Causal Discovery for Irregularly Time Series with Consistency Guarantees
Pith reviewed 2026-05-19 06:44 UTC · model grok-4.3
The pith
ReTimeCausal recovers consistent causal structures from irregularly sampled time series by alternating between imputation and structure learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
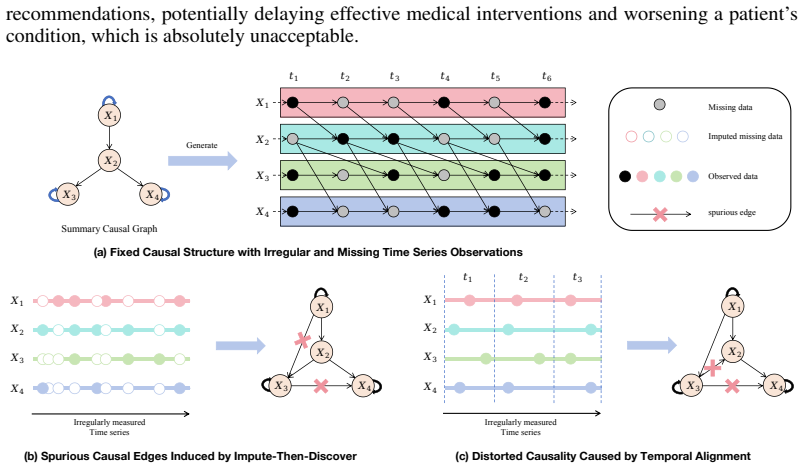
ReTimeCausal is an EM-style procedure that alternates between imputing missing values in irregularly sampled time series and estimating the causal structure via kernel-based sparse regression subject to structural constraints. The alternation is designed to promote mutual consistency between the imputed data and the graph estimate. The paper establishes theoretical consistency guarantees that extend classical structure-recovery results to the irregular-sampling and high-missingness regime.
What carries the argument
ReTimeCausal, the alternating EM-style loop that updates the completed data matrix and the causal graph estimate in turn using kernel-based sparse regression.
If this is right
- The method extends classical consistency guarantees for causal structure recovery to irregular sampling rates and high fractions of missing entries.
- The alternating process prevents imputation errors and structure errors from reinforcing each other.
- Performance on both synthetic and real data exceeds that of separate imputation followed by discovery or joint neural optimization.
- The framework applies directly to risk-sensitive settings such as finance, healthcare, and climate monitoring where irregular sampling is common.
Where Pith is reading between the lines
- If the consistency result holds, the same alternating idea could be tested on other structure-learning backbones besides kernel sparse regression.
- The guarantees suggest the method may remain reliable on real monitoring streams where sampling gaps vary over time rather than staying fixed.
- One could examine whether the number of alternation rounds needed for convergence scales predictably with the degree of irregularity.
Load-bearing premise
Each round of kernel-based sparse regression on the current imputation yields a graph estimate accurate enough to steer the next imputation step toward the true structure instead of reinforcing earlier errors.
What would settle it
Generate synthetic time series from a known ground-truth causal graph, apply controlled irregular sampling and missingness, run ReTimeCausal, and check whether the estimated graph converges in probability to the true graph as the number of observed time points grows.
Figures

read the original abstract
This paper studies causal discovery in irregularly sampled time series-a key challenge in risk-sensitive domains like finance, healthcare, and climate science, where missing data and inconsistent sampling frequencies distort causal mechanisms. The main challenge comes from the interdependence between missing data imputation and causal structure recovery: errors in imputation and structure learning can reinforce each other, leading to an inaccurate causal graph. Existing methods either impute first and then discover, or jointly optimize both via neural representation learning, but lack explicit mechanisms to ensure mutual consistency of imputation and structure learning. We address this challenge with ReTimeCausal, an EM-based framework that alternates between imputation and structure learning, which encourages structural consistency throughout the optimization process. Our framework provides theoretical consistency guarantees for structure recovery and extends classical results to settings with irregular sampling and high missingness. ReTimeCausal combines kernel-based sparse regression and structural constraints in an alternating process that updates the completed data and the causal graph in turn. Experiments on synthetic and real-world datasets show that ReTimeCausal is more effective than existing methods under challenging irregular sampling and missing data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ReTimeCausal, an EM-style alternating optimization framework for causal discovery in irregularly sampled time series subject to high missingness. It alternates kernel-based sparse regression for structure learning with data imputation, imposing structural constraints to encourage consistency between the two steps, and claims to provide theoretical consistency guarantees that extend classical sparse regression results to this setting. Experiments on synthetic and real-world datasets report improved structure recovery over baselines that either impute first or jointly optimize via neural representations.
