A Survey on 3D Gaussian Splatting Applications: Segmentation, Editing, and Generation
Pith reviewed 2026-05-18 22:35 UTC · model grok-4.3
The pith
3D Gaussian Splatting applications are organized into segmentation, editing, and generation tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
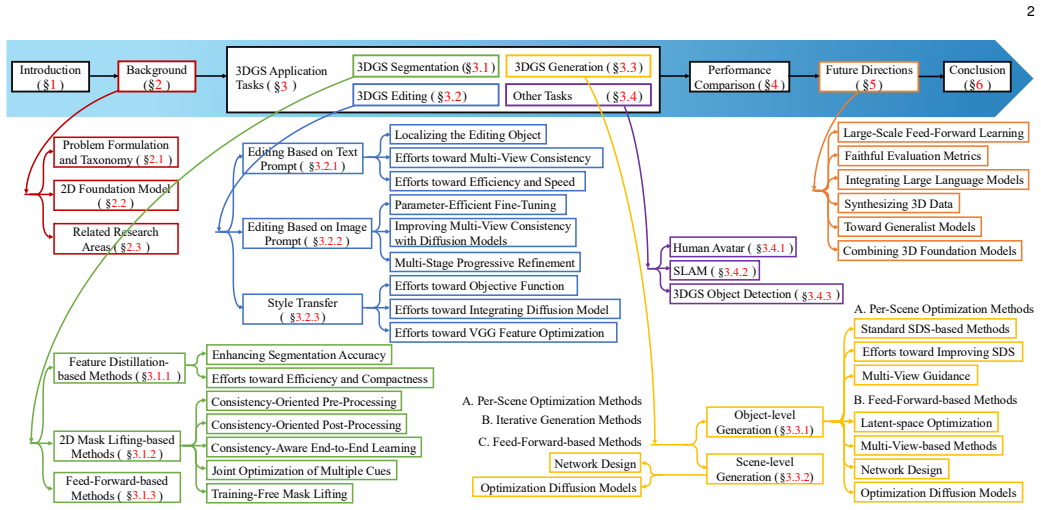
The survey establishes that the explicit and compact form of 3D Gaussian Splatting supports a range of tasks needing geometric and semantic understanding, and that these tasks can be grouped into segmentation, editing, and generation as foundational categories, with methods drawing on 2D foundation models and prior NeRF work to reveal common design principles.
What carries the argument
The three-category taxonomy of segmentation, editing, and generation that structures the review and brings out shared supervision and learning patterns.
If this is right
- Common supervision strategies and learning paradigms become visible across task types.
- Datasets and evaluation protocols enable direct comparisons of methods on public benchmarks.
- Design principles identified in each category can guide development of new techniques.
- The maintained repository of papers and code supports tracking further progress.
Where Pith is reading between the lines
- The same taxonomy approach could be used to organize applications of other explicit 3D representations.
- New application types may appear that require expanding or revising the current categories.
- Benchmark comparisons could point to performance differences that suggest specific future improvements.
Load-bearing premise
The chosen split of applications into segmentation, editing, and generation plus related functions accurately reflects the main structure of the research area.
What would settle it
Publication of many 3D Gaussian Splatting application papers that cannot be placed in segmentation, editing, or generation would show the categorization misses major parts of the field.
