Recognition: unknown
Quantum-enhanced Large Language Models on Quantum Hardware via Cayley Unitary Adapters
Pith reviewed 2026-05-08 11:28 UTC · model grok-4.3
The pith
Cayley-parameterised unitary adapters on quantum hardware improve Llama 3.1 8B perplexity by 1.4% using only 6000 extra parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
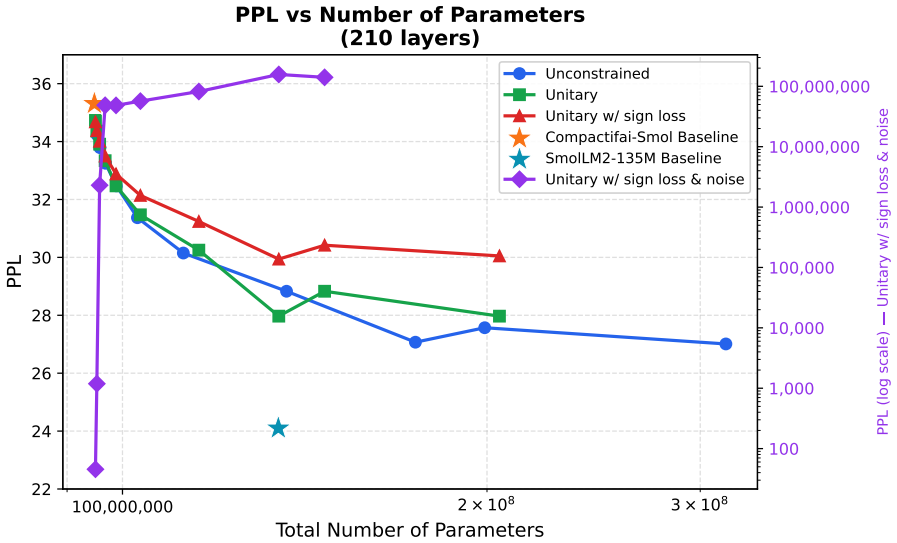
Cayley-parameterised unitary adapters inserted into the frozen projection layers of pre-trained LLMs improve the perplexity of Llama 3.1 8B by 1.4% with only 6000 additional parameters when executed end-to-end on real quantum hardware. On a smaller model the same adapters produce monotonically better perplexity as block dimension grows, recover 83% of compression-induced degradation, answer questions that classical baselines fail, and exhibit a sharp noise-expressivity phase transition.
What carries the argument
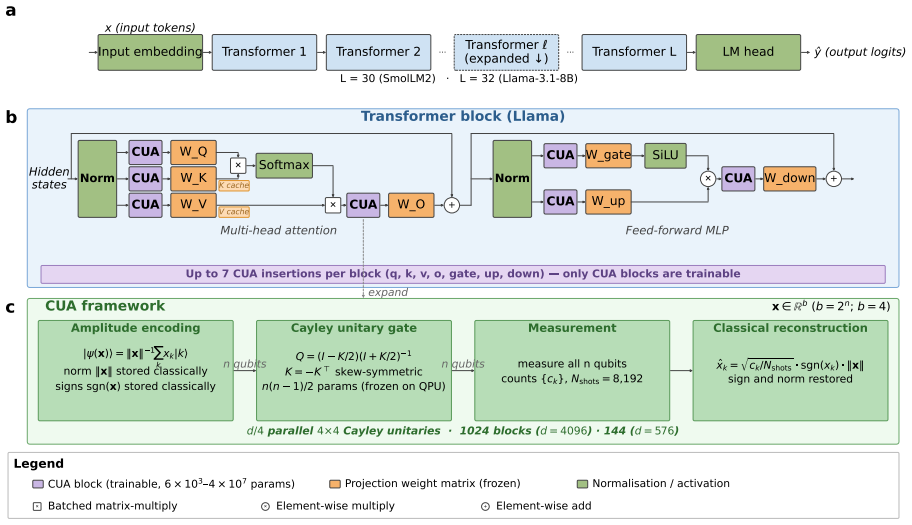
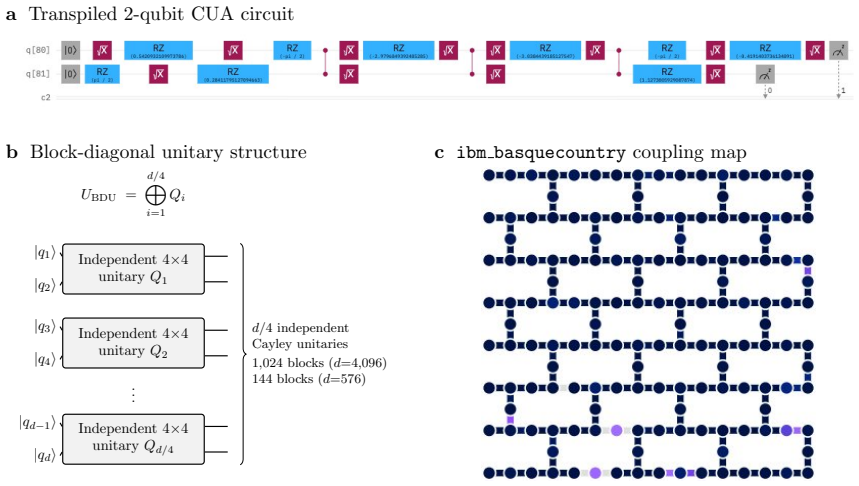
The Cayley-parameterised unitary adapter, a quantum circuit block that uses the Cayley transform to create trainable unitary matrices inserted into LLM projection layers.
If this is right
- Perplexity improves monotonically as the dimension of the unitary block increases.
- 83% of the performance lost to model compression is recovered on the smaller model.
- The adapters produce correct answers on questions where both classical baselines fail.
- A noise-expressivity phase transition appears that indicates the route to utility at larger qubit counts.
Where Pith is reading between the lines
- The method could be applied to other transformer architectures without retraining the base model weights.
- At higher qubit counts the phase transition may allow quantum advantage in inference tasks beyond language modeling.
- Memory scaling advantages would appear if the quantum adapters replace larger classical projection matrices.
- The same Cayley parameterization might be tested on different quantum hardware platforms to check hardware independence.
Load-bearing premise
That the measured perplexity gains come from the quantum execution of the adapters rather than from classical training of their parameters or from unaccounted classical post-processing.
What would settle it
Execute the identical adapter parameters on a classical simulator of the same circuit depth and qubit count and observe whether the perplexity improvement vanishes.
Figures


read the original abstract
