PAGE-4D: VGGT-4D Perception via Disentangled Pose and Geometry Estimation
Pith reviewed 2026-05-18 06:16 UTC · model grok-4.3
The pith
PAGE-4D extends VGGT to dynamic scenes by using a dynamics-aware mask to disentangle pose and geometry estimation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PAGE-4D resolves the multitask conflict in 4D reconstruction by proposing a dynamics aware aggregator that disentangles static and dynamic information through a predicted dynamics-aware mask, suppressing motion cues for camera pose estimation while amplifying them for geometry reconstruction, and thereby achieves superior results over the original VGGT in dynamic scenarios for pose estimation, monocular and video depth, and dense point map reconstruction without post-processing.
What carries the argument
Dynamics-aware aggregator that predicts a dynamics-aware mask to suppress motion for pose estimation and amplify it for geometry reconstruction.
If this is right
- More accurate camera pose estimation when scenes contain independently moving objects.
- Improved monocular and video depth estimation that accounts for dynamic elements.
- Better dense point map reconstruction in the presence of motion without extra refinement steps.
- Direct feed-forward output of all three tasks instead of separate models or post-processing.
Where Pith is reading between the lines
- The same mask-based disentanglement could transfer to other feed-forward 3D models that face conflicting task signals.
- Real-time robotics or augmented-reality systems might benefit from running the model on live video streams with moving people.
- Further tests on varied motion types, such as fast camera shake combined with slow object deformation, would clarify the mask's robustness.
Load-bearing premise
That one predicted dynamics-aware mask can reliably suppress motion cues for pose while amplifying them for geometry without introducing new inconsistencies or needing heavy task-specific fine-tuning.
What would settle it
A dynamic video sequence with known ground-truth camera poses where PAGE-4D produces larger pose errors than the original VGGT because the predicted mask fails to cleanly separate the motion information.
Figures

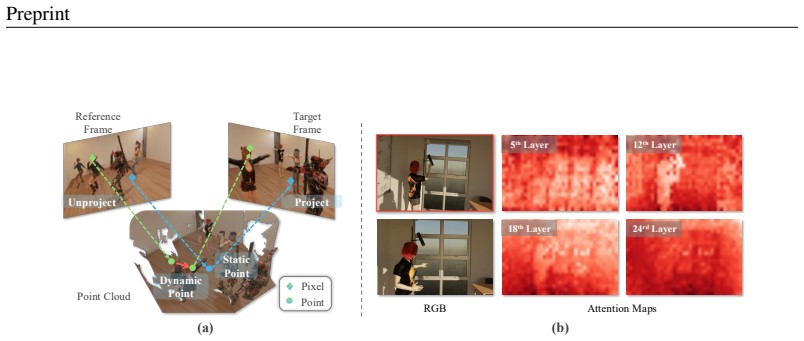

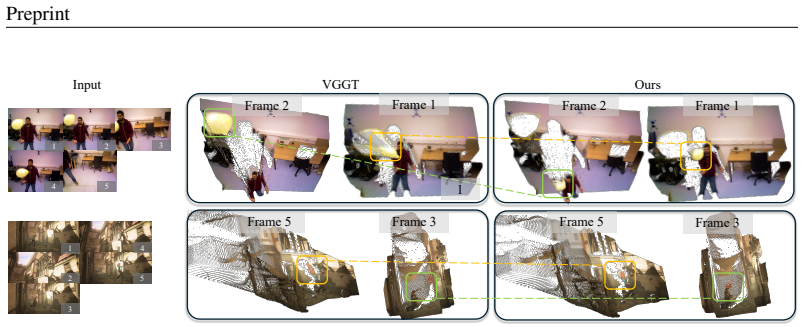

read the original abstract
Recent 3D feed-forward models, such as the Visual Geometry Grounded Transformer (VGGT), have shown strong capability in inferring 3D attributes of static scenes. However, since they are typically trained on static datasets, these models often struggle in real-world scenarios involving complex dynamic elements, such as moving humans or deformable objects like umbrellas. To address this limitation, we introduce PAGE-4D, a feedforward model that extends VGGT to dynamic scenes, enabling camera pose estimation, depth prediction and point cloud reconstruction - all without post-processing. A central challenge in multitask 4D reconstruction is the inherent conflict between tasks: accurate camera pose estimation requires suppressing dynamic regions, while geometry reconstruction requires modeling them. To resolve this tension, we propose a dynamics aware aggregator that disentangles static and dynamic information by predicting a dynamics-aware mask - suppressing motion cues for pose estimation while amplifying them for geometry reconstruction. Extensive experiments show that PAGE-4D consistently outperforms the original VGGT in dynamic scenarios, achieving superior results in camera pose estimation, monocular and video depth estimation, and dense point map reconstruction. Necessary code and additional demos are available at Link: https://page4d.github.io/. Keywords: VGGT-4D, 4D Perception, Dynamic Scene Reconstruction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents PAGE-4D, a feed-forward extension of VGGT for dynamic 4D scenes. It introduces a dynamics-aware aggregator that predicts a single mask to resolve the task conflict: the mask suppresses motion cues for camera pose estimation while amplifying them for monocular/video depth and dense point-map reconstruction. The model operates without post-processing and is reported to outperform the original VGGT across these tasks in dynamic scenarios.