Figures


read the original abstract
In the context of novel view synthesis, 3D Gaussian Splatting (3DGS) has recently emerged as an efficient and competitive counterpart to Neural Radiance Field (NeRF), enabling high-fidelity photorealistic rendering in real time. Beyond novel view synthesis, the explicit and compact nature of 3DGS enables a wide range of downstream applications that require geometric and semantic understanding. This survey provides a comprehensive overview of recent progress in 3DGS applications. It first reviews the reconstruction preliminaries of 3DGS, followed by the problem formulation, 2D foundation models, and related NeRF-based research areas that inform downstream 3DGS applications. We then categorize 3DGS applications into three foundational tasks: segmentation, editing, and generation, alongside additional functional applications built upon or tightly coupled with these foundational capabilities. For each, we summarize representative methods, supervision strategies, and learning paradigms, highlighting shared design principles and emerging trends. Commonly used datasets and evaluation protocols are also summarized, along with comparative analyses of recent methods across public benchmarks. To support ongoing research and development, a continually updated repository of papers, code, and resources is maintained at https://github.com/heshuting555/Awesome-3DGS-Applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This survey reviews 3D Gaussian Splatting (3DGS) applications beyond novel view synthesis. It first covers reconstruction preliminaries, problem formulations, 2D foundation models, and related NeRF work, then organizes applications into three foundational tasks—segmentation, editing, and generation—plus additional functional applications. For each category the paper summarizes representative methods, supervision strategies, and learning paradigms, highlights shared principles and trends, and provides datasets, benchmarks, and comparative analyses while maintaining a public GitHub repository of resources.
Significance. A well-executed survey in this rapidly growing area would help researchers navigate the literature on 3DGS downstream tasks. The explicit maintenance of a continually updated repository (https://github.com/heshuting555/Awesome-3DGS-Applications) is a concrete strength that aids reproducibility and community use. If the taxonomy is justified and coverage is representative, the work would usefully synthesize supervision and paradigm trends across the three core tasks.
major comments (1)
- [Categorization section] Categorization section (following the preliminaries review): the central claim that the tripartite taxonomy plus functional applications delivers a comprehensive overview rests on the unstated assumption that the chosen framing accurately reflects field structure. The paper should add an explicit discussion of boundary porosity (e.g., editing methods that presuppose segmentation) and state inclusion/exclusion criteria for surveyed works to address possible omissions in areas such as physics-aware simulation or medical volumetric analysis.
minor comments (2)
- [Abstract] Abstract: the phrase 'additional functional applications built upon or tightly coupled with these foundational capabilities' is vague; a short parenthetical list of examples would improve clarity.
- [Introduction / Resources] The GitHub link is given but no statement is made about how frequently it is updated or what curation process is used; adding one sentence on maintenance policy would strengthen the reproducibility claim.
Simulated Author's Rebuttal
We thank the referee for the positive assessment and recommendation for minor revision. We address the single major comment below and will incorporate the suggested clarifications to improve transparency of the taxonomy.
read point-by-point responses
-
Referee: [Categorization section] Categorization section (following the preliminaries review): the central claim that the tripartite taxonomy plus functional applications delivers a comprehensive overview rests on the unstated assumption that the chosen framing accurately reflects field structure. The paper should add an explicit discussion of boundary porosity (e.g., editing methods that presuppose segmentation) and state inclusion/exclusion criteria for surveyed works to address possible omissions in areas such as physics-aware simulation or medical volumetric analysis.
Authors: We agree that an explicit justification of the taxonomy and its boundaries will strengthen the manuscript. In the revised version we will add a short dedicated paragraph (or subsection) right after the preliminaries that (i) states the rationale for the tripartite core (segmentation, editing, generation) plus functional applications, namely that these categories correspond to the dominant research threads observed in the literature at the time of writing; (ii) discusses boundary porosity with concrete examples, such as editing pipelines that first invoke segmentation to obtain semantic Gaussians or generation methods that condition on previously edited or segmented representations; and (iii) articulates inclusion/exclusion criteria: we survey methods that directly extend or apply 3DGS to the listed tasks in general scenes, drawing from peer-reviewed and arXiv papers up to our literature cutoff date. We will note that physics-aware simulation and medical volumetric analysis are emerging but still sparsely represented within the 3DGS literature; they are mentioned briefly under functional applications where relevant and flagged as promising directions for future dedicated surveys rather than being omitted by oversight. These additions preserve the existing structure while making the framing assumptions transparent. revision: yes
Circularity Check
No circularity: survey organizes external literature without derivations or self-referential reductions
full rationale
This paper is a literature survey that reviews reconstruction preliminaries, categorizes 3DGS applications into segmentation/editing/generation plus functional tasks, and summarizes methods from cited external works. No original equations, parameter fitting, or derivation chain exists that could reduce to the paper's own inputs by construction. The taxonomy is an organizational framework drawn from the field rather than a fitted or self-defined result, and all referenced supervision strategies and benchmarks originate from independent prior publications. Self-citations, if present, are not load-bearing for any central claim.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 3 Pith papers
-
3DEditSafe: Defending 3D Editing Pipelines from Unsafe Generation
3DEditSafe adds generation-stage guidance, 3D safety regularization, semantic projection, residue suppression, and mask-aware preservation to reduce unsafe semantic alignment in 3D editing while noting a safety-qualit...
