0
Prototype-guided retrieval improves EHR clinical predictions
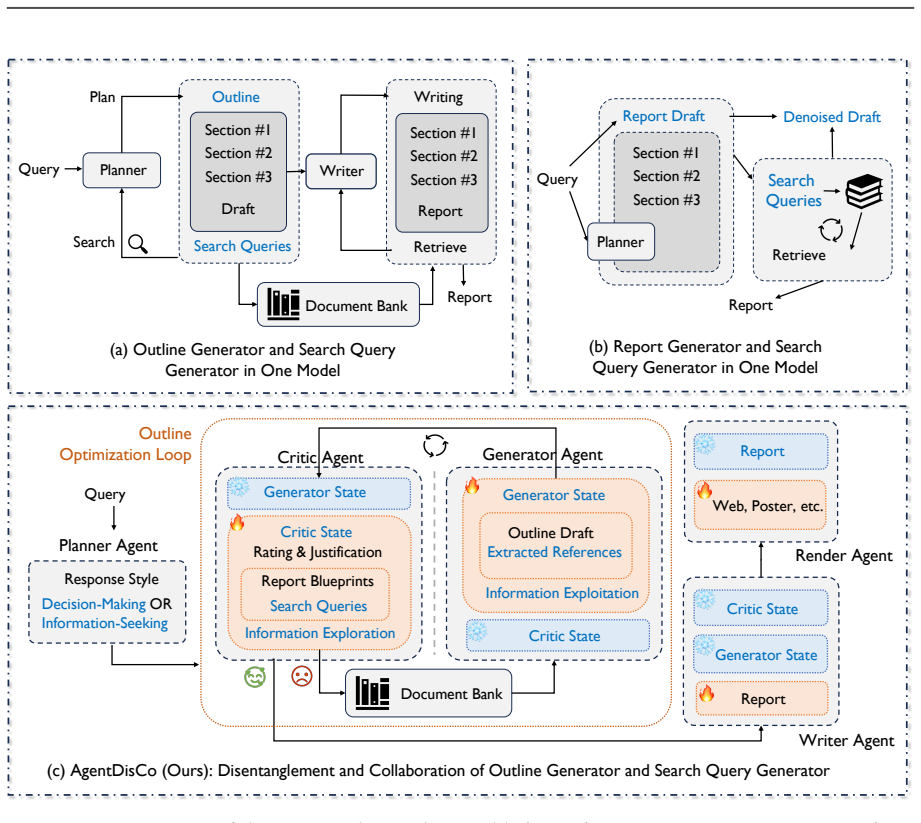
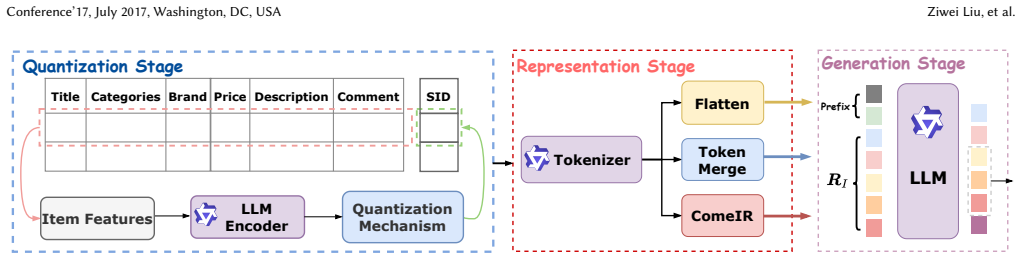
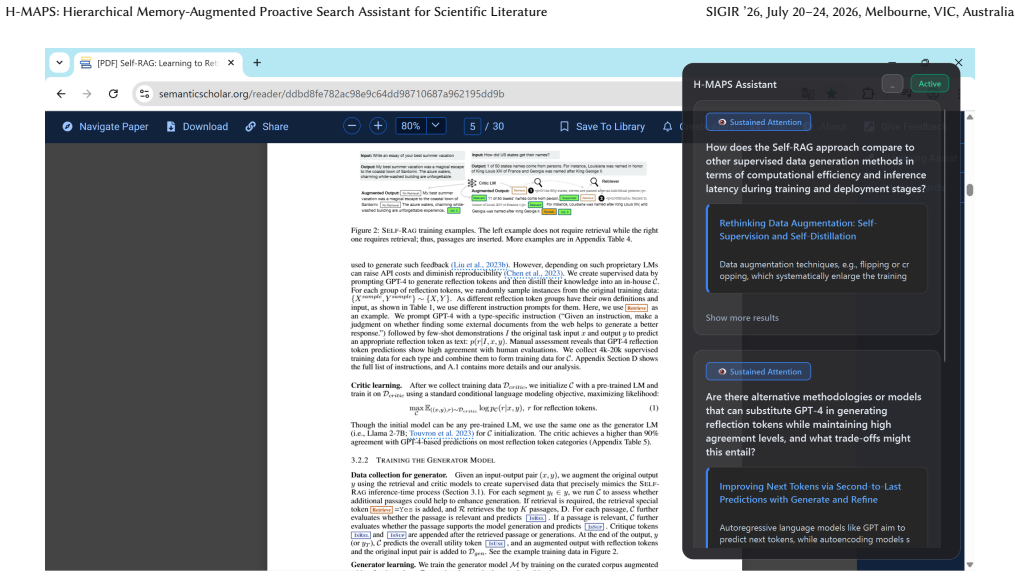
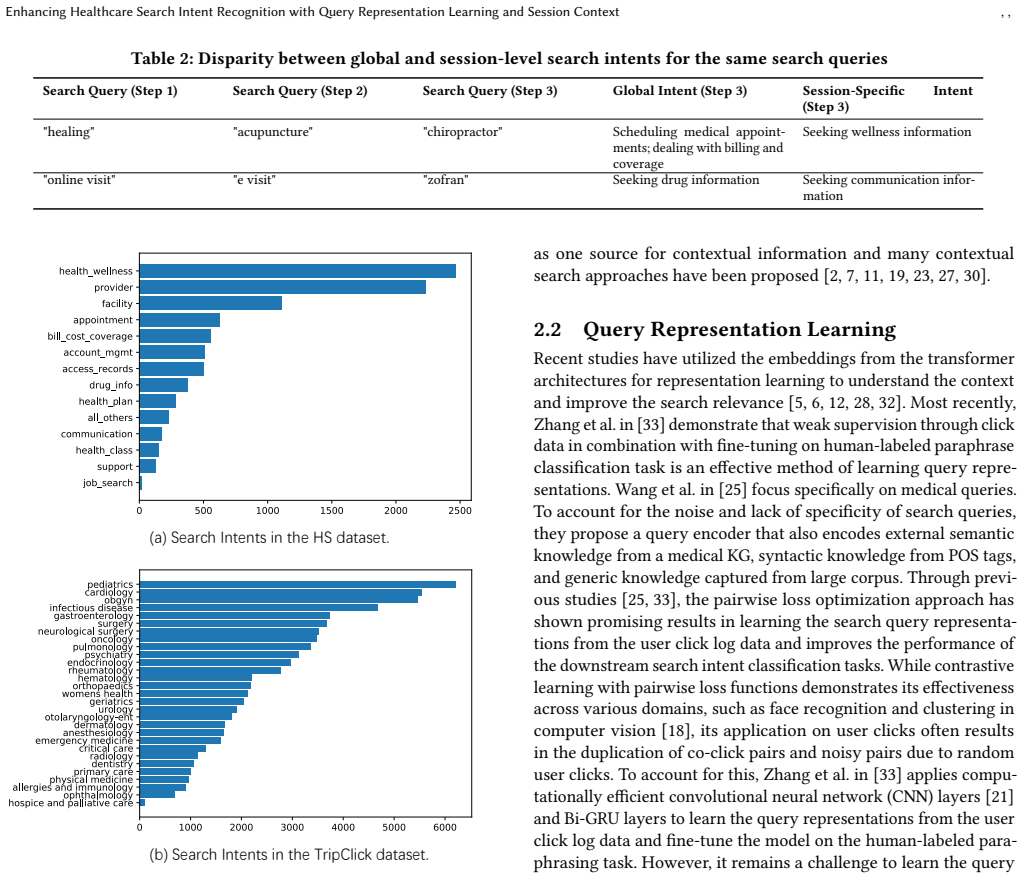
