From REST to MCP: An Empirical Study of API Wrapping and Automated Server Generation for LLM Agents
Pith reviewed 2026-05-19 03:20 UTC · model grok-4.3
The pith
MCP servers predominantly wrap existing REST APIs as bare tools, exposing a median of 19% of operations in predictable patterns that support automated generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
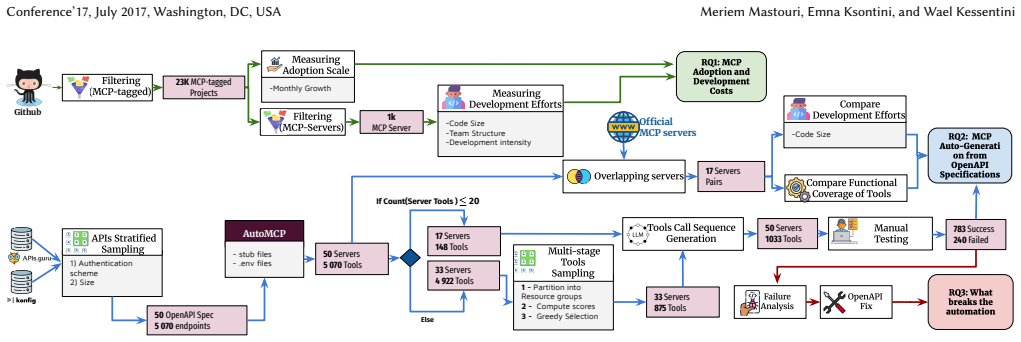
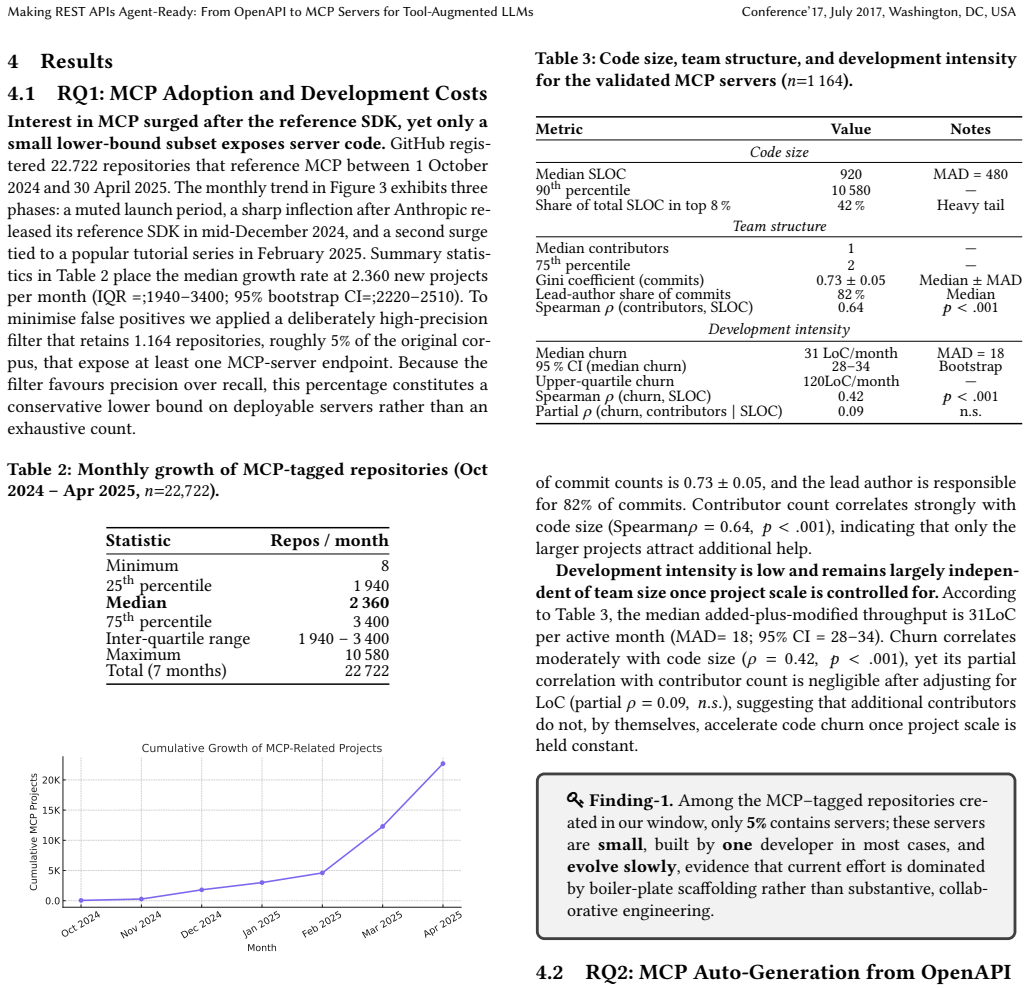
Through examination of 116 official MCP servers the authors establish that 88.6% are fully or partially REST-backed and 92% implement tools as bare API wrappers. Pairing servers with OpenAPI specifications shows that MCP servers expose a median of 19% of available operations and follow systematic, predictable mapping patterns. Automated generation from 80 real-world OpenAPI contracts succeeds for 76% of sampled tools; specification repair lifts this to 94.2% while filtering and regrouping reduce the median tool count per API by one-third. The work releases AutoMCP, an end-to-end pipeline that integrates these empirically derived repair and transformation steps.
