Towards Multimodal Active Learning: Efficient Learning with Limited Paired Data
Pith reviewed 2026-05-18 13:17 UTC · model grok-4.3
The pith
A new active learning framework acquires cross-modal alignments from unaligned multimodal data to reduce annotation costs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a multimodal active learning framework for unaligned data can be built by designing a modality-aware acquisition function that combines uncertainty and diversity to prioritize valuable cross-modal alignments, achieving linear-time selection that applies to pool-based and streaming settings and reduces annotation needs without accuracy loss on tested benchmarks.
What carries the argument
The modality-aware combination of uncertainty and diversity scores that ranks and selects the most valuable cross-modal alignments to acquire.
If this is right
- Annotation budgets for multimodal models can be reduced substantially while maintaining performance.
- The linear-time algorithm enables scaling to large unaligned multimodal pools or streams.
- The same selection logic works without modification in both pool-based and streaming active learning.
- Focus shifts from labeling pre-paired data to actively choosing which alignments to create.
Where Pith is reading between the lines
- The approach could extend to domains where pairing different sensor or data streams is the dominant cost, such as robotics or medical imaging.
- It suggests testing whether similar modality-aware scoring improves other costly operations like data pairing in self-supervised learning.
- One could measure how well the selected alignments transfer to downstream tasks beyond the training objective.
Load-bearing premise
That the modality-aware combination of uncertainty and diversity scores will reliably identify the most valuable cross-modal alignments to acquire in practice.
What would settle it
An experiment on a held-out multimodal dataset showing that pairs selected by this method yield no better final accuracy than randomly chosen alignments at the same annotation budget.
Figures







read the original abstract
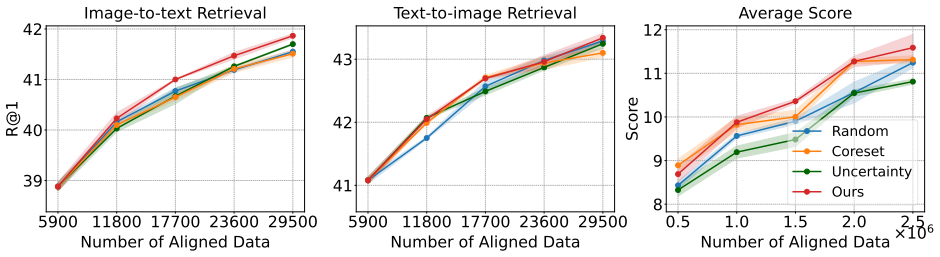
Active learning (AL) is a principled strategy to reduce annotation cost in data-hungry deep learning. However, existing AL algorithms focus almost exclusively on unimodal data, overlooking the substantial annotation burden in multimodal learning. We introduce the first framework for multimodal active learning with unaligned data, where the learner must actively acquire cross-modal alignments rather than labels on pre-aligned pairs. This setting captures the practical bottleneck in modern multimodal pipelines, where unimodal features are easy to obtain but high-quality alignment is costly. We develop a new algorithm that combines uncertainty and diversity principles in a modality-aware design, achieves linear-time acquisition, and applies seamlessly to both pool-based and streaming-based settings. Extensive experiments on benchmark datasets demonstrate that our approach consistently reduces multimodal annotation cost while preserving performance; for instance, on the ColorSwap dataset it cuts annotation requirements by up to 40% without loss in accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the first framework for multimodal active learning with unaligned data, where the task is to actively acquire cross-modal alignments rather than labels on pre-aligned pairs. It proposes a modality-aware acquisition function that combines uncertainty and diversity principles, claims linear-time complexity, and supports both pool-based and streaming settings. Experiments on benchmark datasets, including ColorSwap, report consistent reductions in multimodal annotation cost (up to 40%) while preserving model accuracy.