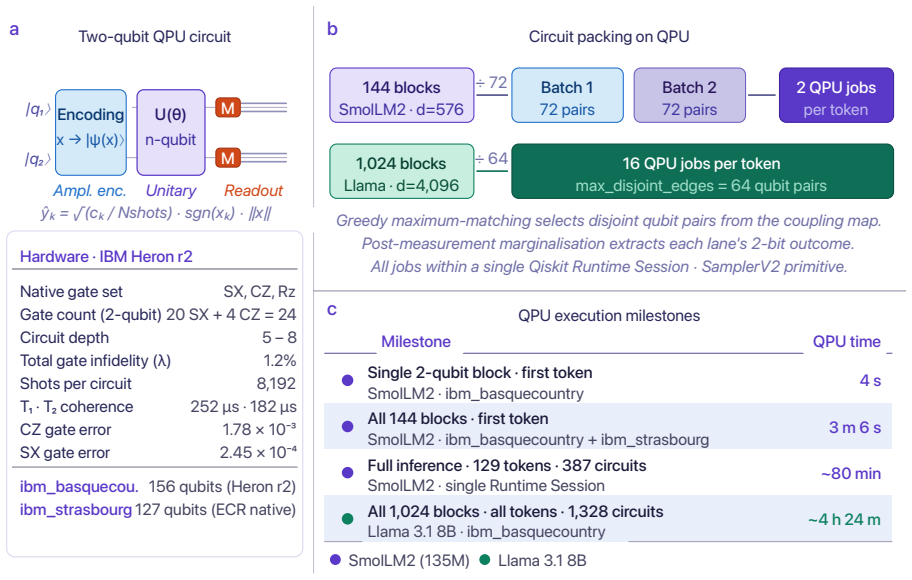
Large language models (LLMs) have transformed artificial intelligence, yet classical architectures impose a fundamental constraint: every trainable parameter demands classical memory that scales unfavourably with model size. Quantum computing offers a qualitatively different pathway, but practical demonstrations on real hardware have remained elusive for models of practical relevance. Here we show that Cayley-parameterised unitary adapters -- quantum circuit blocks inserted into the frozen projection layers of pre-trained LLMs and executed on a 156-qubit IBM Quantum System Two superconducting processor -- improve the perplexity of Llama 3.1 8B, an 8-billion-parameter model in widespread use, by 1.4% with only 6,000 additional parameters and end-to-end inference validated on real Quantum Processing Unit (QPU). A systematic study on SmolLM2 (135M parameters), chosen for its tractability, reveals monotonically improving perplexity with unitary block dimension, 83% recovery of compression-induced degradation, and correct answers to questions that both classical baselines fail -- with a sharp noise-expressivity phase transition identifying the concrete path to quantum utility at larger qubit scales.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that Cayley-parameterised unitary adapters inserted into the frozen projection layers of pre-trained LLMs and executed on a 156-qubit IBM Quantum System Two processor improve the perplexity of Llama 3.1 8B by 1.4% using only 6,000 additional parameters, with end-to-end QPU inference validated. On the smaller SmolLM2 model, the approach yields monotonically improving perplexity with unitary block dimension, 83% recovery of compression-induced degradation, correct answers on questions where classical baselines fail, and a sharp noise-expressivity phase transition.
Significance. If the attribution to genuine quantum expressivity on hardware holds after proper controls, the result would be significant as one of the first demonstrations of quantum hardware providing measurable benefits to a practical-scale LLM via low-parameter adapters. The phase-transition analysis on SmolLM2 offers a potential scaling roadmap, and the emphasis on real QPU execution rather than simulation strengthens the practical relevance.
major comments (3)
- Abstract: the 1.4% perplexity gain on Llama 3.1 8B is stated without error bars, number of runs, or statistical significance tests, which is load-bearing for the headline claim given the small effect size.