What carries the argument
The central mechanism is the empirical quantification of operation exposure, omission, and mapping patterns between OpenAPI specifications and MCP tool definitions, combined with the AutoMCP pipeline that applies specification repair followed by filtering and regrouping transformations.
If this is right
- MCP servers can be generated from existing REST specifications with high reliability once common issues are repaired.
- Predictable exposure patterns allow systematic simplification of tool sets without losing essential functionality.
- Automated pipelines reduce the manual effort needed to expose vendor services to LLM agents.
- Direct wrapper implementations dominate, suggesting MCP functions largely as a thin, standardized interface over legacy APIs.
Where Pith is reading between the lines
- If the observed patterns persist, new services could design their REST APIs with MCP compatibility in mind from the start.
- The release of AutoMCP may lower the barrier for smaller teams to publish MCP servers for niche APIs.
- Widespread adoption of these generation techniques could shift developer focus from writing custom servers to refining mapping rules and repair heuristics.
Load-bearing premise
The 116 servers and 80 OpenAPI contracts examined are representative of the broader MCP ecosystem and the chosen success metrics accurately reflect real-world correctness and usability for LLM agents.
What would settle it
A larger sample of newly published MCP servers showing substantially lower REST reliance than 88.6%, or generated servers that pass the paper's metrics yet fail when actually invoked by agents, would undermine the central claims.
Figures

read the original abstract
The Model Context Protocol (MCP) is emerging as a standard interface through which LLM agents invoke external tools, and a growing ecosystem of MCP servers now mediates access to vendor services. Most of these servers target vendors that already expose REST APIs, yet the relationship between MCP tool interfaces and the underlying API surface has not been empirically characterised. This paper presents the first large-scale study of MCP server construction. We analyse 116 official servers to determine REST reliance and integration strategies (RQ1); examine servers paired with OpenAPI specifications to quantify operation exposure, omission, and mapping patterns (RQ2); evaluate automated generation from 80 real-world OpenAPI contracts (RQ3); and assess specification repair and tool-set transformations to improve correctness and reduce complexity (RQ4). We find that 88.6% of servers are fully or partially REST-backed, with 92% implementing tools as bare API wrappers. MCP servers expose a median of 19% of available operations, following systematic patterns predictable from the specification. Baseline generation succeeds for 76% of sampled tools; automated repair raises this to 94.2%, while filtering and regrouping reduce the median tool count per API by one-third. We release AutoMCP, an end-to-end pipeline integrating specification repair and empirically grounded tool-set transformations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents the first large-scale empirical study of MCP server construction practices. It analyzes 116 official MCP servers to characterize REST reliance and integration patterns (RQ1/RQ2), then evaluates an automated generation pipeline (AutoMCP) on 80 real-world OpenAPI contracts, measuring baseline success, the impact of specification repair, and tool-set transformations for correctness and reduced complexity (RQ3/RQ4). Central claims include 88.6% of servers being fully or partially REST-backed (92% as bare API wrappers), a median 19% operation exposure rate with predictable patterns, baseline generation success of 76% rising to 94.2% after repair, and filtering/regrouping reducing median tool count by one-third.
