Online Learning of Whittle Indices for Restless Bandits with Non-Stationary Transition Kernels
Pith reviewed 2026-05-19 07:51 UTC · model grok-4.3
The pith
A sliding-window Whittle policy adapts to unknown non-stationary dynamics in restless bandits while achieving sub-linear dynamic regret.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
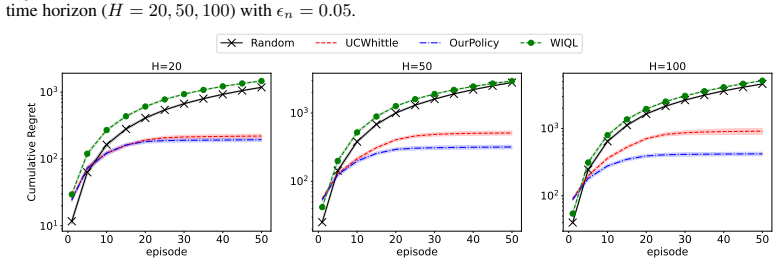
The authors develop the SW-Whittle policy that tracks time-varying kernels by restricting kernel estimates to a sliding window of tunable length, then obtains Whittle indices via upper-confidence bounds on those estimates together with a bilinear optimization routine. They prove that this construction yields sub-linear dynamic regret against the optimal policy for the prevailing dynamics at each episode. When the variation budget is unknown, the same framework is wrapped inside a Bandit-over-Bandit procedure that learns the window length online from the observed total variation, preserving the same regret order.
What carries the argument
The sliding-window estimator of transition kernels, paired with upper-confidence-bound index computation and bilinear optimization to obtain the indices themselves.
If this is right
- The policy stays computationally efficient because index computation reuses the same bilinear routine on recent data only.
- Sub-linear dynamic regret holds uniformly over episodes even though the optimal policy itself changes with the kernels.
- The bandit-over-bandit wrapper removes the need to know the variation budget in advance while keeping the same regret scaling.
- Numerical tests show lower total regret than stationary baselines across multiple drifting environments.
Where Pith is reading between the lines
- The same window-plus-outer-bandit pattern could be tried on other index policies that currently assume stationary dynamics.
- One could examine whether the bilinear optimization step can be replaced by faster approximations without losing the regret guarantee.
- Deployed systems might use the online window-selection rule to set practical adaptation rates when exact variation budgets are unavailable.
Load-bearing premise
The non-stationary transition kernels admit a bounded total variation that some sliding window can track.
What would settle it
A sequence of episodes in which the kernels change faster than any online-tuned window can follow, producing cumulative regret that grows linearly rather than sub-linearly with episode count.
Figures

read the original abstract
The restless multi-armed bandit (RMAB) framework is a popular approach to solving resource allocation problems in networked systems. In this paper, we study optimal resource allocation in RMABs facing unknown and non-stationary dynamics. Solving RMABs optimally is known to be PSPACE-hard even with full knowledge of model parameters. While Whittle index policies offer asymptotic optimality with low computational cost, they require access to stationary transition kernels, an unrealistic assumption in many modern networking applications. To address this challenge, we propose a Sliding-Window Online Whittle (SW-Whittle) policy that remains computationally efficient while adapting to time-varying kernels. Through theoretical analysis, we show that our algorithm achieves sub-linear dynamic regret with respect to the number of episodes. We further address the important case where the variation budget is unknown in advance by combining a Bandit-over-Bandit framework with our sliding-window design. In our scheme, window lengths are tuned online as a function of the estimated variation, while Whittle indices are computed via an upper-confidence-bound of the estimated transition kernels and a bilinear optimization routine. Numerical experiments demonstrate that our algorithm consistently outperforms baselines, achieving the lowest cumulative regret across a range of non-stationary environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the Sliding-Window Online Whittle (SW-Whittle) policy for restless multi-armed bandits with unknown non-stationary transition kernels. It estimates time-varying kernels over sliding windows, computes Whittle indices via UCB bounds and bilinear optimization, and achieves sub-linear dynamic regret w.r.t. the number of episodes. For the case of unknown total variation budget, a Bandit-over-Bandit meta-algorithm is used to tune window lengths online. Numerical experiments on synthetic non-stationary environments show the method outperforming several baselines in cumulative regret.
