Decoupled Multimodal Fusion for User Interest Modeling in Click-Through Rate Prediction
Pith reviewed 2026-05-18 08:07 UTC · model grok-4.3
The pith
Decoupled Multimodal Fusion lets ID-based and multimodal embeddings interact at fine grain for user interest modeling in CTR prediction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
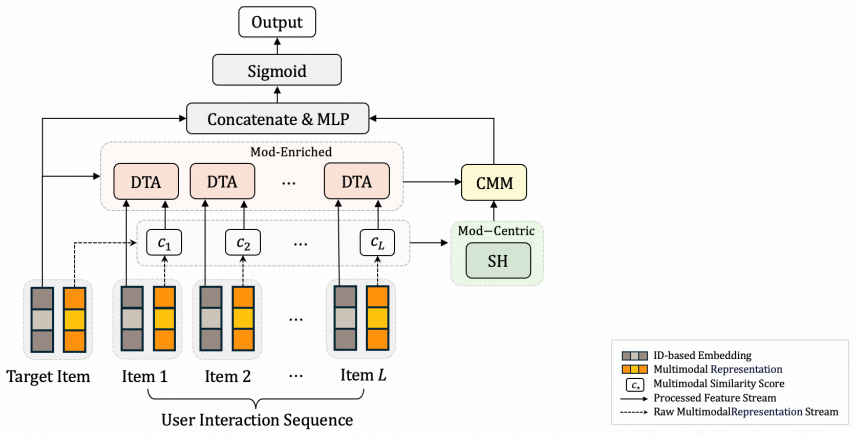
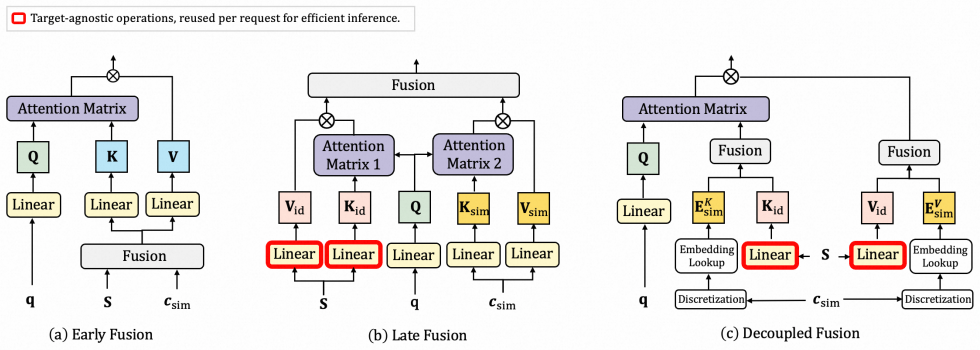
DMF introduces a modality-enriched modeling path that constructs target-aware features from multimodal and ID embeddings to bridge their semantic gap and then applies an inference-optimized attention mechanism that separates the target-aware computation from the ID embedding computation before the attention layer; the system finally combines the resulting user interest representations with those obtained from a conventional modality-centric path, producing stronger CTR predictions.
What carries the argument
Target-aware features paired with a decoupled attention mechanism that pre-computes multimodal side information independently of ID embeddings.
If this is right
- The combined modality-centric and modality-enriched paths produce more complete user interest representations than either path alone.
- Decoupling the attention computation removes the main latency cost of adding multimodal side information.
- Negligible extra compute allows the method to run in production recommendation pipelines without hardware changes.
- The same fusion pattern can be applied to any CTR model that already accepts both ID and content embeddings.
Where Pith is reading between the lines
- Similar target-aware construction and decoupling may reduce cost in other attention-heavy fusion settings such as vision-language or multi-sensor models.
- If the semantic-gap bridging proves robust, the same side-information trick could transfer to cross-domain recommendation where user behavior and item content live in mismatched spaces.
- The explicit merge of two modeling strategies offers a template for hybrid systems that want both efficiency and interaction depth.
Load-bearing premise
Target-aware features reliably close the semantic gap between embedding spaces and the decoupled attention step keeps all necessary fine-grained interactions intact.
What would settle it
A controlled ablation on the Lazada deployment data in which target-aware features or the decoupled attention is removed and the resulting CTCVR and GMV show no gain or a loss compared with the full DMF model would disprove the central claim.