Significance. If the sampled artifacts prove representative, the quantitative characterization of MCP-REST mappings and the demonstrated effectiveness of the AutoMCP pipeline (with released code) would provide timely, actionable guidance for standardizing tool interfaces in the emerging MCP ecosystem and for automating server generation from existing OpenAPI specifications. The concrete metrics from 116 servers and 80 contracts, together with the end-to-end pipeline, constitute a reproducible empirical contribution that could inform both protocol evolution and practical LLM-agent tooling.
major comments (3)
- [RQ1 data collection] Data collection subsection (RQ1): The paper describes the 116 servers as 'official servers' but provides no explicit sampling frame, registry source, inclusion/exclusion criteria, or stratification details. Without this, the headline statistics (88.6% REST-backed, 92% bare wrappers, median 19% exposure) cannot be confidently generalized beyond the chosen snapshot, directly affecting the external validity of all RQ1/RQ2 claims.
- [RQ3/RQ4 evaluation] Evaluation setup (RQ3/RQ4): The selection process and diversity criteria for the 80 OpenAPI contracts are not reported. This leaves open whether the reported generation success rates (76% baseline to 94.2% post-repair) and tool-count reductions reflect properties of the broader MCP-relevant API population or artifacts of the particular contracts chosen.
- [RQ3 evaluation] Success metric definition (RQ3): The operational definition of 'success' for generated MCP servers (e.g., syntactic validity, semantic correctness, or actual agent invocation outcomes) is not validated against real LLM-agent usage traces. This weakens the interpretation that the repair pipeline raises success from 76% to 94.2% in a practically meaningful sense.
minor comments (2)
- [Abstract] Abstract should briefly state the sampling approach or source registry for the 116 servers and 80 contracts to allow readers to assess representativeness at first reading.
- [Methods] Notation for 'median tool count' and 'operation exposure' should be defined once in a table or early methods paragraph to avoid ambiguity when comparing across RQs.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We agree that greater transparency in data collection and evaluation procedures will strengthen the external validity and interpretability of our results. We will revise the manuscript accordingly and address each major comment below.
read point-by-point responses
-
Referee: [RQ1 data collection] Data collection subsection (RQ1): The paper describes the 116 servers as 'official servers' but provides no explicit sampling frame, registry source, inclusion/exclusion criteria, or stratification details. Without this, the headline statistics (88.6% REST-backed, 92% bare wrappers, median 19% exposure) cannot be confidently generalized beyond the chosen snapshot, directly affecting the external validity of all RQ1/RQ2 claims.
Authors: We agree that explicit documentation of the sampling process is necessary. The 116 servers were obtained from the official MCP server registry and GitHub organization maintained by the MCP community as of June 2024; we included every server explicitly labeled 'official' or contributed by recognized vendors and excluded only those lacking publicly accessible source code or documentation. We will add a dedicated 'Data Collection' subsection (including source, collection date, inclusion/exclusion criteria, and any stratification by domain) to the revised manuscript so that readers can assess generalizability. revision: yes
-
Referee: [RQ3/RQ4 evaluation] Evaluation setup (RQ3/RQ4): The selection process and diversity criteria for the 80 OpenAPI contracts are not reported. This leaves open whether the reported generation success rates (76% baseline to 94.2% post-repair) and tool-count reductions reflect properties of the broader MCP-relevant API population or artifacts of the particular contracts chosen.
Authors: We acknowledge the omission. The 80 contracts were drawn from the public SwaggerHub repository and popular open-source API repositories, deliberately spanning multiple domains (e.g., payments, cloud infrastructure, social platforms) and varying in size and complexity. We will insert a new paragraph in the Evaluation Setup section that reports the sources, selection criteria, and summary statistics on domain coverage and API size to allow readers to judge representativeness. revision: yes
-
Referee: [RQ3 evaluation] Success metric definition (RQ3): The operational definition of 'success' for generated MCP servers (e.g., syntactic validity, semantic correctness, or actual agent invocation outcomes) is not validated against real LLM-agent usage traces. This weakens the interpretation that the repair pipeline raises success from 76% to 94.2% in a practically meaningful sense.