Significance. If the claimed consistency guarantees can be rigorously established under explicit assumptions, the work would address a practically important gap: reliable causal structure recovery when imputation and graph learning can otherwise reinforce each other's errors. The alternating procedure with kernel regression offers a concrete mechanism that could be useful in finance, healthcare, and climate applications where irregular sampling is common.
major comments (2)
- [Abstract and §3] Abstract and §3 (Method): the claim of 'theoretical consistency guarantees for structure recovery' is stated without any derivation steps, proof sketch, or list of assumptions (e.g., on the kernel, the missingness mechanism, identifiability of the causal graph, or contraction properties of the alternation). Classical consistency for sparse regression does not automatically transfer when the design matrix is iteratively constructed from the previous imputation estimate.
- [§3.2] §3.2 (Alternating procedure): the central assumption that the kernel-based sparse regression step, applied to the current imputation, will produce a sufficiently accurate graph estimate to drive the next imputation toward the true structure is not supported by any contraction mapping, monotonic improvement argument, or identifiability condition. Under high missingness, early biased imputations can induce spurious edges that feed back into worse imputations, and no analysis rules out convergence to an incorrect fixed point.
minor comments (2)
- [§4] §4 (Experiments): the description of synthetic data generation and the precise irregular sampling patterns (e.g., sampling frequencies, missing rates) should be expanded with explicit parameters to allow exact reproduction of the reported results.
- [Notation] Notation throughout: define the kernel function, the precise form of the structural constraints, and the stopping criterion for the alternation more explicitly.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback on our manuscript. We address each major comment below, clarifying the current state of the theoretical analysis and outlining the revisions we will make to strengthen the presentation of the consistency guarantees and the alternating procedure.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Method): the claim of 'theoretical consistency guarantees for structure recovery' is stated without any derivation steps, proof sketch, or list of assumptions (e.g., on the kernel, the missingness mechanism, identifiability of the causal graph, or contraction properties of the alternation). Classical consistency for sparse regression does not automatically transfer when the design matrix is iteratively constructed from the previous imputation estimate.
Authors: We agree that the abstract and Section 3 currently state the consistency guarantees at a high level without an explicit list of assumptions or a proof sketch. The intended extension of classical sparse regression consistency relies on the kernel being characteristic, the missingness mechanism satisfying MAR, and the causal graph being identifiable from the time-series structure; however, these are not enumerated in the main text. We will revise the manuscript to include a dedicated subsection (or appendix) that lists all assumptions and provides a high-level proof outline showing how the alternating updates preserve consistency when the imputation error is controlled. revision: yes
-
Referee: [§3.2] §3.2 (Alternating procedure): the central assumption that the kernel-based sparse regression step, applied to the current imputation, will produce a sufficiently accurate graph estimate to drive the next imputation toward the true structure is not supported by any contraction mapping, monotonic improvement argument, or identifiability condition. Under high missingness, early biased imputations can induce spurious edges that feed back into worse imputations, and no analysis rules out convergence to an incorrect fixed point.
Authors: This concern is well-founded. The current manuscript motivates the structural constraints as a mechanism to encourage consistency but does not supply a contraction-mapping argument or explicit conditions ruling out spurious fixed points. We will revise Section 3.2 to add a discussion of this issue, including sufficient conditions (e.g., bounded imputation error after the first iteration and graph identifiability) under which the alternation is expected to improve, together with a note on potential limitations under extreme missingness. Supporting simulation results already in the experiments will be highlighted as empirical evidence. revision: partial
Circularity Check
No circularity detected in claimed consistency guarantees
full rationale
The paper introduces ReTimeCausal as an EM-style alternation between kernel-based sparse regression for structure learning and imputation of irregularly sampled time series. The central theoretical claim is an extension of classical consistency results to this setting, rather than any quantity defined in terms of its own fitted parameters or a self-referential fixed point. No equations or steps in the provided abstract reduce a prediction or guarantee to a fit by construction, and the load-bearing alternation is presented as a procedural mechanism whose convergence properties are asserted via extension of prior results rather than by renaming or self-definition. The derivation chain therefore remains self-contained against external benchmarks for sparse regression consistency.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The underlying data-generating process admits a sparse causal graph that can be recovered by kernel-based regression once missing entries are imputed.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
ReTimeCausal ... alternates between imputation and structure learning ... kernel-based sparse regression ... Proposition 1 (Structural Consistency) ... recovers the true causal graph G∗ with probability one
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Additive Noise Model (ANM) ... fi(Pat i) + ϵt i
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Benchmarking Sensor-Fault Robustness in Forecasting
SensorFault-Bench is a new CPS-grounded benchmark showing that clean-MSE rankings of forecasting models often disagree with their robustness under standardized sensor-fault scenarios across four real datasets.
