ALIGN: A Vision-Language Framework for High-Accuracy Accident Location Inference through Geo-Spatial Neural Reasoning
Pith reviewed 2026-05-21 18:53 UTC · model grok-4.3
The pith
A vision-language framework with geometric voting infers accident locations from Bangla news reports to sub-kilometer accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
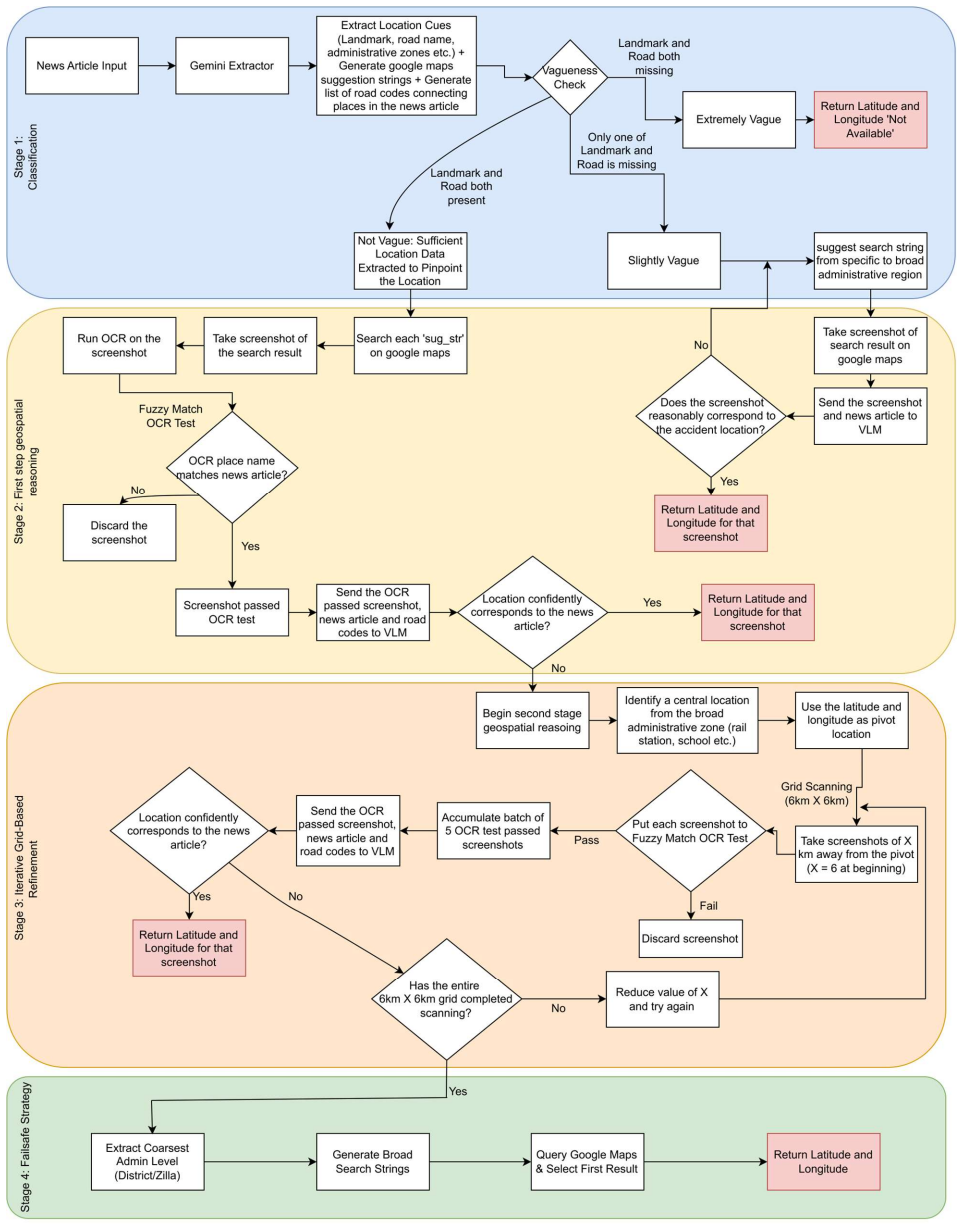
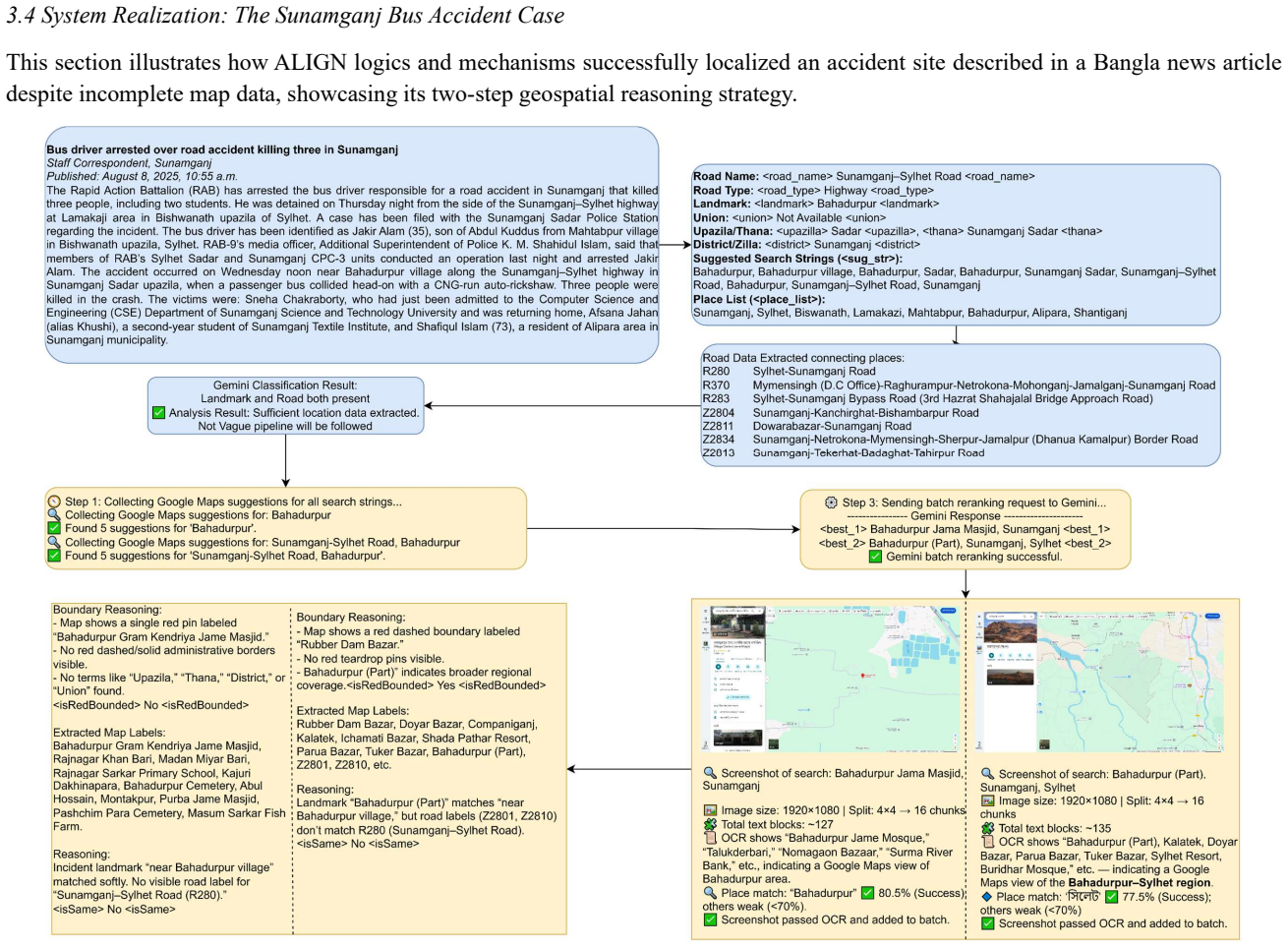
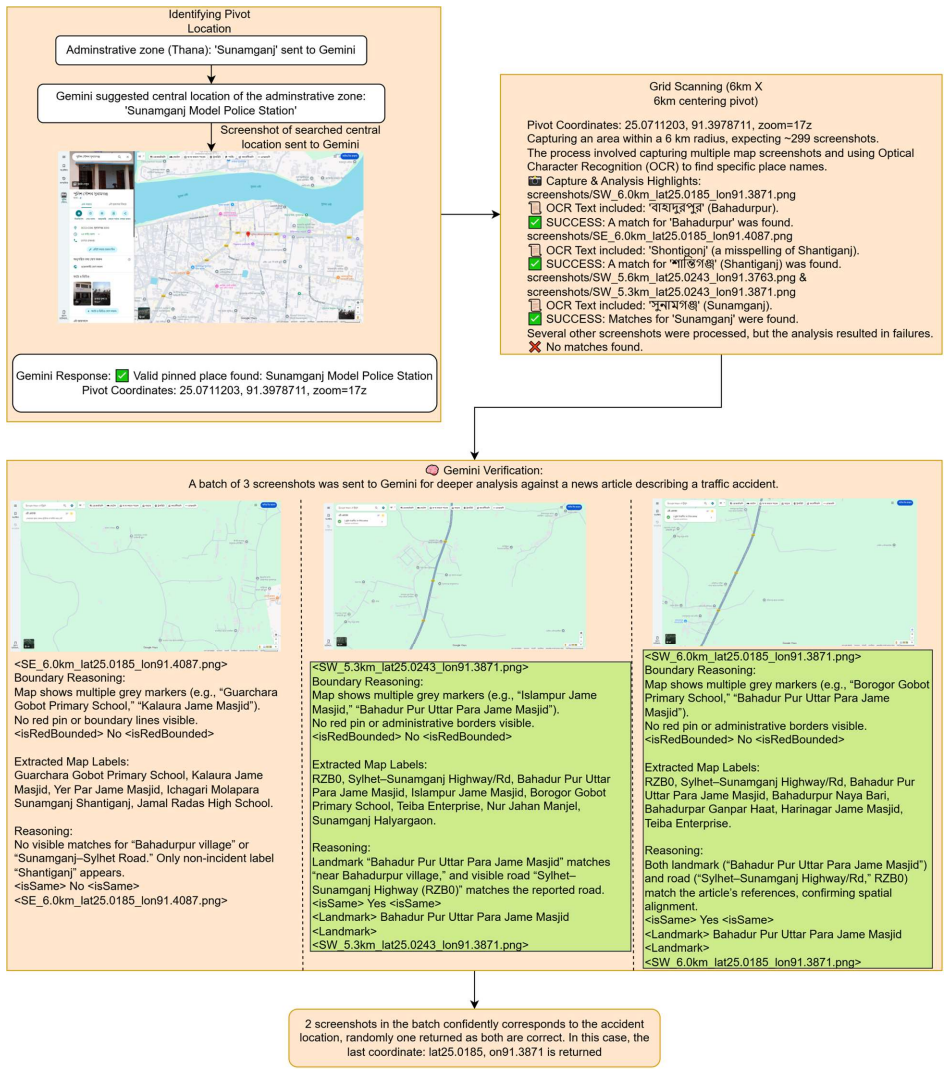
The central claim is that a multimodal agentic architecture combining text extraction, map verification, and a 3-run geometric voting method can mathematically isolate visual hallucinations and produce reliable geospatial coordinates from noisy, multilingual news sources where conventional geocoding tools fail.