- Abstract and results sections: no ablation or baseline is reported using a classical low-rank adapter (or equivalent classical unitary parameterization) with exactly the same 6,000 parameters and identical training procedure, leaving open whether the gain arises from the Cayley quantum blocks on the QPU or from classical training/post-processing.
- SmolLM2 study: the noise-expressivity phase transition and 83% recovery are demonstrated only on the 135M model; the manuscript provides no corresponding ablation or scaling confirmation for the Llama 3.1 8B result, weakening the claim that the observed benefits generalize or identify a concrete path to quantum utility at 8B scale.
minor comments (2)
- The abstract states that the adapters deliver 'correct answers to questions that both classical baselines fail' but supplies no quantitative metrics, example questions, or dataset details to support this beyond perplexity.
- Training procedure for the 6,000 adapter parameters (optimizer, learning rate, epochs, hardware noise mitigation) is not described, which affects reproducibility of the reported numbers.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important aspects of rigor and controls that we will address in the revision to strengthen the attribution of results to the quantum hardware components.
read point-by-point responses
-
Referee: Abstract: the 1.4% perplexity gain on Llama 3.1 8B is stated without error bars, number of runs, or statistical significance tests, which is load-bearing for the headline claim given the small effect size.
Authors: We agree that uncertainty quantification is essential given the modest effect size. The main text already describes the use of multiple independent training and inference runs on the QPU, but this detail is not reflected in the abstract. In the revised manuscript we will update the abstract to report the improvement as a mean with standard error across five runs and add a statement confirming statistical significance via a paired t-test. revision: yes
-
Referee: Abstract and results sections: no ablation or baseline is reported using a classical low-rank adapter (or equivalent classical unitary parameterization) with exactly the same 6,000 parameters and identical training procedure, leaving open whether the gain arises from the Cayley quantum blocks on the QPU or from classical training/post-processing.