-
NG-GS: NeRF-Guided 3D Gaussian Splatting Segmentation
NG-GS uses NeRF guidance and RBF interpolation on 3DGS to produce smoother, higher-quality object segmentation boundaries.
-
GS4City: Hierarchical Semantic Gaussian Splatting via City-Model Priors
GS4City derives geometry-grounded semantic masks from LoD3 CityGML models via raycasting and fuses them with 2D foundation model outputs to supervise identity encodings on Gaussians, improving coarse and fine semantic...
Reference graph
Works this paper leans on
-
[1]
3d gaussian splatting for real-time radiance field rendering
B. Kerbl, G. Kopanas, T. Leimkühler, and G. Drettakis, “3d gaussian splatting for real-time radiance field rendering.” ACM TOG, 2023
work page 2023
-
[2]
Nerf: Representing scenes as neural radiance fields for view synthesis,
B. Mildenhall, P. P. Srinivasan, M. Tancik, J. T. Barron, R. Ramamoor- thi, and R. Ng, “Nerf: Representing scenes as neural radiance fields for view synthesis,” in ECCV, 2020
work page 2020
-
[3]
Scaffold- gs: Structured 3d gaussians for view-adaptive rendering,
T. Lu, M. Yu, L. Xu, Y . Xiangli, L. Wang, D. Lin, and B. Dai, “Scaffold- gs: Structured 3d gaussians for view-adaptive rendering,” in CVPR, 2024
work page 2024
-
[4]
Mvsplat: Efficient 3d gaussian splatting from sparse multi-view images,
Y . Chen, H. Xu, C. Zheng, B. Zhuang, M. Pollefeys, A. Geiger, T.-J. Cham, and J. Cai, “Mvsplat: Efficient 3d gaussian splatting from sparse multi-view images,” in ECCV, 2024
work page 2024
-
[5]
Gs-slam: Dense visual slam with 3d gaussian splatting,
C. Yan, D. Qu, D. Xu, B. Zhao, Z. Wang, D. Wang, and X. Li, “Gs-slam: Dense visual slam with 3d gaussian splatting,” in CVPR, 2024
work page 2024
-
[6]
Gaussianavatars: Photorealistic head avatars with rigged 3d gaussians,
S. Qian, T. Kirschstein, L. Schoneveld, D. Davoli, S. Giebenhain, and M. Nießner, “Gaussianavatars: Photorealistic head avatars with rigged 3d gaussians,” in CVPR, 2024
work page 2024
-
[7]
ReferSplat: Referring segmentation in 3d gaussian splatting,
S. He, G. Jie, C. Wang, Y . Zhou, S. Hu, G. Li, and H. Ding, “ReferSplat: Referring segmentation in 3d gaussian splatting,” in ICML, 2025
work page 2025
-
[8]
Gaussianeditor: Swift and controllable 3d editing with gaussian splatting,
Y . Chen, Z. Chen, C. Zhang, F. Wang, X. Yang, Y . Wang, Z. Cai, L. Yang, H. Liu, and G. Lin, “Gaussianeditor: Swift and controllable 3d editing with gaussian splatting,” in CVPR, 2024
work page 2024
-
[9]
Dreamgaussian: Generative gaussian splatting for efficient 3d content creation,
J. Tang, J. Ren, H. Zhou, Z. Liu, and G. Zeng, “Dreamgaussian: Generative gaussian splatting for efficient 3d content creation,” inICLR, 2024
work page 2024
-
[10]
A Survey on 3D Gaussian Splatting
G. Chen and W. Wang, “A survey on 3d gaussian splatting,” arXiv preprint arXiv:2401.03890, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
3d gaussian splatting in robotics: A survey
S. Zhu, G. Wang, X. Kong, D. Kong, and H. Wang, “3d gaussian splatting in robotics: A survey,”arXiv preprint arXiv:2410.12262, 2024
-
[12]
3dgs. zip: A survey on 3d gaussian splatting compression methods,
