WebAggregator: Enhancing Compositional Reasoning Capabilities of Deep Research Agent Foundation Models
Pith reviewed 2026-05-18 06:47 UTC · model grok-4.3
The pith
A synthesis pipeline generating 10K compositional QA pairs from web data shifts research agents toward deliberate multi-step aggregation and away from simple retrieval.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By curating 10K verifiable QA pairs grounded on 50K websites through the WebAggregator pipeline that pairs Proactive Explorer for interconnected knowledge collection with Compositional Logic Proposer applying over 12 composition guidelines derived from deconstructing the deep research setting, supervised fine-tuning produces WebAggregator-32B. This training fundamentally transforms agent behavior by fostering deliberate compositional reasoning and reduced tool redundancy. The model surpasses GPT-4.1 and matches Claude-3.7-Sonnet on GAIA, WebWalkerQA, and XBench, while the introduced WebAggregatorQA testbed demonstrates that even perfect retrieval leaves top models underperforming, confirming
What carries the argument
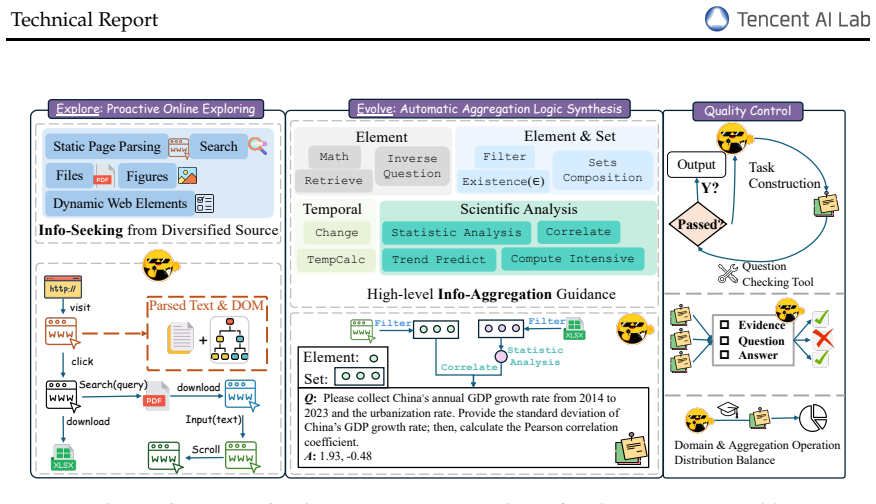
The WebAggregator data synthesis pipeline that uses Proactive Explorer to collect interconnected web knowledge and Compositional Logic Proposer to weave it into complex questions via over 12 guidelines.
If this is right
- Agents exhibit lower tool redundancy and more deliberate planning steps after training.
- Performance gains appear on multiple existing benchmarks that mix retrieval and reasoning.
- The WebAggregatorQA testbed isolates reasoning deficits that persist even when retrieval is perfect.
- Compositional aggregation, rather than retrieval volume, sets the performance ceiling for research agents.
Where Pith is reading between the lines
- The same synthesis approach could be adapted to generate training data for compositional tasks in code or scientific literature domains.
- Targeted synthetic data focused on specific reasoning failures may offer a more efficient path than general pretraining scale for agent capabilities.
- Combining this data pipeline with improved retrieval modules could produce further gains beyond what either component achieves alone.
- The results suggest that measuring agent progress requires benchmarks that decouple retrieval from aggregation demands.
Load-bearing premise
The generated 10K QA pairs genuinely train and measure compositional reasoning rather than rewarding retrieval patterns or memorization.
What would settle it
Evaluating the fine-tuned model on a held-out set of compositional questions that require aggregation patterns outside the 12 guidelines used in synthesis, while holding retrieval quality constant.