Figures





read the original abstract
Modern industrial recommendation systems improve recommendation performance by integrating multimodal representations from pre-trained models into ID-based Click-Through Rate (CTR) prediction frameworks. However, existing approaches typically adopt modality-centric modeling strategies that process ID-based and multimodal embeddings independently, failing to capture fine-grained interactions between content semantics and behavioral signals. In this paper, we propose Decoupled Multimodal Fusion (DMF), which introduces a modality-enriched modeling strategy to enable fine-grained interactions between ID-based collaborative representations and multimodal representations for user interest modeling. Specifically, we construct target-aware features to bridge the semantic gap across different embedding spaces and leverage them as side information to enhance the effectiveness of user interest modeling. Furthermore, we design an inference-optimized attention mechanism that decouples the computation of target-aware features and ID-based embeddings before the attention layer, thereby alleviating the computational bottleneck introduced by incorporating target-aware features. To achieve comprehensive multimodal integration, DMF combines user interest representations learned under the modality-centric and modality-enriched modeling strategies. Offline experiments on public and industrial datasets demonstrate the effectiveness of DMF. Moreover, DMF has been deployed on the product recommendation system of the international e-commerce platform Lazada, achieving relative improvements of 5.30% in CTCVR and 7.43% in GMV with negligible computational overhead.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Decoupled Multimodal Fusion (DMF) for user interest modeling in CTR prediction. It critiques modality-centric approaches for missing fine-grained interactions between ID-based collaborative signals and multimodal content semantics. DMF introduces a modality-enriched strategy that constructs target-aware features from multimodal and ID embeddings to bridge semantic gaps, feeds them into an inference-optimized attention mechanism that decouples target-aware and ID-based computations before attention, and finally combines the resulting user interest representations from both modeling strategies. Effectiveness is shown via offline experiments on public and industrial datasets plus a live deployment on Lazada's product recommendation system reporting +5.30% relative CTCVR and +7.43% GMV with negligible overhead.
Significance. If the reported lifts are robust, the work offers a practical engineering contribution to industrial multimodal recommendation systems by addressing semantic gaps while maintaining inference efficiency. The combination of modality-centric and modality-enriched paths plus the deployment results on a production e-commerce platform constitute a strength; reproducible code or parameter-free derivations are not claimed.
major comments (2)
- [modality-enriched modeling description] Modality-enriched modeling description: the central claim that target-aware features plus decoupled attention preserve fine-grained behavioral-semantic interactions (rather than approximate them via separate projections) is load-bearing for attributing the Lazada gains to the proposed mechanism; the manuscript does not provide a derivation or controlled ablation showing that joint interaction terms survive the pre-attention decoupling.
- [deployment results] Deployment results paragraph: the 5.30% CTCVR and 7.43% GMV lifts are presented without accompanying statistical significance tests, confidence intervals, or A/B test duration details; this weakens the claim that the improvements are attributable to DMF rather than other production factors.
minor comments (2)
- The abstract and method sections use 'target-aware features' without an explicit equation or pseudocode definition in the provided text; adding a compact formulation would improve reproducibility.
- Offline experiment tables should report standard deviations or p-values across multiple runs to allow readers to assess stability of the reported metric improvements.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help improve the clarity and rigor of our manuscript. We provide point-by-point responses below and have revised the paper accordingly.
read point-by-point responses
-
Referee: [modality-enriched modeling description] Modality-enriched modeling description: the central claim that target-aware features plus decoupled attention preserve fine-grained behavioral-semantic interactions (rather than approximate them via separate projections) is load-bearing for attributing the Lazada gains to the proposed mechanism; the manuscript does not provide a derivation or controlled ablation showing that joint interaction terms survive the pre-attention decoupling.
Authors: We appreciate the referee highlighting this key aspect of our contribution. The target-aware features are explicitly constructed by combining multimodal content embeddings with ID-based collaborative signals in a joint projection step prior to any decoupling; this step encodes the cross-modal interaction terms directly into the side information. The subsequent decoupling applies only to the separate computation of attention inputs for efficiency, while the attention operation itself still receives the enriched representations that retain those joint terms. In the revised manuscript we have added both a mathematical derivation of the preserved interaction terms and a controlled ablation that compares the full DMF against a variant without target-aware bridging, confirming that the fine-grained interactions contribute measurably to the reported gains. revision: yes
-
Referee: [deployment results] Deployment results paragraph: the 5.30% CTCVR and 7.43% GMV lifts are presented without accompanying statistical significance tests, confidence intervals, or A/B test duration details; this weakens the claim that the improvements are attributable to DMF rather than other production factors.