Significance. If the dynamic-regret bounds hold under the stated variation-budget assumption, the result would meaningfully extend the Whittle-index literature to non-stationary RMAB settings that arise in networking and resource allocation. The explicit handling of unknown variation via an outer bandit-over-bandit layer, together with the computational efficiency of the inner index computation, is a practical strength. The work supplies both a theoretical guarantee and reproducible numerical validation.
major comments (2)
- [§5.3, Theorem 4] §5.3, Theorem 4 (dynamic regret bound): the decomposition into inner SW-Whittle regret O(√W + VT/W) and outer meta-regret O(T^{2/3}K^{1/3} polylog T) is stated, but the proof does not explicitly verify that the sum remains o(T) uniformly over all admissible variation budgets V when W is chosen by the outer algorithm; an additional cross term arising from the dependence between window selection and kernel estimation error appears to be omitted.
- [§4.2, Algorithm 2] §4.2, Algorithm 2 (Bandit-over-Bandit): the outer UCB index for window lengths is defined using an empirical estimate of variation that itself depends on the inner UCB kernel estimates; the analysis does not bound the resulting bias in the meta-regret term, which is load-bearing for the claim that sub-linear regret holds when V is unknown.
minor comments (2)
- [Abstract] The abstract states 'sub-linear dynamic regret with respect to the number of episodes' but does not specify the dependence on the variation budget V; this should be clarified in the introduction and abstract for precision.
- [Figure 3] Figure 3 caption: the legend labels 'SW-Whittle (known V)' and 'SW-Whittle (unknown V)' but the x-axis scale is not labeled as number of episodes; this reduces readability.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive comments on our manuscript. We address the two major comments point by point below, indicating the revisions we will make to strengthen the theoretical analysis.
read point-by-point responses
-
Referee: [§5.3, Theorem 4] §5.3, Theorem 4 (dynamic regret bound): the decomposition into inner SW-Whittle regret O(√W + VT/W) and outer meta-regret O(T^{2/3}K^{1/3} polylog T) is stated, but the proof does not explicitly verify that the sum remains o(T) uniformly over all admissible variation budgets V when W is chosen by the outer algorithm; an additional cross term arising from the dependence between window selection and kernel estimation error appears to be omitted.
Authors: We agree that the main-text statement of Theorem 4 presents the decomposition without an explicit verification that the total remains o(T) uniformly over admissible V, and that a cross term arising from the dependence between the outer window choice and the inner kernel estimation error is not isolated in the provided sketch. The appendix proof controls this dependence implicitly via the concentration of the sliding-window estimators and the fact that the outer algorithm selects W from a discrete grid whose size is polynomial in T, but we acknowledge the presentation would benefit from an explicit step. We will add a supporting lemma that bounds the cross term by O(T^{2/3} polylog T) and verifies that the sum of all terms is o(T) for every V in the admissible range [0,T]. revision: yes
-
Referee: [§4.2, Algorithm 2] §4.2, Algorithm 2 (Bandit-over-Bandit): the outer UCB index for window lengths is defined using an empirical estimate of variation that itself depends on the inner UCB kernel estimates; the analysis does not bound the resulting bias in the meta-regret term, which is load-bearing for the claim that sub-linear regret holds when V is unknown.
Authors: The referee is correct that the outer UCB index is constructed from an empirical variation estimate that inherits error from the inner UCB kernel estimates, and that the current analysis does not explicitly quantify the resulting bias in the meta-regret. We will revise the proof of the Bandit-over-Bandit regret bound by adding a concentration argument showing that the variation estimator deviates from the true V by at most O(√(W log T)) with high probability; this bias contributes an additive term that is absorbed into the existing O(T^{2/3} K^{1/3} polylog T) meta-regret without changing the overall sub-linear rate. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper derives sub-linear dynamic regret for the SW-Whittle policy under non-stationary kernels via standard sliding-window UCB analysis and a Bandit-over-Bandit meta-algorithm for unknown variation budget. The regret decomposition follows established non-stationary bandit techniques (concentration bounds on kernel estimates, bilinear index computation, and window tuning), without any step reducing by construction to a fitted parameter, self-defined quantity, or load-bearing self-citation. The bounded total variation assumption is used to control the bias-variance tradeoff in the regret bound independently of the algorithm's outputs. The central claim therefore rests on external mathematical tools rather than tautological re-labeling of inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Transition kernels possess a bounded total variation budget over the horizon.