What carries the argument
The 3-run geometric voting method inside a grid-based spatial scanning loop that isolates and reduces visual hallucinations in vision-language model outputs.
If this is right
- Enables automated, training-free crash mapping in regions without official location records.
- Supplies evidence for road-safety policymaking and urban planning where data is currently scarce.
- Outperforms text-only geoparsing baselines in multilingual and ambiguous place-name settings.
- Provides a foundation for integrating multimodal AI into transportation analytics.
Where Pith is reading between the lines
- The same pipeline could be tested on reports from other languages or disaster types that share similar location ambiguity.
- Coupling the system with live news feeds might support near-real-time safety monitoring.
- Extending the map-verification step to additional imagery sources could further tighten location estimates in dense urban areas.
Load-bearing premise
The 3-run geometric voting method combined with grid-based spatial scanning reliably isolates and reduces visual hallucinations without introducing systematic bias or requiring dataset-specific tuning.
What would settle it
Apply the full pipeline to a fresh collection of news reports whose true accident coordinates are independently verified by GPS or detailed police logs; a mean error that remains above several kilometers would falsify the accuracy claim.
Figures

read the original abstract
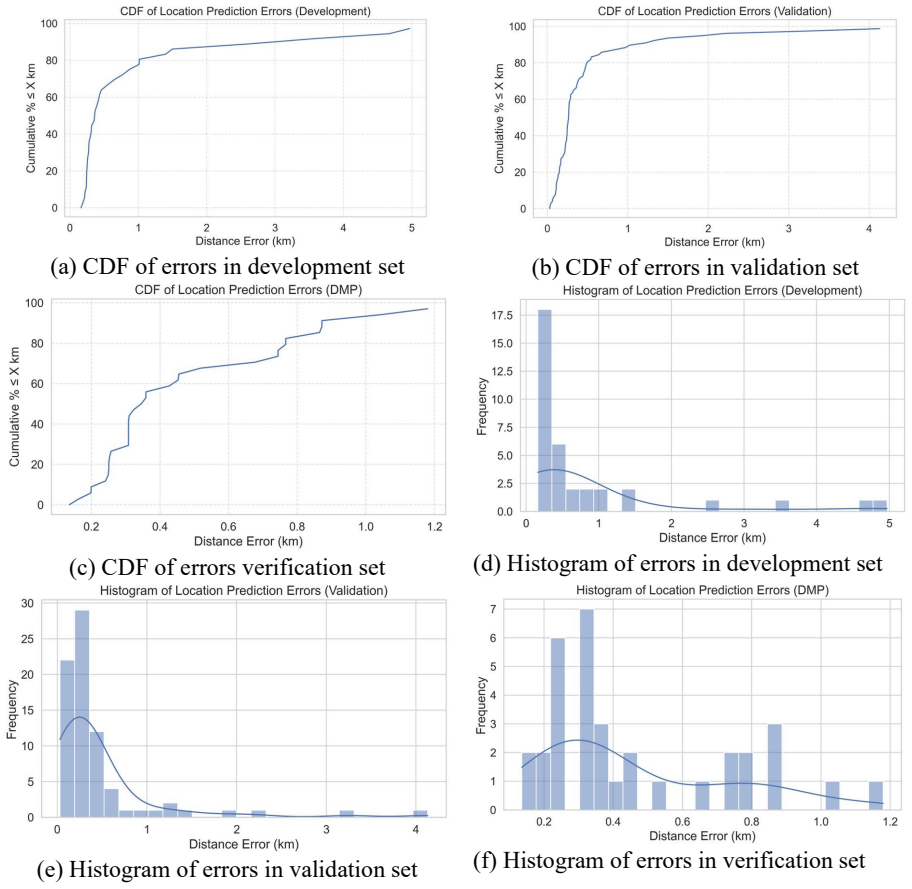
In low- and middle-income countries, public safety and urban planning initiatives frequently face a critical shortage of accurate, location-specific road crash data. Extracting reliable geospatial information from unstructured text requires overcoming the limitations of traditional text-based geocoding tools, which often fail in multilingual environments with ambiguous place descriptions. This study introduces ALIGN (Accident Location Inference through Geo-Spatial Neural Reasoning), a vision-language framework designed to emulate human spatial reasoning to infer precise accident coordinates from unstructured Bangla news reports and map-based cues. A multi stage automated pipeline was developed to process diverse textual and visual data, integrating large language models for cue extraction with vision-language models for map verification. Using an agentic architecture, we modelled an iterative reasoning loop that combines Optical Character Recognition (OCR), grid-based spatial scanning, and a 3-run geometric voting method to mathematically isolate and reduce visual hallucinations. The findings highlight that the multimodal ALIGN framework significantly outperforms traditional text-only geoparsing baselines. For example, the proposed system successfully reduced the mean localization error from an unusable 10.915 km to a sub-kilometer precision of 0.593 km on a validation dataset. Furthermore, testing the framework against official Dhaka Metropolitan Police records confirmed its reliability by achieving a mean error of 0.465 km. The results provide a high-accuracy, training-free foundation for automated crash mapping in data-scarce regions, supporting evidence-driven road-safety policymaking and the integration of multimodal AI in transportation analytics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ALIGN, a vision-language framework for inferring precise accident coordinates from unstructured