Significance. If the mask-based disentanglement is shown to be accurate and stable, the approach would offer a practical route to multitask 4D perception in real-world dynamic environments. The public release of code and demos strengthens reproducibility and allows direct verification of the claimed gains.
major comments (2)
- [Abstract / §3 (Methods)] The central mechanism—the dynamics-aware aggregator and its predicted mask—is described only at a high level in the abstract and presumed §3. No information is given on mask supervision (e.g., ground-truth dynamic labels or self-supervision), auxiliary consistency losses between the pose and geometry branches, or the precise injection points into the VGGT backbone. Without these details it is impossible to assess whether the same mask can reliably suppress motion for pose while preserving it for geometry without introducing cross-task inconsistencies.
- [Abstract / §4 (Experiments)] The claim of consistent outperformance rests on experimental results that are asserted but not quantified in the provided abstract. Specific metrics, baselines (including VGGT variants and recent 4D methods), ablation studies on the mask, and error analysis on dynamic vs. static regions are required to substantiate the superiority in camera pose, depth, and point-map tasks.
minor comments (1)
- [Abstract] The project link is provided; ensure it remains accessible and contains the promised code and additional demos.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our submission. We address each major comment in detail below and have prepared revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract / §3 (Methods)] The central mechanism—the dynamics-aware aggregator and its predicted mask—is described only at a high level in the abstract and presumed §3. No information is given on mask supervision (e.g., ground-truth dynamic labels or self-supervision), auxiliary consistency losses between the pose and geometry branches, or the precise injection points into the VGGT backbone. Without these details it is impossible to assess whether the same mask can reliably suppress motion for pose while preserving it for geometry without introducing cross-task inconsistencies.
Authors: We agree that additional technical details on the dynamics-aware aggregator are required for a complete evaluation. In the revised manuscript we will expand §3 with a new subsection that specifies: (i) the mask supervision approach, which relies primarily on self-supervision through photometric and geometric consistency losses computed on regions classified as static; (ii) the auxiliary consistency losses that enforce agreement between the pose and geometry branches on the static portions of the mask; and (iii) the precise mask injection locations within the VGGT backbone (after the shared encoder for the pose head and within the geometry decoder). A supplementary architectural diagram with labeled injection points will also be added. revision: yes
-
Referee: [Abstract / §4 (Experiments)] The claim of consistent outperformance rests on experimental results that are asserted but not quantified in the provided abstract. Specific metrics, baselines (including VGGT variants and recent 4D methods), ablation studies on the mask, and error analysis on dynamic vs. static regions are required to substantiate the superiority in camera pose, depth, and point-map tasks.
Authors: We acknowledge that the abstract states the performance gains at a high level. Section 4 of the full manuscript already contains quantitative results on standard dynamic-scene benchmarks, including comparisons against VGGT and additional 4D baselines, together with ablations that isolate the contribution of the mask. In the revision we will (a) insert the key numerical improvements directly into the abstract and (b) ensure the mask ablations and dynamic-versus-static error breakdowns are explicitly summarized in the main text with clear references to the corresponding tables and figures. revision: yes
Circularity Check
No circularity: new aggregator introduced as independent learned module
full rationale
The paper extends VGGT by proposing a dynamics-aware aggregator that predicts a mask to disentangle tasks. This mask is presented as a new learned component rather than being defined in terms of the final pose/geometry outputs or fitted to them by construction. No equations, self-citations, or reductions to inputs are evident in the provided text that would make any prediction equivalent to its own inputs. The central claim rests on the behavior of this added module, which is positioned as externally testable via experiments.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A predicted dynamics-aware mask can be used to suppress motion for pose while amplifying it for geometry without introducing unresolvable task interference.
