge: Selective instruction following with alignment self-evaluation
Hai Ye and Hwee Tou Ng. Self-judge: Selective instruction following with alignment self-evaluation. arXiv [Preprint], 2024. . https://arxiv.org/abs/2409.00935 (accessed 4 July 2025)
-
[13]
FAIRE: Assessing Racial and Gender Bias in AI-Driven Resume Evaluations, 2025
Athena Wen, Tanush Patil, Ansh Saxena, Yicheng Fu, Sean O’Brien, and Kevin Zhu. FAIRE: Assessing Racial and Gender Bias in AI-Driven Resume Evaluations, 2025
work page 2025
-
[14]
Aligning with human judgement: The role of pairwise preference in large language model evaluators
Yinhong Liu, Han Zhou, Zhijiang Guo, Ehsan Shareghi, Ivan Vuli´c, Anna Korhonen, and Nigel Collier. Aligning with human judgement: The role of pairwise preference in large language model evaluators. arXiv [Preprint],
- [15]
-
[16]
A setwise approach for effective and highly efficient zero-shot ranking with large language models
Shengyao Zhuang, Honglei Zhuang, Bevan Koopman, and Guido Zuccon. A setwise approach for effective and highly efficient zero-shot ranking with large language models. In Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 38–47, 2024
work page 2024
-
[17]
Zhen Qin, Rolf Jagerman, Kai Hui, Honglei Zhuang, Junru Wu, Le Yan, Jiaming Shen, Tianqi Liu, Jialu Liu, Donald Metzler, et al. Large language models are effective text rankers with pairwise ranking prompting. arXiv [Preprint], 2023. . https://arxiv.org/abs/2306.17563 (accessed 4 July 2025)
-
[18]
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging LLM-as-a-judge with MT-bench and chatbot arena.Advances in Neural Information Processing Systems, 36:46595–46623, 2023
work page 2023
-
[19]
Decision making in the employment interview
Edward C Webster and Clifford Wilfred Anderson. Decision making in the employment interview. (No Title), 1964
work page 1964
-
[20]
Factors affecting the final decision in the employment interview
BM Springbett. Factors affecting the final decision in the employment interview. Canadian Journal of Psychol- ogy/Revue canadienne de psychologie, 12(1):13, 1958
work page 1958
-
[21]
The primacy order effect in complex decision making
Arnaud Rey, K ´evin Le Goff, Marl`ene Abadie, and Pierre Courrieu. The primacy order effect in complex decision making. Psychological Research, 84(6):1739–1748, 2020
work page 2020
-
[22]
Primacy and recency effects on clicking behavior
Jamie Murphy, Charles Hofacker, and Richard Mizerski. Primacy and recency effects on clicking behavior. Journal of computer-mediated communication, 11(2):522–535, 2006
work page 2006
-
[23]
Effects of applicant stereotypes, order, and information on interview impressions
Manuel London and Milton D Hakel. Effects of applicant stereotypes, order, and information on interview impressions. Journal of Applied Psychology, 1974
work page 1974
-
[24]
Effect of interview information in altering valid impressions
Robert E Carlson. Effect of interview information in altering valid impressions. Journal of Applied Psychology, 55(1):66, 1971
work page 1971
-
[25]
Amos Tversky and Daniel Kahneman. Judgment under uncertainty: Heuristics and biases: Biases in judgments reveal some heuristics of thinking under uncertainty. science, 185(4157):1124–1131, 1974
work page 1974
-
[26]
A literature review of the anchoring effect
Adrian Furnham and Hua Chu Boo. A literature review of the anchoring effect. The Journal of Socio-Economics, 40(1):35–42, 2011
work page 2011
-
[27]
Training interviewers to eliminate contrast effects in employment interviews
Kenneth N Wexley, Raymond E Sanders, and Gary A Yukel. Training interviewers to eliminate contrast effects in employment interviews. Journal of Applied Psychology, 57(3):233, 1973
work page 1973
-
[28]
Training managers to minimize rating errors in the observation of behavior
Gary P Latham, Kenneth N Wexley, and Elliot D Pursell. Training managers to minimize rating errors in the observation of behavior. Journal of Applied Psychology, 60(5):550, 1975
work page 1975
-
[29]
Scott Highhouse. Context-dependent selection: The effects of decoy and phantom job candidates.Organizational Behavior and Human Decision Processes, 65(1):68–76, 1996
work page 1996
-
[30]
Examining models of nondominated decoy effects across judgment and choice
Jonathan C Pettibone and Douglas H Wedell. Examining models of nondominated decoy effects across judgment and choice. Organizational Behavior and Human Decision Processes, 81(2):300–328, 2000. 11 Fragile Preferences: Order Effects in LLMs