Forward citations
Cited by 2 Pith papers
-
A Modularized Framework for Piecewise-Stationary Restless Bandits
A modular PS-RMAB framework integrates base algorithms with change detection and diminishing exploration to achieve tilde-O(sqrt(L M K T)) excess regret against a segment-oracle benchmark, with simulations showing nea...
-
MARBLE: Multi-Armed Restless Bandits in Latent Markovian Environment
Under the Markov-Averaged Indexability condition, synchronous Q-learning with Whittle indices converges almost surely to the optimal Q-function and indices in restless bandits whose arms are driven by an unobserved la...
Reference graph
Works this paper leans on
-
[1]
Restless bandits: Activity allocation in a changing world
Peter Whittle. Restless bandits: Activity allocation in a changing world. Journal of applied probability, 25(A):287–298, 1988
work page 1988
-
[2]
Opportunistic scheduling as restless bandits
Vivek S Borkar, Gaurav S Kasbekar, Sarath Pattathil, and Priyesh Y Shetty. Opportunistic scheduling as restless bandits. IEEE Transactions on Control of Network Systems, 5(4):1952– 1961, 2017
work page 1952
-
[3]
Schedul- ing policies for minimizing age of information in broadcast wireless networks
Igor Kadota, Abhishek Sinha, Elif Uysal-Biyikoglu, Rahul Singh, and Eytan Modiano. Schedul- ing policies for minimizing age of information in broadcast wireless networks. IEEE/ACM Transactions on Networking, 26(6):2637–2650, 2018
work page 2018
-
[4]
A whittle index approach to minimizing functions of age of information
Vishrant Tripathi and Eytan Modiano. A whittle index approach to minimizing functions of age of information. IEEE/ACM Transactions on Networking, 2024
work page 2024
-
[5]
Timely communications for remote inference
Md Kamran Chowdhury Shisher, Yin Sun, and I-Hong Hou. Timely communications for remote inference. IEEE/ACM Transactions on Networking, 32(5):3824–3839, 2024
work page 2024
-
[6]
Igor Kadota, Abhishek Sinha, and Eytan Modiano. Scheduling algorithms for optimizing age of information in wireless networks with throughput constraints. IEEE/ACM Transactions on Networking, 27(4):1359–1372, 2019
work page 2019
-
[7]
Indexability and whittle index for restless bandit problems involving reset processes
Keqin Liu, Richard Weber, and Qing Zhao. Indexability and whittle index for restless bandit problems involving reset processes. In 2011 50th IEEE Conference on Decision and Control and European Control Conference, pages 7690–7696. IEEE, 2011
work page 2011
-
[8]
Diego Ruiz-Hernández, Jesús M Pinar-Pérez, and David Delgado-Gómez. Multi-machine preventive maintenance scheduling with imperfect interventions: A restless bandit approach. Computers & Operations Research, 119:104927, 2020
work page 2020
-
[9]
Scalable operator allocation for multirobot assistance: A restless bandit approach
Abhinav Dahiya, Nima Akbarzadeh, Aditya Mahajan, and Stephen L Smith. Scalable operator allocation for multirobot assistance: A restless bandit approach. IEEE Transactions on Control of Network Systems, 9(3):1397–1408, 2022
work page 2022
-
[10]
Continuous-time restless bandit and dynamic scheduling for make-to-stock production
Fabrice Dusonchet and M-O Hongler. Continuous-time restless bandit and dynamic scheduling for make-to-stock production. IEEE Transactions on Robotics and Automation, 19(6):977–990, 2003
work page 2003
-
[11]
A hidden markov restless multi-armed bandit model for playout recommendation systems
Rahul Meshram, Aditya Gopalan, and D Manjunath. A hidden markov restless multi-armed bandit model for playout recommendation systems. In Communication Systems and Networks: 9th International Conference, COMSNETS 2017, Bengaluru, India, January 4–8, 2017, Revised Selected Papers and Invited Papers 9, pages 335–362. Springer, 2017
work page 2017
-
[12]
On the whittle index for restless multiarmed hidden markov bandits
Rahul Meshram, D Manjunath, and Aditya Gopalan. On the whittle index for restless multiarmed hidden markov bandits. IEEE Transactions on Automatic Control, 63(9):3046–3053, 2018
work page 2018
-
[13]
Multi-armed bandit models for the optimal design of clinical trials: benefits and challenges