M. T. Bagdasarian, P. Knoll, Y .-H. Li, F. Barthel, A. Hilsmann, P. Eisert, and W. Morgenstern, “3dgs. zip: A survey on 3d gaussian splatting compression methods,” arXiv preprint arXiv:2407.09510, 2024
-
[13]
Compression in 3d gaussian splatting: A survey of methods, trends, and future directions,
M. S. Ali, C. Zhang, M. Cagnazzo, G. Valenzise, E. Tartaglione, and S.-H. Bae, “Compression in 3d gaussian splatting: A survey of methods, trends, and future directions,” arXiv preprint arXiv:2502.19457, 2025
-
[14]
Recent advances in 3d gaussian splatting,
T. Wu, Y .-J. Yuan, L.-X. Zhang, J. Yang, Y .-P. Cao, L.-Q. Yan, and L. Gao, “Recent advances in 3d gaussian splatting,” Computational Visual Media, 2024
work page 2024
-
[15]
3d gaussian splatting as new era: A survey,
B. Fei, J. Xu, R. Zhang, Q. Zhou, W. Yang, and Y . He, “3d gaussian splatting as new era: A survey,” IEEE TVCG, 2024
work page 2024
-
[16]
3d gaussian splatting: Survey, technologies, challenges, and opportunities,
Y . Bao, T. Ding, J. Huo, Y . Liu, Y . Li, W. Li, Y . Gao, and J. Luo, “3d gaussian splatting: Survey, technologies, challenges, and opportunities,” IEEE TCSVT, 2025
work page 2025
-
[17]
M.-B. Jurca, R. Royen, I. Giosan, and A. Munteanu, “Rt-gs2: Real-time generalizable semantic segmentation for 3d gaussian representations of radiance fields,” BMVC, 2024
work page 2024
-
[18]
Omniseg3d: Omniversal 3d segmentation via hierarchical contrastive learning,
H. Ying, Y . Yin, J. Zhang, F. Wang, T. Yu, R. Huang, and L. Fang, “Omniseg3d: Omniversal 3d segmentation via hierarchical contrastive learning,” in CVPR, 2024
work page 2024
-
[19]
Gaga: Group any gaussians via 3d-aware memory bank,
W. Lyu, X. Li, A. Kundu, Y .-H. Tsai, and M.-H. Yang, “Gaga: Group any gaussians via 3d-aware memory bank,” arXiv preprint arXiv:2404.07977, 2024
work page internal anchor Pith review arXiv 2024
-
[20]
Rethinking end-to-end 2d to 3d scene segmentation in gaussian splatting,
R. Zhu, S. Qiu, Z. Liu, K.-H. Hui, Q. Wu, P.-A. Heng, and C.-W. Fu, “Rethinking end-to-end 2d to 3d scene segmentation in gaussian splatting,” in CVPR, 2025
work page 2025
-
[21]
W. Hu, W. Chai, S. Hao, X. Cui, X. Wen, J.-N. Hwang, and G. Wang, “Pointmap association and piecewise-plane constraint for consistent and compact 3d gaussian segmentation field,” arXiv, 2025
work page 2025
-
[22]
Gaussian grouping: Segment and edit anything in 3d scenes,
M. Ye, M. Danelljan, F. Yu, and L. Ke, “Gaussian grouping: Segment and edit anything in 3d scenes,” in ECCV, 2024
work page 2024
-
[23]
SAGD: Boundary-enhanced segment anything in 3D gaussian via gaussian decomposition,
X. Hu, Y . Wang, L. Fan, J. Fan, J. Peng, Z. Lei, Q. Li, and Z. Zhang, “Sagd: Boundary-enhanced segment anything in 3d gaussian via gaus- sian decomposition,” arXiv preprint arXiv:2401.17857, 2024
-
[24]
Click-gaussian: Interactive segmentation to any 3d gaussians,
S. Choi, H. Song, J. Kim, T. Kim, and H. Do, “Click-gaussian: Interactive segmentation to any 3d gaussians,” in ECCV, 2024
work page 2024
-
[25]
isegman: Interactive segment-and-manipulate 3d gaussians,
Y . Zhao, W. Xu, R. Zheng, P. Qiao, C. Liu, and J. Chen, “isegman: Interactive segment-and-manipulate 3d gaussians,” in CVPR, 2025