Authors: We agree that additional statistical context strengthens the deployment claims. The revised manuscript now states that the A/B test ran for four weeks on Lazada’s production traffic and that the observed lifts exceeded the platform’s internal statistical-significance threshold. Exact confidence intervals and raw p-values remain undisclosed for proprietary reasons, but we have clarified that the results are not attributable to concurrent changes because the control and treatment groups were isolated to the DMF modification alone. revision: partial
Circularity Check
No significant circularity; empirical deployment results stand independent of internal definitions
full rationale
The paper proposes DMF as an engineering model for multimodal CTR prediction, introducing target-aware features and a decoupled attention mechanism to enable modality-enriched interactions. Effectiveness is shown via offline experiments on public/industrial datasets plus real-world deployment metrics (5.30% CTCVR, 7.43% GMV lift on Lazada). No derivation chain exists that reduces a claimed prediction or uniqueness result to fitted parameters or self-citations by construction. The central claims rest on external measurement rather than tautological re-use of the model's own outputs or prior self-authored theorems.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose Decoupled Target Attention (DTA), which decouples the computation of the K based on ID-derived embeddings from that based on multimodal similarity features... each scalar similarity score c_j is discretized into a bucket index b_j = bucket(c_j), and then mapped into separate learnable embedding vectors
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanalpha_pin_under_high_calibration unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The final user representation r_u is obtained via a convex combination... r_u = α r_me + (1-α) r_mc
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
SID-Coord: Coordinating Semantic IDs for ID-based Ranking in Short-Video Search
SID-Coord coordinates semantic IDs with hashed item IDs via attention fusion, adaptive gating, and interest alignment, yielding +0.664% long-play rate and +0.369% playback duration gains in production search ranking.
Reference graph
Works this paper leans on
-
[1]
DeepFM: A Factorization-Machine based Neural Network for CTR Prediction
H. Guo, R. Tang, Y . Ye, Z. Li, and X. He, “Deepfm: a factorization- machine based neural network for ctr prediction,”arXiv preprint arXiv:1703.04247, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[2]
Miss: Multi-interest self-supervised learning framework for click-through rate prediction,
W. Guo, C. Zhang, Z. Heet al., “Miss: Multi-interest self-supervised learning framework for click-through rate prediction,” in2022 IEEE 38th international conference on data engineering (ICDE). IEEE, 2022, pp. 727–740
work page 2022
-
[3]
J. Gong, Z. Chen, C. Maet al., “Attention weighted mixture of experts with contrastive learning for personalized ranking in e-commerce,” in 2023 IEEE 39th International Conference on Data Engineering (ICDE). IEEE, 2023, pp. 3222–3234
work page 2023
-
[4]
Hierarchical interest modeling of long-tailed users for click-through rate prediction,
X. Xie, J. Niu, L. Denget al., “Hierarchical interest modeling of long-tailed users for click-through rate prediction,” in2023 IEEE 39th International Conference on Data Engineering (ICDE). IEEE, 2023, pp. 3058–3071
work page 2023
-
[5]
Deep interest network for click- through rate prediction,
G. Zhou, X. Zhu, C. Songet al., “Deep interest network for click- through rate prediction,” inProceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining, 2018, pp. 1059–1068
work page 2018
-
[6]
Transact: Transformer- based realtime user action model for recommendation at pinterest,
X. Xia, P. Eksombatchai, N. Panchaet al., “Transact: Transformer- based realtime user action model for recommendation at pinterest,” inProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2023, pp. 5249–5259
work page 2023
-
[7]
Where to go next for recommender systems? id-vs. modality-based recommender models revisited,
Z. Yuan, F. Yuan, Y . Songet al., “Where to go next for recommender systems? id-vs. modality-based recommender models revisited,” inPro- ceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval, 2023, pp. 2639–2649
work page 2023
-
[8]
Towards universal sequence representation learning for recommender systems,