Authors: We define success as syntactic validity under the MCP schema plus successful basic invocation in a controlled test harness; this directly measures whether the generated server is usable by an agent without immediate structural failure. We recognize that end-to-end validation against real LLM-agent traces would provide stronger evidence of practical impact. We will (a) state the precise operational definition in the RQ3 section, (b) add a limitations paragraph acknowledging the absence of trace-based validation, and (c) note that future work could incorporate such traces. These clarifications will prevent over-interpretation while preserving the reported quantitative improvements. revision: partial
Circularity Check
No significant circularity; empirical observations from external artifacts
full rationale
The paper reports direct measurements from 116 official MCP servers and 80 public OpenAPI contracts, with all statistics (REST reliance, wrapper patterns, exposure rates, generation success) obtained via observation and experimental runs on those external specifications. No equations, fitted parameters, self-definitional constructs, or load-bearing self-citations reduce any result to the paper's own inputs by construction. The derivation chain consists of independent data collection and evaluation steps that remain falsifiable against the sampled artifacts.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption MCP is an emerging standard interface through which LLM agents invoke external tools and that most servers target vendors exposing REST APIs.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
AutoMCP is a static code generator that compiles an OpenAPI 2.0 or 3.0 specification into a complete, executable MCP server stub.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 4 Pith papers
-
Five Attacks on x402 Agentic Payment Protocol
Five practical attacks on the x402 agentic payment protocol are demonstrated across authorization, binding, replay protection, and web handling, validated on local chains, Base Sepolia, live endpoints, and three open-...
-
DADL: A Declarative Description Language for Enterprise Tool Libraries in LLM Agent Systems
DADL is a declarative YAML format that lets a single runtime handle many REST API tools for LLM agents, cutting tool advertisement context cost by 142x from 142,000 to 1,000 tokens on a catalog of 1,833 definitions.
-
HarnessAPI: A Skill-First Framework for Unified Streaming APIs and MCP Tools
HarnessAPI derives streaming HTTP endpoints, OpenAPI UI, and MCP tools from a single handler.py plus Pydantic schemas, cutting framework boilerplate by 74%.
-
Making OpenAPI Documentation Agent-Ready: Detecting Documentation and REST Smells with a Multi-Agent LLM System
Hermes uses multi-agent LLMs to detect 2450 documentation and REST smells across 600 OpenAPI endpoints, demonstrating that structurally valid microservice APIs are often not semantically ready for agent consumption.
Reference graph
Works this paper leans on
-
[1]
React: Synergizing reasoning and acting in language models,
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. R. Narasimhan, and Y. Cao, “React: Synergizing reasoning and acting in language models, ” inThe Eleventh International Conference on Learning Representations, 2023. [Online]. Available: https://openreview.net/forum?id=WE_vluYUL-X
work page 2023
-
[2]
Toolformer: language models can teach themselves to use tools,
T. Schick, J. Dwivedi-Yu, R. Dessí, R. Raileanu, M. Lomeli, E. Hambro, L. Zettle- moyer, N. Cancedda, and T. Scialom, “Toolformer: language models can teach themselves to use tools, ” inProceedings of the 37th International Conference on Neural Information Processing Systems, ser. NIPS ’23. Red Hook, NY, USA: Curran Associates Inc., 2023
work page 2023
-
[3]
Restgpt: Connecting large language models with real-world applications via restful apis,
Y. Song, W. Xiong, D. Zhu, C. Li, K. Wang, Y. Tian, and S. Li, “Restgpt: Connecting large language models with real-world applications via restful apis, ” 06 2023
work page 2023
-
[4]
Gorilla: Large Language Model Connected with Massive APIs