work page 2025
-
[26]
Langsplat: 3d language gaussian splatting,
M. Qin, W. Li, J. Zhou, H. Wang, and H. Pfister, “Langsplat: 3d language gaussian splatting,” in CVPR, 2024
work page 2024
-
[27]
Feature 3dgs: Supercharging 3d gaussian splatting to enable distilled feature fields,
S. Zhou, H. Chang, S. Jiang, Z. Fan, Z. Zhu, D. Xu, P. Chari, S. You, Z. Wang, and A. Kadambi, “Feature 3dgs: Supercharging 3d gaussian splatting to enable distilled feature fields,” in CVPR, 2024
work page 2024
-
[28]
3d vision-language gaussian splatting,
Q. Peng, B. Planche, Z. Gao, M. Zheng, A. Choudhuri, T. Chen, C. Chen, and Z. Wu, “3d vision-language gaussian splatting,” ICLR, 2025
work page 2025
-
[29]
Gaussiancut: Interactive segmentation via graph cut for 3d gaussian splatting,
U. Jain, A. Mirzaei, and I. Gilitschenski, “Gaussiancut: Interactive segmentation via graph cut for 3d gaussian splatting,” inNeurIPS, 2024
work page 2024
-
[30]
J. Cen, J. Fang, C. Yang, L. Xie, X. Zhang, W. Shen, and Q. Tian, “Segment any 3d gaussians,” in AAAI, 2025
work page 2025
-
[31]
H. Li, Y . Wu, J. Meng, Q. Gao, Z. Zhang, R. Wang, and J. Zhang, “Instancegaussian: Appearance-semantic joint gaussian representation for 3d instance-level perception,” CVPR, 2024
work page 2024
-
[32]
Opengaussian: Towards point-level 3d gaussian-based open vocabulary understanding,
Y . Wu, J. Meng, H. Li, C. Wu, Y . Shi, X. Cheng, C. Zhao, H. Feng, E. Ding, J. Wang et al. , “Opengaussian: Towards point-level 3d gaussian-based open vocabulary understanding,” in NeurIPS, 2024
work page 2024
-
[33]
Tip-editor: An accurate 3d editor following both text-prompts and image-prompts,
J. Zhuang, D. Kang, Y .-P. Cao, G. Li, L. Lin, and Y . Shan, “Tip-editor: An accurate 3d editor following both text-prompts and image-prompts,” ACM TOG, 2024
work page 2024
-
[34]
View- consistent 3d editing with gaussian splatting,
Y . Wang, X. Yi, Z. Wu, N. Zhao, L. Chen, and H. Zhang, “View- consistent 3d editing with gaussian splatting,” in ECCV, 2024
work page 2024
-
[35]
Gaussianeditor: Editing 3d gaussians delicately with text instructions,
J. Wang, J. Fang, X. Zhang, L. Xie, and Q. Tian, “Gaussianeditor: Editing 3d gaussians delicately with text instructions,” in CVPR, 2024
work page 2024
-
[36]
J. Kim, S. Lee, J. Shin, J. Choi, and H. Shim, “Dreamcatalyst: Fast and high-quality 3d editing via controlling editability and identity preservation,” in ICLR, 2025
work page 2025
-
[37]
Lgm: Large multi-view gaussian model for high-resolution 3d content creation,
J. Tang, Z. Chen, X. Chen, T. Wang, G. Zeng, and Z. Liu, “Lgm: Large multi-view gaussian model for high-resolution 3d content creation,” in ECCV, 2024
work page 2024
-
[38]
Grm: Large gaussian reconstruction model for efficient 3d reconstruction and generation,
Y . Xu, Z. Shi, W. Yifan, H. Chen, C. Yang, S. Peng, Y . Shen, and G. Wetzstein, “Grm: Large gaussian reconstruction model for efficient 3d reconstruction and generation,” in ECCV, 2024
work page 2024
-
[39]
Gs-lrm: Large reconstruction model for 3d gaussian splatting,