invented entities (1)
-
dynamics aware aggregator
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
dynamics-aware aggregator that disentangles static and dynamic information by predicting a dynamics-aware mask—suppressing motion cues for pose estimation while amplifying them for geometry reconstruction
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
fine-tuning only the middle 10 layers of the global attention mechanism
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 4 Pith papers
-
FreeOrbit4D: Training-Free Arbitrary Camera Redirection for Monocular Videos via Foreground-Complete 4D Reconstruction
FreeOrbit4D recovers a foreground-complete 4D proxy via decoupled background and object-centric reconstruction to provide geometric guidance for large-angle camera redirection in monocular videos using conditional vid...
-
4DVGGT-D: 4D Visual Geometry Transformer with Improved Dynamic Depth Estimation
A training-free progressive decoupling framework improves dynamic depth estimation in 4D reconstruction via mask-guided pose decoupling, topological subspace surgery, and Bayesian fusion, yielding better point-cloud m...
-
GEM-4D: Geometry-Enhanced Video World Models for Robot Manipulation
GEM-4D is a video world model that injects 4D correspondence supervision to improve geometric consistency and robot manipulation success from 61% to 81%.
-
GeoWorld-VLM: Geometry from World Models for Vision-Language Models
GeoWorld-VLM distills geometric structure from camera-conditioned world models into VLMs by aligning visual features, improving spatial reasoning by about 4% on What'sUp and VSR benchmarks across two architectures whi...
Reference graph
Works this paper leans on
-
[1]
ZoeDepth: Zero-shot Transfer by Combining Relative and Metric Depth
Shariq Farooq Bhat, Reiner Birkl, Diana Wofk, Peter Wonka, and Matthias M¨uller. ZoeDepth: Zero- shot transfer by combining relative and metric depth.arXiv preprint arXiv:2302.12288,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Depth Pro: Sharp Monocular Metric Depth in Less Than a Second
Aleksei Bochkovskii, Ama ˜AG ¸ l Delaunoy, Hugo Germain, Marcel Santos, Yichao Zhou, Stephan R Richter, and Vladlen Koltun. Depth pro: Sharp monocular metric depth in less than a second. arXiv preprint arXiv:2410.02073,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Reconstructing 4D spatial intelligence: A survey
Yukang Cao, Jiahao Lu, Zhisheng Huang, Zhuowei Shen, Chengfeng Zhao, Fangzhou Hong, Zhaoxi Chen, Xin Li, Wenping Wang, Yuan Liu, et al. Reconstructing 4D spatial intelligence: A survey. arXiv preprint arXiv:2507.21045,
-
[4]
Anpei Chen, Zexiang Xu, Fuqiang Zhao, Xiaoshuai Zhang, Fanbo Xiang, Jingyi Yu, and Hao Su. MVSNeRF: Fast generalizable radiance field reconstruction from multi-view stereo.arXiv preprint arXiv:2103.15595,
-
[5]
Easi3r: Estimating disentangled motion from dust3r without training.arXiv preprint arXiv:2503.24391,
Xingyu Chen, Yue Chen, Yuliang Xiu, Andreas Geiger, and Anpei Chen. Easi3r: Estimating disen- tangled motion from DUSt3R without training.arXiv preprint arXiv:2503.24391,
-
[6]
D^2USt3R: Enhancing 3D Reconstruction with 4D Pointmaps for Dynamic Scenes, April 2025
Jisang Han, Honggyu An, Jaewoo Jung, Takuya Narihira, Junyoung Seo, Kazumi Fukuda, Chae- hyun Kim, Sunghwan Hong, Yuki Mitsufuji, and Seungryong Kim. D 2USt3R: Enhancing 3D reconstruction with 4D pointmaps for dynamic scenes.arXiv preprint arXiv:2504.06264,
-
[7]
Geo4d: Leveraging video generators for geometric 4d scene reconstruction
Zeren Jiang, Chuanxia Zheng, Iro Laina, Diane Larlus, and Andrea Vedaldi. Geo4D: Leveraging video generators for geometric 4D scene reconstruction.arXiv preprint arXiv:2504.07961,