Reference graph
Works this paper leans on
-
[1]
Assaad, Emilie Devijver, and Eric Gaussier
Charles K. Assaad, Emilie Devijver, and Eric Gaussier. Survey and evaluation of causal discovery methods for time series. J. Artif. Int. Res. , 73, May 2022. ISSN 1076-9757. doi: 10.1613/jair.1.13428. URL https://doi.org/10.1613/jair.1.13428. 9
-
[2]
Rohit Bhattacharya, Razieh Nabi, Ilya Shpitser, and James M. Robins. Identification in missing data models represented by directed acyclic graphs. In Ryan P. Adams and Vibhav Gogate, editors, Proceedings of The 35th Uncertainty in Artificial Intelligence Conference, volume 115 of Proceedings of Machine Learning Research, pages 1149–1158. PMLR, 22–25 Jul 2...
work page 2020
-
[3]
Differentiable causal discovery from interventional data
Philippe Brouillard, Sébastien Lachapelle, Alexandre Lacoste, Simon Lacoste-Julien, and Alexandre Drouin. Differentiable causal discovery from interventional data. In Proceedings of the 34th International Conference on Neural Information Processing Systems, NIPS ’20, Red Hook, NY , USA, 2020. Curran Associates Inc. ISBN 9781713829546
work page 2020
-
[4]
Peter Bühlmann, Jonas Peters, and Jan Ernest. Cam: Causal additive models, high-dimensional order search and penalized regression. The Annals of Statistics, 42, 10 2013. doi: 10.1214/14-AOS1260
-
[5]
Vinod Kumar Chauhan, Anshul Thakur, Odhran O’Donoghue, Omid Rohanian, Soheila Molaei, and David A. Clifton. Continuous patient state attention model for addressing irregularity in electronic health records. BMC Medical Informatics and Decision Making , 24(1):117, 2024. doi: 10.1186/ s12911-024-02514-2. URL https://bmcmedinformdecismak.biomedcentral.com/ar...
work page 2024
-
[6]
CUTS: Neural causal discovery from irregular time-series data
Yuxiao Cheng, Runzhao Yang, Tingxiong Xiao, Zongren Li, Jinli Suo, Kunlun He, and Qionghai Dai. CUTS: Neural causal discovery from irregular time-series data. In The Eleventh International Conference on Learning Representations (ICLR), 2023. URL https://openreview.net/forum?id= UG8bQcD3Emv
work page 2023
-
[7]
Yuxiao Cheng, Lianglong Li, Tingxiong Xiao, Zongren Li, Jinli Suo, Kunlun He, and Qionghai Dai. CUTS+: high-dimensional causal discovery from irregular time-series. In Proceedings of the Thirty- Eighth AAAI Conference on Artificial Intelligence and Thirty-Sixth Conference on Innovative Applications of Artificial Intelligence and Fourteenth Symposium on Ed...
-
[8]
Missdag: causal discovery in the presence of missing data with continuous additive noise models
Erdun Gao, Ignavier Ng, Mingming Gong, Li Shen, Wei Huang, Tongliang Liu, Kun Zhang, and Howard Bondell. Missdag: causal discovery in the presence of missing data with continuous additive noise models. In Proceedings of the 36th International Conference on Neural Information Processing Systems, NIPS ’22, Red Hook, NY , USA, 2022. Curran Associates Inc. IS...