K. Zhang, S. Bi, H. Tan, Y . Xiangli, N. Zhao, K. Sunkavalli, and Z. Xu, “Gs-lrm: Large reconstruction model for 3d gaussian splatting,” in ECCV, 2024
work page 2024
-
[40]
Gaussiandreamer: Fast generation from text to 3d gaussians by bridging 2d and 3d diffusion models,
T. Yi, J. Fang, J. Wang, G. Wu, L. Xie, X. Zhang, W. Liu, Q. Tian, and X. Wang, “Gaussiandreamer: Fast generation from text to 3d gaussians by bridging 2d and 3d diffusion models,” in CVPR, 2024
work page 2024
-
[41]
Luciddreamer: Towards high-fidelity text-to-3d generation via interval score matching,
Y . Liang, X. Yang, J. Lin, H. Li, X. Xu, and Y . Chen, “Luciddreamer: Towards high-fidelity text-to-3d generation via interval score matching,” in CVPR, 2024
work page 2024
-
[42]
Text2room: Extracting textured 3d meshes from 2d text-to-image models,
L. Höllein, A. Cao, A. Owens, J. Johnson, and M. Nießner, “Text2room: Extracting textured 3d meshes from 2d text-to-image models,” inICCV, 2023
work page 2023
-
[43]
Dreamscene: 3d gaussian-based text-to-3d scene generation via formation pattern sampling,
H. Li, H. Shi, W. Zhang, W. Wu, Y . Liao, L. Wang, L.-h. Lee, and P. Y . Zhou, “Dreamscene: 3d gaussian-based text-to-3d scene generation via formation pattern sampling,” in ECCV, 2024
work page 2024
-
[44]
Dreamscene360: Unconstrained text-to-3d scene generation with panoramic gaussian splatting,
S. Zhou, Z. Fan, D. Xu, H. Chang, P. Chari, T. Bharadwaj, S. You, Z. Wang, and A. Kadambi, “Dreamscene360: Unconstrained text-to-3d scene generation with panoramic gaussian splatting,” in ECCV, 2024
work page 2024
-
[45]
Emerging properties in self-supervised vision transformers,
M. Caron, H. Touvron, I. Misra, H. Jégou, J. Mairal, P. Bojanowski, and A. Joulin, “Emerging properties in self-supervised vision transformers,” in ICCV, 2021
work page 2021
-
[46]
Dinov2: Learning robust visual features without supervision,
M. Oquab, T. Darcet, T. Moutakanni, H. V o, M. Szafraniec, V . Khalidov, P. Fernandez, D. Haziza, F. Massa, A. El-Nouby et al. , “Dinov2: Learning robust visual features without supervision,” TMLR, 2024
work page 2024
-
[47]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark et al., “Learning transferable visual models from natural language supervision,” in ICML, 2021
work page 2021
-
[48]
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y . Loet al., “Segment anything,” in ICCV, 2023
work page 2023
-
[49]
Sam 2: Segment anything in images and videos,
N. Ravi, V . Gabeur, Y .-T. Hu, R. Hu, C. Ryali, T. Ma, H. Khedr, R. Rädle, C. Rolland, L. Gustafson et al., “Sam 2: Segment anything in images and videos,” in ICLR, 2025. 16
work page 2025
-
[50]
MOSEv2: A more challenging dataset for video object segmentation in complex scenes,
H. Ding, K. Ying, C. Liu, S. He, X. Jiang, Y .-G. Jiang, P. H. Torr, and S. Bai, “MOSEv2: A more challenging dataset for video object segmentation in complex scenes,” arXiv preprint arXiv:2508.05630 , 2025
-
[51]
MOSE: A new dataset for video object segmentation in complex scenes,
H. Ding, C. Liu, S. He, X. Jiang, P. H. Torr, and S. Bai, “MOSE: A new dataset for video object segmentation in complex scenes,” in ICCV, 2023
work page 2023
-