Figures







read the original abstract
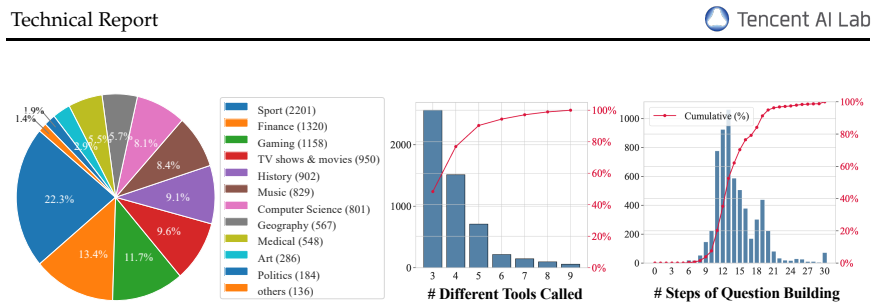
The hallmark of Deep Research agents lies in compositional reasoning, the capacity to aggregate distributed, heterogeneous information into coherent logical insights. However, current agentic systems are often retrieval-heavy but reasoning-light, where success is predominantly determined by simple entity-seeking rather than the multi-step aggregation of scattered evidence. To address this, we propose a data synthesis pipeline WebAggregator, designed to shift the agentic paradigm from retrieval-centric to compositional aggregation. Our approach first employs Proactive Explorer to collect interconnected knowledge, then Compositional Logic Proposer to weave knowledge into complex questions using over 12 composition guidelines derived from a rigorous deconstruction of the Deep Research problem setting. By leveraging 10K verifiable QA pairs grounded on 50K websites, we curate a high-quality SFT dataset via rejection sampling. Fine-tuning on this corpus fundamentally transforms agent behavior, fostering deliberate composition reasoning and reduced tool redundancy. The resulting WebAggregator-32B surpasses GPT-4.1 and matches Claude-3.7-Sonnet on GAIA, WebWalkerQA, and XBench. To address the lack of benchmarks that emphasize both reasoning and retrieval, we introduce the WebAggregatorQA testbed, which reveals that even with perfect retrieval, top-tier models still underperformed. These results demonstrate that compositional reasoning, not retrieval, is the true performance ceiling for next-generation research agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that current deep research agents are retrieval-heavy but reasoning-light, and introduces the WebAggregator data synthesis pipeline to address this. Proactive Explorer collects interconnected knowledge from the web, followed by Compositional Logic Proposer applying over 12 guidelines to generate 10K verifiable QA pairs grounded in 50K websites. After rejection sampling, fine-tuning produces WebAggregator-32B, which is said to foster deliberate compositional reasoning and reduced tool redundancy. This model surpasses GPT-4.1 and matches Claude-3.7-Sonnet on GAIA, WebWalkerQA, and XBench. A new WebAggregatorQA testbed is introduced to demonstrate that compositional reasoning, not retrieval, remains the performance ceiling even under perfect retrieval.
Significance. If the results and claims hold after addressing verification gaps, this would represent a meaningful advance in training agentic systems for deep research tasks by shifting focus from retrieval to compositional aggregation via targeted synthetic data. The WebAggregatorQA testbed provides a useful contribution by isolating reasoning as the bottleneck, which could inform future benchmark design and agent training paradigms in the field.
major comments (3)
- [§3] §3 (Method, Proactive Explorer and Compositional Logic Proposer): The central claim that fine-tuning on the 10K QA pairs shifts agents to deliberate compositional reasoning with reduced tool redundancy is load-bearing on the assumption that the synthesis pipeline produces questions requiring multi-step logical integration of heterogeneous evidence. However, no controls are described, such as ablation against retrieval-only variants, quantitative metrics on knowledge interconnection density, or trace analysis of tool calls pre- and post-fine-tuning to confirm fewer but more compositional actions. Without these, performance gains could stem from higher-quality SFT data or alignment effects rather than the targeted reasoning shift.
- [§4] §4 (Experiments): The reported outperformance of WebAggregator-32B over GPT-4.1 and parity with Claude-3.7-Sonnet on GAIA, WebWalkerQA, and XBench lacks details on baseline agent setups, number of evaluation runs, statistical significance tests, or error analysis. This makes it difficult to determine whether the gains are robust or attributable to the compositional focus of the training data.
- [§5] §5 (WebAggregatorQA testbed): The claim that reasoning is the true ceiling even with perfect retrieval is central to arguing that compositional reasoning—not retrieval—is the limiting factor. Yet the construction of the 'perfect retrieval' oracle is not specified (e.g., whether it provides full relevant passages without answer leakage or how it simulates ideal conditions), undermining the testbed's ability to isolate reasoning deficits.
minor comments (2)
- [§3] The exact list of the 'over 12 composition guidelines' is referenced in the abstract and method but not enumerated or exemplified in the main text; including them (perhaps in an appendix) would improve reproducibility.
- Consider adding a table summarizing the 10K QA pair statistics (e.g., average number of reasoning steps, source diversity) to support the claim of high-quality compositional data.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation of our methods, experiments, and testbed.
read point-by-point responses
-
Referee: [§3] §3 (Method, Proactive Explorer and Compositional Logic Proposer): The central claim that fine-tuning on the 10K QA pairs shifts agents to deliberate compositional reasoning with reduced tool redundancy is load-bearing on the assumption that the synthesis pipeline produces questions requiring multi-step logical integration of heterogeneous evidence. However, no controls are described, such as ablation against retrieval-only variants, quantitative metrics on knowledge interconnection density, or trace analysis of tool calls pre- and post-fine-tuning to confirm fewer but more compositional actions. Without these, performance gains could stem from higher-quality SFT data or alignment effects rather than the targeted reasoning shift.
