Classical Neural Networks on Quantum Devices via Tensor Network Disentanglers: A Case Study in Image Classification
Pith reviewed 2026-05-18 18:26 UTC · model grok-4.3
The pith
Linear layers in classical neural networks can be compressed into matrix product operators, disentangled, and executed in a hybrid classical-quantum setup without losing accuracy on image tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
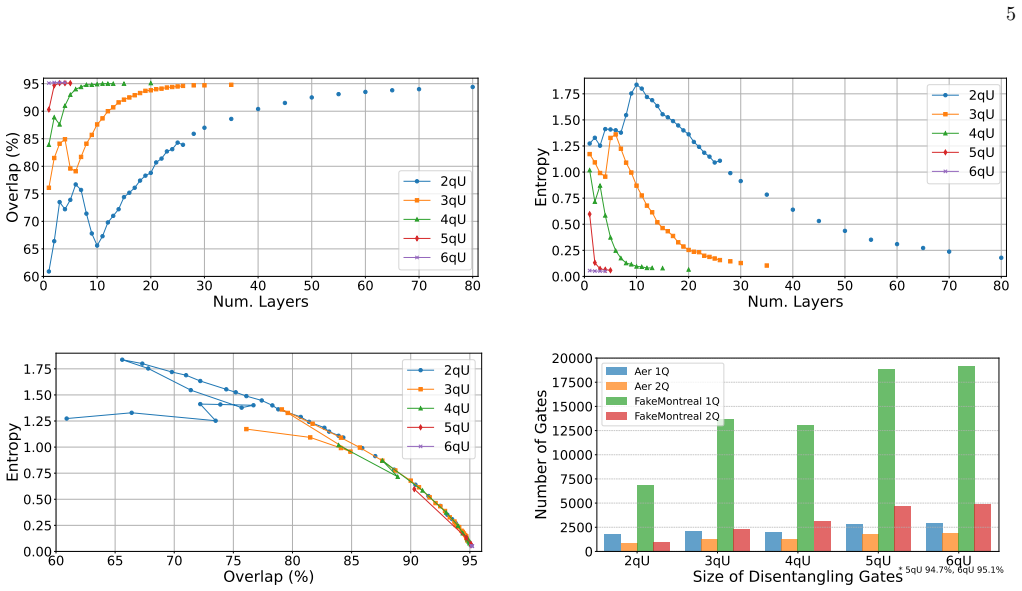
The authors show that a target linear layer can first be expressed as an effective matrix product operator without degrading the network's performance, after which the operator is disentangled either by an explicit variational tensor-network method or by an implicit gradient-descent procedure. The resulting disentangling circuits are placed on a quantum device while the remainder of the model, including the disentangled MPO, runs classically. This hybrid scheme is validated on simple networks for MNIST and CIFAR-10 classification.
What carries the argument
Matrix product operator (MPO) disentangling: a compression of a large linear transformation into a tensor network that is further broken into compact quantum circuits for hybrid execution.
If this is right
- Hybrid models can place only the disentangled circuits on quantum hardware while keeping the compressed MPO and other layers classical.
- Two distinct algorithms exist for the disentangling step: one variational and one gradient-based.
- The same compression-plus-disentangling pipeline applies to both MNIST and CIFAR-10 image-classification networks.
- The method targets bottleneck layers, leaving the rest of a pre-trained network unchanged.
Where Pith is reading between the lines
- If MPO compression continues to work for deeper or wider networks, the hybrid scheme could be applied to larger models without full retraining.
- The approach suggests a general pattern in which tensor-network compression isolates the parts of a computation that benefit most from quantum hardware.
- Extending the same disentangling logic to other tensor-network representations beyond MPOs could broaden the set of layers that can be off-loaded to quantum devices.
Load-bearing premise
A linear layer can be rewritten as a matrix product operator that preserves the original network accuracy.
What would settle it
Running the MPO-compressed and disentangled version of a linear layer on MNIST or CIFAR-10 and measuring lower classification accuracy than the original classical network would falsify the claim.
Figures





read the original abstract
We address the problem of implementing bottleneck layers from classical pre-trained neural networks on a quantum computer, with the goal of exploring intrinsically quantum ansatz for representing large linear layers within hybrid classical-quantum models. Our approach begins with a compression step in which the target linear layer is represented as an effective matrix product operator (MPO) without degrading model performance. The MPO is then further disentangled into a more compact form. This enables a hybrid classical-quantum execution scheme, where the disentangling circuits are deployed on a quantum computer while the remainder of the network -- including the disentangled MPO -- runs on classical hardware. We introduce two complementary algorithms for MPO disentangling: (i) an explicitly disentangling variational method leveraging standard tensor-network optimization techniques, and (ii) an implicitly disentangling gradient-descent-based approach. We validate these methods through a proof-of-concept translation of simple classical neural networks for MNIST and CIFAR-10 image classification into a hybrid classical-quantum form.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to address implementing bottleneck layers from classical pre-trained neural networks on quantum computers by first compressing target linear layers into effective matrix product operators (MPOs) without degrading model performance, then applying disentangling to enable a hybrid classical-quantum execution scheme. Two complementary MPO disentangling algorithms are introduced—an explicitly disentangling variational method and an implicitly disentangling gradient-descent approach—and validated via proof-of-concept translation of simple classical networks on MNIST and CIFAR-10 image classification tasks.