Sofía S Villar, Jack Bowden, and James Wason. Multi-armed bandit models for the optimal design of clinical trials: benefits and challenges. Statistical science: a review journal of the Institute of Mathematical Statistics, 30(2):199, 2015
work page 2015
-
[14]
Restless bandits visiting villages: A preliminary study on distributing public health services
Biswarup Bhattacharya. Restless bandits visiting villages: A preliminary study on distributing public health services. In Proceedings of the 1st ACM SIGCAS Conference on Computing and Sustainable Societies, pages 1–8, 2018
work page 2018
-
[15]
Optimal screening for hepatocellular carcinoma: A restless bandit model
Elliot Lee, Mariel S Lavieri, and Michael V olk. Optimal screening for hepatocellular carcinoma: A restless bandit model. Manufacturing & Service Operations Management, 21(1):198–212, 2019
work page 2019
-
[16]
Collapsing bandits and their application to public health intervention
Aditya Mate, Jackson Killian, Haifeng Xu, Andrew Perrault, and Milind Tambe. Collapsing bandits and their application to public health intervention. Advances in Neural Information Processing Systems, 33:15639–15650, 2020. 11
work page 2020
-
[17]
A decision-language model (dlm) for dynamic restless multi-armed bandit tasks in public health
Nikhil Behari, Edwin Zhang, Yunfan Zhao, Aparna Taneja, Dheeraj Nagaraj, and Milind Tambe. A decision-language model (dlm) for dynamic restless multi-armed bandit tasks in public health. arXiv preprint arXiv:2402.14807, 2024
-
[18]
The complexity of optimal queueing network control
Christos H Papadimitriou and John N Tsitsiklis. The complexity of optimal queueing network control. In Proceedings of IEEE 9th Annual Conference on Structure in Complexity Theory, pages 318–322, 1994
work page 1994
-
[19]
On an index policy for restless bandits
Richard R Weber and Gideon Weiss. On an index policy for restless bandits. Journal of applied probability, 27(3):637–648, 1990
work page 1990
-
[20]
Asymptotically optimal priority policies for indexable and nonindexable restless bandits
Ina Maria Verloop. Asymptotically optimal priority policies for indexable and nonindexable restless bandits. The Annals of Applied Probability, 26(4):1947–1995, 2016
work page 1947
-
[21]
When are kalman-filter restless bandits indexable? In C
Christopher R Dance and Tomi Silander. When are kalman-filter restless bandits indexable? In C. Cortes, N. Lawrence, D. Lee, M. Sugiyama, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 28. Curran Associates, Inc., 2015
work page 2015
-
[22]
Multi-uav dynamic routing with partial observations using restless bandit allocation indices
Jerome Le Ny, Munther Dahleh, and Eric Feron. Multi-uav dynamic routing with partial observations using restless bandit allocation indices. In 2008 American Control Conference, pages 4220–4225. IEEE, 2008
work page 2008
-
[23]
Optimistic whittle index policy: Online learning for restless bandits
Kai Wang, Lily Xu, Aparna Taneja, and Milind Tambe. Optimistic whittle index policy: Online learning for restless bandits. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 37, pages 10131–10139, 2023
work page 2023
-
[24]
A reinforcement learning algorithm for restless bandits
Vivek S Borkar and Karan Chadha. A reinforcement learning algorithm for restless bandits. In 2018 Indian Control Conference (ICC), pages 89–94. IEEE, 2018
work page 2018
-
[25]
Real-time status: How often should one update? In IEEE INFOCOM, pages 2731–2735, 2012
Sanjit Kaul, Roy Yates, and Marco Gruteser. Real-time status: How often should one update? In IEEE INFOCOM, pages 2731–2735, 2012
work page 2012
-
[26]
Yin Sun, Elif Uysal-Biyikoglu, Roy Yates, C. Emre Koksal, and Ness B. Shroff. Update or wait: How to keep your data fresh. In IEEE INFOCOM, pages 1–9, 2016. doi: 10.1109/INFOCOM. 2016.7524524
-
[27]
Arpita Biswas, Gaurav Aggarwal, Pradeep Varakantham, and Milind Tambe. Learn to intervene: An adaptive learning policy for restless bandits in application to preventive healthcare. arXiv preprint arXiv:2105.07965, 2021
-
[28]