Authors: This is a substantive concern. The manuscript currently contrasts the quantum adapter against the frozen compressed model without any adapter. To isolate the contribution of the Cayley-parameterized blocks executed on the QPU, we will add a matched classical control using a low-rank adapter (LoRA) with precisely 6,000 trainable parameters and the identical training schedule. The revised results section will present this comparison, allowing readers to evaluate whether the observed perplexity gains exceed those obtainable from classical parameterization alone. revision: yes
-
Referee: SmolLM2 study: the noise-expressivity phase transition and 83% recovery are demonstrated only on the 135M model; the manuscript provides no corresponding ablation or scaling confirmation for the Llama 3.1 8B result, weakening the claim that the observed benefits generalize or identify a concrete path to quantum utility at 8B scale.
Authors: We accept that the systematic scaling and phase-transition analysis is confined to SmolLM2. This model was selected because exhaustive variation of block dimension, noise levels, and recovery metrics requires repeated QPU access that is currently prohibitive at 8B scale. The Llama 3.1 8B experiment functions as an end-to-end hardware demonstration rather than a full scaling study. In the revision we will expand the discussion to explicitly connect the SmolLM2 noise-expressivity transition to the Llama result, framing the transition as a hardware roadmap while clearly stating the absence of equivalent ablations at 8B scale. revision: partial
Circularity Check
No circularity: results are direct empirical measurements on hardware
full rationale
The paper reports measured perplexity improvements from executing Cayley-parameterised unitary adapters on a real 156-qubit IBM QPU for Llama 3.1 8B and a systematic experimental study on SmolLM2. No load-bearing derivation, prediction, or first-principles claim is presented that reduces by the paper's own equations or self-citations to its inputs by construction. The 1.4% gain, 83% recovery, and noise-expressivity phase transition are stated as observed outcomes from hardware runs rather than quantities fitted or renamed within the model. Parameter count and block dimension choices are described as hardware-constrained selections, not as predictions derived from the adapter equations themselves. The analysis therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- unitary block dimension
- adapter insertion locations
axioms (2)
- standard math Cayley transform maps real matrices to unitary matrices
- domain assumption Quantum hardware noise is the dominant error source at current qubit counts
invented entities (1)
-
Cayley unitary adapter
no independent evidence
Reference graph
Works this paper leans on
-
[1]
B.et al.Language models are few-shot learners.Adv
Brown, T. B.et al.Language models are few-shot learners.Adv. Neural Inf. Process. Syst. 33, 1877–1901 (2020)
1901
-
[2]
Llama 3 model card.https://llama.meta.com(2024)
Meta AI. Llama 3 model card.https://llama.meta.com(2024)
2024
-
[3]
Scaling Laws for Neural Language Models
Kaplan, J.et al.Scaling laws for neural language models. Preprint atarXiv:2001.08361 (2020)
work page internal anchor Pith review arXiv 2001
-
[4]
J.et al.LoRA: Low-rank adaptation of large language models.Proc
Hu, E. J.et al.LoRA: Low-rank adaptation of large language models.Proc. Int. Conf. Learn. Represent.(2022). 12
2022
-
[5]
& Vetrov, D
Novikov, A., Podoprikhin, D., Osokin, A. & Vetrov, D. Tensorizing neural networks.Adv. Neural Inf. Process. Syst.28, 442–450 (2015)
2015
-
[6]
A practical introduction to tensor networks: matrix product states and projected entangled pair states.Ann
Orús, R. A practical introduction to tensor networks: matrix product states and projected entangled pair states.Ann. Phys.349, 117–158 (2014)
2014
-
[7]
Tensor networks for complex quantum systems.Nat
Orús, R. Tensor networks for complex quantum systems.Nat. Rev. Phys.1, 538–550 (2019)