S. Patil, T. Zhang, Y. Wuet al., “Gorilla: Large language model connected with massive apis, ”arXiv preprint arXiv:2305.15334, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Api-bank: A benchmark for tool-augmented llms with api usage,
C. Li, Y. Cao, X. Chen, W. Huang, D. Zhang, and C. Zhou, “Api-bank: A benchmark for tool-augmented llms with api usage, ” inProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2023, pp. 3280–3293
work page 2023
-
[6]
ToolFactory: Automating tool generation by leveraging LLM to understand REST API documentations
Z. Li, C. Li, X. Zhang, Y. Ma, Z. Xu, C. Tu, and Z. Liu, “Toolfactory: Automating tool generation by leveraging llm to understand rest api documentations, ”arXiv preprint arXiv:2501.16945, 2024. [Online]. Available: https://arxiv.org/abs/2501.16945
-
[7]
An empirical study on challenges for llm application developers,
X. Chen, C. Gao, C. Chen, G. Zhang, and Y. Liu, “An empirical study on challenges for llm application developers, ”ACM Trans. Softw. Eng. Methodol., Jan. 2025, just Accepted. [Online]. Available: https://doi.org/10.1145/3715007
-
[8]
Anthropic, “Model context protocol (mcp), ” 2025, [Online]. [Online]. Available: https://docs.anthropic.com/claude/docs/model-context-protocol
work page 2025
-
[9]
Docker mcp catalog and toolkit,
Docker Inc., “Docker mcp catalog and toolkit, ” https://docs.docker.com/ai/mcp- catalog-and-toolkit/catalog/, 2025, accessed July 2025
work page 2025
-
[10]
Mcp.so: Community mcp server directory,
MCP.so Community, “Mcp.so: Community mcp server directory, ” https://mcp.so/, 2025, accessed July 2025
work page 2025
-
[11]
Model Context Protocol (MCP): Landscape, Security Threats, and Future Research Directions
X. Hou, Y. Zhao, S. Wang, and H. Wang, “Model context protocol (mcp): Landscape, security threats, and future research directions, ”arXiv preprint arXiv:2503.23278, 2025. [Online]. Available: https://arxiv.org/abs/2503.23278
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
A. Authors, “Automcp-executable, ” [Online]. [Online]. Available: https: //anonymous.4open.science/r/AutoMCP-executable-274E/README.md
-
[13]
Function calling and other api updates,
OpenAI, “Function calling and other api updates, ” 2023, [Online]. [Online]. Available: https://openai.com/blog/function-calling-and-other-api-updates
work page 2023
-
[14]
Langchain: Building applications with llms through composability,
H. Chase, “Langchain: Building applications with llms through composability, ” 2023, [Online]. [Online]. Available: https://docs.langchain.com/
work page 2023
-
[15]
Auto-gpt: An autonomous gpt-4 experiment,
S. Gravitas, “Auto-gpt: An autonomous gpt-4 experiment, ” 2023, [Online]. [Online]. Available: https://github.com/Torantulino/Auto-GPT
work page 2023
-
[16]
Tool documentation enabl es zero-shot tool-usage with large language models
C.-Y. Hsieh, S.-A. Chen, C.-L. Li, Y. Fujii, A. Ratner, C.-Y. Lee, R. Krishna, and T. Pfister, “Tool documentation enables zero-shot tool-usage with large language models, ” 2023. [Online]. Available: https://arxiv.org/abs/2308.00675
-
[17]
A2a: A new era of agent interoperability,
G. Developers, “A2a: A new era of agent interoperability, ” https://developers. googleblog.com/en/a2a-a-new-era-of-agent-interoperability/, 2024, accessed: 2025-04-27
work page 2024
-
[18]
Postman Inc., “Mcp generator, ” https://www.postman.com/explore/mcp- generator, 2025, accessed July 2025
work page 2025
-
[19]
T. O. Initiative, “Openapi specification v3.1.0, ” 2023, [Online]. [Online]. Available: https://spec.openapis.org/oas/v3.1.0
work page 2023
-
[20]
A study of api versioning in the openapi ecosystem,
S. Serbout and C. Pautasso, “A study of api versioning in the openapi ecosystem, ” inProceedings of the 2023 IEEE International Conference on Software Architecture (ICSA), 2023, pp. 137–148
work page 2023
-
[21]
Should i deprecate this api operation? an empirical analysis of api evolution,
A. D. Lauro, T. G. Dietrich, and M. L. Bernardi, “Should i deprecate this api operation? an empirical analysis of api evolution, ” inProceedings of the 2022 IEEE International Conference on Web Services (ICWS), 2022, pp. 188–195
work page 2022
-
[22]