Authors: We thank the referee for this observation. The pipeline is built around more than 12 composition guidelines explicitly derived from deconstructing the Deep Research setting to require multi-step integration of heterogeneous evidence across interconnected sources. We acknowledge that the original submission did not include explicit controls or quantitative validation of this shift. In the revised manuscript we will add an ablation comparing the full pipeline to a retrieval-only data synthesis variant, report metrics on knowledge interconnection density (such as average linked sources per question), and include pre-/post-fine-tuning tool-call trace analysis to quantify the reduction in redundancy and increase in compositional steps. revision: yes
-
Referee: [§4] §4 (Experiments): The reported outperformance of WebAggregator-32B over GPT-4.1 and parity with Claude-3.7-Sonnet on GAIA, WebWalkerQA, and XBench lacks details on baseline agent setups, number of evaluation runs, statistical significance tests, or error analysis. This makes it difficult to determine whether the gains are robust or attributable to the compositional focus of the training data.
Authors: We appreciate the referee highlighting these gaps in experimental reporting. In the revised version we will expand the experimental section with full details on baseline agent setups (including prompt templates and tool configurations for GPT-4.1 and Claude-3.7-Sonnet), report results aggregated over five independent evaluation runs with means and standard deviations, include statistical significance testing via paired t-tests, and add an error analysis that categorizes failure modes to help attribute gains to the compositional focus of the training data. revision: yes
-
Referee: [§5] §5 (WebAggregatorQA testbed): The claim that reasoning is the true ceiling even with perfect retrieval is central to arguing that compositional reasoning—not retrieval—is the limiting factor. Yet the construction of the 'perfect retrieval' oracle is not specified (e.g., whether it provides full relevant passages without answer leakage or how it simulates ideal conditions), undermining the testbed's ability to isolate reasoning deficits.
Authors: We agree that clearer specification of the oracle is required. In the revision we will explicitly describe the perfect retrieval oracle as supplying the complete set of gold-relevant passages drawn from the underlying 50K websites, concatenated without any direct answer text or leakage, thereby simulating ideal retrieval while forcing the model to perform compositional aggregation and logical inference over the provided evidence. This clarification will better isolate reasoning deficits and support the testbed's contribution. revision: yes
Circularity Check
No circularity: performance claims rest on external benchmarks and independent data synthesis
full rationale
The paper's chain consists of an external-web-grounded synthesis pipeline (Proactive Explorer + Compositional Logic Proposer with >12 guidelines) producing 10K QA pairs, followed by SFT and evaluation on independent public benchmarks (GAIA, WebWalkerQA, XBench) plus a newly introduced testbed. No equations, fitted parameters, or self-citations are shown to reduce the reported gains to the generation process by construction. The central empirical result (WebAggregator-32B surpassing GPT-4.1 and matching Claude-3.7-Sonnet) is measured against externally defined tasks rather than being a renaming or statistical consequence of the synthesis inputs themselves. This is a standard empirical agent paper whose derivation remains self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Compositional reasoning in deep research can be rigorously deconstructed into over 12 composition guidelines that generate complex, verifiable questions.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose an Explore to Evolve paradigm... Automatic Aggregation Logic Synthesis... 12 high-level logical types... Element, Set, Scientific Analysis, and Temporal Reasoning
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
SciResearcher: Scaling Deep Research Agents for Frontier Scientific Reasoning
SciResearcher automates creation of diverse scientific reasoning tasks from academic evidence to train an 8B model that sets new SOTA at 19.46% on HLE-Bio/Chem-Gold and gains 13-15% on SuperGPQA-Hard-Biology and TRQA-...
-
Training LLM Agents for Spontaneous, Reward-Free Self-Evolution via World Knowledge Exploration
LLM agents trained with a task-success reward on self-generated knowledge can spontaneously explore and adapt to new environments without any rewards or instructions at inference, yielding 20% gains on web tasks and a...
Reference graph
Works this paper leans on
-
[1]
doi: 10.18653/v1/2024.findings-acl.557
Association for Computational Linguistics. doi: 10.18653/v1/2024.findings-acl.557. URL https://aclanthology.org/2024.findings-acl.557/. Tianqing Fang, Zeming Chen, Yangqiu Song, and Antoine Bosselut. Complex reasoning over logical queries on commonsense knowledge graphs. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar (eds.), Proceedings of the 62nd Annu...
-
[2]
Information Gathering • Start by thoroughly exploring the given URL and its description. • Visit and browse at least **{least_visits} different websites** to collect diverse and relevant information. • Avoid relying solely on simple search engine queries or Wikipedia. Instead, actively browse, jump between pages, and record your navigation steps and key f...