work page 2000
-
[31]
The decoy effect and recommendation systems
Nasim Mousavi, Panagiotis Adamopoulos, and Jesse Bockstedt. The decoy effect and recommendation systems. Information Systems Research, 34(4):1533–1553, 2023
work page 2023
-
[32]
Pouya Pezeshkpour and Estevam Hruschka. Large language models sensitivity to the order of options in multiple- choice questions. arXiv [Preprint], 2023. . https://arxiv.org/abs/2308.11483 (accessed 4 July 2025)
-
[33]
Measuring the inconsistency of large language models in preferential ranking
Xiutian Zhao, Ke Wang, and Wei Peng. Measuring the inconsistency of large language models in preferential ranking. arXiv [Preprint], 2024. . https://arxiv.org/abs/2410.08851 (accessed 4 July 2025)
-
[34]
Serial position effects of large language models, 2024
Xiaobo Guo and Soroush V osoughi. Serial position effects of large language models, 2024
work page 2024
-
[35]
Yiwei Wang, Yujun Cai, Muhao Chen, Yuxuan Liang, and Bryan Hooi. Primacy effect of chatgpt. arXiv [Preprint], 2023. . https://arxiv.org/abs/2310.13206 (accessed 4 July 2025)
-
[36]
David Rozado. Gender and positional biases in llm-based hiring decisions: Evidence from comparative cv/re- sume evaluations. arXiv [Preprint], 2025. . https://arxiv.org/abs/2505.17049 (accessed 4 July 2025)
-
[37]
Anchoring bias in large language models: An experimental study
Jiaxu Lou and Yifan Sun. Anchoring bias in large language models: An experimental study. arXiv [Preprint],
- [38]
-
[39]
Irrelevant alternatives bias large language model hiring decisions
Kremena Valkanova and Pencho Yordanov. Irrelevant alternatives bias large language model hiring decisions. arXiv [Preprint], 2024. . https://arxiv.org/abs/2409.15299 (accessed 4 July 2025)
-
[40]
On the emergence of position bias in transformers
Xinyi Wu, Yifei Wang, Stefanie Jegelka, and Ali Jadbabaie. On the emergence of position bias in transformers. arXiv [Preprint], 2025. . https://arxiv.org/abs/2502.01951 (accessed 4 July 2025)
-
[41]
A systematic evaluation of large lan- guage models of code
Frank F Xu, Uri Alon, Graham Neubig, and Vincent Josua Hellendoorn. A systematic evaluation of large lan- guage models of code. In Proceedings of the 6th ACM SIGPLAN international symposium on machine program- ming, pages 1–10, 2022
work page 2022
-
[42]
The effect of sampling temperature on problem solving in large language models
Matthew Renze. The effect of sampling temperature on problem solving in large language models. In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 7346–7356, 2024
work page 2024
-
[43]
The structure of random utility models
Charles F Manski. The structure of random utility models. Theory and decision, 8(3):229, 1977
work page 1977
-
[44]
Reference-point formation and updating
Manel Baucells, Martin Weber, and Frank Welfens. Reference-point formation and updating. Management Science, 57(3):506–519, 2011
work page 2011
-
[45]
Theory of games and economic behavior: 60th anniversary com- memorative edition
John V on Neumann and Oskar Morgenstern. Theory of games and economic behavior: 60th anniversary com- memorative edition. In Theory of games and economic behavior. Princeton university press, 2007
work page 2007
-
[46]
Explicitly unbiased large language models still form biased associations
Xuechunzi Bai, Angelina Wang, Ilia Sucholutsky, and Thomas L Griffiths. Explicitly unbiased large language models still form biased associations. Proceedings of the National Academy of Sciences , 122(8):e2416228122, 2025
work page 2025
-
[47]
Marked personas: Using natural language prompts to measure stereotypes in language models
Myra Cheng, Esin Durmus, and Dan Jurafsky. Marked personas: Using natural language prompts to measure stereotypes in language models. In The 61st Annual Meeting Of The Association For Computational Linguistics, 2023
work page 2023
-
[48]
The silicon ceiling: Auditing gpt’s race and gender biases in hiring
Lena Armstrong, Abbey Liu, Stephen MacNeil, and Dana ¨e Metaxa. The silicon ceiling: Auditing gpt’s race and gender biases in hiring. In Proceedings of the 4th ACM Conference on Equity and Access in Algorithms, Mechanisms, and Optimization, EAAMO ’24, page 1–18. ACM, October 2024
work page 2024
-
[49]
Gender bias and stereotypes in large language models