Significance. If the central claims hold, the work could offer a concrete route for embedding large classical linear layers into hybrid models that offload disentangled components to quantum hardware while retaining the rest classically. The use of standard public datasets and tensor-network techniques provides a reproducible starting point for exploring quantum representations of classical bottlenecks.
major comments (1)
- [Abstract] Abstract (compression step): The claim that the target linear layer is represented as an effective MPO 'without degrading model performance' is load-bearing for all subsequent steps, yet the description supplies no quantitative verification such as accuracy deltas, operator-norm error bounds, or ablation over bond dimension on the validation sets. Because the disentangling algorithms and hybrid execution operate directly on this MPO, any unquantified approximation error at compression directly undermines the assertion that the hybrid model preserves the original network's accuracy.
minor comments (1)
- [Abstract] Abstract: The phrase 'simple classical neural networks' is used without specifying layer widths, activation functions, or total parameter counts, making it difficult to assess how the MPO bond-dimension choice scales with network size.
Simulated Author's Rebuttal
We thank the referee for their careful reading of the manuscript and for highlighting the importance of quantitative support for the compression step. We address the major comment below and will revise the manuscript to strengthen the presentation of our results.
read point-by-point responses
-
Referee: [Abstract] Abstract (compression step): The claim that the target linear layer is represented as an effective MPO 'without degrading model performance' is load-bearing for all subsequent steps, yet the description supplies no quantitative verification such as accuracy deltas, operator-norm error bounds, or ablation over bond dimension on the validation sets. Because the disentangling algorithms and hybrid execution operate directly on this MPO, any unquantified approximation error at compression directly undermines the assertion that the hybrid model preserves the original network's accuracy.
Authors: We agree that explicit quantitative verification is necessary to support the compression claim. The main text reports classification accuracies for the original and MPO-compressed networks on both MNIST and CIFAR-10, but we acknowledge that these comparisons, along with bond-dimension ablations and error metrics, are not presented with sufficient prominence or detail in the abstract and introductory sections. In the revised manuscript we will add a dedicated paragraph (or table) in the results section that reports (i) accuracy deltas before/after compression, (ii) operator-norm or Frobenius-norm approximation errors for the MPO fits, and (iii) performance versus bond dimension on the validation sets. We will also revise the abstract to reference these quantitative results, thereby grounding the “without degrading model performance” statement in concrete numbers. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper presents algorithmic contributions for MPO disentangling (variational and gradient-descent methods) followed by empirical validation on public MNIST and CIFAR-10 datasets. The compression of linear layers to MPO is described as a preprocessing step whose performance preservation is tested rather than defined into existence. No equations, fitted parameters, or self-citations are shown to reduce any reported accuracy or hybrid execution result to a tautology or input by construction. The methods remain independent of the target performance metric.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The target linear layer can be represented as an effective matrix product operator without degrading model performance.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
maximizing the overlap Tr(Mχ(QL M'χ' QR)) ... environment tensor Eg ... SVD update g' = V†U†
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Quantum-enhanced Large Language Models on Quantum Hardware via Cayley Unitary Adapters
Cayley unitary adapters executed on real quantum hardware improve LLM perplexity by 1.4% on Llama 3.1 8B with 6000 parameters and recover 83% of compression-induced degradation on SmolLM2.
Reference graph
Works this paper leans on
-
[1]
Normalize and encode the input data using AmplitudeorMPS Encoding
-
[2]
Add unitaries to the quantum circuit via the OperatorandUnitarymethods
-
[3]
Prepare aStateTomographyexperiment using qiskit experiments.library
-
[4]
Extract the statevector from the resulting density matrix
-
[5]
Apply the initial normalization and contract with the reduced MPO
-
[6]
Repeat the procedure with unitaries applied to the other side of the MPO. Finally, we highlight two empirical observations that warrant further investigation but lie beyond the scope of this work. First, the disentangling algorithm described above converged more rapidly and achieved higher over- laps than a gradient-descent optimization of unitaries aimed...
-
[7]
G. Acampora, A. Ambainis, N. Ares, L. Banchi, P. Bhardwaj, D. Binosi, G. A. D. Briggs, T. Calarco, V. Dunjko, J. Eisert, O. Ezratty, P. Erker, F. Fedele, E. Gil-Fuster, M. GÃďrttner, M. Granath, M. Heyl, I. Kerenidis, M. Klusch, A. F. Kockum, R. Kueng, M. Krenn, J. LÃďssig, A. Macaluso, S. Manis- calco, F. Marquardt, K. Michielsen, G. MuÃśoz-Gil, D. MÃijss...