EHR-RAGp: Retrieval-Augmented Prototype-Guided Foundation Model for Electronic Health Records
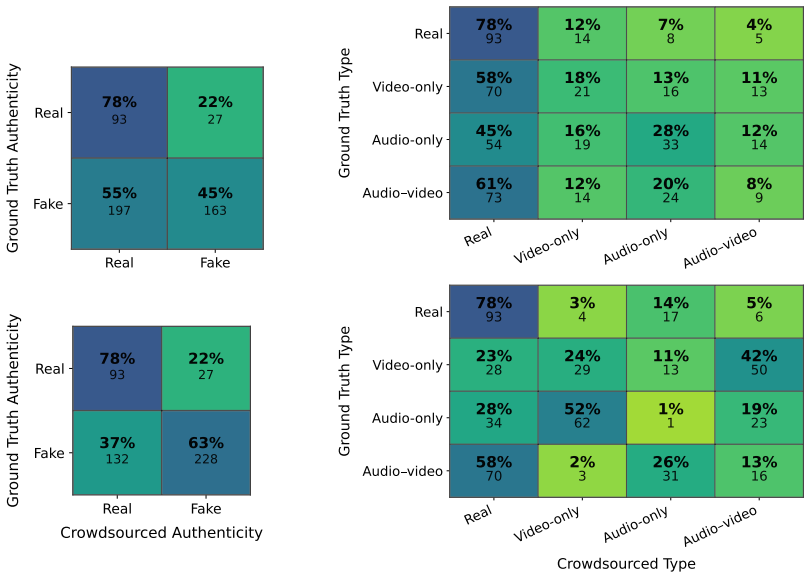
The module selects task-relevant history chunks and outperforms fixed-window baselines while boosting other foundation models.