-
[3]
The answer should **not** be obtainable by a simple search or from a single page
Question Design Formulate a **multi-hop question** that MUST requires reasoning across multiple sources. The answer should **not** be obtainable by a simple search or from a single page. The question should be: 18 Technical Report • Challenging but natural and concise, as if a real user is seeking to learn or solve a puzzle. Avoid unnatural or arbitrary q...
-
[4]
Composition Reasoning Operations (Mandatory) Incorporate at least one of the following reasoning operations in your question: • Scientific Analysis > Statistical Analysis - Analyze data from web pages, you may use, but not limited to: calculating the mean, variance, or standard deviation within a specified time period. Some good examples:
-
[5]
What is the median winnings for drivers who have driven a Chevrolet car?
-
[6]
Which category exhibits the most consistent growth rate across the 5-year period, and what is the average annual percentage increase for that category?
-
[7]
Can you calculate the standard deviation of the average comprehension scores across A, B, and C? > Correlation Analysis
-
[8]
What is the Pearson correlation coefficient (to two decimal places) between China’s average annual temperature and its CO2 emissions per capita over the same period? > Trend Forecasting - Based on historical data, predict future data points. Any algorithm can be used, such as linear regression, polynomial regression, logistic regression, EMA, etc. REMEMBE...
-
[9]
Considering the historical data from 1961 to 1967, what could be the forecasted points of Suzuki in the 50cc and 125cc classes for the upcoming years? Use the average growth rate or the most recent 5-year growth rate for prediction
work page 1961
-
[10]
KFF published an article on abortion in Women’s Health Policy on Feb 27,
-
[11]
> General Computation Intensive Tasks - Batch Data Analysis Requires Intensive Computation
Using single exponential smoothing and MSE, search for the optimal alpha (0.01-0.99) based on the historical data, the MSE loss, and use the alpha to estimate the next data point. > General Computation Intensive Tasks - Batch Data Analysis Requires Intensive Computation. The need to retrieve and process large lists of numbers makes coding ESSENTIAL
-
[12]
What is the average closure price of Apple.inc from Sep. 2024 to Oct. 2024?
work page 2024
-
[13]
Across all NBA seasons where Manu Ginobili’s Player Efficiency Rating (PER) exceeded 20 in the regular season, what was the average number of regular season wins by his team? > Other Tasks - Complex Algorithm with high Complexity: Try to design problems that require coding to reduce time complexity. –––––––––––– • Element-wise operations > Calculation - S...
-
[14]
What is the sum of A’s speed and B’s speed?
-
[15]
By how much does C’s value exceed D’s value?
-
[16]
Avoid direct listing; use indirect clues framed as questions
What is the difference between the population of city X and city Y? > Inverse Question - Formalized as an inverse question about certain information. Avoid direct listing; use indirect clues framed as questions. Ensure your phrasing uniquely identifies the subject without ambiguity. - Examples:
-
[17]
Tom is a singer from New York, who was born on 11 Nov 2024, he
Instead of "Tom is a singer from New York, who was born on 11 Nov 2024, he...", you can use "for the single from New York, who was born on 11 Nov 2024, he..."
work page 2024
-
[18]
My research primarily focuses on
In June 2022, researchers from Huddersfield University published a paper on the application of YOLO in agriculture. My research primarily focuses on ... 20 Technical Report –––––––––––– • List/Set-wise operations > sorting (alphabetical, numerical, top-K), sum, average, counting, intersection, subtraction, merging. Examples:
work page 2022
-
[19]
Which is the shortest among XXX?
-
[20]
What is the average length of YYY?
-
[21]
How many items appear in both set A and set B?
- [22]
-
[23]
Is element E part of the top 10 ranked items?
-
[24]
Exclude all names that were born in 1984 from
work page 1984
-
[25]
Between 2012 and 2021, was the rate of increase in China’s average annual temperature higher or lower than the global average?
work page 2012
-
[26]
On the same day that a landmark house on South Main Street in Coeymans Landing, New York, rich with local history, built in the late 1830s, officially entered the National Register of Historic Places listing, how many places entered the list total? –––––––––––– Note: The numbers or elements used in these operations should be discoverable by reading the we...
-
[27]
> Short, Concise and easy to verify
Answer Requirements > The answer MUST not be obtained directly from the retrieved text and MUST be derived through reasoning. > Short, Concise and easy to verify. > Stable over time (avoid dynamic or real-time data). > Of a clear entity type (e.g., person, number, date, place). ––––––––––––
-
[28]
Output Format Output your final result in the following JSON format: { "topic": "Brief description of the question’s domain or topic", "question": "The constructed multi-hop question", "answer": "The answer X", "context": { "URLs": [ "url_1", "url_2", "url_3", "url_4", "url_5", ... ] } } 21 Technical Report B.4 Prompt of Data Quality Checking Agent TASK D...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.