Bangla news reports and map images. It employs an agentic multi-stage pipeline combining LLMs for textual cue extraction, VLMs for map verification, OCR, grid-based spatial scanning, and a 3-run geometric voting method intended to reduce visual hallucinations. The central empirical claims are large reductions in mean localization error—from 10.915 km with text-only baselines to 0.593 km on a validation set, and 0.465 km when compared against official Dhaka Metropolitan Police records—positioning the method as a training-free solution for crash mapping in data-scarce regions.
Significance. If the reported error reductions are reproducible and attributable to the proposed multimodal reasoning components, the work would provide a practical foundation for automated, high-accuracy geospatial data extraction from news sources in low- and middle-income countries. This could directly support evidence-based road-safety policy and urban planning where official records are incomplete. The integration of vision-language models with geometric voting for spatial disambiguation is a timely application of agentic AI to a real-world multimodal inference problem.
major comments (2)
- [Abstract / multi-stage automated pipeline description] Abstract and pipeline description: the headline performance claims (mean error drop from 10.915 km to 0.593 km, then 0.465 km vs. police records) rest on the assertion that the 3-run geometric voting plus grid-based scanning 'mathematically isolate and reduce visual hallucinations.' No ablation (with vs. without the voting stage), no count of hallucinated vs. corrected cases, and no check for systematic bias (e.g., consistent offsets in dense vs. sparse road networks) are reported. Without this evidence it is unclear whether the sub-kilometer numbers can be attributed to the proposed neural reasoning mechanism rather than simple averaging of noisy outputs.
- [Abstract] Abstract: dataset size, construction of the validation set, selection criteria for the Bangla news reports, and implementation details for the text-only geoparsing baselines are not provided. Error bars or statistical significance for the reported means are also absent. These omissions make it impossible to assess whether the large error reductions are robust or sensitive to particular experimental choices.
minor comments (1)
- [Abstract] The phrase 'multi stage' appears without a hyphen; standard technical writing uses 'multi-stage' for consistency.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The comments highlight important areas where additional evidence and clarity can strengthen the manuscript. We address each major comment below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [Abstract / multi-stage automated pipeline description] Abstract and pipeline description: the headline performance claims (mean error drop from 10.915 km to 0.593 km, then 0.465 km vs. police records) rest on the assertion that the 3-run geometric voting plus grid-based scanning 'mathematically isolate and reduce visual hallucinations.' No ablation (with vs. without the voting stage), no count of hallucinated vs. corrected cases, and no check for systematic bias (e.g., consistent offsets in dense vs. sparse road networks) are reported. Without this evidence it is unclear whether the sub-kilometer numbers can be attributed to the proposed neural reasoning mechanism rather than simple averaging of noisy outputs.