 full image
full image
abstract click to expand
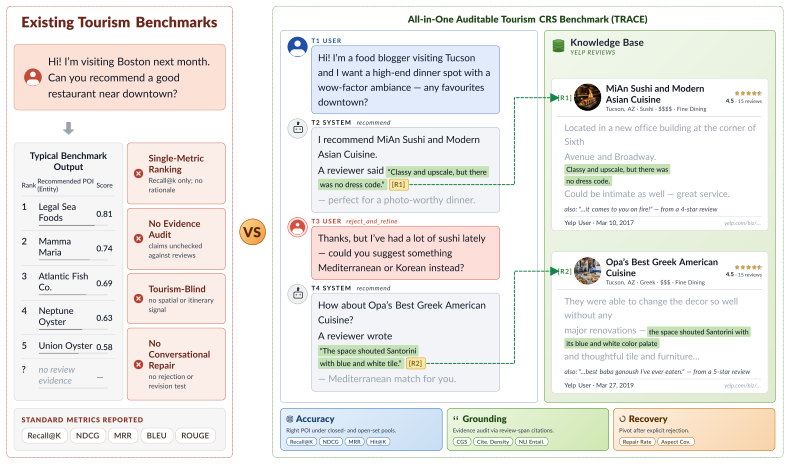
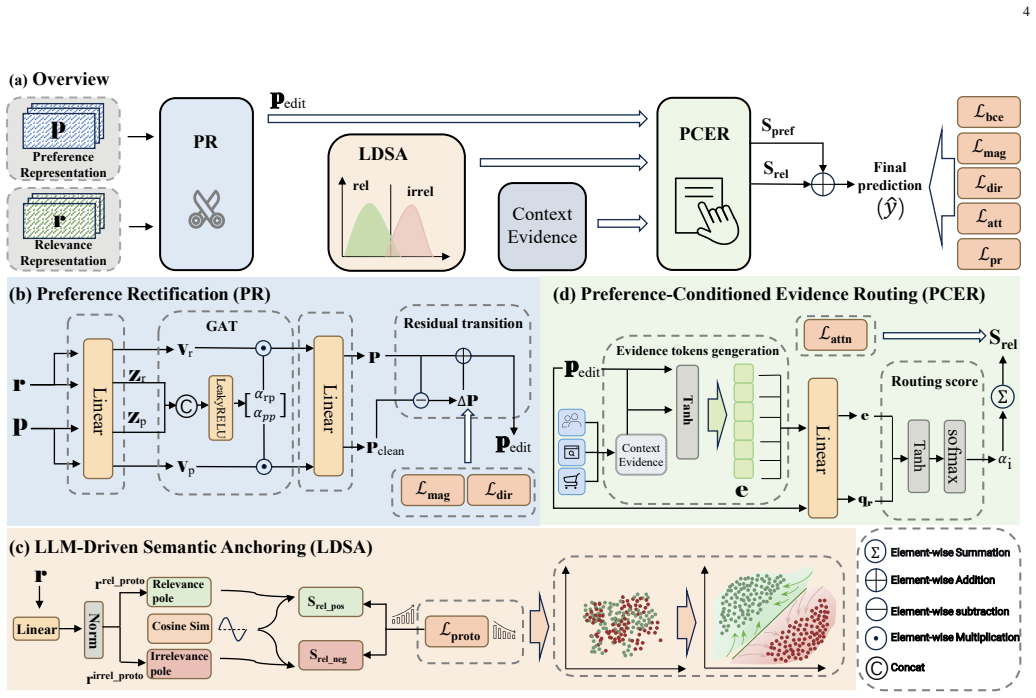
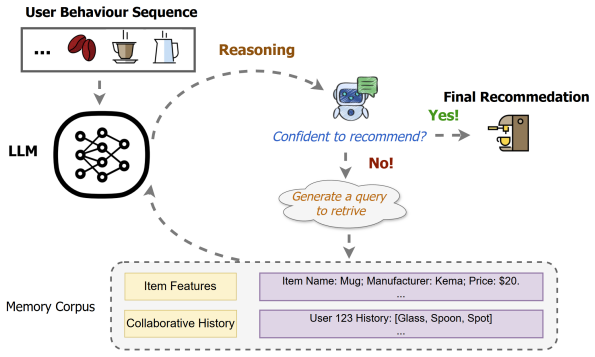
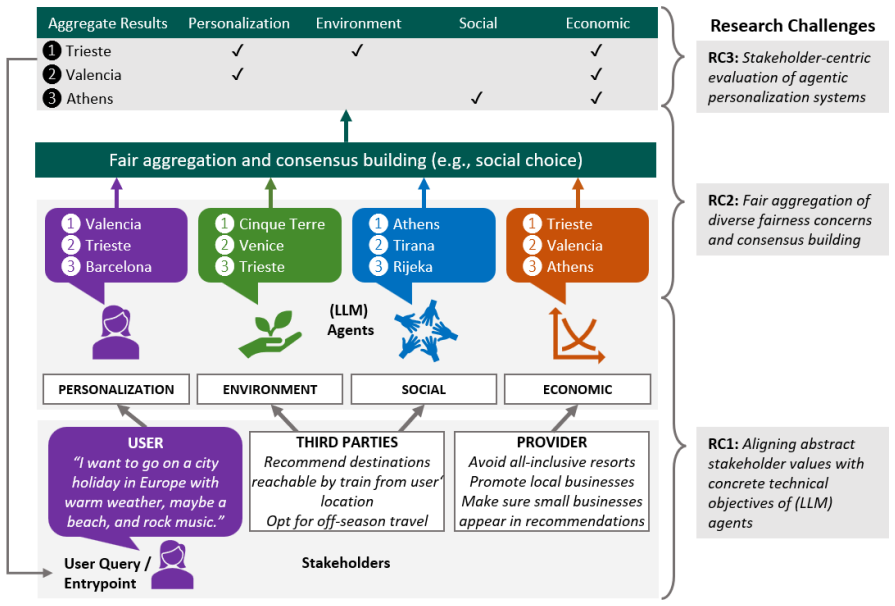
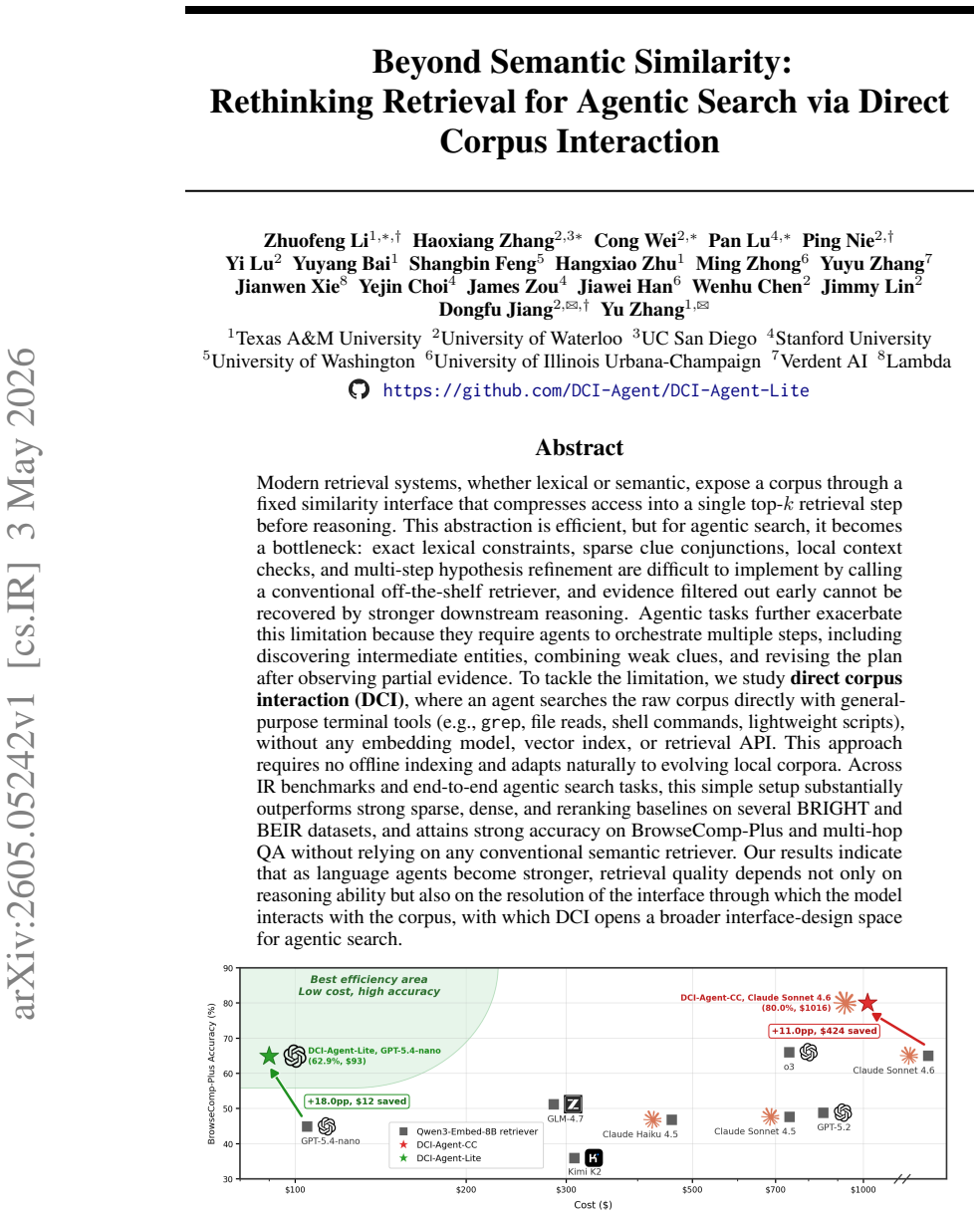
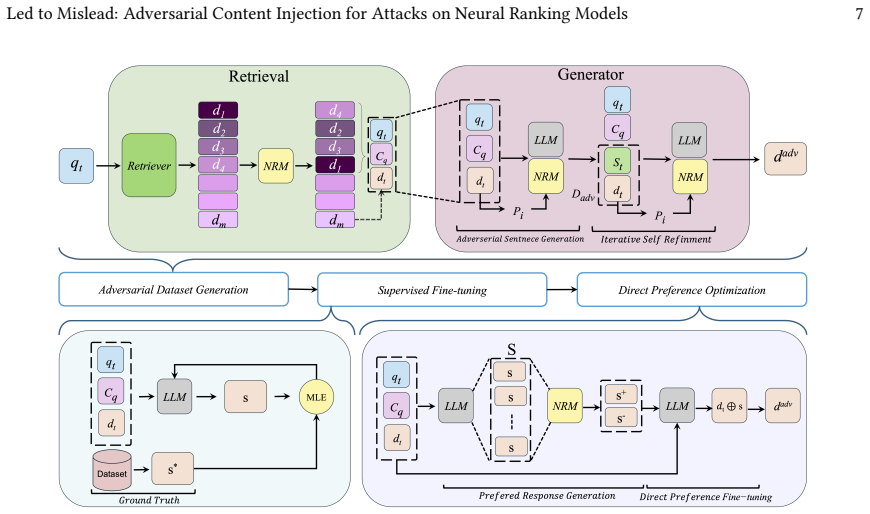
Electronic Health Records (EHR) contain rich longitudinal patient information and are widely used in predictive modeling applications. However, effectively leveraging historical data remains challenging due to long trajectories, heterogeneous events, temporal irregularity, and the varying relevance of past clinical context. Existing approaches often rely on fixed windows or uniform aggregation, which can obscure clinically important signals. In this work, we introduce EHR-RAGp, a retrieval-augmented foundation model that dynamically integrates the most relevant patient history across diverse clinical event types. We propose a prototype-guided retrieval module that acts as an alignment mechanism and estimates the relevance of retrieved historical chunks with respect to a given prediction task, guiding the model towards the most informative context. Across multiple clinical prediction tasks, EHR-RAGp consistently outperforms state-of-the-art EHR foundation models and transformer-based baselines. Furthermore, integrating EHR-RAGp with existing clinical foundation models yields substantial performance gains. Overall, EHR-RAGp provides a scalable and efficient framework for leveraging long-range clinical context to improve downstream performance.