Autooas: A framework for automatically enhancing openapi specifications,
D. Lercher, D. Leoni, and M. Gusev, “Autooas: A framework for automatically enhancing openapi specifications, ” inProceedings of the 2024 International Con- ference on Software Engineering (ICSE), 2024
work page 2024
-
[23]
Mining security documenta- tion practices in openapi descriptions,
D. C. M. noz Hurtado, S. Serbout, and C. Pautasso, “Mining security documenta- tion practices in openapi descriptions, ” inProceedings of the 22nd IEEE Interna- tional Conference on Software Architecture (ICSA), 2025
work page 2025
-
[24]
Mining preconditions of apis in large-scale code corpus,
H. Nguyen, R. Dyer, N. Tien, and H. Rajan, “Mining preconditions of apis in large-scale code corpus, ” 11 2014, pp. 166–177
work page 2014
-
[25]
Understanding the impact of apis behavioral breaking changes on client applications,
D. Jayasuriya, V. Terragni, J. Dietrich, and K. Blincoe, “Understanding the impact of apis behavioral breaking changes on client applications, ”Proceedings of the ACM on Software Engineering, vol. 1, pp. 1238–1261, 07 2024
work page 2024
-
[26]
Leveraging large language models to improve rest api testing,
M. Kim, T. Stennett, D. Shah, S. Sinha, and A. Orso, “Leveraging large language models to improve rest api testing, ” in2024 IEEE/ACM 46th International Confer- ence on Software Engineering: New Ideas and Emerging Results (ICSE-NIER), 2024, pp. 37–41
work page 2024
-
[27]
ToolLLM: Facilitating large language models to master 16000+ real-world APIs,
Y. Qin, S. Liang, Y. Ye, K. Zhu, L. Yan, Y. Lu, Y. Lin, X. Cong, X. Tang, B. Qian, S. Zhao, L. Hong, R. Tian, R. Xie, J. Zhou, M. Gerstein, dahai li, Z. Liu, and M. Sun, “ToolLLM: Facilitating large language models to master 16000+ real-world APIs, ” inThe Twelfth International Conference on Learning Representations, 2024. [Online]. Available: https://ope...
work page 2024
-
[28]
E. Anuff. (2025, May) Is model context protocol the new api? The New Stack. Accessed 18 June 2025. [Online]. Available: https://thenewstack.io/is-model- context-protocol-the-new-api/
work page 2025
-
[29]
Team activities measurement method for open source software development using the gini coefficient,
A. Masuda, T. Matsuodani, and K. Tsuda, “Team activities measurement method for open source software development using the gini coefficient, ” in2019 IEEE International Conference on Software Testing, Verification and Validation Workshops (ICSTW), 2019, pp. 140–147
work page 2019
-
[30]
The spearman correlation formula,
C. Wissler, “The spearman correlation formula, ”Science, vol. 22, no. 558, pp. 309–311, 1905
work page 1905
-
[31]
Apis.guru: The wikipedia for web apis,
APIs.guru, “Apis.guru: The wikipedia for web apis, ” https://apis.guru/, 2024, accessed: 2025-04-27
work page 2024
-
[32]
Konfig SDKs OpenAPI Examples Repository,
Konfig, “Konfig SDKs OpenAPI Examples Repository, ” https://github.com/konfig- sdks/openapi-examples, 2025, gitHub repository•accessed 18 april 2025
work page 2025
-
[33]
Restler: Stateful rest api fuzzing,
V. Atlidakis, P. Godefroid, and M. Polishchuk, “Restler: Stateful rest api fuzzing, ” inProceedings of the 41st International Conference on Software Engineering (ICSE), 2019
work page 2019
-
[34]
Restats: A test coverage tool for restful apis,
D. Corradini, A. Zampieri, M. Pasqua, and M. Ceccato, “Restats: A test coverage tool for restful apis, ” in2021 IEEE International Conference on Software Maintenance and Evolution (ICSME), 2021, pp. 300–310
work page 2021
- [35]
-
[36]
Kat: Dependency- aware automated api testing with large language models,
T. Le, T. Tran, D. Cao, V. Le, T. N. Nguyen, and V. Nguyen, “Kat: Dependency- aware automated api testing with large language models, ” in2024 IEEE Conference on Software Testing, Verification and Validation (ICST). IEEE, 2024, pp. 82–92
work page 2024
-
[37]
A multi-agent approach for rest api test- ing with semantic graphs and llm-driven inputs,
M. Kim, T. Stennett, S. Sinha, and A. Orso, “A multi-agent approach for rest api test- ing with semantic graphs and llm-driven inputs, ”arXiv preprint arXiv:2411.07098, 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.