-
[8]
11 Preprint Hong Li, Houyuan Chen, Chongjie Ye, Zhaoxi Chen, Bohan Li, Shaocong Xu, Xianda Guo, Xuhui Liu, Yikai Wang, Baochang Zhang, et al. Light of normals: Unified feature representation for universal photometric stereo.arXiv preprint arXiv:2506.18882,
-
[9]
Hanxue Liang, Jiawei Ren, Ashkan Mirzaei, Antonio Torralba, Ziwei Liu, Igor Gilitschenski, Sanja Fidler, Cengiz Oztireli, Huan Ling, Zan Gojcic, et al. Feed-forward bullet-time reconstruction of dynamic scenes from monocular videos.arXiv preprint arXiv:2412.03526,
-
[10]
MoVieS: Motion-aware 4D dynamic view synthesis in one second.arXiv preprint arXiv:2507.10065,
Chenguo Lin, Yuchen Lin, Panwang Pan, Yifan Yu, Honglei Yan, Katerina Fragkiadaki, and Yadong Mu. MoVieS: Motion-aware 4D dynamic view synthesis in one second.arXiv preprint arXiv:2507.10065,
-
[11]
Align3r: Aligned monocular depth estimation for dynamic videos.arXiv preprint arXiv:2412.03079,
Jiahao Lu, Tianyu Huang, Peng Li, Zhiyang Dou, Cheng Lin, Zhiming Cui, Zhen Dong, Sai-Kit Yeung, Wenping Wang, and Yuan Liu. Align3r: Aligned monocular depth estimation for dynamic videos.arXiv preprint arXiv:2412.03079,
-
[12]
A Survey of Structure from Motion
Onur Ozyesil, Vladislav V oroninski, Ronen Basri, and Amit Singer. A survey of structure from motion.arXiv preprint arXiv:1701.08493,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Ba-net: Dense bundle adjustment network, 2019
Chengzhou Tang and Ping Tan. BA-Net: Dense bundle adjustment network.arXiv preprint arXiv:1806.04807,
-
[14]
Mv-dust3r+: Single-stage scene reconstruction from sparse views in 2 seconds,
12 Preprint Zhenggang Tang, Yuchen Fan, Dilin Wang, Hongyu Xu, Rakesh Ranjan, Alexander Schwing, and Zhicheng Yan. MV-DUSt3R+: Single-stage scene reconstruction from sparse views in 2 seconds. arXiv preprint arXiv:2412.06974,
-
[15]
3D Reconstruction with Spatial Memory
Hengyi Wang and Lourdes Agapito. 3d reconstruction with spatial memory.arXiv preprint arXiv:2408.16061, 2024a. Hengyi Wang and Lourdes Agapito. 3D reconstruction with spatial memory.arXiv preprint arXiv:2408.16061, 2024b. Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. VGGT: Visual geometry grounded tran...
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Yuqi Wu, Wenzhao Zheng, Jie Zhou, and Jiwen Lu. Point3R: Streaming 3D reconstruction with explicit spatial pointer memory.arXiv preprint arXiv:2507.02863,
-
[17]
arXiv preprint arXiv:2412.19584 (2024)
Kai Xu, Tze Ho Elden Tse, Jizong Peng, and Angela Yao. Das3r: Dynamics-aware gaussian splat- ting for static scene reconstruction.arXiv preprint arXiv:2412.19584,
-
[18]
Geome- trycrafter: Consistent geometry estimation for open-world videos with diffusion priors, 2025
Tian-Xing Xu, Xiangjun Gao, Wenbo Hu, Xiaoyu Li, Song-Hai Zhang, and Ying Shan. Geome- tryCrafter: Consistent geometry estimation for open-world videos with diffusion priors.arXiv preprint arXiv:2504.01016,
-
[19]
DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection
Hao Zhang, Feng Li, Shilong Liu, Lei Zhang, Hang Su, Jun Zhu, Lionel M Ni, and Heung-Yeung Shum. Dino: Detr with improved denoising anchor boxes for end-to-end object detection.arXiv preprint arXiv:2203.03605, 2022a. Jiahui Zhang, Yuelei Li, Anpei Chen, Muyu Xu, Kunhao Liu, Jianyuan Wang, Xiao-Xiao Long, Hanxue Liang, Zexiang Xu, Hao Su, et al. Advances i...
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Streaming 4D Visual Geometry Transformer
Dong Zhuo, Wenzhao Zheng, Jiahe Guo, Yuqi Wu, Jie Zhou, and Jiwen Lu. Streaming 4D visual geometry transformer.arXiv preprint arXiv:2507.11539,
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.