Authors: We agree that the manuscript would benefit from explicit evidence linking the performance gains to the geometric voting and grid-scanning components rather than averaging effects. The current version does not contain the requested ablation study, hallucination counts, or bias analysis. In the revised manuscript we will add an ablation comparing the full pipeline against a version without the 3-run voting stage, report the number of cases in which the voting mechanism corrected hallucinations, and include a stratified error analysis across dense and sparse road networks to check for systematic offsets. revision: yes
-
Referee: [Abstract] Abstract: dataset size, construction of the validation set, selection criteria for the Bangla news reports, and implementation details for the text-only geoparsing baselines are not provided. Error bars or statistical significance for the reported means are also absent. These omissions make it impossible to assess whether the large error reductions are robust or sensitive to particular experimental choices.
Authors: We acknowledge that these experimental details were omitted. In the revised manuscript we will report the dataset size, describe the construction of the validation set and the selection criteria applied to the Bangla news reports, provide implementation details for the text-only geoparsing baselines, and include error bars together with statistical significance tests for the mean localization errors. revision: yes
Circularity Check
No circularity: localization errors are measured against external validation and police records
full rationale
The paper describes an empirical pipeline (OCR + grid scanning + 3-run geometric voting) whose outputs are evaluated by computing mean localization error on a held-out validation set (reduced from 10.915 km baseline to 0.593 km) and against independent Dhaka Metropolitan Police records (0.465 km). These error figures are post-hoc measurements against external ground truth, not quantities obtained by fitting parameters inside the same equations or by renaming internal definitions. No self-citations, uniqueness theorems, or ansatzes are invoked to derive the accuracy numbers; the central claims rest on direct comparison to data outside the model's construction. The derivation chain is therefore self-contained and non-circular.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
multi-stage automated pipeline ... OCR, grid-based spatial scanning, and a 3-run geometric voting method to mathematically isolate and reduce visual hallucinations
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
reduced the mean localization error from an unusable 10.915 km to a sub-kilometer precision of 0.593 km
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Ajanaku, B. (2025). Geo-Semantics Analysis of Environmental Disasters in Nigeria Using National Print Media Data for Disaster Management. In Workshop on Tackling Climate Change with Machine Learning, ICLR
work page 2025
-
[2]
https://www.climatechange.ai/papers/iclr2025/53/poster.pdf Algiriyage, N., Prasanna, R., Stock, K., Doyle, E. E. H., & Johnston, D. (2022). DEES: A real- time system for event extraction from disaster-related web text. Social Network Analysis and Mining, 13(1),
work page 2022
-
[3]
https://doi.org/10.1007/s13278-022-01007-2 Al-Olimat, H., Thirunarayan, K., Shalin, V ., & Sheth, A. (2018). Location name extraction from targeted text streams using gazetteer-based statistical language models. In E. M. Bender, L. Derczynski, & P. Isabelle (Eds.), Proceedings of the 27th International Conference on Computational Linguistics (pp. 1986–199...
-
[4]
Retrieval-Augmented Generation for Large Language Models: A Survey
https://doi.org/10.1186/1476-072X-8-72 Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-V oss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D. M., Wu, J., Winter, C., ... Amodei, D. (2020). Language models are few-shot learners. Advances in ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1186/1476-072x-8-72 2020
-
[5]
https://doi.org/10.3390/ijgi14040170 Yang, D., Wu, Y ., Sun, F., Chen, J., Zhai, D., & Fu, C. (2021). Freeway accident detection and classification based on the multi-vehicle trajectory data and deep learning model. Transportation Research Part C: Emerging Technologies, 130, 103303. Yang, S., Abdel-Aty, M., & Han, L. (2026). Crash prediction under limited...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.