[52]
MeViS: A large-scale benchmark for video segmentation with motion expressions,
H. Ding, C. Liu, S. He, X. Jiang, and C. C. Loy, “MeViS: A large-scale benchmark for video segmentation with motion expressions,” in ICCV, 2023
work page 2023
-
[53]
MeViS: A multi-modal dataset for referring motion expression video segmentation,
H. Ding, C. Liu, S. He, K. Ying, X. Jiang, C. C. Loy, and Y .-G. Jiang, “MeViS: A multi-modal dataset for referring motion expression video segmentation,” IEEE TPAMI, 2025
work page 2025
-
[54]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” NeurIPS, 2020
work page 2020
-
[55]
High- resolution image synthesis with latent diffusion models,
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High- resolution image synthesis with latent diffusion models,” in CVPR, 2022
work page 2022
-
[56]
Scalable diffusion models with transformers,
W. Peebles and S. Xie, “Scalable diffusion models with transformers,” in ICCV, 2023
work page 2023
-
[57]
B. F. Labs, “Flux,” https://github.com/black-forest-labs/flux, 2024
work page 2024
-
[58]
In-place scene labelling and understanding with implicit scene representation,
S. Zhi, T. Laidlow, S. Leutenegger, and A. J. Davison, “In-place scene labelling and understanding with implicit scene representation,” in CVPR, 2021
work page 2021
-
[59]
Decomposing nerf for editing via feature field distillation,
S. Kobayashi, E. Matsumoto, and V . Sitzmann, “Decomposing nerf for editing via feature field distillation,” NeurIPS, 2022
work page 2022
-
[60]
Neural feature fu- sion fields: 3d distillation of self-supervised 2d image representations,
V . Tschernezki, I. Laina, D. Larlus, and A. Vedaldi, “Neural feature fu- sion fields: 3d distillation of self-supervised 2d image representations,” in 3DV, 2022
work page 2022
-
[61]
Interactive segmen- tation of radiance fields,
R. Goel, D. Sirikonda, S. Saini, and P. Narayanan, “Interactive segmen- tation of radiance fields,” in CVPR, 2023
work page 2023
-
[62]
Lerf: Language embedded radiance fields,
J. Kerr, C. M. Kim, K. Goldberg, A. Kanazawa, and M. Tancik, “Lerf: Language embedded radiance fields,” in ICCV, 2023
work page 2023
-
[63]
Weakly supervised 3d open-vocabulary segmenta- tion,
K. Liu, F. Zhan, J. Zhang, M. Xu, Y . Yu, A. El Saddik, C. Theobalt, E. Xing, and S. Lu, “Weakly supervised 3d open-vocabulary segmenta- tion,” NeurIPS, 2023
work page 2023
-
[64]
Dm-nerf: 3d scene geometry decom- position and manipulation from 2d images,
B. Wang, L. Chen, and B. Yang, “Dm-nerf: 3d scene geometry decom- position and manipulation from 2d images,” in ICLR, 2023
work page 2023
-
[65]
Panoptic lifting for 3d scene understanding with neural fields,
Y . Siddiqui, L. Porzi, S. R. Buló, N. Müller, M. Nießner, A. Dai, and P. Kontschieder, “Panoptic lifting for 3d scene understanding with neural fields,” in CVPR, 2023
work page 2023
-
[66]
Contrastive lift: 3d object instance segmentation by slow-fast con- trastive fusion,
Y . Bhalgat, I. Laina, J. F. Henriques, A. Zisserman, and A. Vedaldi, “Contrastive lift: 3d object instance segmentation by slow-fast con- trastive fusion,” in NeurIPS, 2023
work page 2023
-
[67]