Hadas Kotek, Rikker Dockum, and David Sun. Gender bias and stereotypes in large language models. In Proceedings of the ACM collective intelligence conference, pages 12–24, 2023
work page 2023
-
[50]
Choosing to avoid: Coping with negatively emotion-laden consumer decisions
Mary Frances Luce. Choosing to avoid: Coping with negatively emotion-laden consumer decisions. Journal of consumer research, 24(4):409–433, 1998
work page 1998
-
[51]
The effect of expected value on attraction effect preference reversals
George D Farmer, Paul A Warren, Wael El-Deredy, and Andrew Howes. The effect of expected value on attraction effect preference reversals. Journal of Behavioral Decision Making, 30(4):785–793, 2017
work page 2017
-
[52]
Reversals of preference between bids and choices in gambling decisions
Sarah Lichtenstein and Paul Slovic. Reversals of preference between bids and choices in gambling decisions. Journal of experimental psychology, 89(1):46, 1971
work page 1971
-
[53]
Hedgcock, Raghunath Singh Rao, and Haipeng (Allan) Chen
William M. Hedgcock, Raghunath Singh Rao, and Haipeng (Allan) Chen. Choosing to choose: The effects of decoys and prior choice on deferral. Management Science, 62(10):2952–2976, 2016
work page 2016
-
[54]
Large language models show human-like content biases in trans- mission chain experiments
Alberto Acerbi and Joseph M Stubbersfield. Large language models show human-like content biases in trans- mission chain experiments. Proceedings of the National Academy of Sciences, 120(44):e2313790120, 2023
work page 2023
-
[55]
Kyrtin Atreides and David J Kelley. Cognitive biases in natural language: Automatically detecting, differentiat- ing, and measuring bias in text. Cognitive Systems Research, 88:101304, 2024. 12 Fragile Preferences: Order Effects in LLMs
work page 2024
-
[56]
Aadesh Salecha, Molly E Ireland, Shashanka Subrahmanya, Jo ˜ao Sedoc, Lyle H Ungar, and Johannes C Eich- staedt. Large language models display human-like social desirability biases in big five personality surveys.PNAS Nexus, 3(12):page533, 2024
work page 2024
-
[57]
Cognitive bias in high-stakes decision-making with llms
Jessica Maria Echterhoff, Yao Liu, Abeer Alessa, Julian J McAuley, and Zexue He. Cognitive bias in high-stakes decision-making with llms. CoRR, 2024
work page 2024
-
[58]
Simon Malberg, Roman Poletukhin, Carolin M. Schuster, and Georg Groh. A comprehensive evaluation of cognitive biases in llms. arXiv [Preprint], 2024. . https://arxiv.org/abs/2410.15413 (accessed 4 July 2025)
-
[59]
Ammar Shaikh, Raj Abhijit Dandekar, Sreedath Panat, and Rajat Dandekar. Cbeval: A framework for evaluating and interpreting cognitive biases in llms. arXiv [Preprint], 2024. . https://arxiv.org/abs/2412.03605 (accessed 4 July 2025)
-
[60]
Serial effects in recall of unorganized and sequentially organized verbal material
James Deese and Roger A Kaufman. Serial effects in recall of unorganized and sequentially organized verbal material. Journal of experimental psychology, 54(3):180, 1957
work page 1957
-
[61]
Memory: A contribution to experimental psychology
Hermann Ebbinghaus. Memory: A contribution to experimental psychology. Annals of neurosciences, 20(4):155, 2013
work page 2013
-
[62]
Proactive inhibition in short-term retention of single items
Geoffrey Keppel and Benton J Underwood. Proactive inhibition in short-term retention of single items. Journal of Verbal Learning and Verbal Behavior, 1(3):153–161, 1962
work page 1962
-
[63]
Terry L. Boles and David M. Messick. A reverse outcome bias: The influence of multiple reference points on the evaluation of outcomes and decisions.Organizational Behavior and Human Decision Processes, 61(3):262–275, 1995
work page 1995
-
[64]
U.S. Social Security Administration. Popular baby names by decade. https://www.ssa.gov/oact/ babynames/decades/index.html, 2024. Accessed: 2025-06-10. 13 Fragile Preferences: Order Effects in LLMs A Color Comparison Sets and Prompts Each model was asked to perform triplewise and pariwise comparisons on four sets of three colors, categorized by tier. From ...
work page 2024
-
[65]
The expected number of times each name would be chosen if there was no name bias is 32. GPT-4o-mini chose each name between 26 and 38 times, consistent with little to no bias. Claude 3 Haiku ’s selections show high variance, with a wide spread and strong preference for certain names. Figure 13 shows box plots for each model, confirming these patterns: Cla...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.