Y . Hou, S. Mu, W. X. Zhaoet al., “Towards universal sequence representation learning for recommender systems,” inProceedings of the 28th ACM SIGKDD conference on knowledge discovery and data mining, 2022, pp. 585–593
work page 2022
-
[9]
X.-R. Sheng, F. Yang, L. Gonget al., “Enhancing taobao display advertising with multimodal representations: Challenges, approaches and insights,” inProceedings of the 33rd ACM International Conference on Information and Knowledge Management, 2024, pp. 4858–4865
work page 2024
-
[10]
Ads recommendation in a collapsed and entangled world,
J. Pan, W. Xue, X. Wanget al., “Ads recommendation in a collapsed and entangled world,” inProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2024, pp. 5566–5577
work page 2024
-
[11]
Distribution-guided auto-encoder for user multimodal interest cross fusion,
M. Zhang, Y . Tang, Y . Jin, J. Hu, and Y . Zhang, “Distribution-guided auto-encoder for user multimodal interest cross fusion,”arXiv preprint arXiv:2508.14485, 2025
-
[12]
Temporal interest network for user response prediction,
H. Zhou, J. Pan, X. Zhouet al., “Temporal interest network for user response prediction,” inCompanion Proceedings of the ACM Web Conference 2024, 2024, pp. 413–422
work page 2024
-
[13]
Twin: Two-stage interest network for lifelong user behavior modeling in ctr prediction at kuaishou,
J. Chang, C. Zhang, Z. Fuet al., “Twin: Two-stage interest network for lifelong user behavior modeling in ctr prediction at kuaishou,” inProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2023, pp. 3785–3794
work page 2023
-
[14]
arXiv preprint arXiv:2108.04468(2021)
Q. Chen, C. Pei, S. Lvet al., “End-to-end user behavior retrieval in click-through rate prediction model,”arXiv preprint arXiv:2108.04468, 2021
-
[15]
Sampling is all you need on modeling long-term user behaviors for ctr prediction,
Y . Cao, X. Zhou, J. Fenget al., “Sampling is all you need on modeling long-term user behaviors for ctr prediction,” inProceedings of the 31st ACM International Conference on Information & Knowledge Management, 2022, pp. 2974–2983
work page 2022
-
[16]
Clickprompt: Ctr models are strong prompt generators for adapting language models to ctr prediction,
J. Lin, B. Chen, H. Wanget al., “Clickprompt: Ctr models are strong prompt generators for adapting language models to ctr prediction,” in Proceedings of the ACM Web Conference 2024, 2024, pp. 3319–3330
work page 2024
-
[17]
Discrete semantic tokenization for deep ctr prediction,
Q. Liu, H. Hu, J. Wuet al., “Discrete semantic tokenization for deep ctr prediction,” inCompanion Proceedings of the ACM Web Conference 2024, 2024, pp. 919–922
work page 2024
-
[18]
Deep & cross network for ad click predictions,
R. Wang, B. Fu, G. Fu, and M. Wang, “Deep & cross network for ad click predictions,” inProceedings of the ADKDD’17, 2017, pp. 1–7
work page 2017
-
[19]
Self-attentive sequential recommenda- tion,
W.-C. Kang and J. McAuley, “Self-attentive sequential recommenda- tion,” in2018 IEEE international conference on data mining (ICDM). IEEE, 2018, pp. 197–206
work page 2018
-
[20]
Bert4rec: Sequential recommendation with bidirectional encoder representations from transformer,
F. Sun, J. Liu, J. Wuet al., “Bert4rec: Sequential recommendation with bidirectional encoder representations from transformer,” inProceedings of the 28th ACM international conference on information and knowledge management, 2019, pp. 1441–1450
work page 2019
-
[21]
R. Ma, D. Sun, J. Xu, J. Yuan, and J. Zhang, “Finding what users look for by attribute-aware personalized item comparison in relevant recom- mendation,” inCompanion Proceedings of the ACM Web Conference 2024, 2024, pp. 549–552
work page 2024
-
[22]
Pinnersage: Multi-modal user embedding framework for recommendations at pinterest,
A. Pal, C. Eksombatchai, Y . Zhouet al., “Pinnersage: Multi-modal user embedding framework for recommendations at pinterest,” inProceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining, 2020, pp. 2311–2320
work page 2020
-
[23]
Courier: contrastive user intention reconstruction for large-scale visual recommendation,
J.-Q. Yang, C. Dai, D. Ouet al., “Courier: contrastive user intention reconstruction for large-scale visual recommendation,”Frontiers of Computer Science, vol. 19, no. 7, p. 197602, 2025
work page 2025
-
[24]
Diffusion-based multi- modal synergy interest network for click-through rate prediction,