Significance. If the empirical savings and efficiency claims hold under more rigorous validation, the work would be significant for addressing the practical bottleneck of costly cross-modal alignment in multimodal pipelines. The modality-aware design and linear-time acquisition represent a timely extension of active learning to unaligned multimodal settings, with potential for broader adoption in data-efficient multimodal training.
major comments (3)
- [§4] §4 (Experiments): The reported up to 40% annotation reduction on ColorSwap is presented without error bars, multiple random seeds, or statistical significance tests; this undermines confidence in the consistency of the cost savings and is load-bearing for the central performance claim.
- [§3.2] §3.2 (Acquisition Function): The modality-aware combination of uncertainty and diversity is introduced without a derivation, ablation study, or analysis showing why this specific design reliably identifies valuable alignments; the assumption that it works in practice rests on benchmark results alone.
- [§3] §3 (Method): The linear-time complexity claim for the acquisition procedure lacks a formal complexity analysis, pseudocode, or breakdown in terms of dataset size and modality dimensions, making the efficiency advantage difficult to verify.
minor comments (2)
- [Abstract] The abstract and introduction could more explicitly contrast the proposed setting against prior multimodal active learning work that assumes aligned pairs.
- [§3] Notation for the uncertainty and diversity scores should be defined consistently across equations and text to improve readability.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive comments. We address each of the major comments below and outline the revisions we plan to make to strengthen the manuscript.
read point-by-point responses
-
Referee: [§4] §4 (Experiments): The reported up to 40% annotation reduction on ColorSwap is presented without error bars, multiple random seeds, or statistical significance tests; this undermines confidence in the consistency of the cost savings and is load-bearing for the central performance claim.
Authors: We fully agree with this observation. The absence of error bars and statistical validation does limit the robustness of our empirical results. In the revised manuscript, we will conduct the ColorSwap experiments using multiple random seeds (specifically, 5 seeds) and report the mean annotation cost reduction along with standard deviations. We will also perform statistical significance tests to confirm that the observed savings are consistent and not due to random variation. revision: yes
-
Referee: [§3.2] §3.2 (Acquisition Function): The modality-aware combination of uncertainty and diversity is introduced without a derivation, ablation study, or analysis showing why this specific design reliably identifies valuable alignments; the assumption that it works in practice rests on benchmark results alone.
Authors: We acknowledge that providing a derivation or more in-depth analysis for the specific modality-aware acquisition function would improve the clarity of the method. We will add an ablation study in the revised version to evaluate different ways of combining uncertainty and diversity, and include a short discussion on the rationale behind our design choice, drawing from the characteristics of unaligned multimodal data. revision: yes
-
Referee: [§3] §3 (Method): The linear-time complexity claim for the acquisition procedure lacks a formal complexity analysis, pseudocode, or breakdown in terms of dataset size and modality dimensions, making the efficiency advantage difficult to verify.
Authors: We agree that a formal analysis is necessary to substantiate the linear-time complexity claim. In the revision, we will provide a detailed complexity analysis in Section 3, including a breakdown with respect to the number of data points and feature dimensions for each modality. Additionally, we will include pseudocode for the acquisition function to make the procedure transparent and verifiable. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper presents a new multimodal active learning framework for unaligned data that actively acquires cross-modal alignments using a modality-aware combination of uncertainty and diversity principles. This is described as an original algorithm achieving linear-time acquisition in both pool-based and streaming settings, with empirical support from benchmark experiments showing annotation cost reductions. No equations, fitted parameters, or self-citations are shown that reduce the central claims or acquisition function to prior inputs by construction. The design is introduced as a novel combination rather than a re-expression or renaming of existing quantities, and the results are offered as direct empirical validation independent of the method definition itself.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Uncertainty and diversity scores computed separately per modality can be combined to rank cross-modal alignment value.
invented entities (1)
-
Modality-aware acquisition function
no independent evidence
Forward citations
Cited by 2 Pith papers
-
Active Testing of Large Language Models via Approximate Neyman Allocation
Proposes surrogate semantic entropy stratification followed by approximate Neyman allocation for active testing of LLMs on generative benchmarks, reporting up to 28% MSE reduction and 22.9% average budget savings vers...