work page 2022
-
[9]
Causalrivers - scaling up benchmarking of causal discovery for real-world time-series
Stein Gideon, Shadaydeh Maha, Blunk Jan, Penzel Niklas, and Denzler Joachim. Causalrivers - scaling up benchmarking of causal discovery for real-world time-series. In The Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=wmV4cIbgl6
work page 2025
-
[10]
Causal discovery from temporal data: An overview and new perspectives.ACM Comput
Chang Gong, Chuzhe Zhang, Di Yao, Jingping Bi, Wenbin Li, and YongJun Xu. Causal discovery from temporal data: An overview and new perspectives. ACM Comput. Surv., 57(4), December 2024. ISSN 0360-0300. doi: 10.1145/3705297. URL https://doi.org/10.1145/3705297
-
[11]
Hoyer, Dominik Janzing, Joris Mooij, Jonas Peters, and Bernhard Schölkopf
Patrik O. Hoyer, Dominik Janzing, Joris Mooij, Jonas Peters, and Bernhard Schölkopf. Nonlinear causal discovery with additive noise models. In Proceedings of the 22nd International Conference on Neural Information Processing Systems, NIPS’08, page 689–696, Red Hook, NY , USA, 2008. Curran Associates Inc. ISBN 9781605609492
work page 2008
-
[12]
Gradient-based neural dag learning
Sébastien Lachapelle, Philippe Brouillard, Tristan Deleu, and Simon Lacoste-Julien. Gradient-based neural dag learning. In International Conference on Learning Representations , 2020. URL https: //openreview.net/forum?id=rklbKA4YDS
work page 2020
-
[13]
Steven Cheng-Xian Li and Benjamin M. Marlin. Learning from irregularly-sampled time series: A missing data perspective. In Proceedings of the 37th International Conference on Machine Learning, 2020
work page 2020
-
[14]
Mengxi Liu, Daniel Geißler, Sizhen Bian, Bo Zhou, and Paul Lukowicz. Assessing the impact of sampling irregularity in time series data: Human activity recognition as a case study, 2025. URL https://arxiv.org/abs/2501.15330
-
[15]
Causal discovery from subsampled time series with proxy variables
Mingzhou Liu, Xinwei Sun, Lingjing Hu, and Yizhou Wang. Causal discovery from subsampled time series with proxy variables. In Proceedings of the 37th International Conference on Neural Information Processing Systems, NIPS ’23, Red Hook, NY , USA, 2023. Curran Associates Inc
work page 2023
-
[16]
Improving the imputation of missing data with markov blanket discovery
Yang Liu and Anthony Constantinou. Improving the imputation of missing data with markov blanket discovery. In The Eleventh International Conference on Learning Representations, 2023. URL https: //openreview.net/forum?id=GrpU6dxFmMN. 10
work page 2023
-
[17]
Dynotears: Structure learning from time-series data
Roxana Pamfil, Nisara Sriwattanaworachai, Shaan Desai, Philip Pilgerstorfer, Konstantinos Georgatzis, Paul Beaumont, and Bryon Aragam. Dynotears: Structure learning from time-series data. In Silvia Chiappa and Roberto Calandra, editors, Proceedings of the Twenty Third International Conference on Artificial Intelligence and Statistics, volume 108 of Procee...
work page 2020
-
[18]
Identification of causal structure in the presence of missing data with additive noise model
Jie Qiao, Zhengming Chen, Jianhua Yu, Ruichu Cai, and Zhifeng Hao. Identification of causal structure in the presence of missing data with additive noise model. Proceedings of the AAAI Conference on Artificial Intelligence, 38(18):20516–20523, Mar. 2024. doi: 10.1609/aaai.v38i18.30036. URL https: //ojs.aaai.org/index.php/AAAI/article/view/30036
-
[19]
Mahecha, Jordi Muñoz-Marí, Egbert H
Jakob Runge, Sebastian Bathiany, Erik Bollt, Gustau Camps-Valls, Dim Coumou, Ethan Deyle, Clark Glymour, Marlene Kretschmer, Miguel D. Mahecha, Jordi Muñoz-Marí, Egbert H. van Nes, Jonas Peters, Rick Quax, Markus Reichstein, Marten Scheffer, Bernhard Schölkopf, Peter Spirtes, George Sugihara, Jie Sun, Kun Zhang, and Jakob Zscheischler. Inferring causation...
-
[20]
Detecting and quantifying causal associations in large nonlinear time series datasets
Jakob Runge, Peer Nowack, Marlene Kretschmer, Seth Flaxman, and Dino Sejdinovic. Detecting and quantifying causal associations in large nonlinear time series datasets. Science Advances, 5(11):eaau4996,
-
[21]
Inferring causation from time series in Earth sys- tem sciences,
doi: 10.1126/sciadv.aau4996. URL https://www.science.org/doi/abs/10.1126/sciadv. aau4996
-
[22]
Causal discovery in financial markets: A framework for nonstationary time-series data
Agathe Sadeghi, Achintya Gopal, and Mohammad Fesanghary. Causal discovery in financial markets: A framework for nonstationary time-series data, 2024. URL https://arxiv.org/abs/2312.17375
-
[23]
Pedro Sanchez, Jeremy P. V oisey, Tian Xia, Hannah I. Watson, Alison Q. ONeil, and Sotirios A. Tsaftaris. Causal machine learning for healthcare and precision medicine. arXiv preprint arXiv:2205.11402, 2022. URL https://arxiv.org/abs/2205.11402
-
[24]
Bernhard Schölkopf and Alexander J. Smola. Learning with Kernels: Support Vector Machines, Regularization, Optimization, and Beyond . The MIT Press, 12 2001. ISBN 9780262256933. doi: 10.7551/mitpress/4175.001.0001. URL https://doi.org/10.7551/mitpress/4175.001.0001
-
[25]
J. M. Smit, J. H. Krijthe, W. M. R. Kant, J. A. Labrecque, M. Komorowski, D. A. M. P. J. Gommers, J. van Bommel, M. J. T. Reinders, and M. E. van Genderen. Causal inference using observational intensive care unit data: a scoping review and recommendations for future practice. npj Digital Medicine, 6(1):221, 2023. doi: 10.1038/s41746-023-00961-1. URL https...