X. Cui, W. Lu, Y . Tong, Y . Li, and Z. Zhao, “Diffusion-based multi- modal synergy interest network for click-through rate prediction,” in Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval, 2025, pp. 581– 591
work page 2025
-
[25]
Adversarial multimodal representation learning for click-through rate prediction,
X. Li, C. Wang, J. Tanet al., “Adversarial multimodal representation learning for click-through rate prediction,” inProceedings of The Web Conference 2020, 2020, pp. 827–836
work page 2020
-
[26]
Diff: Dual side- information filtering and fusion for sequential recommendation,
H.-y. Kim, M. Choi, S. Lee, I. Baek, and J. Lee, “Diff: Dual side- information filtering and fusion for sequential recommendation,” inPro- ceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval, 2025, pp. 1624–1633
work page 2025
-
[27]
Aligned side information fusion method for sequential recommendation,
S. Wang, B. Shen, X. Minet al., “Aligned side information fusion method for sequential recommendation,” inCompanion Proceedings of the ACM Web Conference 2024, 2024, pp. 112–120
work page 2024
-
[28]
S3-rec: Self-supervised learning for sequential recommendation with mutual information maximization,
K. Zhou, H. Wang, W. X. Zhaoet al., “S3-rec: Self-supervised learning for sequential recommendation with mutual information maximization,” inProceedings of the 29th ACM international conference on information & knowledge management, 2020, pp. 1893–1902
work page 2020
-
[29]
Noninvasive self-attention for side information fusion in sequential recommendation,
C. Liu, X. Li, G. Caiet al., “Noninvasive self-attention for side information fusion in sequential recommendation,” inProceedings of the AAAI conference on artificial intelligence, vol. 35, 2021, pp. 4249– 4256
work page 2021
-
[30]
Feature-level deeper self-attention network for sequential recommendation
T. Zhang, P. Zhao, Y . Liuet al., “Feature-level deeper self-attention network for sequential recommendation.” inIJCAI, 2019, pp. 4320– 4326
work page 2019
-
[31]
Decoupled side information fusion for sequential recommendation,
Y . Xie, P. Zhou, and S. Kim, “Decoupled side information fusion for sequential recommendation,” inProceedings of the 45th international ACM SIGIR conference on research and development in information retrieval, 2022, pp. 1611–1621
work page 2022
-
[32]
A. Vaswani, N. Shazeer, N. Parmaret al., “Attention is all you need,” in Proceedings of the 31st International Conference on Neural Information Processing Systems, 2017, pp. 6000–6010
work page 2017
-
[33]
Delving deep into rectifiers: Surpassing human-level performance on imagenet classification,
K. He, X. Zhang, S. Ren, and J. Sun, “Delving deep into rectifiers: Surpassing human-level performance on imagenet classification,” in Proceedings of the IEEE international conference on computer vision, 2015, pp. 1026–1034
work page 2015
-
[34]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Y . Liu, M. Ott, N. Goyalet al., “Roberta: A robustly optimized bert pretraining approach,”arXiv preprint arXiv:1907.11692, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[35]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy, “An image is worth 16x16 words: Transformers for image recognition at scale,”arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[36]
J. Zhai, L. Liao, X. Liuet al., “Actions speak louder than words: trillion- parameter sequential transducers for generative recommendations,” in Proceedings of the 41st International Conference on Machine Learning, 2024, pp. 58 484–58 509
work page 2024
-
[37]
An embedding learning framework for numerical features in ctr prediction,
H. Guo, B. Chen, R. Tanget al., “An embedding learning framework for numerical features in ctr prediction,” inProceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, 2021, pp. 2910–2918
work page 2021
-
[38]
Dcn v2: Improved deep & cross network and practical lessons for web-scale learning to rank systems,
R. Wang, R. Shivanna, D. Chenget al., “Dcn v2: Improved deep & cross network and practical lessons for web-scale learning to rank systems,” inProceedings of the web conference 2021, 2021, pp. 1785–1797
work page 2021
-
[39]
Practice on long sequential user behavior modeling for click-through rate prediction,
Q. Pi, W. Bian, G. Zhou, X. Zhu, and K. Gai, “Practice on long sequential user behavior modeling for click-through rate prediction,” inProceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining, 2019, pp. 2671–2679
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.