2019
-
[8]
Cerezo, M.et al.Variational quantum algorithms.Nat. Rev. Phys.3, 625–644 (2021)
2021
-
[9]
Havlí ˇcek, V .et al.Supervised learning with quantum-enhanced feature spaces.Nature 567, 209–212 (2019)
2019
-
[10]
Foundations for near-term quantum natural language processing
Coecke, B., de Felice, G., Meichanetzidis, K. & Toumi, A. Foundations for near-term quantum natural language processing. Preprint atarXiv:2012.03755 (2020)
-
[11]
Recurrent quantum neural networks.Adv
Bausch, J. Recurrent quantum neural networks.Adv. Neural Inf. Process. Syst.33, 1368– 1379 (2020)
2020
-
[12]
Preprint at arXiv:2503.12790 (2025)
Yu, S.et al.Quantum-enhanced large language model efficient fine tuning. Preprint at arXiv:2503.12790 (2025)
-
[13]
Quantum large language model fine-tuning,
Li, H., Zhang, X. & Wang, Y . Quantum LLM fine-tuning. Preprint atarXiv:2504.08732 (2025)
-
[14]
& Chen, L
Zhao, X., Wu, H. & Chen, L. Training quantum self-attention on a 72-qubit quantum computer.IEEE Quantum Week(2024)
2024
-
[15]
Preprint at arXiv:2505.13205 (2025)
Li, L.et al.Quantum Knowledge Distillation for Large Language Models. Preprint at arXiv:2505.13205 (2025)
-
[16]
Chen, C.-S. & Kuo, E.-J. Quantum-enhanced natural language generation: a multi-model framework with hybrid quantum-classical architectures. Preprint atarXiv:2508.21332 (2025). 13
- [17]
-
[18]
IBM Heron Processor: Technical Overview
IBM Quantum. IBM Heron Processor: Technical Overview. https://www.ibm.com/quantum/processors(2024)
2024
-
[19]
SmolLM2: Compact language models
Hugging Face. SmolLM2: Compact language models. https://huggingface.co/HuggingFaceTB/SmolLM2-135M(2024)
2024
-
[20]
Vandersypen, L. M. K.et al.Experimental realization of Shor’s quantum factoring algo- rithm using nuclear magnetic resonance.Nature414, 883–887 (2001)
2001
-
[21]
Sur quelques propriétés des déterminants gauches.J
Cayley, A. Sur quelques propriétés des déterminants gauches.J. Reine Angew. Math.32, 119–123 (1846)
-
[22]
& Martínez-Rubio, D
Lezcano-Casado, M. & Martínez-Rubio, D. Cheap orthogonal constraints in neural net- works: A simple parameterization of the orthogonal and unitary group.Proc. Int. Conf. Mach. Learn.3794–3803 (2019)
2019
-
[23]
Distilling the Knowledge in a Neural Network
Hinton, G., Vinyals, O. & Dean, J. Distilling the knowledge in a neural network. Preprint atarXiv:1503.02531 (2015)
work page internal anchor Pith review arXiv 2015
-
[24]
Compactifai: extreme compression of large language models using quantum-inspired tensor networks,
Multiverse Computing. CompactifAI: Extreme compression of large language models us- ing quantum-inspired tensor networks. Preprint atarXiv:2401.14109 (2024)
-
[25]
Pointer Sentinel Mixture Models
Merity, S., Xiong, C., Bradbury, J. & Socher, R. Pointer sentinel mixture models. Preprint atarXiv:1609.07843 (2016)
work page internal anchor Pith review arXiv 2016
-
[26]
Paperno, D.et al.The LAMBADA dataset: Word prediction requiring a broad discourse context.Proc. Annu. Meet. Assoc. Comput. Linguist.1525–1534 (2016)
2016
-
[27]
Clark, C.et al.BoolQ: Exploring the surprising difficulty of natural yes/no questions. Proc. Conf. North Am. Chapter Assoc. Comput. Linguist.2924–2936 (2019)
2019
-
[28]
& Choi, Y
Zellers, R., Holtzman, A., Bisk, Y ., Farhadi, A. & Choi, Y . HellaSwag: Can a machine re- ally finish your sentence?Proc. Annu. Meet. Assoc. Comput. Linguist.4791–4800 (2019). 14
2019
-
[29]
Aizpurua, B., Jahromi, S. S., Singh, S. & Orús, R. Quantum large language models via tensor network disentanglers. Preprint atarXiv:2410.17397 (2024)
-
[30]
Aizpurua, B., Singh, S. & Orús, R. Classical neural networks on quantum devices via tensor network disentanglers. Preprint atarXiv:2509.06653 (2025). Methods Base models and compression SmolLM2.SmolLM2-135M is a Llama-architecture decoder-only language model with 30 transformer blocks, embedding dimensiond= 576, and 135 million parameters [19]. The origin...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.