-
[26]
Alik Sokolov, Fabrizzio Sabelli, Behzad Azadie faraz, Wuding Li, and Luis A. Seco. Towards automating causal discovery in financial markets and beyond. Technical report, SSRN, December 2023. URL https: //ssrn.com/abstract=4679414. Available at SSRN: https://ssrn.com/abstract=4679414 or http://dx.doi.org/10.2139/ssrn.4679414
-
[27]
Causal discovery with stage variables for health time series,
Bharat Srikishan and Samantha Kleinberg. Causal discovery with stage variables for health time series,
- [28]
-
[29]
Nts-notears: Learning nonparametric dbns with prior knowledge
Xiangyu Sun, Oliver Schulte, Guiliang Liu, and Pascal Poupart. Nts-notears: Learning nonparametric dbns with prior knowledge. In Francisco Ruiz, Jennifer Dy, and Jan-Willem van de Meent, editors, Proceedings of The 26th International Conference on Artificial Intelligence and Statistics, volume 206 of Proceedings of Machine Learning Research, pages 1942–19...
work page 1942
-
[30]
Regression shrinkage and selection via the lasso
Robert Tibshirani. Regression shrinkage and selection via the lasso. Journal of the Royal Statistical Society Series B: Statistical Methodology, 58(1):267–288, 1996
work page 1996
-
[31]
Causal discovery in the presence of missing data
Ruibo Tu, Cheng Zhang, Paul Ackermann, Karthika Mohan, Hedvig Kjellström, and Kun Zhang. Causal discovery in the presence of missing data. In Kamalika Chaudhuri and Masashi Sugiyama, editors, Proceedings of the Twenty-Second International Conference on Artificial Intelligence and Statistics , volume 89 of Proceedings of Machine Learning Research, pages 17...
work page 2019
-
[32]
Martin J. Wainwright. Sharp thresholds for high-dimensional and noisy sparsity recovery using ℓ1 - constrained quadratic programming (lasso). IEEE Transactions on Information Theory, 55(5):2183–2202,
-
[33]
doi: 10.1109/TIT.2009.2016018
-
[34]
Shiyu Wang, Haixu Wu, Xiaoming Shi, Tengge Hu, Huakun Luo, Lintao Ma, James Y . Zhang, and Jun Zhou. Timemixer: Decomposable multiscale mixing for time series forecasting. In ICLR, 2024. URL https://openreview.net/forum?id=7oLshfEIC2. 11
work page 2024
-
[35]
Causal discovery from incomplete data: A deep learning approach, 2020
Yuhao Wang, Vlado Menkovski, Hao Wang, Xin Du, and Mykola Pechenizkiy. Causal discovery from incomplete data: A deep learning approach, 2020. URL https://arxiv.org/abs/2001.05343
-
[36]
Learning instrumental variable from data fusion for treatment effect estimation
Anpeng Wu, Kun Kuang, Ruoxuan Xiong, Minqing Zhu, Yuxuan Liu, Bo Li, Furui Liu, Zhihua Wang, and Fei Wu. Learning instrumental variable from data fusion for treatment effect estimation. In Proceedings of the Thirty-Seventh AAAI Conference on Artificial Intelligence and Thirty-Fifth Conference on Innovative Applications of Artificial Intelligence and Thirt...
-
[37]
Learning causal relations from subsampled time series with two time-slices
Anpeng Wu, Haoxuan Li, Kun Kuang, Keli Zhang, and Fei Wu. Learning causal relations from subsampled time series with two time-slices. In Proceedings of the 41st International Conference on Machine Learning, ICML’24. JMLR.org, 2024
work page 2024
-
[38]
C. F. Jeff Wu. On the convergence properties of the em algorithm. The Annals of Statistics, 11(1):95–103, 1983
work page 1983
-
[39]
Y . Xu et al. Predictive modeling of biomedical temporal data in healthcare: challenges and solutions. Journal of Biomedical Informatics , 145:104379, 2024. doi: 10.1016/j.jbi.2024.104379. URL https: //www.sciencedirect.com/science/article/pii/S1532046424000796. 12
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.