-
Active Testing of Large Language Models via Approximate Neyman Allocation
Active testing via surrogate semantic entropy stratification and approximate Neyman allocation reduces MSE by up to 28% versus uniform sampling and saves about 23% of the labeling budget on language and multimodal benchmarks.
Reference graph
Works this paper leans on
-
[1]
Deep batch active learning by diverse, uncertain gradient lower bounds
Jordan T Ash, Chicheng Zhang, Akshay Krishnamurthy, John Langford, and Alekh Agarwal. Deep batch active learning by diverse, uncertain gradient lower bounds.arXiv preprint arXiv:1906.03671,
-
[2]
A survey of multimodal large language model from a data-centric perspective
Tianyi Bai, Hao Liang, Binwang Wan, Yanran Xu, Xi Li, Shiyu Li, Ling Yang, Bozhou Li, Yifan Wang, Bin Cui, et al. A survey of multimodal large language model from a data-centric perspective.arXiv preprint arXiv:2405.16640,
-
[3]
Colorswap: A color and word order dataset for multimodal evaluation.arXiv preprint arXiv:2402.04492,
Jirayu Burapacheep, Ishan Gaur, Agam Bhatia, and Tristan Thrush. Colorswap: A color and word order dataset for multimodal evaluation.arXiv preprint arXiv:2402.04492,
-
[4]
CLIPScore: A Reference-free Evaluation Metric for Image Captioning
Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan Le Bras, and Yejin Choi. Clipscore: A reference-free evaluation metric for image captioning.arXiv preprint arXiv:2104.08718,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Deduplicating Training Data Makes Language Models Better
Katherine Lee, Daphne Ippolito, Andrew Nystrom, Chiyuan Zhang, Douglas Eck, Chris Callison-Burch, and Nicholas Carlini. Deduplicating training data makes language models better.arXiv preprint arXiv:2107.06499,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Katerina Margatina, Timo Schick, Nikolaos Aletras, and Jane Dwivedi-Yu. Active learning principles for in-context learning with large language models.arXiv preprint arXiv:2305.14264,
-
[7]
LAION-400M: Open Dataset of CLIP-Filtered 400 Million Image-Text Pairs
Christoph Schuhmann, Richard Vencu, Romain Beaumont, Robert Kaczmarczyk, Clayton Mullis, Aarush Katta, Theo Coombes, Jenia Jitsev, and Aran Komatsuzaki. Laion-400m: Open dataset of clip-filtered 400 million image-text pairs.arXiv preprint arXiv:2111.02114,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Active Learning for Convolutional Neural Networks: A Core-Set Approach
Ozan Sener and Silvio Savarese. Active learning for convolutional neural networks: A core-set approach. arXiv preprint arXiv:1708.00489,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Weizhi Wang, Khalil Mrini, Linjie Yang, Sateesh Kumar, Yu Tian, Xifeng Yan, and Heng Wang. Finetuned multimodal language models are high-quality image-text data filters.arXiv preprint arXiv:2403.02677, 2024a. Yiping Wang, Yifang Chen, Wendan Yan, Alex Fang, Wenjing Zhou, Kevin Jamieson, and Simon Shaolei Du. Cliploss and norm-based data selection methods ...
-
[10]
Shuo Yang, Zeke Xie, Hanyu Peng, Min Xu, Mingming Sun, and Ping Li. Dataset pruning: Reducing training data by examining generalization influence.arXiv preprint arXiv:2205.09329,
-
[11]
Bo Yuan, Yulin Chen, Yin Zhang, and Wei Jiang. Hide and seek in noise labels: Noise-robust collaborative active learning with llm-powered assistance.arXiv preprint arXiv:2504.02901,
-
[12]
can be implemented using a distance caching strategy. Initially, we compute the minimum distances between all candidate points in Dt and the selection set St−1, incurring a runtime of O(|Dt| · |St−1|). For subsequent iterations in the greedy selection process, we only need O(|Dt|)operations to update the cache and select the next point. Thus, the overall ...
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.