0
Nine LLM audits on prompts found 51 defects and converged to zero
Expanded-scope rounds in a 7150-line multi-agent system caught issues single-file checks missed.
 full image
full image
abstract click to expand
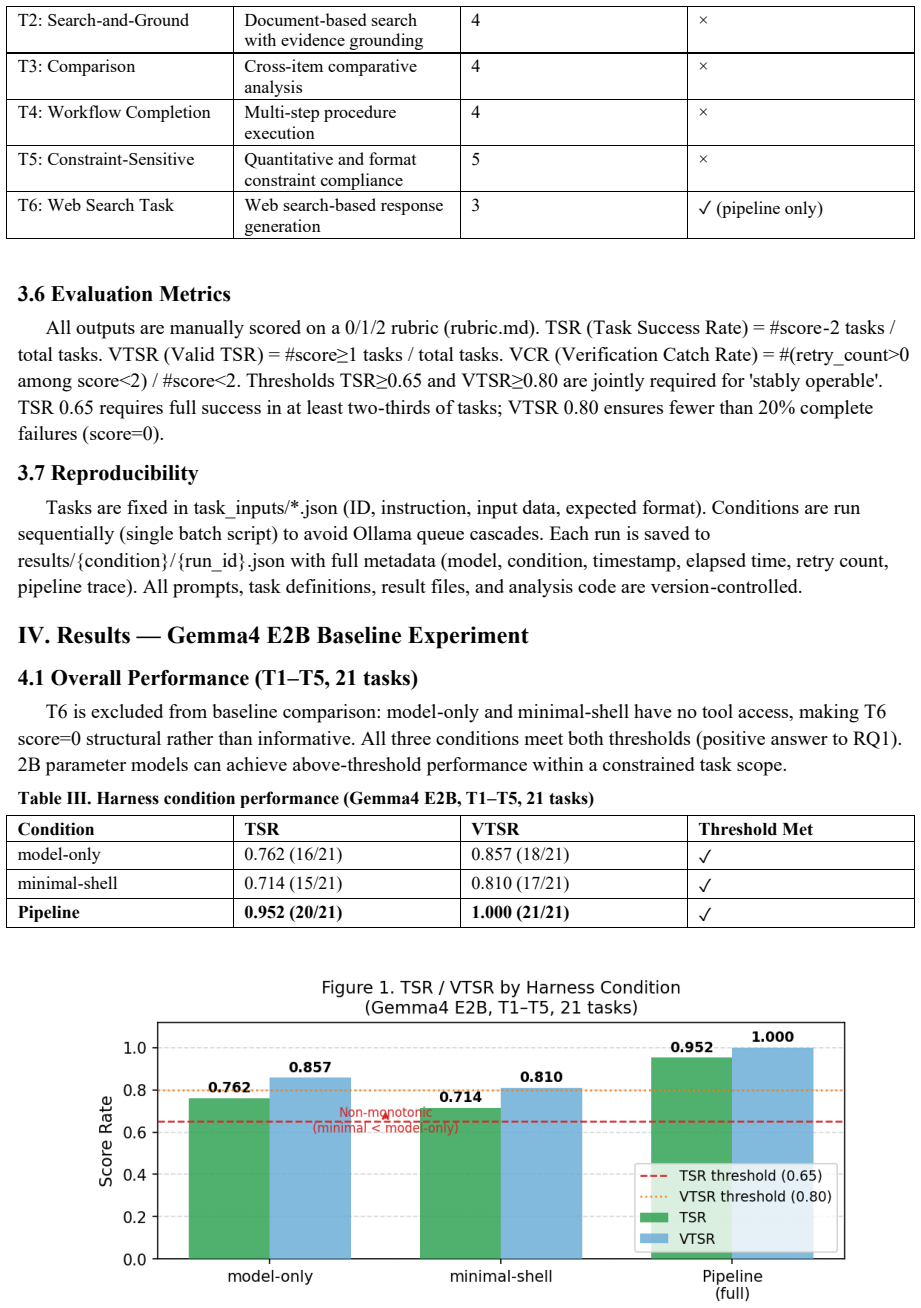
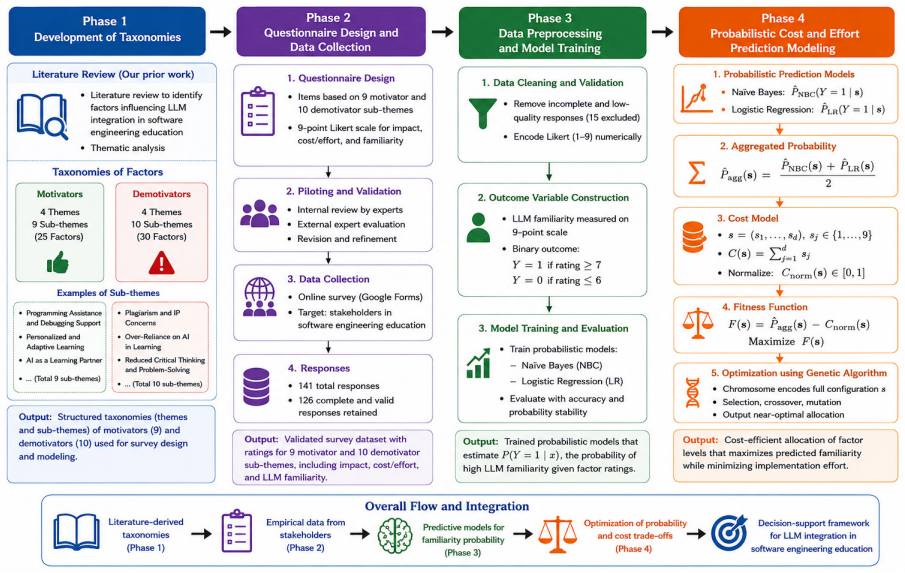
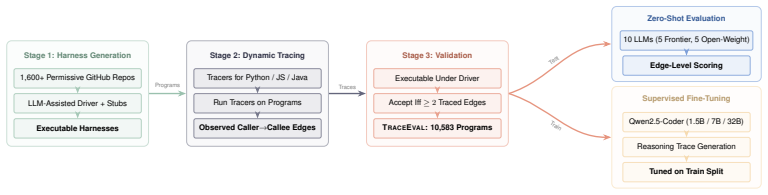
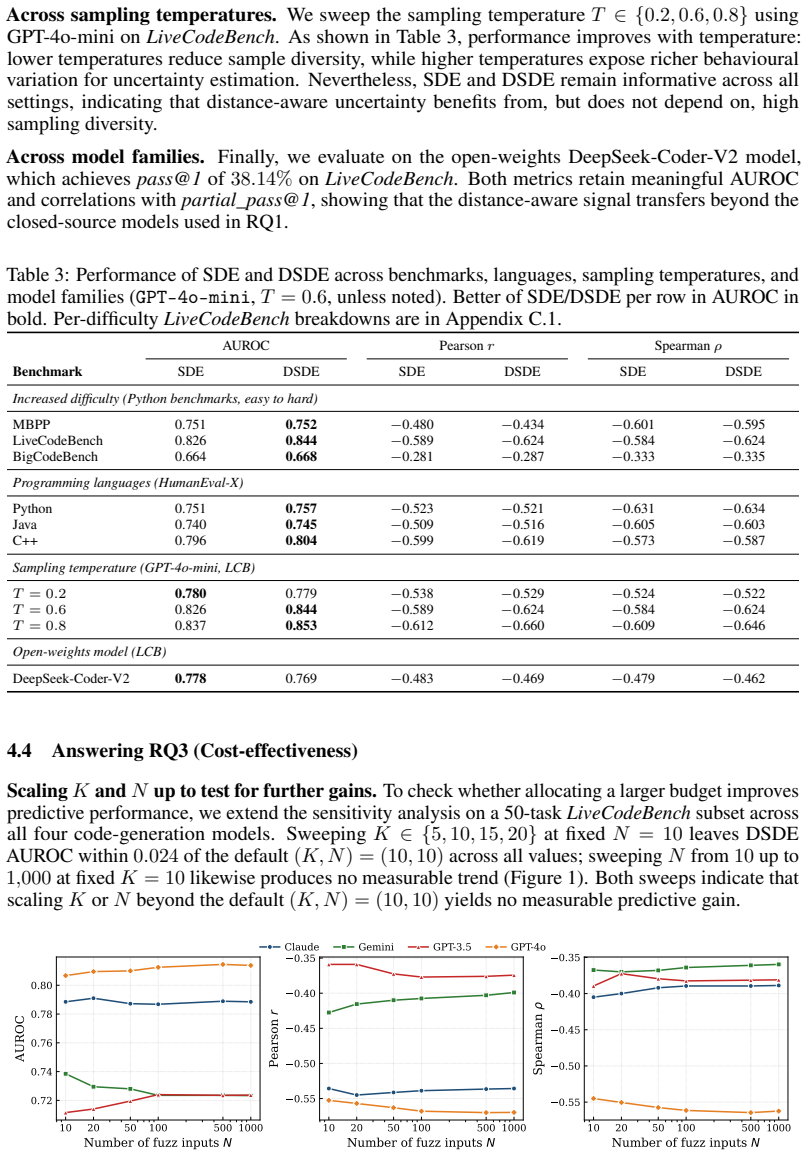
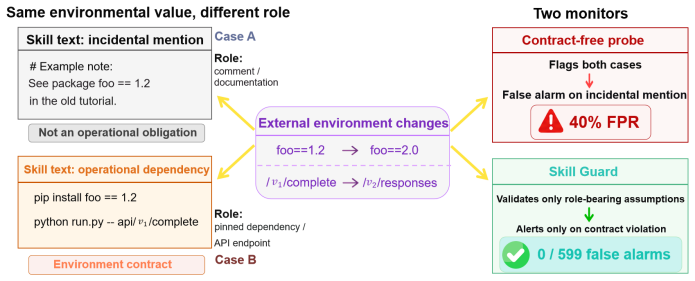
Prompt specifications for multi-agent large language model (LLM) systems carry data contracts and integration logic across many interdependent files but are rarely subjected to structured-inspection rigor. This paper reports a single-system empirical case study of iterative, agent-driven auditing applied to AEGIS (Autonomous Engineering Governance and Intelligence System), a production seven-lane orchestration pipeline whose prompt-specification surface comprises approximately 7150 lines: 6907 across seven lane PROMPT.md files and a 245-line shared Ticket Contract. Nine sequential audit rounds, executed by Claude sub-agents using a checklist-driven walkthrough adapted from Weinberg and Freedman, surfaced 51 prompt-specification consistency defects, distinct from the 51 STRIDE-categorized adversarial code findings reported in the companion preprint. Per-round counts were 15, 8, 12, 2, 8, 1, 4, 1, and 0. We report a seven-category post-hoc defect taxonomy with explicit coding rules, observed non-monotonic convergence consistent with cascading edits and audit-scope expansion, and an audit protocol distilled from the study, with the final locked checklist released as a reproducibility appendix. Single-file review missed defect classes that were surfaced only by later expanded-scope rounds in this system. The same LLM family authored and audited the specifications; replication with dissimilar models and human reviewers is required before generalization.