Restless bandits with controlled restarts: Indexability and computation of whittle index
Nima Akbarzadeh and Aditya Mahajan. Restless bandits with controlled restarts: Indexability and computation of whittle index. In 2019 IEEE 58th conference on decision and control (CDC), pages 7294–7300. IEEE, 2019
work page 2019
-
[29]
Tasmeen Zaman Ornee and Yin Sun. A Whittle index policy for the remote estimation of multiple continuous Gauss-Markov processes over parallel channels. ACM MobiHoc, 2023
work page 2023
-
[30]
Whittle index based q-learning for restless bandits with average reward
Konstantin E Avrachenkov and Vivek S Borkar. Whittle index based q-learning for restless bandits with average reward. Automatica, 139:110186, 2022
work page 2022
-
[31]
Towards q-learning the whittle index for restless bandits
Jing Fu, Yoni Nazarathy, Sarat Moka, and Peter G Taylor. Towards q-learning the whittle index for restless bandits. In 2019 Australian & New Zealand Control Conference (ANZCC), pages 249–254. IEEE, 2019
work page 2019
-
[32]
Neurwin: Neural whittle index network for restless bandits via deep rl
Khaled Nakhleh, Santosh Ganji, Ping-Chun Hsieh, I Hou, Srinivas Shakkottai, et al. Neurwin: Neural whittle index network for restless bandits via deep rl. Advances in Neural Information Processing Systems, 34:828–839, 2021
work page 2021
-
[33]
Deeptop: Deep threshold-optimal policy for mdps and rmabs
Khaled Nakhleh, I Hou, et al. Deeptop: Deep threshold-optimal policy for mdps and rmabs. Advances in Neural Information Processing Systems, 35:28734–28746, 2022
work page 2022
-
[34]
An online learning approach to optimizing time-varying costs of aoi
Vishrant Tripathi and Eytan Modiano. An online learning approach to optimizing time-varying costs of aoi. In Proceedings of the Twenty-second International Symposium on Theory, Algo- rithmic Foundations, and Protocol Design for Mobile Networks and Mobile Computing, pages 241–250, 2021. 12
work page 2021
-
[35]
Lecture notes on information theory
Yury Polyanskiy and Yihong Wu. Lecture notes on information theory. Lecture Notes for MIT (6.441), UIUC (ECE 563), Yale (STAT 664), (2012-2017), 2014
work page 2012
-
[36]
Non-stationary stochastic optimization
Omar Besbes, Yonatan Gur, and Assaf Zeevi. Non-stationary stochastic optimization. Opera- tions research, 63(5):1227–1244, 2015
work page 2015
-
[37]
Optimal exploration–exploitation in a multi-armed bandit problem with non-stationary rewards
Omar Besbes, Yonatan Gur, and Assaf Zeevi. Optimal exploration–exploitation in a multi-armed bandit problem with non-stationary rewards. Stochastic Systems, 9(4):319–337, 2019
work page 2019
-
[38]
Q-learning lagrange policies for multi-action restless bandits
Jackson A Killian, Arpita Biswas, Sanket Shah, and Milind Tambe. Q-learning lagrange policies for multi-action restless bandits. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, pages 871–881, 2021
work page 2021
-
[39]
Zvifadzo Matsena Zingoni, Tobias F Chirwa, Jim Todd, and Eustasius Musenge. A review of multistate modelling approaches in monitoring disease progression: Bayesian estimation using the kolmogorov-chapman forward equations. Statistical methods in medical research, 30(5): 1373–1392, 2021
work page 2021
-
[40]
Monitored markov decision processes
Simone Parisi, Montaser Mohammedalamen, Alireza Kazemipour, Matthew E Taylor, and Michael Bowling. Monitored markov decision processes. arXiv preprint arXiv:2402.06819, 2024
-
[41]
Sampling for data freshness optimization: Non-linear age functions
Yin Sun and Benjamin Cyr. Sampling for data freshness optimization: Non-linear age functions. J. Commun. Netw., 21(3):204–219, 2019
work page 2019
-
[42]
Inequalities for the l1 deviation of the empirical distribution
Tsachy Weissman, Erik Ordentlich, Gadiel Seroussi, Sergio Verdu, and Marcelo J Weinberger. Inequalities for the l1 deviation of the empirical distribution. Hewlett-Packard Labs, Tech. Rep, page 125, 2003. 13 A Proof of Lemma 1 We can get Lemma 1 by combining Lemma 2 and Lemma 3, which are provided below: Lemma 2. Given η1 > 0 and t ≥ 1, for (s, a) ∈ Z (n)...
work page 2003
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.