Spin-nerf: Multiview segmentation and perceptual inpainting with neural radiance fields,
A. Mirzaei, T. Aumentado-Armstrong, K. G. Derpanis, J. Kelly, M. A. Brubaker, I. Gilitschenski, and A. Levinshtein, “Spin-nerf: Multiview segmentation and perceptual inpainting with neural radiance fields,” in CVPR, 2023
work page 2023
-
[68]
Segment anything in 3d with nerfs,
J. Cen, Z. Zhou, J. Fang, W. Shen, L. Xie, D. Jiang, X. Zhang, Q. Tian et al., “Segment anything in 3d with nerfs,” in NeurIPS, 2023
work page 2023
-
[69]
Garfield: Group anything with radiance fields,
C. M. Kim, M. Wu, J. Kerr, K. Goldberg, M. Tancik, and A. Kanazawa, “Garfield: Group anything with radiance fields,” in CVPR, 2024
work page 2024
-
[70]
Editing conditional radiance fields,
S. Liu, X. Zhang, Z. Zhang, R. Zhang, J.-Y . Zhu, and B. Russell, “Editing conditional radiance fields,” in CVPR, 2021
work page 2021
-
[71]
Clip-nerf: Text-and- image driven manipulation of neural radiance fields,
C. Wang, M. Chai, M. He, D. Chen, and J. Liao, “Clip-nerf: Text-and- image driven manipulation of neural radiance fields,” in CVPR, 2022
work page 2022
-
[72]
Learning object-compositional neural radiance field for editable scene rendering,
B. Yang, Y . Zhang, Y . Xu, Y . Li, H. Zhou, H. Bao, G. Zhang, and Z. Cui, “Learning object-compositional neural radiance field for editable scene rendering,” in ICCV, 2021
work page 2021
-
[73]
Laterf: Label and text driven object radiance fields,
A. Mirzaei, Y . Kant, J. Kelly, and I. Gilitschenski, “Laterf: Label and text driven object radiance fields,” in ECCV, 2022
work page 2022
-
[74]
Conerf: Controllable neural radiance fields,
K. Kania, K. M. Yi, M. Kowalski, T. Trzci ´nski, and A. Tagliasacchi, “Conerf: Controllable neural radiance fields,” in CVPR, 2022
work page 2022
-
[75]
Instruct-nerf2nerf: Editing 3d scenes with instructions,
A. Haque, M. Tancik, A. A. Efros, A. Holynski, and A. Kanazawa, “Instruct-nerf2nerf: Editing 3d scenes with instructions,” inICCV, 2023
work page 2023
-
[76]
Graf: Generative radiance fields for 3d-aware image synthesis,
K. Schwarz, Y . Liao, M. Niemeyer, and A. Geiger, “Graf: Generative radiance fields for 3d-aware image synthesis,” NeurIPS, 2020
work page 2020
-
[77]
Gram: Generative radiance manifolds for 3d-aware image generation,
Y . Deng, J. Yang, J. Xiang, and X. Tong, “Gram: Generative radiance manifolds for 3d-aware image generation,” in CVPR, 2022
work page 2022
-
[78]
Dreamfusion: Text- to-3d using 2d diffusion,
B. Poole, A. Jain, J. T. Barron, and B. Mildenhall, “Dreamfusion: Text- to-3d using 2d diffusion,” ICLR, 2023
work page 2023
-
[79]
Magic3d: High-resolution text-to- 3d content creation,
C.-H. Lin, J. Gao, L. Tang, T. Takikawa, X. Zeng, X. Huang, K. Kreis, S. Fidler, M.-Y . Liu, and T.-Y . Lin, “Magic3d: High-resolution text-to- 3d content creation,” in CVPR, 2023
work page 2023
-
[80]
Latent-nerf for shape-guided generation of 3d shapes and textures,
G. Metzer, E. Richardson, O. Patashnik, R. Giryes, and D. Cohen-Or, “Latent-nerf for shape-guided generation of 3d shapes and textures,” in CVPR, 2023
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.