-
[8]
A. Peruzzo, J. McClean, P. Shadbolt, M.-H. Yung, X.-Q. Zhou, P. J. Love, A. Aspuru-Guzik, and J. L. O’Brien, A variational eigenvalue solver on a photonic quantum processor, Nature Communications5, 4213 (2014)
work page 2014
- [9]
-
[10]
A Quantum Approximate Optimization Algorithm
E. Farhi, J. Goldstone, and S. Gutmann, A quan- tum approximate optimization algorithm (2014), arXiv:1411.4028 [quant-ph]
work page internal anchor Pith review Pith/arXiv arXiv 2014
- [11]
-
[12]
M. H. Amin, E. Andriyash, J. Rolfe, B. Kulchytskyy, and R. Melko, Quantum boltzmann machine, Phys. Rev. X 8, 021050 (2018)
work page 2018
-
[13]
V. Havl´ ıˇ cek, A. D. C´ orcoles, K. Temme, A. W. Harrow, A. Kandala, J. M. Chow, and J. M. Gambetta, Super- vised learning with quantum-enhanced feature spaces, Nature567, 209 (2019)
work page 2019
-
[14]
A. Poggiali, A. Berti, A. Bernasconi, G. M. Del Corso, and R. Guidotti, Quantum clustering with k-means: A hybrid approach, Theoretical Computer Science992, 114466 (2024)
work page 2024
- [15]
-
[16]
A. W. Harrow, A. Hassidim, and S. Lloyd, Quantum al- gorithm for linear systems of equations, Physical review letters103, 150502 (2009)
work page 2009
- [17]
- [18]
-
[19]
S. Sim, P. D. Johnson, and A. Aspuru-Guzik, Express- ibility and entangling capability of parameterized quan- tum circuits for hybrid quantum-classical algorithms, Ad- vanced Quantum Technologies2, 1900070 (2019)
work page 2019
-
[20]
Preskill, Quantum computing in the nisq era and be- yond, Quantum2, 79 (2018)
J. Preskill, Quantum computing in the nisq era and be- yond, Quantum2, 79 (2018)
work page 2018
- [21]
-
[22]
J. R. McClean, S. Boixo, V. N. Smelyanskiy, R. Bab- bush, and H. Neven, Barren plateaus in quantum neural network training landscapes, Nature communications9, 4812 (2018)
work page 2018
-
[23]
S.-J. Ran, Encoding of matrix product states into quan- tum circuits of one- and two-qubit gates, Physical Review A101, 10.1103/physreva.101.032310 (2020)
-
[24]
A. Novikov, D. Podoprikhin, A. Osokin, and D. P. Vetrov, Tensorizing neural networks, Advances in neural information processing systems28(2015)
work page 2015
- [25]
- [26]
-
[27]
B. Aizpurua, S. S. Jahromi, S. Singh, and R. Orus, Quan- tum large language models via tensor network disentan- glers, arXiv preprint arXiv:2410.17397 (2024)
-
[28]
L. Deng, The mnist database of handwritten digit images for machine learning research, IEEE Signal Processing Magazine29, 141 (2012)
work page 2012
- [29]
-
[30]
Krizhevsky, Learning multiple layers of features from tiny images (2009)
A. Krizhevsky, Learning multiple layers of features from tiny images (2009)
work page 2009
-
[31]
M. A. Nielsen and I. L. Chuang,Quantum computation and quantum information(Cambridge university press, 2010)
work page 2010
-
[32]
Vidal, Entanglement renormalization, Physical review letters99, 220405 (2007)
G. Vidal, Entanglement renormalization, Physical review letters99, 220405 (2007)
work page 2007
-
[33]
G. Evenbly and G. Vidal, Algorithms for entanglement renormalization, Physical Review B-Condensed Matter and Materials Physics79, 144108 (2009)
work page 2009
-
[34]
S.-J. Ran, E. Tirrito, C. Peng, X. Chen, L. Tagliacozzo, G. Su, and M. Lewenstein,Tensor Network Contractions (Springer Cham – Lecture Notes in Physics, 2020)
work page 2020
-
[35]
J. Gray and G. K.-L. Chan, Hyperoptimized approximate contraction of tensor networks with arbitrary geometry, Phys. Rev. X14, 011009 (2024)
work page 2024
-
[36]
J. Chen, J. Jiang, D. Hangleiter, and N. Schuch, Sign problem in tensor-network contraction, PRX Quantum 6, 010312 (2025)
work page 2025
- [37]
-
[38]
A. M. Saxe, J. L. McClelland, and S. Ganguli, Exact solutions to the nonlinear dynamics of learning in deep linear neural networks, arXiv preprint arXiv:1312.6120 (2013)
work page internal anchor Pith review Pith/arXiv arXiv 2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.